

0 引言
矿山遥感监测已成为常态性的年度任务,每年在监测成果整理完成时,需立即开展监测指标[1]统计工作,统计任务工作量大、时间紧迫。矿山遥感监测统计指标涉及的数据具有结构复杂、条目众多、空间属性数据格式要求严格等特点,需要按照矿山遥感监测技术标准进行统计计算,且由于监测数据涉及大量的修改、变动,监测指标需要随着监测数据及时同步更新,因此要在短时间内同步完成监测区域内全部矿山监测指标的统计计算,是极大的挑战。目前针对矿山遥感监测指标快速统计,还缺乏一个成熟、完整、可用的自动化统计方法,主要是因为在统计工作中存在如下难点:
1)统计数据较多。统计汇总工作涉及的数据包括各类监测成果矢量图斑、各类数据字典、各类统计表单等。监测成果数据对应的数据字典有十几大类和几百小项,针对这些大量的分类组合衍生出极多种类的统计指标,且这些统计指标之间互相具有联动、重复、互证的属性。
2)统计过程繁复。需要协同使用多种软件完成矿山监测,统计数据涉及多种数据格式,内容涵盖按监测成果数据分类、行政区划范围、矿山类型提取和统计大量的属性、图形信息并进行汇总计算。任一统计值都涉及十几步连续的操作,且要在不同软件中衔接转换。
3)统计结果易错。由于统计工作量巨大,且需要分别按指标类型、按行政区域或者矿山区域、按矿山属性类型等进行统计,最终再汇总成统一的统计结果,稍有疏忽容易重复统计、漏统计。因此需要大量的人工协作才能完成,容易混入错误且错误结果较难排查,导致统计结果指标不一致、精度不达标或统计结果相互矛盾的情况时有发生。
针对以上问题许多学者已经开展了相关研究。杨振山等[2]阐述了空间统计时应注意的空间尺度、空间权重矩阵等问题; 杨兴华等[3]采用红黑树对查询建立索引,把查询分解为单独的布尔因子,实现了数据流条件过滤的批处理策略; 尹燕[4]提出的XML数据流查询过滤算法,利用所构造的文档的索引结构,对给定的一系列XPath查询表达式进行预处理,可以有效提高查询速度; 鞠瑞年等[5]提出多维矩阵是一种新的处理多指标问题的方法和体系,并定义了多维矩阵的加法、乘法及转置等基本运算; 刁明光等[6,7,8]通过COM组件开发实现了对监测数据进行自动化样本采集、检查、转换的方法; 随欣欣等[9,10]通过Raster Catalog混合模式对遥感解译成果进行了高效存储和调取。
本文基于空间统计的基本原理,针对矿山遥感监测指标自动统计问题,将计算机科学中数据流式过滤方法和应用数学中多维矩阵计算方法与空间统计问题相结合,提出自动化快速统计方法,然后借鉴已有矿山遥感系统模式,开发程序验证方法的准确性和效率,期望为以后解决此类问题提供一种有效可行的途径。
1 矿山遥感监测统计指标及流程
矿山遥感监测统计指标按不同统计类型包括不同的多种要素[11],在总结人工统计操作流程的基础上,本文提出一种自动化的统计方法及流程。
1.1 矿山遥感监测统计指标
矿山统计结果包含全矿山统计和涉及露天开采矿山统计2种。其中全矿山统计又包括4类,分别是正在利用矿山统计、废弃矿山统计、分县矿山统计和煤矸石山统计,涉及露天开采矿山统计包括3类,和全矿山统计的前三类一一对应。
正在利用矿山统计和废弃矿山统计指标结构类似,存在的部分区别可以归并处理。煤矸石山统计是类似简化过的单一统计,这里不再论述。正在利用/废弃矿山统计指标值为一二维主系矩阵结构,统计指标矩阵行包括按矿山、县、省的统计,按县及县内矿山(许可证号)顺序编号排列。正在利用矿山分类统计指标包括县代码、县名称、矿业许可证号、矿山图斑坐标、矿种类型(煤、花岗岩、石灰岩、水泥用粘土...)、占地方式(采场、中转场地、固体废弃物、矿山建筑、地下开采塌陷面积)及所占面积、面积合计、其中的违法图斑面积、其中的煤矸石山面积、生产状况(生产矿山、停采矿山)、矿山开采方式(露天开采、地下开采)、矿产疑似违法图斑类型(无证开采、...)、主要矿山环境问题(次生地质灾害、景观破坏、...)和备注等内容。废弃矿山统计指标还包括是否是2006年以来责任主体灭失的关闭矿山。
