
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
地形因子流程化提取的模型描述与方法研究
[付天举1  , 许昱苹
, 许昱苹1 , 安添琳2 , 乔占明3 ]
, 许昱苹|
|


第一作者简介:付天举(1981-),男,高级工程师,主要从事计算机软件、电子商务与GIS应用研究。Email: abcde2046123@126.com。
将工作流思想引入到地形因子的提取中,应用可扩展标记语言(extensible markup language,XML)对地形因子流程化提取过程进行建模描述与方法研究。通过对地形因子提取过程中数据流转关系和数据输入与输出、参数执行、因子模型与驱动执行的结构化组织与描述,形成一套适用于地形因子流程化提取的模型和建模方法。在基础地形因子提取算法的基础上,采用分辨率为5 m×5 m的数字高程模型(digital elevation model,DEM)数据,对实验区域的地形因子进行全自动流程化提取验证。同时,应用该模型对实验区域的河网进行提取,均取得了良好效果,表明该模型具有较强的普适性与可扩展性。
The workflow technology was tentatively applied to the terrain factor extraction. The authors chose the extensible markup language (XML) as modeling language to study and model the process of terrain factor extraction. A set of models and modeling methods suitable for terrain factor flow extraction was formed by structured organization and description of the relationship between data transfer, input data, output data, parameters, factor model and driven execution from terrain factor extraction. The model with 5 m×5 m resolution based on traditional terrain factor algorithm automatically extracted terrain factor from DEM data of the experimental area, with good results achieved. At the same time, the river network extraction was conducted to test the terrain factor extraction model. The results show that the model has strong adaptability and scalability.
我国国土面积大, 地形地貌类型复杂多样, 地表变化频繁, 地理国情复杂。地形因子能够真实反映地表状态及其发展演化规律, 是对国家战略决策、经济发展、资源调配以及灾害预防等方面产生重要影响的自然地理要素。不同的地形因子从不同的侧重点反映着地面的起伏特征状况、地形变化以及地貌发育的内在规律[1]。目前, 基本地形因子的提取算法已经很成熟, 并已被广泛集成应用到GIS空间分析及水文分析功能模块中[2]。国内外学者对于地形因子的研究内容也主要集中在基本地形因子提取算法和提取精度与误差研究方面。陈楠等指出坡度的不同提取方法对坡度的平均值、最大值、标准差及中误差的影响以及坡度与空间分辨率的关系[2, 3, 4]; 强晓焕等以数字高程模型(digital elevation model, DEM)为基础, 探讨了坡度算法及其精度分析方法[5]; 刘学军等基于DEM的空间因素的不同提取算法进行了系统的误差分析[6, 7]; 汤国安、赵牡丹等研究了坡度提取、分级, 研究坡度分级的方法, 最终对不同地面坡度带进行了统计分析[8, 9]等。但是, 以地形因子间的关联关系和地形因子流程整合建模为整体的研究还较为少见。
