
{kind=link}
{kind=link}
{kind=link}
岷江上游亚高山典型森林植被高光谱特征识别
[戴晓爱1  , 贾虎军
, 贾虎军1 , 张晓雪1 , 吴芬芳2 , 郭守恒1 , 杨武年1 , 杨叶1 ]
, 贾虎军, 郭守恒|
|


第一作者简介: 戴晓爱(1979-),女,博士,副教授,主要从事遥感与GIS方面的研究。Email:daixiaoa@cdut.cn
在高光谱数据分类应用中,地物光谱特征分析是对地物进行分类和检索的基础性工作。选取禾本科斑竹、草本科蕨类、荨麻科冷水花、杉科杉木和棕榈科棕榈树等5种岷江上游亚高山森林植被进行实地光谱测量,建立高光谱相似性度量参量,如欧式距离(Euclidean distance,ED)、光谱角度(spectral angle mapper,SAM)、光谱信息散度(spectral information divergence,SID)、SID和SAM混合SID(TAN)以及基于道格拉斯-普克算法的光谱降维距离(spectral distance based on Douglas-Peucker,SDDP)度量算法,定量分析对亚高山森林植被的识别能力。研究结果表明: 5种亚高山森林植被光谱特征的差异主要表现在光谱曲线反射波峰和波谷位置; ED对冷水花的相对光谱识别概率最高; SID和SID(TAN)对斑竹与蕨类的识别概率最高; SDDP对杉木的识别概率最高; SAM,SDDP,ED,SID(TAN)和SID这5种光谱相似性测度算法对亚高山森林植被的相对光谱识别熵分别是1.51,1.59,1.61,2.16和2.18,说明光谱角度制图具有较高的识别能力; 而道格拉斯-普克光谱检索算法是在提取光谱曲线特征向量的基础上进行相似性测度,其降低了光谱检索的时间频率,在保证相近识别能力的条件下,能够大大提高程序的检索效率,是一种快速有效的高光谱特征匹配和检索算子。
Spectral characteristics analysis is the basis of spectral feature classification and matching in hyperspectral image processing. In this paper, the authors selected five kinds of subalpine forest vegetation to measure their field spectra in the upper reaches of the Minjiang River, which include gramineae mottled bamboo, herbaceous fern,pilea notate, arbor china fir and shrubs palm. Through constructing the high spectral similarity measure index, five measuring methods, i.e., Euclidean distance(ED), spectral angle mapper(SAM), spectral information divergence(SID), spectral information divergence-spectral angle mapper(SID(TAN))and spectral distance based on Douglas-Peucker(SDDP), were used to analyze the relative capability for recognizing forest vegetation on the plateau. According to the results obtained, the spectral feature difference in the five kinds of forest vegetation mainly lies in peaks and troughs in the spectral curves; pilea notate has the highest relative spectral discriminatory probability in ED similarity measurement; mottled bamboo and fern have the highest relative spectral discriminatory probability in SID and SID(TAN); China fir has the highest relative spectral discriminatory probability in SDDP. SAM, SDDP, ED, SID(TAN)and SID of the relative spectral discriminatory entropy are 1.51, 1.59, 1.61, 2.16 and 2.18 respectively. The research results showed that the means reduced the amount of calculation for doing the similarity measurement which extracted the spectral feature vectors with the SFT, DPBSR and DABSR, DPSR. In order to ensure the condition of similar recognition capability, the means can greatly improve the retrieval efficiency of the program, and hence they are the fast and efficient hyperspectral feature matching and retrieval methods.
