

0 引言
图像语义分割是计算机视觉领域的一项关键技术,其目标是对图像的每个像素进行语义标注[1]。图像语义分割将图像分割和目标识别结合起来,同时解决目标边界识别和类别检测问题,能够满足图像中目标精细定位的需求,具有重要的应用价值。随着遥感技术的发展,遥感图像的空间分辨率不断提高,呈现的结构、纹理等细节信息更加清晰,地物边界和空间布局等上下文信息日益丰富,为图像语义分割提供了良好的数据条件; 同时遥感图像信息量巨大、数据复杂等特点也给图像语义分割带来了困难和挑战。
近年来,卷积神经网络(convolutional neural network, CNN)因避免了传统人工显式特征提取,能够自动从海量数据中获取特征,受到越来越多研究者们的关注[5,6,7,8,9]。图像语义分割方法也随之有了全新的发展,一系列语义分割方法相继提出: Long等[10]提出了全卷积神经网络(fully convolutional networks, FCN),用卷积层替换CNN网络结构中的全连接层,实现了端到端的像素级分类; Sherrah等[11]采用无下采样层的FCN模型版本对航空遥感图像进行了语义标注; Badrinarayanan等[12]提出基于编码-解码结构的SegNet模型,通过将编码过程中最大池化操作的像素索引传输到解码器中,保留了部分细节信息,在一定程度上改善了分割精度; Ronneberger等[13]提出了U-Net网络模型,通过跳跃连接融合解码信息与对应的编码信息,成功应用到医学影像语义分割中。然而,上述方法由于没有考虑到像素与像素之间的上下文关联,分割结果缺乏语义的空间一致性。为引入上下文信息,进一步优化语义分割效果,条件随机场(conditional random field, CRF)被引入到CNN模型框架中。Chen等[14]提出了DeepLab模型,在FCN后接全连接CRF,对结果进行平滑约束,增加了区域一致性和连续性,克服了定位精度问题; Zheng等[15]提出了CRFasRNN模型,将CRF的学习推理过程嵌入CNN架构中,通过反向传播算法对整个深度网络进行端到端的训练,避免了后处理,但其位置信息精度不如DeepLab模型。由于CNN中的逐层池化操作,细节信息在网络的浅层到深层的传播过程中不断衰减,最终的图像语义分割精度有待提升。
在前人工作基础上,本文提出了一种深度卷积融合条件随机场(deep fusion convolutional networks and conditional random field, DFN-CRF)的遥感图像语义分割方法。首先,在FCN框架中加入反卷积融合结构; 同时,将CRF的求解过程以迭代层的形式融合到深层网络架构中,搭建DFN-CRF模型; 最后,在模型训练的过程中结合图像中丰富的细节信息和上下文信息,实现端到端的图像语义分割。方法不仅利用FCN自动提取深度语义特征的优势,提升了模型泛化能力; 而且通过反卷积融合结构引入多尺度特征,将浅层细节信息和深层语义信息结合起来做模型预测,有效地提高模型的处理精度。同时,利用CRF引入上下文信息,可以更好地定位地物,进一步提升模型的处理效果。另外,端到端的网络模型缩减了人工预处理和后续处理,模型可以根据数据优化参数,提高模型的契合度。
1 方法概述
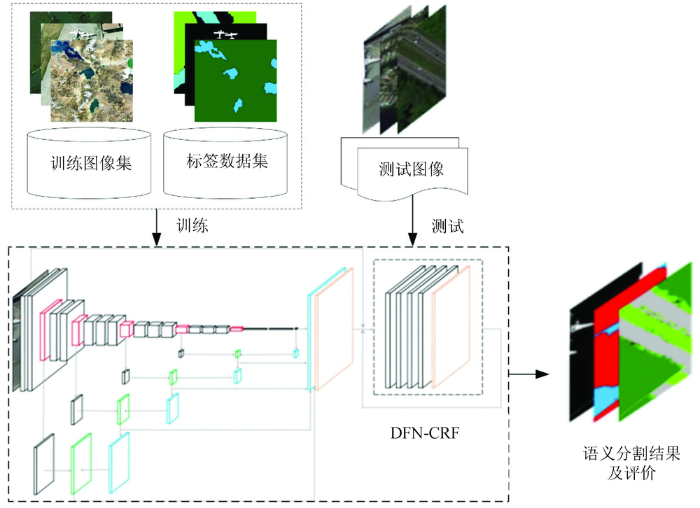