随着3S技术的不断发展, 仅关注地形因子算法、精度、误差的研究已经不足以满足地质灾害、环境监测等相关行业的应用要求。必须加快建立基础地理信息动态更新机制, 建立空间决策支持系统, 进行空间分析和管理决策, 以满足政府、企业、社会各部门对及时获取准确、可靠的地形、地貌信息的迫切要求。本文以地形因子间的关联与组合关系提取过程建模为主要研究内容, 通过建模侧重描述各地形因子提取的前置输出与后继输入过程的流转关系。以基本地形因子提取算法理论为基础, 运用工作流思想, 组合与定制地形因子的提取流程, 研究地形因子流程化提取模型描述与建模方法, 实现自定义全自动的地形因子流程化提取。
工作流(workflow)技术起源于办公自动化(office automation, OA)领域[10]。随着计算机技术的发展, C/S体系结构和分布式数据库处理技术的发展日益成熟。工作流是一类能够部分或完全自动执行的经营过程, 它根据一系列过程规则、文档、信息或任务能够在不同执行者之间进行传递与执行[11]。其主要特征是实现计算机与人交互结合过程中的自动化。工作流也即表示某个业务过程的计算机模型。该模型可通过不同的表达形式预制整个业务流程所需的各种参数, 如负责实体、执行顺序、执行条件、数据等的定义[12, 13], 并按照这些预定义的参数, 完成任务在不同执行者之间传递, 最终实现任务执行过程的全自动化或半自动化[16]。
DEM是数字地面模型(digital terrain model, DTM)中最基本的部分, 是将地形的高程数据进行了数字化表示[14], 具有易更新、尺度综合、数据结构简单、数学运算方便等特点。本文采用DEM数据作为地形因子提取的主要数据源, 采用微观和宏观地形因子提取相结合的方法提取各类地形因子。
微观地形因子描述DEM中单一栅格的地形特征信息, 其大小仅受它所在行列及微小邻域范围内高程值的影响。在算法设计上, 采用3× 3的DEM栅格分析窗口(即八邻域运算), 提取算法中用到的X和Y方向的高程变化率。这种方式已广泛应用于基本地形因子(坡度、坡向、坡长等)的提取中。
宏观地形因子提取描述的是一定区域范围内整体的地形特征, 该区域(分析窗口)被看作一个整体进行运算。地形因子宏观提取方法不仅考虑它所在点的高程值, 同时需要综合考虑分析窗口内的所有点的高程信息。这种地形因子提取方式适合应用于复杂地形因子的提取(地面起伏度、地表粗糙度、地表切割深度、高程变异系数以及侵蚀势能等)。分析窗口一般有矩形分析窗口、圆形分析窗口、环形分析窗口和扇形分析窗口。本文采用矩形分析窗口, 分析窗口大小作为参数传入提取模型进行地形因子的提取。
以基本地形因子提取算法理论为基础, 从地形因子提取的精度、误差、参数设置等方面选定基本地形因子提取的算法, 形成基于工作流思想的地形因子提取的算法体系, 并对各个算法进行模块化描述与表达, 封装单一地形因子提取的功能模块, 设置数据输入、输出和参数设置功能入口。
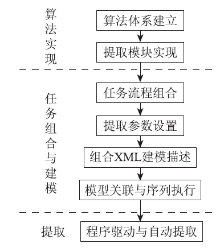
建立基于可扩展标记语言(extensible markup language, XML)的地形因子提取模型描述, 利用工作流思想将彼此独立的任务进行流程化的组合与配置, 通过XML模型描述中的关于地形因子提取任务间关联关系、执行顺序、前置与后继过程结果以及参数输入等信息, 组合地形因子提取过程, 进行模型描述。通过对地形因子提取的模型描述的驱动执行, 实现地形因子提取的灵活组合和全自动流程化提取, 具体的提取流程见图1。
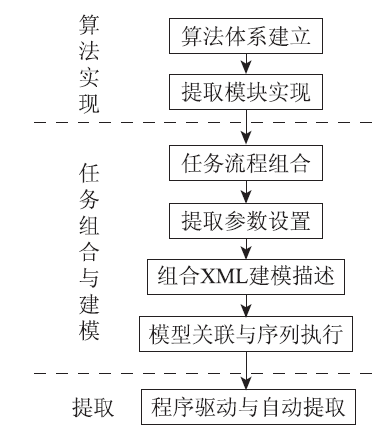 | 图1 地形因子提取流程Fig.1 Terrain factor extraction process flow |
XML是一种用来传递数据和储存数据的语言[15], 本文采用XML语言对基于工作流思想的地形因子流程化提取模型进行描述。通过定义标签, 全面地表达数据存储内容和模型实质。通过XML中不同标签节点的设置, 描述地形因子流程化提取的输入、输出、参数设置以及地形因子间的关联关系和提取序列。充分考虑地形因子流程化提取过程中基本地形因子的灵活性和地形因子间低耦合、高内聚的特点, 设计出一套基于XML的地形因子流程化提取的建模方法和模型描述。
分别从输入信息、执行参数、输出信息和地形因子模型关联4个方面描述地形因子流程化提取模型。以地形因子流程化提取的数据流转关系、输入与输出、元数据以及驱动执行参数设置等方面进行扩展与模型建立。具体模型组织与描述见表1。