森林是人类生存环境的影响因子之一, 正确识别其植被特征是植被生态学研究的支撑性工作。目前森林树种特征识别的方法主要包括地面调查、图像解译和数字遥感。野外调查需要花费大量的时间, 且识别非常困难; 利用常规遥感数据通常只能区分到树种组或比较粗略的森林类型; 而高光谱遥感突破了光谱分辨率这一瓶颈因子, 能够准确地探测到具有细微光谱差异的各种地物类型, 能明显改善对森林树种的识别效果, 提高分类精度[1, 2, 3, 4]。国内外很多学者利用高光谱数据进行地物识别并取得了较好的结果[5, 6], 但利用高光谱遥感技术的高光谱分辨率特点进行西部亚高山森林植被识别的研究甚少。不同的森林类型具有不同的结构和功能等群落特征, 灌丛和林下草本植被特征也是体现森林植物群落多样性的丰富内容, 在一定程度上可以反映环境的差异[7, 8], 在森林植被的覆盖度调查、分类识别、动态监测、遥感反演及生态环境调控等方面具有重要意义。
在高光谱数据分类处理中, 通过对光谱曲线的相似性测度判断地物类型的光谱匹配程度已成为光谱特征测度的主要方法, 也是高光谱数据信息提取的基础。孔祥兵等[9]在几何距离、相关系数和相对熵的基础上, 提出了一种结合多种光谱特征的新型光谱相似性测度方法; 王珂等[10]提出以目标和参考光谱曲线的频谱幅度值之差来度量光谱的相似性; 李飞等[11]基于经典的曲线简化道格拉斯-普克(Douglas-Peucke)算法(简称DP算法, 是用来对大量冗余的图形数据点进行压缩以提取必要数据点的抽稀算法)提取光谱曲线的形态特征; 陈熙等[12]以巴氏(Bhattacharyya)距离(用于测量2个离散或连续概率分布的相似性)作为指标定量计算不同类别地物波谱间的光谱差异性; 施蓓琦等[13]提出了基于Hausdorff距离(即2个点集之间的距离)的地物光谱相似性测度模型; 杜培军等[14]采用不同的度量原理与实现策略, 提出基于光谱多边形的测度、四值编码、十进制编码、树状变换测度及基于小波变换的测度等新方法。目前, 光谱相似性测度模型仍侧重考虑基于距离和形状的方法。本文在考虑信息损失较低、处理效率较高、同时保证相似性度量效果最好的基础上, 选择了基于距离和形状的光谱相似性测度方法, 如欧式距离(Euclidean distance, ED)、光谱角度(spectral angle mapper, SAM)、光谱信息散度(spectral information divergence, SID)、SID和SAM混合(SID(TAN))以及基于道格拉斯-普克算法的光谱降维距离(spectral distance based on Douglas-Peucker, SDDP)测度。同时, 在采用3种统计学方法的基础上, 对禾本科斑竹、草本科蕨类、荨麻科冷水花、杉科杉木和棕榈科棕榈树等5种岷江上游典型亚高山森林植被的高光谱识别效果进行对比, 以便为高光谱植被遥感分类与识别提供技术依据。
本文的实验区青城山地处四川盆地西部边缘山地著名的“ 华西雨屏带” 的中北段, 都江堰市城西南区15 km处, 中心地理坐标为E 103° 35', N 30° 54'。该区地理条件特殊, 加之地处成都平原的生态屏障地带, 其生态环境非常重要。因受地质、地貌、气候等因素的影响, 该区植被类型不仅复杂, 而且存在随海拔从低到高垂直变化的规律, 依次为: 常绿林―灌木林―灌草混交林―天然草地。本文选取该区内叶片生理生化组分差异性较大的禾本科斑竹、草本科蕨类、荨麻科冷水花、杉科杉木和棕榈科棕榈树等5种植被(图1)作为实验样本。
 | 图1 5种森林植被样本照片Fig.1 Photos of five kinds of forest vegetation samples |