本文的遥感图像语义分割处理流程(图1)包括模型训练和测试2个阶段。在模型训练阶段,首先通过反卷积融合结构将高层语义信息和浅层细节信息相结合,同时在深度网络模型中以迭代层的形式融入全连接条件随机场,进而引入上下文信息,构建DFN-CRF网络模型; 然后利用随机梯度下降法进行模型参数学习,完成网络模型的训练。在测试阶段,即利用训练阶段得到的模型对待处理的遥感图像中的像素进行标记推断,最终实现端到端的遥感图像语义分割。
图1
1.1 FCN
FCN基本结构主要由输入层、卷积层、池化层和输出层组成。
1)输入层。读取数据为h×g×d的d维数组,其中h和g为数据尺寸,d为特征或通道数。本文输入图像的尺寸为224×224×3。
2)卷积层。用于提取局部特征,又称特征提取层。通过一组滤波器(卷积核)对输入的数据进行卷积,然后将卷积结果传递给非线性激活函数。本文采用的激活函数为修正线性单元(rectified linear units,ReLU),函数定义为:
3)池化层。用于进行非线性降采样,通过对卷积特征进行降维,保留有用信息的同时减少计算复杂度,加快网络训练速度。常用的池化有最大池化和平均池化。本文采用最大池化方法。
4)输出层。通过Softmax分类器输出每个像素点属于各语义类别的概率,并选择最大概率值所对应的类别结果作为最终输出。Softmax函数的公式定义为:
式中:
1.2 反卷积融合结构
借助多层网络架构,CNN能够从输入图像自动获取到多层特征: 浅层感知域较小,可以得到局部区域的细节信息; 深层感知域大,能够得到更加抽象的语义信息。然而,CNN中的逐层池化,不仅使得细节信息在网络的浅层到深层的传播过程中不断衰减,也不断缩小了图像尺寸。因此,本文方法采用反卷积融合结构结合浅层细节信息和深层语义信息来实现像素级图像语义标注。
反卷积融合结构主要由卷积层、反卷积层和融合层组成,其中融合层是将来自不同层的结果求和后输出。反卷积操作本质上也是卷积操作,区别在于卷积实现下采样,反卷积操作是完成上采样。以Caffe框架中的反卷积操作为例,卷积操作的前向和反向传播过程,前向传播过程为:
式中:
式中:
式中Loss为损失函数。所以反卷积操作就是正向传播时左乘
1.3 CRF模型
式中: Z为归一化常数; C为所有基团
满足最大后验概率的标注向量
模型的能量函数为:
式中: ψ1(xi)为一阶势函数,描述单像素点观测信息与其相应标记之间的关系; Ni为像素i的邻域位置集合; ψ2(xi, xj)为二阶势函数,描述像素之间的关系,鼓励相似的像素分配相同的标签,相差较大的像素分配不同的标签。具体采用的Gibbs能量函数为:
式中: μ(xi,xj)为判别函数,若xi≠xj,则μ(xi,xj)=1,否则为0;
采用平均场算法[18]来实现模型参数推断,通过最小化KL距离D(QP),以近似分布Q(X)代替精确分布P(X),即
最小化过程的迭代计算公式为:
式中Zi为归一化常数。
迭代过程可分为5个步骤: ①“消息传递”
本文方法将CRF模型以循环神经网络(recurrent neural networks,RNN)迭代层的形式加入到网络模型中,RNN迭代层包括4个卷积层和1个Softmax输出层。“消息传递”和“滤波结果求加权和”相当于卷积操作; “兼容性转换”和“一元项加入”都相当于使用1×1的卷积核对全图进行卷积操作; “类别概率归一化”相当于使用Softmax分类器,然后迭代求解条件随机场模型的参数。
1.4 DFN-CRF网络结构
本文方法在FCN中加入反卷积融合结构,并以RNN迭代层的形式引入将CRF模型参数推断过程,搭建DFN-CRF模型,在模型训练过程中同时利用细节信息和上下文信息。网络模型的网络结构参数如图2所示,各层旁边标注为卷积(或池化、反卷积)核大小以及核个数。输入图像为256×256的三通道图像,卷积层3×3×64表示使用64个尺寸为3×3卷积核的卷积层,池化层为使用尺寸为2×2卷积核的最大池化层,反卷积层4×4×21表示使用21个尺寸为4×4卷积核的反卷积层。