相比于正在利用/废弃矿山统计侧重于按矿业许可证号以矿山为最小单元统计图斑,分县矿山统计按县行政区域统计下辖所有矿山图斑。分县矿山统计矩阵行按县代码顺序排列统计值,统计指标按矿山类型分为能源矿山、金属矿山、非金属矿山及所有非油气矿山。其中每一类矿山类型下又按生产矿山、停产矿山、疑似违法矿山、2006年以来灭失的矿山和其他关闭矿山进行细分,在每一类矿山细分状态下需要分别统计对应的矿山数量(按许可证号合并同矿山图斑计数)及面积。在每类矿山、县、省中要对应汇总分类统计值。
统计完成的矿山统计指标值,按现状/废弃矿山达到上千行,分县统计指标有50多列,是一个大型复合明细矩阵。
1.2 矿山遥感监测统计流程
传统的矿山遥感监测统计流程首先需要任务分工,单人完成某一县、矿山、属性分类的统计工作,最后再进行合并汇总。首先,用县代码、矿业许可证号筛选出目标图斑集合; 再用不同统计分类属性如占地方式、开采主体状态、矿种类型等,对照数据字典转换,筛选出目标统计图斑,提取计算图斑数量、面积、坐标等几何信息,合并统计值并汇入统计结果中; 然后开始下一项的统计; 最后,待个人分区统计完成后,再将不同统计结果合并汇总。人工统计的繁琐主要是体现在需要反复组合筛选图斑并计算。
自动化统计流程如图1所示,将统计过程一体化,通过一次性读入数据字典、源统计图斑文件和统计模板,利用数据流式过滤和多维矩阵计算方式,依次迭代统计正在利用矿山、废弃矿山、分县矿山指标,统计完成后会一次性按统计模板自动导出统计汇总结果。
图1
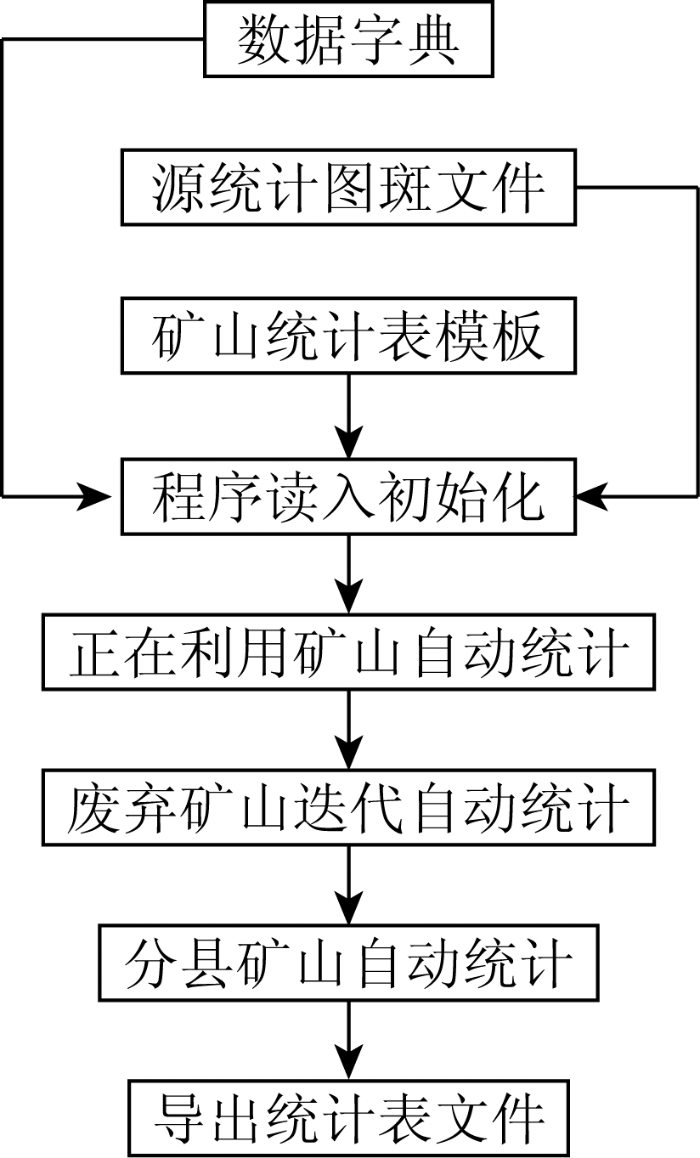
图1
矿山遥感监测自动统计流程
Fig.1
Mine remote sensing monitoring automatic statistical process
2 数据流式过滤和多维矩阵计算的自动统计方法
为了满足自动化流程,矿山遥感监测自动统计方法的实现包括2部分,分别是数据流式过滤统计方法和多维矩阵统计方法。
2.1 基于数据流式过滤的自动统计方法
“数据流式过滤”中“数据”指的是待统计的遥感监测图斑; “流式”指的是在不同尺度下数据嵌套、循环、迭代的过程中动态计算; “过滤”指的是针对不同指标计算要求,自动筛选对应符合要求的要素信息进行计算。数据流式过滤的自动统计方法适用于正在利用/废弃矿山信息的统计,按照从外到内嵌套3层逻辑迭代循环,分别是县迭代-矿山迭代-图斑迭代。子迭代从属于上层的过滤范围,依次完成统计数据流的过滤与统计值的计算,主要方法步骤如图2所示。
图2

图2
基于数据流式过滤的自动统计方法
Fig.2
Automatic statistical method based on data stream filtering
2.1.1 县迭代
读取源统计图斑矢量文件中所有不重复县信息,以县代码-县名称键值对形式按序放入有序字典,本文采用开源泛型集合库PowerCollections中的OrderedDictionary对象作为有序字典集合对象。
在迭代中,依次读出县信息,如果存在,新生成县代码和名称信息,生成自动序列号,县统计信息待后续县下属矿山信息统计完成迭代回归后,对应项合并汇总。如果县集合迭代完毕,合并计算所有县统计信息成省统计信息,并结束本类统计。
2.1.2 矿山迭代
正在利用矿山和废弃矿山统计数据过滤条件SQL Where条件分别为:
xdm = ‘?’ and ( KCZTZT = ‘A’ or KCZTZT = ‘B’ or KCZTZT = ‘C’ )