光谱测量采用美国ASD公司FieldSpec 3便携式光谱仪, 其有效波段在350~2 500 nm之间。数据采集时间为2013年4月12―16日。由于室外测量的影响因素较多, 本文主要在室内对样品进行光谱测试。室内光谱采集是在一个允许控制光照条件的黑暗实验室内, 将样品放在铺盖有黑色鹅绒布的桌子上, 在人工灯光(1 000 W)照明下, 用ASD光谱仪对样本进行光谱测量。光源离样本约50 cm; 采用3° 视场角的探头, 探测器头部垂直对准样品, 距样品约20 cm; 探测面积直径约为2 cm, 以保证样本充满整个视场。对每个样品测量9次光谱值后取其平均值。对每种植被叶片共测得36组反射光谱数据, 每组10条数据(5条叶片反射DN值, 5条参考板反射DN值)。为了消除仪器引起的随机误差, 本文首先求出每类物种的平均光谱值, 然后再对平均光谱用Savitzky-Golay方法(简称为S-G滤波器, 是一种在时域内基于局域多项式最小二乘法拟合的滤波方法)以15个数组窗口和二次多项式进行平滑处理。
1.2.1 欧式距离(ED)
ED是光谱相似性测度中最为常见的测度指标。欧式距离Ψ ED(x, y)的判决函数[15, 16] 为
Ψ ED(x, y)=
式中: x和y分别为2个待测光谱; n为光谱维数。距离值越小, 相似性越高, 则光谱相对识别能力越弱。
1.2.2 光谱角制图(SAM)
SAM是在以波段数为维数的坐标空间中, 以原点和实际光谱点构成高维向量, 以2个高维向量的夹角作为测度指标, 计算光谱角的余弦 [14, 17]。光谱角Ψ SAM(x, y)的计算公式为
Ψ SAM(x, y)=(
光谱角越小, 其余弦值越接近1, 相似性越高。
1.2.3 光谱信息散度(SID)
SID是一种基于概率统计理论, 计算光谱曲线相对信息熵的大小, 以确定2个光谱之间相似性的测度算子。光谱信息散度Ψ SID(x, y)的计算公式[18, 19]为
Ψ SID(x, y)=D(x‖ y)+D(y‖ x) , (3)
D(x‖ y)=
D(y‖ x)=
式中: D(x‖ y)为x对y的相对熵; D(y‖ x)为y对x的相对熵; pi和qi分别为光谱x和y的概率值。
1.2.4 SID(TAN)混合测度
SID(TAN)是一种SID结合SAM的混合测度算法。混合测度Ψ SID(TAN)(x, y)的计算公式[20]为
Ψ SID(TAN)(x, y)=Ψ SID(x, y)tan[Ψ SAM(x, y)] 。 (6)
1.2.5 道格拉斯-普克光谱降维距离(SDDP)
首先利用道格拉斯-普克算法对高光谱曲线进行降维预处理, 在减少数据量的同时保持光谱曲线的总体走向趋势不变; 然后按顺序选取光谱特征信息点, 依据式(5)计算各特征点之间的距离, 以此测度光谱相似性[11], 即
Ψ SDDP(λ , r)=
式中: Ψ SDDP(λ , r)为道格拉斯-普克光谱降维距离; λ ix和rix与λ iy和riy分别为2个待测光谱x, y的波段λ 与反射率r。
为了评估ED, SAM, SID, SID(TAN)和 SDDP等5种相似性测度算子的相对光谱识别能力, 本文选用3种统计学参数, 即相对光谱识别力(relative spectral discriminatory power, RSDPW)、相对光谱识别概率(relative spectral discriminatory probability, RSDP)和相对光谱识别熵(relative spectral discriminatory entropy, RSDE)。
1.3.1 相对光谱识别力
相对光谱识别力用于评估目标光谱向量从其相关参考光谱向量中被识别出的能力。假设m为任一光谱相似性测度算子, d为参考光谱向量, si和sj分别为待测光谱特征的2个向量, 则相对光谱识别力PWm(si, sj; d)的计算公式[23]为
PWm(si, sj; d)=max
PWm(si, sj; d)值越大, 光谱相似性测度算子m的识别能力越高。此外, PWm(si, sj; d)值具有对称性且下界为1, 即PWm(si, sj; d)≥ 1。
1.3.2 相对光谱识别概率
不同光谱相似性测度算法的计算结果具有不同的测度单位, 因此本文将不同算子的测度值进行标准化处理, 其计算公式[21]为
Pm(i)=
式中: Pm(i)为相对光谱识别概率; i为不同算子, i=1, 2, …, j; m(t, si)为标准光谱向量t相对于其他目标光谱sk的相似性测量值;