图2
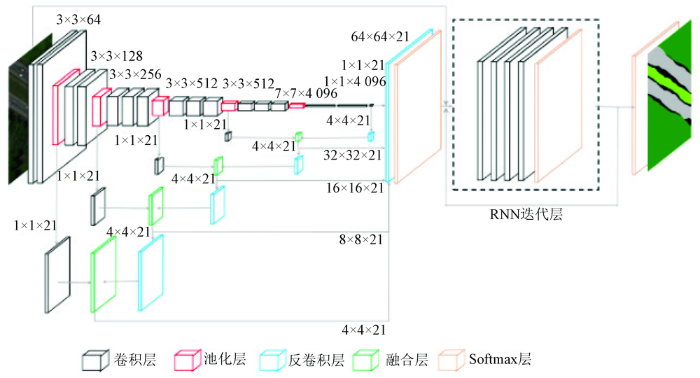
FCN模型最终的卷积层结果只有最后一层池化层的信息,仅对这一结果进行反卷积操作的模型记为DFN-CRF-5。根据融合层级的不同,将融合池化层深度到pool4,pool3,pool2,pool1的模型,分别记为DFN-CRF-4,DFN-CRF-3,DFN-CRF-2,DFN-CRF-1。以DFN-CRF-4为例,反卷积融合结构将最后卷积层的结果反卷积到pool4层输出结果尺寸,与pool4层卷积后结果通过融合层输出,再将融合层结果反卷积到输入图像尺寸,得到最终的像素级图像语义分割结果。模型DFN-CRF-3将DFN-CRF-4中融合层结果反卷积到pool3层输出结果尺寸,与pool3层卷积后结果通过融合层输出,再将融合层结果反卷积到输入图像尺寸,模型DFN-CRF-2和DFN-CRF-1以此类推。
2 实验与结果
2.1 实验数据与评价准则
模型训练及测试数据来自公开的遥感数据集NWPU[19],包含R,G,B 3个波段数据。NWPU数据集在视角、对象姿势、空间分辨率、光照、阴影等方面都有丰富的变化,具有较高的类内多样性,能够很好地检验语义分割方法的可靠性。模型泛化能力验证部分的实验数据采用来自UC Merced Land-Use[20]数据集的遥感图像。选取20种遥感地物语义类别进行实验,分别为: 飞机、菱形棒球场、灌木丛、圆形农田、密集住宅区、沙漠、森林、高速公路、高尔夫球场、湖泊、草地、中等密集住宅区、山、停车场、矩形农田、河流、海冰、稀疏住宅区、梯田、湿地。模型训练及测试数据集每类700张图像; 模型泛化能力验证数据集每类100张图像。
实验平台服务器处理器为Intel Xeon(R) CPU E5-2620 2.00GHz,显卡为NVIDIA GeForce GTX TITAN X,采用Python 2.7.13与Matlab R2016b混合编程。网络模型随机选取数据集中的12 000张遥感图像进行训练,其余作为测试图像。各网络的训练参数设置为: 学习率固定为1×10-14,动量设置为0.99,权重衰减参数为0.000 5,采用随机梯度下降法进行网络训练,反卷积层权重初始化采用双线性插值法。
本文从定性和定量2个方面对图像语义分割结果进行评价。定性评价主要从直观感觉如分割边缘是否明确、轮廓是否清晰等方面进行评估; 定量评价主要采用像素平均精度(per pixel accuracy, PA)、类别平均精度(mean class accuracy, CA)以及平均像素交叠率(mean intersection over union, MIOU)3个指标[21],具体计算方法为:
式中: nc为数据集语义类别数; nij为类别i被预测为类别j的像素总数。
2.2 细节信息影响分析
为了分析细节信息对遥感图像语义分割结果的影响,本文对融合不同深度信息的网络模型进行了对比实验。细节信息的融合尺度由少到多,分别是DFN-CRF-5,DFN-CRF-4,DFN-CRF-3,DFN-CRF-2和DFN-CRF-1。各模型迭代50 000次的训练时间及一幅图像平均测试时间如表1所示。
表1 各模型训练及测试时间
Tab.1
| 模型 | 训练时间/min | 测试时间/s |
|---|---|---|
| DFN-CRF-5 | 474 | 0.61 |
| DFN-CRF-4 | 5 013 | 0.69 |