| 表1 地形因子流程化提取XML模型描述 Tab.1 XML model description of extracting terrain factors process |
表中数据信息(DataInfo)、元数据(MetaData)以及因子模型(Model)描述仅用标签节点无法进行完整的描述, 因此对这3类子节点的XML建模描述进行扩展, 详细建模描述信息见表2。
| 表2 元数据、数据信息与因子模型描述 Tab.2 Description of MetaData, DataInfo and factor Model |
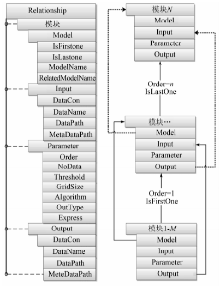
地形因子流程化提取XML建模描述的4方面在模型建立和纵向使用过程中, 4类建模描述信息相互之间并不并行, 各个节点之间具有包含、嵌套等逻辑关系。在XML建模描述中, 以模型关系描述(relationship)为流程组织的主线, 流程组织中集成了地形因子流程化提取所使用的因子模型, 并通过“ 关联模型名称” 实现因子流程化提取的顺畅进行, 以“ IsFirstOne” 和“ IsLastOne” 标签为流程化提取开始与结束标志。
输入、输出信息描述、执行参数描述与因子模型共同组成单个地形因子提取的模型描述。输入、输出信息描述作为相关因子模型的数据血液, 流转于流程组织中的各个因子提取模型中, 保证数据应用与产出的前驱和后继。执行参数描述为因子模型运行时需要的参数设置, 主要包含条件阈值、表达式、采用算法、分析窗口设置、模型执行序列、空值约束与数据输出格式, 通过数据的流转和执行参数的设置保障流程组合过程中单个地形因子模型提取的顺利完成。同时, 通过因子模型中的“ RelatedModleName” 作为因子模型关联与数据流转的纽带, 共同完成地形因子的流程化提取。具体的XML建模描述标签的逻辑关系见图2。
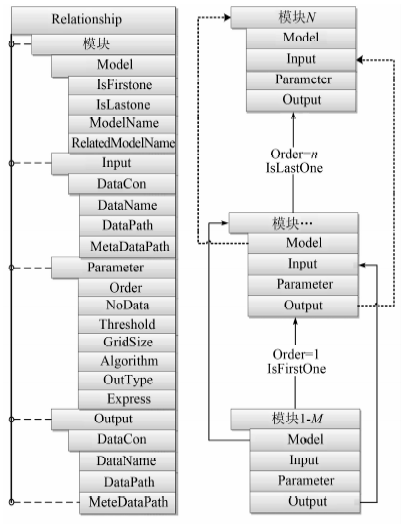 | 图2 地形因子流程化提取XML模型组织结构Fig.2 XML model structure of extracting terrain factors process |
实验区域位于N35° ~36° , E103.5° ~105° 之间, 包含了咸河、洮河、渭河和关川河的部分流域。区域位于黄土高原的西端, 地貌类型为典型的黄土丘陵沟壑地貌, 地形破碎, 沟壑纵横, 土壤侵蚀剧烈, 水土流失严重。地壳的不断运动和变迁, 使该地区形成了雄浑粗犷的黄土地貌。覆积厚度达百余米的黄土地表经过洪水、河流的不断剥蚀和切割, 形成目前的高原、沟壑、河谷、平川、山峦、斜坡兼有的地形地貌特征。本文采用的水平分辨率为5 m× 5 m的DEM数据精度较高, 能够真实反映各种地貌类型的地形特征, 保证地形因子提取的精度, 适用于进行区域间地形差异的比对与分析。
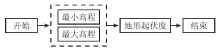
本文以地形起伏度的提取作为地形因子流程化提取模型建立与提取实验样例。地形起伏度为基本地形因子, 是指在所指定的分析区域内的高程差值。其算法原理为:首先定出一个栅格, 并以其为中心, 对周围3× 3窗口内最大高程值和最小高程值求差, 作为该中心栅格的起伏度。以此类推, 完成影像所有栅格的计算。其执行过程如图3所示。
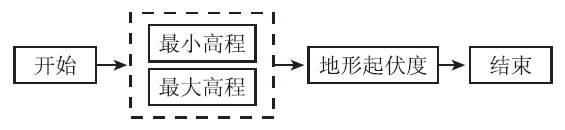 | 图3 地形起伏度提取执行过程Fig.3 Execution process of surface relief |
XML模型的核心表达如下:
< Roughness>
< Modle
ModleName="地形起伏度提取"
IsFirstOne="false"
IsLastOne="true"
RelatedModleName=""/>
< Input>
< DataCon>
< DataInfo
DataName="Out_Max"
DataPath="D: \\OutData\\Out_Max_05301622.img"MeteDataPath="D: \\OutData\\Out_Max_05301622_MeteData.xml"/>
< DataInfo
DataName="Out_Min"
