
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于NPP-VIIRS夜间灯光数据的北京市GDP空间化方法
[李峰1  , 米晓楠
, 米晓楠2 , 刘军1 , 刘小阳1 ]
, 米晓楠|
|


第一作者简介: 李 峰(1979- ),男,讲师,工程师,工学博士,主要从事测量与遥感方面的教学与研究工作。Email:lif1223@aliyun.com
为了分析像素级社会经济活动的空间分布状况,以Landsat8 和NPP-VIIRS夜间灯光影像为数据源,分别对北京市第一产业和第二、三产业GDP进行空间化操作。利用分类回归树(classification and regression tree,CART)算法,通过Landsat8影像生成北京市的土地利用图,在分析第一产业GDP与土地利用类型面积相关性的基础上,构建了第一产业GDP与耕地面积的线性回归模型。建立了5种灯光指标与第二、三产业GDP的数学关系,通过相关性和回归分析确定第二、三产业GDP与综合灯光指数呈明显的幂函数关系。根据以上2种模型分别生成对应2类产业的像素级GDP密度图,再分别对其进行线性纠正并求和后制作出北京市500 m格网尺寸的GDP密度图。误差分析发现,第一产业GDP、第二、三产业GDP和GDP总量与实际统计值的平均相对误差分别为0.86%,0.61%和1.37%。结果表明,结合土地利用数据的NPP-VIIRS夜间灯光GDP空间化方法可以精确估算北京市GDP产值,反映北京市经济空间分布特征。
In order to analyze spatial distributions of socioeconomic activities at pixel scale, the authors used Landsat8 and NPP-VIIRS night-time light images as data sources and produced spatialization maps of primary industry GDP and the secondary, tertiary industry GDP in Beijing. The land use map of Beijing for the spatialization was produced from Landsat8 image with CART decision-tree algorithm. According to the correlation results between the primary industry GDP and areas of land use, a linear regression model was built based on the primary industry GDP and areas of plough. By analyzing the correlation relationships between five light indexes and the secondary, tertiary industry GDP, compounded night light index (CNLI) and the secondary, tertiary industry GDP presented apparent power function’s correlation relationship. Using linear corrections and summation of two types of pixel level’s GDP density maps produced both modes listed above, and a total GDP density map was generated with the resolution of five hundred meters in Beijing. The results