| DFN-CRF-3 | 5 237 | 0.73 |
| DFN-CRF-2 | 5 589 | 0.74 |
| DFN-CRF-1 | 5 976 | 0.77 |
采用不同层级融合结构的DFN-CRF模型进行遥感图像语义分割,结果如表2所示。其中,白色为飞机,灰色为公路,绿色为草地,黑色为背景。从表2中可以看出,DFN-CRF-5的语义分割结果非常粗糙,无法识别出遥感图像中具有固定形状的类别,存在多处语义分割错误(结果图中基本看不出飞机轮廓、高速公路边缘,与标签图像不符)。DFN-CRF-4模型通过融合结构引入了pool4层尺度的细节信息进行模型训练,相较于DFN-CRF -5模型其语义分割结果明显有所提升(结果图中飞机形状渐显、高速公路的轮廓逐渐清晰)。DFN-CRF-3模型在DFN-CRF-4基础上结合pool3尺度的细节信息进行语义分割,其结果已可以清楚地识别出飞机,高速公路间的背景类别被逐渐识别出来,边缘更细化。DFN-CRF-2和DFN-CRF-1模型各自又在前一个模型的基础上融合了pool2层和pool1层尺度的细节信息,从结果中可以看出相较之前模型的语义分割结果,DFN-CRF-2和DFN-CRF-1的语义分割结果主要改善了各语义类别的细小部分,使其边缘更加精细、轮廓更清晰、更接近标签图像(如飞机类别的尾部更细化、左下角飞机尾部与机身逐渐连接,高速公路间背景类别被误语义分割为草地类别的部分减少)。
表2 采用不同层级融合结构的DFN-CRF模型语义分割结果对比
Tab.2
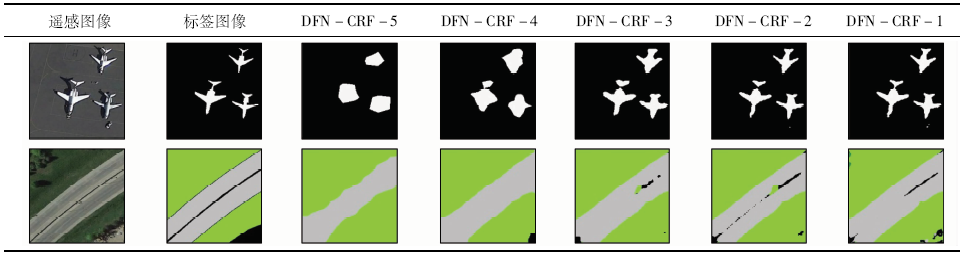 |
进一步通过定量评价进行结果分析,各模型语义分割精度如表3所示。可知,从DFN-CRF-5到DFN-CRF-1,PA值,CA值和MIOU值都逐渐增加,分别提高了1.10,4.48和5.08百分点,与定性评价结果一致。
表3 各模型语义分割结果定量评价
Tab.3
| 模型 | PA | CA | MIOU |
|---|---|---|---|
| DFN-CRF-5 | 0.908 990 | 0.855 277 | 0.768 730 |
| DFN-CRF-4 | 0.910 455 | 0.878 851 | 0.799 701 |
| DFN-CRF-3 | 0.918 773 | 0.897 060 | 0.809 149 |
| DFN-CRF-2 | 0.918 969 | 0.898 627 | 0.816 557 |
| DFN-CRF-1 | 0.919 967 | 0.900 086 | 0.819 535 |
2.3 上下文信息影响分析
表4 DFN-1和DFN-CRF-1语义分割结果定量评价
Tab.4
| 模型 | 训练时间/min | PA | CA | MIOU |
|---|---|---|---|---|
| DFN-1 | 5 749 | 0.912 465 | 0.883 090 | 0.811 262 |
| DFN-CRF-1 | 5 976 | 0.919 967 | 0.900 086 | 0.819 535 |
图3
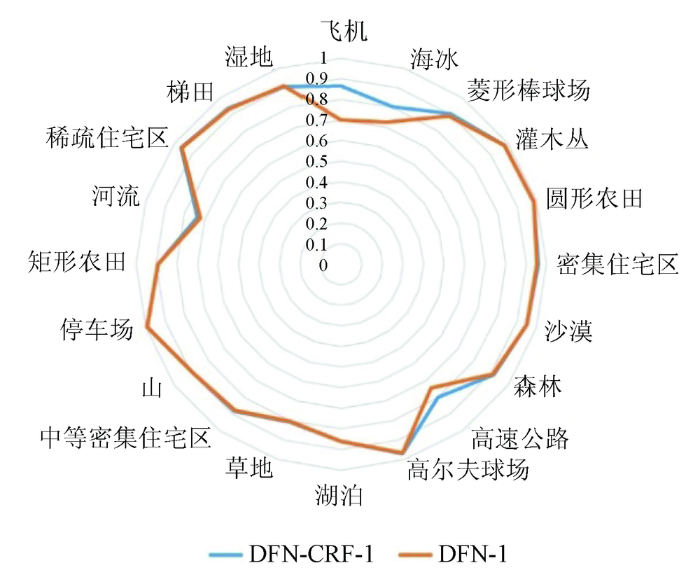
图3
DFN-1和DFN-CRF-1地物类别PA对比
Fig.3
PA contrast diagram of different model’s results between DFN-1 and DFN-CRF-1