1.3.3 相对光谱识别熵
为了分析光谱相似性测度算子的总体识别能力, 计算相对光谱识别熵RSDE(t), 其公式 [22]为
RSDE(t)=-
式中Pm(i)为相对光谱识别概率。RSDE值越小, 相似性测度算子对植被光谱识别的能力越强, 其分类结果的精度越高。
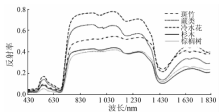
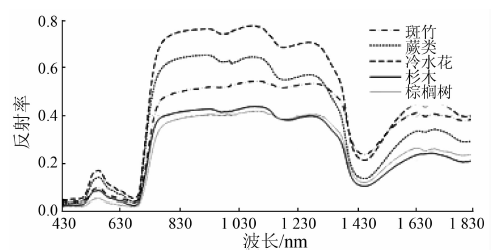
2.1 5种森林植被基本光谱反射特征
本文所研究的5种亚高山森林植被叶片的光谱曲线分布趋势大体相同, 如图2所示。
 | 图2 5种森林植被平均反射光谱曲线Fig.2 Average reflective spectral curves of five kinds of forest vegetation |
在490 nm附近的蓝光区和685 nm附近的红光区存在强吸收带, 形成“ 蓝谷” 与“ 红谷” , 反射率分别在0.02~0.05和0.04~0.06之间变化; 因绿光波段吸收减弱, 在蓝谷和红谷之间形成一个反射峰, 峰值位于553 nm附近, 反射率在0.05~0.17之间变化; 在685~755 nm谱段反射率急剧上升, 形成一个陡坡; 由于生物量和叶面积指数等的影响, 在760~1 300 nm波段区间形成一个较高的反射平台; 在红外波段(1 300~1 820 nm)因受到叶片内含水量的影响, 吸收率增加, 反射率降低; 在1 455 nm附近主要受到大气含水量的影响, 形成一个低谷。
因植被生理生化的差异, 不同植被叶片光谱曲线之间存在明显的差异。如图2所示, 在可见光和近红外波段(430~1 170 nm), 5种亚高山森林植被的反射率由高到低依次是冷水花、蕨类、斑竹、杉木和棕榈树。由于草本类冷水花和蕨类的叶绿素与水分含量低, 与其他3种植被相比反射率偏高; 同时, 蕨类受叶片内含水量的影响较大, 在1 323 nm附近的反射率显著降低。在可见光波段, 5种森林植被反射率差异较小; 但在红外波段, 存在较大的差异。受叶片内细胞的影响, 棕榈树在1 165 nm附近的反射率有所升高。
本文以Visual C++ 6.0为工具, 完成了光谱相似性测度算法程序的开发, 并用于对5种亚高山森林植被进行了光谱相似性测度。表1―表3为用5种相似性测度算法度量亚高山森林植被得到的相对相似性测度矩阵。
斑竹、蕨类、冷水花、杉木和棕榈树反射光谱曲线之间的欧式距离ED和空间夹角余弦值SAM结果见表1。
| 表1 ED和SAM相似性测度矩阵① Tab.1 Similarity measure matrix of ED and SAM |
从表1可以看出, 冷水花与棕榈树的欧式距离最大, 反射光谱特征相似度最小, 有较强的识别能力。杉木与棕榈树的反射光谱特征非常接近, 相似度最大, 识别能力较弱。光谱角度相似性度量算子具有很高的相似度, 整体余弦值大于0.98。其中, 杉木和冷水花的光谱余弦值最大(即它们之间夹角最小), 识别能力最弱; 蕨类与斑竹余弦值最小(即它们之间夹角最大), 具有较高的可分性。
斑竹、蕨类、冷水花、杉木和棕榈树反射光谱的SID和SID(TAN)结果见表2。
| 表2 SID和SID(TAN)相似性测度矩阵① Tab.2 Similarity measure matrix of SID and SID(TAN) |
从表2可以看出, 在5种森林植被中, 斑竹和蕨类的光谱信息熵最大, 亦即2种植被的光谱差异最大, 相对识别能力比较强。冷水花与杉木的信息熵最小, 两者的光谱差异性最小。斑竹和蕨类的SID-SAM混合测度值最大, 即结合反射光谱波形与空间角度测度的相似性最小, 有最强的相对识别能力。冷水花与杉木的SID-SAM混合测度值最小, 相对识别能力较弱。
斑竹、蕨类、冷水花、杉木和棕榈树反射光谱降维后特征量的相似距离结果见表3。
| 表3 SDDP相似性测度矩阵① Tab.3 SDDP similarity measure matrix |