of GDP relative errors show that the primary industry GDP and the secondary, tertiary industry GDP were 0.86%, 0.61% and 1.37% respectively. This suggests that this approach of pixel level’s GDP spatialization can be applied to estimate Beijing’s GDP and reflect characteristics of its economic distribution.
国民生产总值(gross domestic product, GDP)是反映一个国家或地区全部生产活动最终成果的重要指标, 用来衡量国家或地区的经济实力和发展状况。长期以来, 社会经济数据常基于统计单元(行政区)建立多边形数据库, 以点值内插法进行全区域统计数据的分析和操作。但因数据分辨率低而不能充分揭示统计数据的空间差异性。随着对高分辨率GDP密度数据需求的日益增加, 格网生成技术被用于社会经济统计数据的格网化。刘红辉等[1]利用遥感数据建立了分产业GDP与土地利用类型的空间关系, 实现1 km格网的社会经济数据的空间定量模拟; 易玲等[2]分别按照人口和土地利用数据构造了GDP空间化模型, 分析认为土地利用GDP模型精度明显高于人口分配GDP模型。随后, GIS和栅格数字模拟技术进一步促进了社会经济数据空间化的发展。自20世纪90年代起, 美国国防气象卫星计划(defense meteorological satellite program’ s operational linescan system, DMSP-OLS)夜间灯光数据因能探测城市灯光甚至小规模低强度灯光, 而被逐渐用于1 km格网的GDP空间化和城市化的研究中[3, 4, 5]。Elvidge等[6, 7]在研究全球21个和200个国家的GDP与DMSP-OLS灯光数据后发现, 两者分别呈现高度的对数和线性关系; Henderson等[8]根据DMSP-OLS稳定灯光和辐射定标灯光数据的最佳阈值, 提取了旧金山、北京和拉萨经济发展水平有差异地区的空间信息; Doll等[9]依据DMSP-OLS夜间灯光与GDP的关系绘制了区域经济活动图; 韩向娣等[10]利用土地利用图对全国第一产业GDP建模, 结合DMSP-OLS和土地利用数据对全国第二、三产业GDP建模, 生成的GDP密度图比单一数据的精度要高。但是, DMSP-OLS数据中的像素过饱和和溢出现象削弱了灯光数据与社会经济数据的相关性, 而新一代的夜间灯光数据可见光红外成像辐射仪(national polar-orbiting partnership’ s visible infrared imaging radiometer suite, NPP-VIIRS)却不存在上述问题。Li等[11]和Shi等[12]在采用这种夜间灯光数据研究中国大陆的GDP后发现, 相比DMSP-OLS数据, 夜间灯光总量与GDP之间有更高的线性关系。随着经济和社会科学的发展, 在全球或国家尺度上的社会经济数据空间化, 更多以行政单元均值的形式来表现, 无法全面准确反映地区的GDP分布状况。因而, 更多的研究重心开始转向省域、县域甚至乡镇级GDP空间化的工作中[13, 14]。
为了深入提高省域GDP空间化的精度, 本文以北京市为例, 在综合分析其经济统计数据的基础上, 通过NPP-VIIRS灯光数据建立其与第二、三产业GDP的数学模型, 通过Landsat8影像生成北京市的土地利用图, 分析并构建各土地利用类型与第一产业GDP的回归模型, 从而建立适用于省域的像素级GDP空间化模型, 更加详实准确地模拟省域GDP分布状况, 为政府经济政策的制定和GDP产值估计提供可靠的决策依据。
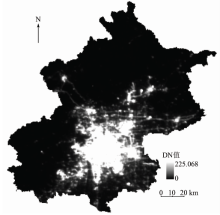