从表4中可看出,DFN-1模型语义分割结果的定量评价低于DFN-CRF-1,这是因为DFN-1模型没有加入上下文信息,缺乏对结构、边缘等空间上下文信息的约束; DFN-CRF-1模型相比DFN-1模型在语义分割结果定性和定量评价中都有所提升,因为方法通过全连接条件随机场的高斯二阶势函数引入了图像中丰富的上下文信息,从而增加了对结构、边缘等空间信息的约束。DFN-CRF-1较DFN-1模型,PA值提高了0.75百分点左右,CA值提高了1.70百分点左右,MIOU值提高了0.83百分点左右。从图3中可以看出,上下文信息的引入对不同地物类别的优化效果不同,对细节信息丰富、结构边缘明显的地物类别(如飞机、高速公路等类别)的影响较为明显。
2.4 对比实验
将本文方法与目前常用的基于CNN的FCN8s,DeepLab,CRFasRNN等语义分割模型进行了对比实验,训练集和测试集保持一致,实验结果如表5所示。可以看出,DeepLab模型的训练时间最短,但精度最低; 本文方法相比FCN8s和CRFasRNN模型训练时间虽然略长,但其MIOU值分别比其他3个模型提高了3.61百分点,2.15百分点和1.43百分点左右。说明通过反卷积融合结构和RNN迭代层在模型训练的过程中同时融入细节信息和空间上下文信息,有效提高了遥感图像语义分割的精度。
表5 本文方法与其他方法结果对比
Tab.5
| 模型 | 训练时间/min | MIOU |
|---|---|---|
| DeepLab | 1 692 | 0.783 401 |
| CRFasRNN | 4 853 | 0.798 024 |
| FCN8s | 4 917 | 0.805 267 |
| DFN-CRF-1 | 5 976 | 0.819 535 |
2.5 泛化能力验证实验
为了验证DFN-CRF-1模型的泛化能力,本文在UC Merced Land-Use数据集上进行了语义分割实验,实验结果如图4所示。从图中可以看出DFN-CRF-1模型能够较好地将河流、飞机、高速公路等地物从遥感图像中分割出来,并一定程度上保留其边缘、轮廓,保持了语义对象的内部一致性。总体来看,对数据来源不同于模型训练数据的遥感图像,本文方法也能够较好地实现图像语义分割,模型泛化能力较强。
图4-1

图4-1
UC Merced Land-Use数据集实验结果
Fig.4-1
Experimental results of UC Merced Land-Use dataset
图4-2
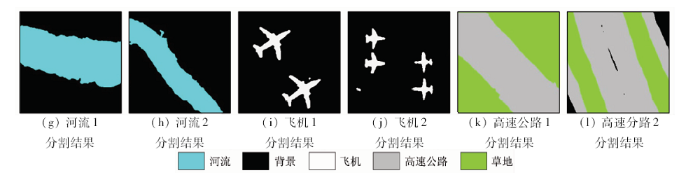
图4-2
UC Merced Land-Use数据集实验结果
Fig.4-2
Experimental results of UC Merced Land-Use dataset
3 结论
本文提出了一种DFN-CRF语义分割方法,在FCN基础上加入反卷积融合结构,同时将CRF的参数推断过程以RNN迭代层的形式嵌入整个网络框架中,构建了端到端的DFN-CRF模型。通过对模型的实验与评价,得到如下结论:
1)采用的反卷积融合结构,能够融合多尺度特征,将浅层细节信息和深层语义信息结合起来做模型预测,有效地提高了模型的处理精度。
2)嵌入式的CRF模型不仅能够引入上下文信息,更准确地定位地物,进一步提升模型的处理效果,而且端到端的网络处理架构,可以避免后处理,简化训练过程。
3)对比实验表明,随着融合结构结合池化层深度的增加,语义分割结果轮廓更清晰,边缘更细化,处理精度逐渐提高; 空间上下文信息的引入有效提升了语义分割的精度,较好地保持了语义对象内部区域的一致性。
参考文献
基于DCNN的图像语义分割综述
[J].