xdm = ‘?’ and ( KCZTZT = ‘D’ or KCZTZT = ‘E’ )
其中xdm代表县代码值(行政区划代码),KCZTZT(开采主体状态)代码A-E分别表示生产矿山、停采矿山、生产矿山、2006年以来责任主体灭失、其他关闭矿山。则在某县下,通过县代码和开采主体状态查询获取所有不重复矿山许可证号。
2.1.3 图斑迭代
用矿山迭代和矿山许可证号遍历过滤其下属所有图斑,即
xkz = ‘?’ and xdm = ‘?’ and ( KCZTZT= ‘A’ or KCZTZT = ‘B’ or KCZTZT = ‘C’ )
其中xkz代表许可证,依次提取图斑开发占地方式、坐标、开发类型、开采方式、主要环境问题、开发占地面积、违法面积等信息。更新图斑所属矿上、县、省汇总值。图斑迭代完毕,汇总上级矿山统计信息,迭代下一个矿山统计。
2.1.4 过滤统计图斑
图斑统计按照开发占地方式,将其面积值落入对应统计类别,其伪代码为:
if (kfzdfs == "10") cc += kfzdmj;
else if (kfzdfs == "2*") zz += kfzdmj;
else if (kfzdfs == "3*"){ fq += kfzdmj;
if (kfzdfs == "3C") mgs += kfzdmj; }
else if (kfzdfs == "40") jz += kfzdmj;
else if (kfzdfs.StartsWith("5")) tx += kfzdmj;
hj += kfzdmj;
属性值通过矿山开发占地分类代码字典表映射后分为5类进行筛选过滤(括号内为匹配代码值,*表示所有子类): 采场(10)、中转场地(2*)、固体废弃物(3*)、矿山建筑(40)、地下开采塌陷坑(5*)。其中固体废弃物包括子类煤矸石山(3C)。
2.2 基于多维矩阵计算的自动统计方法
“多维矩阵计算”中,“多维”指的是统计计算的矩阵总体是二维、局部是三维的混合,“矩阵”指的是将一组统计指标抽象为一个矩阵,进行批量计算,提高数据计算效率,达到快速、抽象、简化的效果。基于多维矩阵计算方法进行分县矿山信息统计,按照县迭代-图斑迭代-矿山分类映射-多维矩阵寻址计算的方式展开。
1)县和图斑迭代。方法类似数据流式过滤统计,县下不再分矿山,依次汇总分县统计信息,遍历完成合计省信息,退出分类统计。
2)矿山分类映射。矿产统计类型按能源、金属、非金属、非油气4项大类分别统计,每类下再按生产、停产、违法、关闭矿山等分别计算其数量、面积,共计2×6=12项。矿产类型根据地质矿产术语分类代码表有284项顺序放入List集合,根据顺序索引区间[1,10],[11,75],[76,284],[0,284]整体划分映射统计分类,总计4×12=48个统计指标。
3)多维矩阵寻址计算。分析分县统计值分布特征,使用二维数组dd[4][12]模拟统计矩阵(式1),一维索引代表矿产大类型,二维数组代表矿山状况下属统计值索引,其中矩阵奇数列为数量值,矩阵偶数列为面积统计值,即
式中: 矩阵行a,b,c,d分别代表矿产类型; 矩阵列索引0,2,4,6,8,10分别对应数量统计值,矩阵列1,3,5,7,9,11分别对应面积统计值。
根据此特点,可以将矿产类型索引归一化为0~3,将矿产主体开采状态A-E归一化为0~4,其伪代码为:
index = lKflx.IndexOf(kflx); iKflx = -1;
if (index < 0) iKflx = -1;
else if (index < 11) iKflx = 0;
else if (index < 76) iKflx = 1;
else if (index < 284) iKflx = 2;