NPP-VIIRS夜晚灯光数据来源于NOAA/NGDC(http://ngdc.noaa.gov/eog/viirs/download monthly.html)网站, 是由 Suomi-NPP 卫星利用VIIRS在2012年4— 10月间拍摄, 距地表约 824 km, 采用极地轨道, 由多幅无云影像拼接得到。与DMSP-OLS数据不同, NPP-VIIRS数据并没有过滤火光、气体燃烧、火山或极光, 背景噪声也未剔除, 但是其影像分辨率达到了15″(约450 m), 所采用的广角辐射探测仪消除了灯光过饱和现象, 增强了探测敏感度, 其在轨检校程序也进一步提高了影像的清晰度。图1显示了2012年北京市NPP-VIIRS夜间灯光数据。
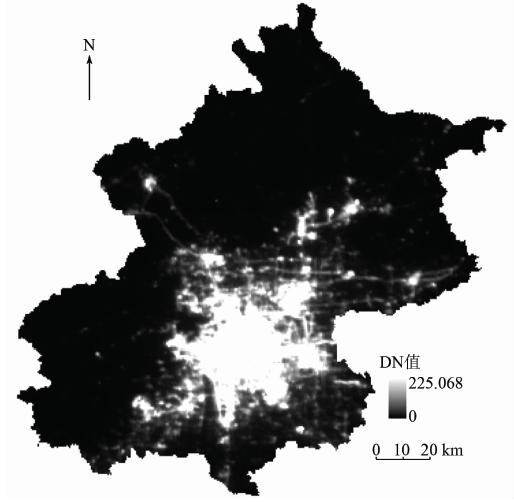 | 图1 2012年北京市NPP-VIIRS夜间灯光数据Fig.1 NPP-VIIRS nigh-time light data of Beijing in 2012 |
原始数据文件采用WGS84椭球下的地理坐标系, 为使得投影变形最小, 投影转换成Albers投影, 以双线性采样的方法重采样成500 m格网大小。
为了降低NPP-VIIRS的噪声, 采用2012年北京市DMSP-OLS夜间平均稳定灯光数据提取NPP-VIIRS的有效灯光数据。DMSP-OLS数据清除了云层的影响, 包含城市、乡镇以及永久性光源地, 排除了偶然灯光噪声, 背景噪声用0值替代, DN值在1~63之间。
由于2012年Landsat5传感器失效, 但是据统计年鉴数据可知2012年第一产业GDP与2013年相比变化较小。因此, 本文利用2013年10月3日Landsat8卫星OLI多光谱数据获得的北京市土地利用类型图建立2012年第一产业GDP模型。
本文的目的在于通过夜间灯光数据和土地利用数据建立与地区生产总值(GDP)、第一产业产值(GDP1)以及第二、三产业产值(GDP23)之间的数学模型。作为第二产业的工业、建筑业与以服务业为主的第三产业之间的城市灯光差异很小, 因此综合第二、三产业的夜间灯光数据的建模结果要优于单独建模的结果。夜间灯光数据很难准确探测到城市以外的农村地区, 第一产业的产值与灯光数据的关系也不明显, 而与耕地等农业用地关系密切, 土地利用数据可以为第一产业产值建模提供便利[15]。
北京市土地利用分类数据通过采用分类回归树(classification and regression tree, CART)算法基于Landsat8影像分类获得[16]。与其他决策树相比, CART算法简单、结构清晰、运行速度快, 能最大限度地降低各个步骤的不纯洁度, 有效处理大量的高维数据。
参加分类的变量包括Landsat8影像中的第1— 7个多光谱波段、NDVI值、MNDWI值及北京市30 m空间分辨率DEM。鉴于草地与耕地的光谱差异极小, 且北京市草地面积仅占总面积的0.13%, 本文将草地归入耕地类别。选择林地、耕地(含草地)、水域、建设用地和其他(裸地和阴影)共5种土地类型的6 092个训练样本, 通过学习得到56个叶结点的决策树结构。根据高空间分辨率Google Earth影像随机提取的276个检验样本建立混淆矩阵。检验结果显示, CART算法的总体分类精度达95.65%, Kappa系数为0.94。虽然北京市林地面积占全市总面积的53.31%, 但是并非所有的林地都能为第一产业贡献产值, 故通过GIS的分析功能提取坡向在90° ~270° 且坡度小于20° 的经济林地来分析其对第一产业的贡献。
根据北京市16个区县的土地利用类型面积(耕地、水域和经济林地)和对应第一产业的产值, 分析各土地利用类型面积与GDP1的相关性, 发现呈多元线性关系, 对应的耕地(含草地)、水域和经济林地面积的模型回归系数分别为m1=0.026 1, m2=0.073 3和m3=-0.000 4, 相关系数为0.689。单独分析耕地面积(Sc)与GDP1的相关性, 其回归关系如图2所示。