A review on image semantic segmentation based on DCNN
[J].
语义对象分割方法研究
[D].
Research on segmentation of semantic objects
[D].
基于纹元森林和显著性先验的弱监督图像语义分割方法
[J].
Weakly supervised semantic segmentation based on semantic texton forest and saliency prior
[J].
Detail-preserving smoothing classifier based on conditional random fields for high spatial resolution remote sensing imagery
[J].
卷积神经网络特征在遥感图像配准中的应用
[J].
Application of convolutional neural network feature to remote sensing image registration
[J].
Hyperspectral images classification with convolutional neural network and textural feature using limited training samples
[J].DOI:10.1080/2150704X.2019.1569274 URL [本文引用: 1]
基于CNN模型的遥感图像复杂场景分类
[J].
Complex scene classification of remote sensing images based on CNN
[J].
Fusion of images and point clouds for the semantic segmentation of large-scale 3D scenes based on deep learning
[J].DOI:10.1016/j.isprsjprs.2018.04.022 URL [本文引用: 1]
Semantic segmentation of small objects and modeling of uncertainty in urban remote sensing images using deep convolutional neural networks
[C]//
Fully convolutional networks for semantic segmentation
[C]//
Fully convolutional networks for dense semantic labelling of high-resolution aerial imagery
[EB/OL].(
SegNet:A deep convolutional encoder-decoder architecture for robust semantic pixel-wise labelling
[J].
U-Net:Convolutional networks for biomedical image segmentation
[C]//
DeepLab:semantic image segmentation with deep convolutional nets,atrous convolution,and fully connected CRFs
[J].
DOI:10.1109/TPAMI.2017.2699184
URL
PMID:28463186
[本文引用: 1]

In this work we address the task of semantic image segmentation with Deep Learning and make three main contributions that are experimentally shown to have substantial practical merit. First, we highlight convolution with upsampled filters, or 'atrous convolution', as a powerful tool in dense prediction tasks. Atrous convolution allows us to explicitly control the resolution at which feature responses are computed within Deep Convolutional Neural Networks. It also allows us to effectively enlarge the field of view of filters to incorporate larger context without increasing the number of parameters or the amount of computation. Second, we propose atrous spatial pyramid pooling (ASPP) to robustly segment objects at multiple scales. ASPP probes an incoming convolutional feature layer with filters at multiple sampling rates and effective fields-of-views, thus capturing objects as well as image context at multiple scales. Third, we improve the localization of object boundaries by combining methods from DCNNs and probabilistic graphical models. The commonly deployed combination of max-pooling and downsampling in DCNNs achieves invariance but has a toll on localization accuracy. We overcome this by combining the responses at the final DCNN layer with a fully connected Conditional Random Field (CRF), which is shown both qualitatively and quantitatively to improve localization performance. Our proposed
Conditional random fields as recurrent neural networks
[C]//
Conditional random fields:Probabilistic models for segmenting and labeling sequence data
[C]//
Markov fields on finite graphs and lattices
[EB/OL].[
Efficient inference in fully connected CRFs with gaussian edge potentials
[C]//
Remote sensing image scene classification:benchmark and state of the art
[C]//
Bag-of-visual-words and spatial extensions for land-use classification
[C]//

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}