这样通过这2个矩阵行列索引按比例系数放大,就能寻址到唯一统计值索引,根据矩阵列索引对2取余数判断统计值类型。通过此方法,在分县统计中,通过二维矩阵行列遍历循环统计矩阵,就能实时自动计算出分县所有统计值,其表达式为
式中: i为矿产类型索引; n为矿产类型数量; j为统计指标索引; m为统计指标数量; dd[i][2j](方括号内为二维数组索引值)为某矿产分类在某状态下的数量值; dd[i][2j+1]为面积值。分县矿产分类汇总值、其他统计值及全省汇总值寻址方法也是类似。
在统计数量值时,因为数量是按照矿山许可证号,而非图斑数计算,因此需要数列容器过滤重复许可证图斑。将矩阵dd中为奇数列(a0,a2,a4,a6,a8,a10,...... ,d10)的数值升级为变长数列L,即
式中x1,x2,...,xn分别为不重复许可证号。将L带入dd,这样dd局部升级为三维矩阵,通过此模拟二三维混合的多维统计矩阵,即
分县统计矩阵计算完毕,进行批量汇总,定义矿产分类汇总区间d[min,max],min和max分别对应区间d的上下限,index为区间d内索引值。将矩阵dd与对应区间d绑定,若d[index]%2=0则矩阵值为面积统计值,否则计算变长数列L的长度为数量统计值。根据统计要求度量单位的数值精度进行小数位截取和统计值格式化。全县合计和全省合计迭代计算方法同步进行。
3 实验与分析
3.1 程序实现
矿山自动统计方法的实验程序基础框架如图3所示,包括3部分。可以通过软件自动化计算方法实现“快速”统计。
图3

自动统计方法的基础框架环境为Visual Studio2010,.Net Framwork4.0,ArcGIS10.2和Excel2010。
1)底层组件。底层组件采用了ArcObjects和NPOI,通过ArcObjects可以方便地操作过滤矢量图斑、提取几何信息,实现数据的自动化流式过滤统计方法,在本方法中主要负责过滤计算数据图斑及数据字典的筛选。NPOI是一个开源的.Net读写MS Office的开源项目,是POI的移植版本,相比于MS Office自带的COM API,操作更为灵活,读写效率高且不需要安装庞大的安装包。NPOI可以将文档对象模型抽象为文档、表单、行、列、单元格、样式、单元值,而且支持方便的二维单元格寻址和函数链式操作,适合将多维矩阵计算统计方法结果快速映射回统计结果文件。底层组件引入这2个库,可以保证统计方法的自动化、轻量和低资源占用。
2)数据预处理。包括源统计图斑检查和数据字典自动生成2个方面。因为矿山统计对许可证、开采主体状态等关键信息有一致性要求,统计图斑的这些信息错误会导致统计结果的不可靠,统计前需要通过检查过滤数据,将不符合统计要求的图斑导出成检查记录表,返回给专业人员对照排查解译问题。数据字典是因为矿山统计中用到了大量标准规范中规定的字典编码,统计中为了减少字典映射的转换开销并提高统计的灵活性,提前将字典标准规范化处理成键值对的统一形式。数据字典自动生成的字典代码包括存在问题代码(无证勘查、越界勘查、擅自改变勘查对象等)、地质矿产术语分类代码(煤、油页岩、石油等)、经济类型代码(国有企业、集体企业、股份合作企业等)、开采方式代码(露天开采、地下开采等)、开采状态代码(正在开采、关闭或废弃、停采)、矿山开发占地分类代码、绿色矿山、土地利用现状分类(水田、水浇地、旱地等)、文件命名编码、用户ID特征项等。
3)自动统计。包括正在利用矿山统计、废弃矿山统计、分县统计、煤矸石统计等具体分项执行模块,这些统计流程可单项或者顺序组合运行。实验自动统计程序由4部分组成,分别是输入文件、可执行入口、依赖库和输出文件。输入文件包括字典库、待统计解译图斑文件夹和统计表模板。可执行入口为ConsoleApplication.exe,readme.txt为实验程序依赖环境及使用方法。NPOI.*.dll,PowerCollections.dll,ICSharpCode.SharpZipLib.dll为依赖库。check.txt为检查输出记录,new.xlsx为实验输出结果。自动统计步骤为: ①待统计数据拷入输入目录; ②运行可执行入口; ③查看输出结果。