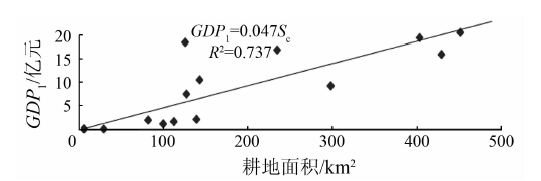 | 图2 耕地面积与GDP1的关系Fig.2 Relationship of agricultural acreage and GDP1 |
很明显, 就GDP1而言, 与耕地面积(Sc)的相关性明显高于其他各土地利用类型面积, 因此本文采用式(1)来模拟北京市GDP1的产值, 即
GDP1=0.047Sc 。 (1)
2.2.1 NPP-VIIRS数据去噪
假设2012年的NPP-VIIRS数据和2012年的DMSP-OLS稳定灯光数据有着同样的灯光范围, 因而可以通过同年份的DMSP-OLS数据制作掩模提取NPP-VIIRS中的有效灯光数据。去噪的DMSP-OLS数据仍然存在灯光过饱和及溢出现象, 根据2.1节的土地利用类型结果, 将分类的建筑用地与DMSP-OLS灯光数据叠加来确定最佳灯光阈值(DN值范围在14~63), 通过去饱和灯光的DMSP-OLS数据掩模NPP-VIIRS数据来消除其背景噪声和偶然灯光噪声[17]。为了去除NPP-VIIRS数据中孤立的极亮像元, 将全部像元值按升序排列, 取像元数99.9%处的像元值作为阈值DNM(本文为89.145), 高于此阈值的像元值均赋值为DNM。
2.2.2 灯光数据与GDP23的回归分析
目前常用的灯光数据指标有总灯光强度(total night-time light, TNL)、平均灯光强度(I)、灯光面积比(S)、线性加权综合灯光指数(L)和综合灯光指数(compounded night light index, CNLI)。TNL是指行政单元内灯光DN值的总和。上述指标的表达式分别[18, 19]为
I=
S=AN/A , (3)
L=Ip1+Sp2 , (4)
CNLI=IS , (5)
式中: DNi和ni 分别表示行政单元内第i级灰度像元值和像元数; N和AN分别代表行政单元内位于[1, DNM]区间的像元总数和所占据的面积; A表示行政单元面积; L为I和S的函数; p1和p2分别为指标I和S的权重, 通过多元线性拟合的方式求出, 故利用Matlab软件求出p1和p2的值分别为0.9和0.1, 即
L=0.9I+0.1S 。 (6)
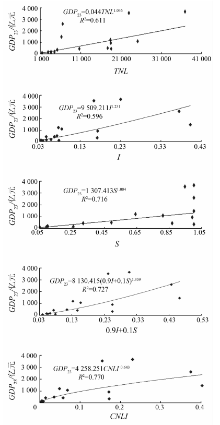
分别统计并生成北京市16个区县的TNL, I, S, L和CNLI这5种灯光数据指标与对应GDP23的散点图, 如图3所示, 分析其与GDP23的相关性, 确定最佳回归模型。
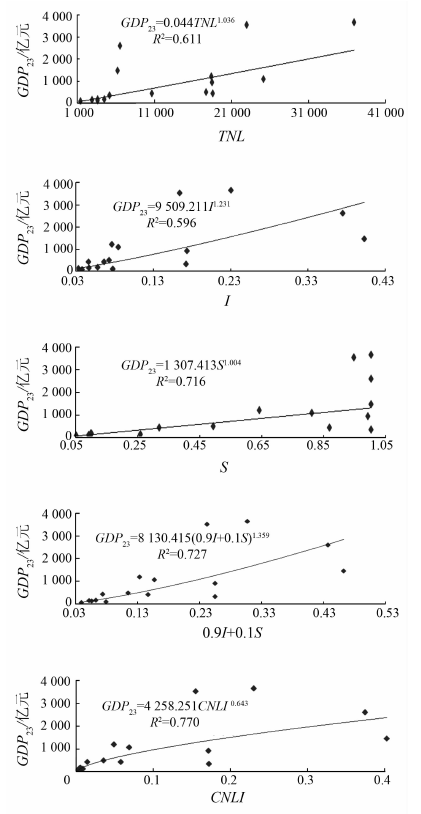 | 图3 5种灯光指标与GDP23的回归关系Fig.3 Relationships of five light indexes and GDP23 |
经过实验发现, 上述5种指标均与GDP23呈现幂函数关系。选取其中相关系数最大的CNLI灯光指标建立与GDP23的最优回归模型, 采用
GDP23=4 258.251CNLI0.643 (7)
来模拟北京市GDP23的产值。为了估计行政单元内的任意像元所代表的GDP23值, 式(7)可改写为
GDP23=4 258.251(DNi/DNM)0.643 。 (8)
虽然式(8)为北京市GDP23的最优回归模型, 但它是通过各区县的灯光数据与实际统计数据回归分析得到, 直接用任意灯光像元计算得到的GDP23的误差依然较大, 因此需要对模拟的GDP23进行分区县重新纠正。
对社会经济数据空间化时, 格网尺度大小对最终模拟结果有着重要的影响, 格网尺度并非越小越好。研究表明, 国家和全球格网尺度为1 km或5 km, 省市级区域的格网尺度在100~1 000 m之间为佳。确定格网尺度的原则为: 在顾及地理数据尺度的前提下, 既要反映社会经济数据的原始分布状态, 又要反映出其连续分布的现实[20, 21]。