斑竹与杉木的空间距离最大, 相似性最小。斑竹与冷水花的距离最小, 相似性最大。
为了验证相似性测度算子的有效性, 本文选取斑竹为参考光谱d, 蕨类为待测光谱si, 冷水花为待测光谱sj, 则相对光谱识别力PW的计算公式为
PWSAM(si, sj; d)=
PWSDDP(si, sj; d)=
式(11)说明以SAM为算子从冷水花中识别出斑竹的效率是从蕨类中识别出斑竹的效率的1倍; 式(12)说明以SDDP为算子从冷水花中识别出斑竹的效率是从蕨类中识别出斑竹的效率的4倍。因此, 在识别斑竹光谱时, SDDP算子比SAM算子更有效。
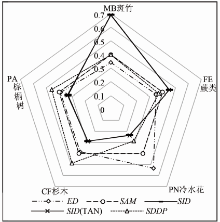
利用式(9)和(10)将5种光谱相似性测度算法测度值进行标准化计算, 使测度值具有统一的尺度, 以分析森林植被各科属的相对识别能力(图3)。
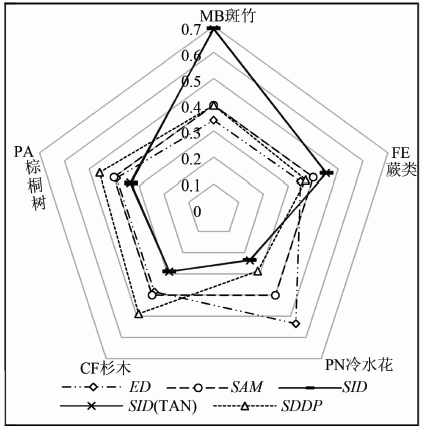 | 图3 相对光谱识别概率Fig.3 Relative spectral discriminatory probability |
分析图3可知, 对亚高山森林植被的高光谱相对识别能力, 不同相似性测度算子具有不同的敏感程度。其中, SID和SID(TAN)对斑竹(MB)与蕨类(FE)的识别概率最高; ED对荨麻科冷水花(PN)的识别概率最高; SDDP对杉科杉木(CF)和棕榈科棕榈树(PA)的识别概率最高。
表4列出ED, SAM, SID, SID(TAN)和SDDP等5种光谱相似性测度算子的RSDE。
| 表4 相对光谱识别熵 Tab.4 Relative spectral discriminatory entropy |
由表4中RSDE可知, 5种光谱相似性测度算子对森林植被总体识别能力的差异性较小, 识别能力由强到弱依次为: SAM> SDDP> ED> SID(TAN)> SID。SAM具有最小的相对光谱识别熵, SID具有最大的相对光谱识别熵, 且5种测度算子的熵值相差较小。其中SDDP算子由基础算法提取光谱特征, 经数据降维后进行光谱相似性度量, 效率较高; 与全部光谱波段参与计算的ED, SAM, SID和SID(TAN)算子相比, 总体光谱识别能力比较相近。
本文针对高光谱数据的亚高山森林植被识别, 从光谱曲线形态相似性测度入手, 利用统计学方法对相似性测度算子进行了评估, 主要结论如下:
1)亚高山森林植被的反射光谱曲线走向基本一致, 特征波段相似。由于棕榈树叶片内细胞的影响, 在1 165 nm附近的反射率有所增加。蕨类因叶片内含水量的影响较大, 在1 323 nm附近的反射率显著降低。
2)欧式距离(ED)、光谱角度(SAM)、光谱信息散度(SID), SID和SAM混合(SID(TAN))以及基于道格拉斯-普克算法的光谱降维距离(SDDP)等5种光谱相似性测度算子在亚高山森林植被光谱信息细微处的相对识别能力不同。ED对荨麻科冷水花的识别能力较强; SAM是一种描述全局性的度量指标, 对局部变化特征响应不显著, 对5种植被光谱的相对识别概率差异性较小; SID测度是基于光谱信息熵的测度算子, 主要受到反射光谱波形的控制, 在5种植被中对波形差异最大的斑竹和蕨类的识别能力最强; SID(TAN)测度因SAM参量变化较小, 其相对识别能力与SID基本一致; SDDP提取光谱特征向量进行相似性度量, 在减少了数据量的同时, 保证了与其他算子相近的计算精度, 对杉木和棕榈树的识别能力最强。
3)5种光谱相似性测度算子对亚高山森林植被分类识别能力由大到小依次是: SAM, SDDP, ED, SID(TAN)和SID。在已发表的文献中, 具有较高识别精度的SID对亚高山森林植被的识别效果较差, 而SAM具有最佳的识别效果, 与本文的研究结果一致。SDDP在提取光谱特征信息的基础上进行相似性测度, 是一种新的、快速、有效的光谱匹配和检索算法。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|