3.2 实例分析
统计方法实验程序运行环境为笔记本windows 7×64系统,基础软件环境为ArcGIS 10.2和.Net 4.0,硬件参数为Intel Core I7-4500U 2.40 GHz 四核心、8.00 GB内存。以2018年青海省矿山遥感监测项目为例,使用本程序进行自动统计实验。将待统计数据630000KF01.shp拷入程序输入目录下,包括青海全省43个区县矿山遥感监测解译图斑共计4 506个,开始使用基于数据流式过滤和多维矩阵计算的统计方法进行实验分析。
1)通过矿山遥感监测自动统计实验程序中makeDic函数进行字典表自动构建。
2)检查数据一致性,矢量图斑文件应符合矿山遥感监测项目《本底数据更新遥感调查成果数据提交说明》矢量图层属性定义及字段要求。调用check函数进行源统计图斑检查,自动检查后输出记录发现存在10条问题图斑,返回给数据处理人员核查修改。
3)对修复后630000KF02.shp文件进行统计计算,生成自动统计结果。输入统计模板、源统计图斑,数据字典进行自动统计,基于数据流式过滤方法采用tj_xz函数进行正在利用矿山统计、tj_fq函数进行废弃矿山统计和tj_mgs函数进行煤矸石统计实验,基于多维矩阵计算采用tj_xian函数进行分县统计,使用tj函数将完整自动化统计流程串联运行。实验程序启动统计后cpu资源占用25%,内存占用500 MB,资源占用稳定。
4)输出统计结果。2018年青海省矿山遥感监测统计结果内容如图4所示,正在利用矿山统计统计出800项,废弃矿山统计出1 629项,分县矿山统计出50项,煤矸石山统计出68项。
图4

图4
矿山遥感监测正在利用矿山自动统计结果
Fig.4
Mine remote sensing monitoring automatic statistical results
统计实验程序运行耗时总计约10 min,人工统计需要耗时1周以上; 经过程序自动筛查和与人工统计指标对比,技术标准要求图斑坐标单位为度,小数点后保留6位,统计程序双精度浮点数保留11位; 面积单位为m2,小数点后面保留2位,统计程序面积采用坐标精度11位; 分县面积单位为hm2,小数点后面保留2位,统计程序使用面积单位m2,最后转换为hm2消除累计误差; 统计值互证与统计值与源数据对比,分县统计表的数据根据图斑面积单位m2的数据计算得出,保证与前面两张表数据一致,统计程序分县结果与现状、废弃表结果对照误差小于0.1 hm2,主要为输出小数位截取导致,实际程序内部精度完整保留; 经过核对标准规范,统计指标内容完整、统计分类正确、精度高于统计标准要求; 与统计模板和人工统计表对比,自动统计结果格式和样式符合要求。自动统计结果总体符合矿山遥感监测统计指标标准要求。
4 结论
本文研究并实现了一种矿山遥感监测自动统计方法,可以较好地满足目前矿山遥感监测对快速统计的需求。将计算机科学中的数据流式过滤与应用数学中的多维矩阵计算与空间统计问题相结合,针对矿山监测指标统计问题,提出了自动化快速统计方法,开发了实验程序验证了快速统计方法的可行性。本统计方法相比于现有的统计技术方法具有如下优点:
1)统计一体自动化。通过自动进行数据流式过滤,无需人工参与,快速迭代遍历成果数据,自动查找计算统计指标,自动合并汇总数值,一体化汇总最终统计结果。
2)统计运行效率高。通过多维矩阵计算方法,将复杂的统计指标抽象为数据矩阵,通过分析总结矩阵特征,归并计算统计值,在极短时间内就可以完成繁复的指标计算任务。