本文在模拟GDP1和GDP23时分别采用了30 m和500 m空间分辨率的影像, 考虑到北京市山地面积和城市用地面积分别占全市总面积的55%和37%, 过小的格网会导致没有GDP分布, 过大的格网会忽略GDP分布的差异性。为此, 本次研究选用了500 m格网尺度。为了避免重采样造成的精度损失, 通过将模拟的500 m空间分辨率的GDP23图上每个像元的地理坐标映射到同范围30 m空间分辨率的土地利用图上, 并统计其中耕地像元的面积, 再利用式(1)计算出500 m空间分辨率每个格网内的GDP1。
直接采用式(1)和式(8)模拟的GDP1和GDP23误差仍较大, 故需要分别利用第一和第二、三产业实际产值通过线性调整的方式来纠正。对每个区县, 在保证各区县GDP1和GDP23总量为实际统计值的前提下, 采用式(9)来分别逐像元纠正模拟的GDP1和GDP23值, 即
GDPT=GDPj(GDPt/GDPall) , (9)
式中, GDPT为纠正后的GDP产值; GDPj为格网j模拟的GDP产值; GDPt为该区县统计的实际GDP值; GDPall为该区县模拟的GDP值。
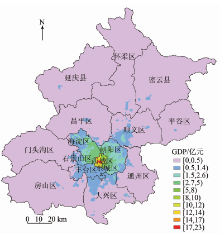
将纠正后的GDP1和GDP23直接求和可得到该地区的总产值, 生成的2012年北京市GDP图如图4所示。
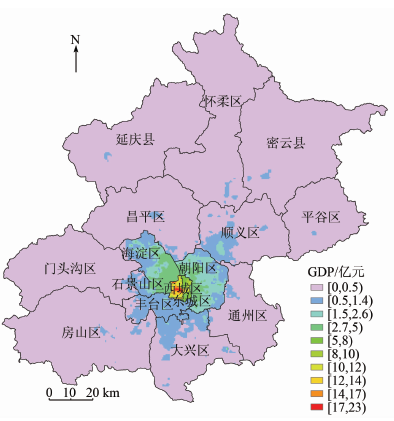 | 图4 2012年北京市500 m空间分辨率的GDP图Fig.4 Beijing GDP map with 500 m resolution in 2012 |
对北京市各区县GDP1, GDP23和GDP的模拟结果与实际统计值进行误差分析, 结果如表1所示。
| 表1 北京市各产业产值模拟结果与实际统计值的相对误差 Tab.1 Relative errors of simulated three kinds of GDP in Beijing(%) |
在第一产业产值的相对误差中, 东城区、西城区和石景山区的误差为0, 主要是由于这3个城区的第二、三产业相当发达, 行政单元内绝大部分区域被建筑用地所覆盖, 耕地、草地和林地面积相对较少, 经过线性纠正后的GDP1模拟值与实际统计结果一致。其中, 朝阳区、门头沟区、密云县和延庆县的GDP1相对误差超过了2%; 朝阳区的第二、三产业很发达而第一产业的比重较低, 在使用Landsat8影像分类时不可避免地把不会产生第一产业产值的公园草地归类为耕地, 造成该区耕地面积被高估, 使得第一产业误差增大; 门头沟区、密云县和延庆县均为山区, 耕地面积较少, 除耕地外, 占大部分面积的林地、密云水库等对第一产业产值的贡献更大, 因此只用耕地来预估GDP1会低估其产值, 从而增大GDP1的相对误差。第二、三产业产值的相对误差均小于2%, 这表明利用NPP-VIIRS夜间灯光数据来模拟GDP23的精度较高。总产值的相对误差中, 除密云县和延庆县外, 其余区的GDP相对误差都低于2%, 这很可能是因为这2个县的GDP1模拟误差较大所造成。GDP1, GDP23和GDP的平均相对误差分别为0.86%, 0.61%和1.37%, 三者的平均相对误差都很小, 各类GDP预测精度较高。
利用NPP-VIIRS夜间灯光和Landsat8数据对北京市的各产业GDP进行空间化处理, 研究结果表明: 耕地面积与第一产业GDP的相关性要高于其他土地利用类型; 第二、三产业GDP与区县NPP-VIIRS综合灯光指数呈现较强的幂函数关系; 基于像素级的第一产业GDP和第二、三产业GDP的回归模型直接计算的GDP产值误差较大, 需要进行线性纠正才能达到较高的精度; 从模拟的各产业GDP平均相对误差上看, 各产业GDP的平均误差均小于2%, 模拟精度较高, 生成的像素级GDP分布可完整地反映北京市经济分布的实际状况。
NPP-VIIRS夜间灯光数据在2012年开始对外提供数据, 当前针对这种新数据源的研究成果较少, 如何有效过滤其背景噪声和偶然灯光因素, 优化回归模型构建方法, 分析社会经济数据的时空变化情况, 将成为后续深入研究的重点。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|