DataPath="D: \\OutData\\Out_Min_05301628.imgMeteDataPath="D: \\OutData\\Out_Min_05301628_MeteData.xml"/>
< /DataCon>
< /Input>
< Parameter>
< ParaDes
Order="2"
NoData="-1"
Threshold=""
GridSize=""
Algorithm="D: \\Modle\\Roughness.dll"
OutType="img"
Express="Max()-Min()"/>
< /Parameter>
< Output>
< DataCon>
< DataInfo
DataName="Out_Roughness"
DataPath="D: \\OutData\\Out_Roughness_0530632.img"MeteDataPath="D: \\OutData\\Out_Roughness_0530632_MeteData.xml"/>
< /DataCon>
< /Output>
< /Roughness>
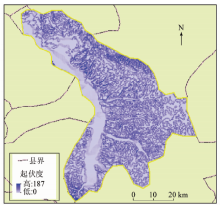
应用上述XML的模型组织, 对地形起伏度进行流程化模型描述与建模, 通过地形起伏度提取功能模块驱动执行, 得到地形起伏度提取结果(图4)。
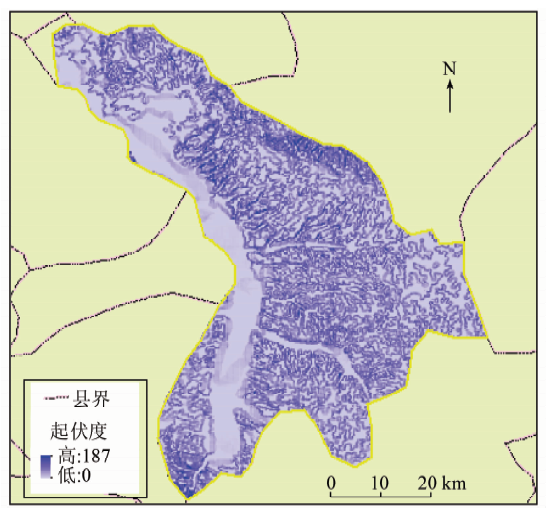 | 图4 地形起伏度提取结果Fig.4 Execution results of surface relief |
同时, 为了验证应用本文提出的流程化建模方法提取结果的准确性, 采用ENVI遥感影像处理软件, 在同一研究区域中, 应用相同的算法和参数设置, 应用逐过程提取地形因子的模式进行地形起伏度与河网提取。经比较, 基于流程化提取模型的提取结果与应用专业软件逐过程提取结果的灰度直方图一致, 但流程化提取结果更为准确可靠。
选择水文因子中的河网提取来验证文中所提模型的扩展性与普适性。在坡面流模拟原理中, 对于河流网络提取主要包含DEM数据预处理(洼地填充)、水流方向计算、汇流累计量计算及阈值选定以及河网提取4步。河流网络提取流程见图5。
 | 图5 河网提取流程Fig.5 Execution process of river network |
水流方向计算依据单流向原理, 采用八邻域计算方法, 在3× 3的窗口中计算DEM数据中每个中心格网的流向。依据水流方向计算的结果计算汇流累计量, 选定实验区域的汇流累计量阈值, 进行河流网络提取。依据本实验区域的专家经验值, 汇流累计量的阈值设置为200。依据本文提出的模型, 对河流网络提取涉及到的4个过程进行模块实现与组合流程描述。通过程序加载模型和注册河网提取过程中的功能组合, 最终实现实验区域的河流网络提取。提取结果见图6。
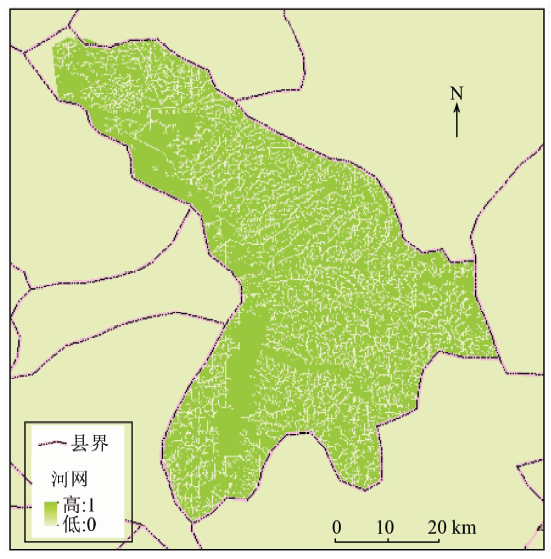 | 图6 河流网络提取结果Fig.6 Execution results of river network |
与地形因子提取算法、精度、误差与应用评价方面的研究不同, 本文侧重于地形因子提取中因子间的关联和组合关系的描述与建模。以工作流思想为指导, 对地形因子的组合提取流程进行建模与描述。通过基于XML的组合流程建模描述, 对地形因子提取的输入、输出、参数执行、因子模型与驱动执行进行结构化组织, 最终形成一套适用于地形因子流程化提取的模型和建模方法。
1)地形因子流程化提取模型能够较好地描述地形因子的提取过程, 在地形因子全自动(半自动)提取中取得了良好效果, 并具有较强的扩展性和普适性。
2)本文打破常规地形因子提取与专业软件捆绑、逐过程提取地形因子的模式, 通过订制提取模型, 解耦提取流程与算法, 灵活提取专题地形因子。
3)地形因子流程化提取模型大大减少了操作误差, 提高了提取结果的可靠性, 执行效率高效、参数配置灵活、设备易于维护。但是, 在进行地形因子组合提取的过程中发现, 某个特定地形因子提取时, 依赖于前置的输出结果, 并不都是一对一的关系, 所以目前模型是通过模块的执行顺序来串行执行地形因子提取过程的。对于前置输出结果与后继执行模型的“ 多对一” 关系, 后续研究可以进一步向并行化方向进行模型扩展开发。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|