3)统计结果精度高。以往人工统计数值截取汇总后会产生累计误差,而本统计方法内部全部使用双精度浮点值进行计算,只在最后输出阶段按标准换算单位、截取数值长度,可以最大程度提高统计精度,避免人工累计误差。
4)统计方法灵活可扩展。本统计方法将统计指标、统计分类、数据字典都进行了抽象隔离,随着矿山遥感监测工作年度标准规范指标的调整,易于进行适配调整,按需扩展调整统计内容。
综上,本文提出的矿山遥感监测自动统计方法实用效果较高,具有较好的实用推广价值。尤其是基于数据流式过滤和多维矩阵的空间统计方法,也可适用于地理国情监测统计、第三次全国国土调查统计、不动产登记统计、农业/土地/水利确权等空间统计工作中,在自然资源和地理空间信息自动化统计研究中,可以进一步开拓研究思路。另外,今后仍需要针对不同地方监测数据差异,完善程序保护机制; 面对海量数据统计任务,优化计算效率; 针对其他平台集成需求,封装组件模块提供统计调用接口。
参考文献
矿山遥感监测评估特点与指标体系
[J].
Characteristics and index system of mine remote sensing monitoring and evaluation
[J].
空间统计学进展及其在经济地理研究中的应用
[J].
The progress of spatial statistics and its application in economic geography research
[J].
一种支持数据流条件过滤的批处理策略
[J].
A batch processing strategy supporting data flow condition filtering
[J].
一种XML数据流查询过滤算法
[D].
An XML Data Stream Query Filtering Algorithm
[D].
多维矩阵基本运算
[J].
Basic operations of multidimensional matrix
[J].
基于ArcGIS的矿山遥感监测成果编制系统
[J].
Architecture system of mine remote sensing monitoring based on ArcGIS
[J].
基于AE插件式矿山遥感监测成果数据质量检查系统
[J].
Data quality inspection system based on AE plug-in mine remote sensing monitoring results
[J].
矿山遥感监测解译记录表自动生成方法研究与实现
[J].
Research and implementation of automatic generation method of mine remote sensing monitoring interpretation record table
[J].
基于MapGIS和ArcGIS的遥感解译成果图件数据库设计与实现
[J].
Design and implementation of remote sensing interpretation results map database based on MapGIS and ArcGIS
[J].
面向遥感业务应用的解译成果数据管理系统研究和构建
[J].
Research and construction of data management system for interpretation results for remote sensing business applications
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}