

0 引言
随着遥感技术的发展,遥感影像在土地资源管理、城市管理和国防方面中得到广泛应用。遥感影像分类是遥感应用的关键基础技术之一,该技术主要利用计算机以自动或半自动方式从影像中分类识别地物信息,分类图既可为目标识别等提供辅助判别信息,也可用于生产和更新土地利用类型图,已成为遥感技术应用的关键基础技术之一[1]。
相比中低空间分辨率遥感影像,高空间分辨率遥感影像(以下简称“高分遥感影像”)能反映出更丰富的地物细节和语义信息[2],但同时带来了“同谱异物”和“同物异谱”问题,具体表现为不同语义类别中的场景具有相同的对象构成,而同类中的场景具有不同的分辨率和地物空间分布,这种类间差异小和类内差异大的特点,使传统的基于像素和基于对象的遥感图像分类方法易出现过多的错分和漏分现象,导致分类精度偏低。近年来,基于场景的影像分类技术已成为高分影像分类的研究热点[3]。依据影像特征层次,基于场景的高分遥感影像分类方法可分为3类: ①基于低层视觉特征的方法。使用各种特征算子从高分遥感影像的低级视觉属性(如颜色、纹理、光谱值)中提取特征来描述图像[4],如颜色直方图(color histogram,CH)[5]、Gist描述子[6]、局部二值模式(local binary patterns,LBP)[7]和尺度不变特征变换方法(scale invariant feature transform,SIFT)[8],这类方法对空间分布和结构模式均匀的高分遥感影像有较好的分类效果,但对空间分布不均匀的场景效果不佳。②基于中层视觉表示的方法。对高分遥感图像的低层局部视觉特征进行编码形成场景图像的全局特征表示,常用的编码模型有: 视觉词袋(bag of words,BoVW)[9]、空间金字塔匹配(spatial pyramid matching,SPM)[10]、局部约束线性编码(locality-constrained linear coding,LLC)[11]、概率潜在语义分析(probabilistic latent semantic analysis,pLSA)[12]、改进的Fisher核(improved Fisher kernel,IFK)[13]、局部聚集描述符向量(vector of locally aggregated descriptors,VLAD)[14]等,与基于低层视觉特征的方法相比,基于中层视觉表示的方法的分类精度有大幅提高,但仍受低层视觉特征和编码方法的限制,不能达到最优的分类精度。③基于高级语义特征的方法。深度学习的发展为高分遥感影像场景分类提供了新的思路,深度学习可以学习到更抽象、更具辨别性的特征,卷积神经网络(convolutional neural networks,CNN)由于大量的训练标记数据和连续多层卷积过程,已被广泛应用于计算机视觉任务中[15,16,17,18],AlexNet[19],CaffeNet[20],VGGNet[21],GoogLeNe[22]及ResNet[23]等深层网络结构的相继出现,在图像分类任务上效果超群。
1 原理与方法
1.1 Inception-V3模型及其改进
Inception模型由Szegedy等[26]在2015年提出(图1,其中,input_d和output_d分别为输入维数和输出维数,stride为步长。),Inception模型通过改进神经网络结构,将原始大卷积核分解为有同等运算的小卷积核,进行非对称卷积的空间分解,并结合使用辅助滤波器,同时模型进一步降低特征图的大小,在更有效地保留图像特征的同时减少计算量。Inception-V3总共有2 000多万参数量,对于这类网络,过拟合是一个很严重的问题。Dropout和BN(图2)是目前2种广泛使用的降低过拟合现象的方法。Dropout指在神经网络中通过随机丢弃一个或多个神经元,暂时把该神经元从神经网络中移除,使网络变得更为稀薄紧凑,更容易预测输出。BN是指通过减小神经网络内部的协方差偏移而提高深度神经网络训练速度的方法[27]。
图1
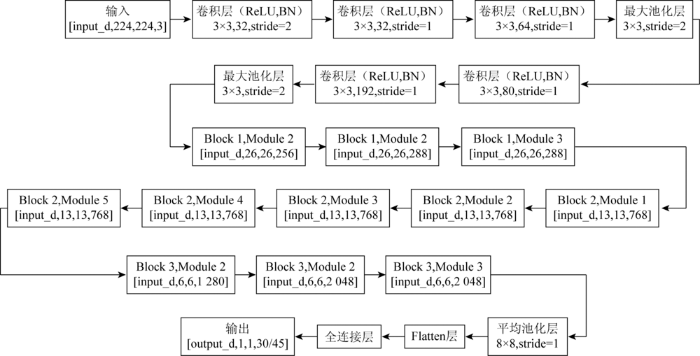
图2
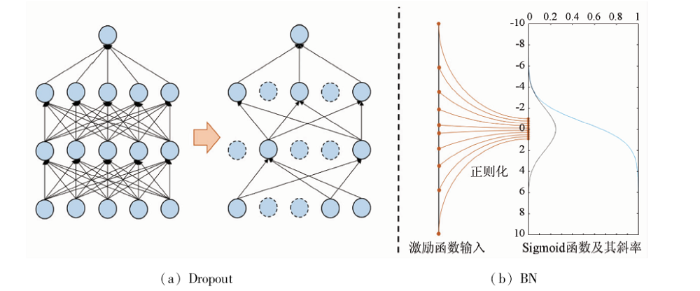
原始的Inception-V3通过使用BN来降低过拟合的发生,同时提高训练速度。针对遥感数据标记样本少,标记成本高的问题,本文进一步在输出层Softmax分类器前添加Dropout运算,与卷积层的BN运算结合,以改进原始的Inception-V3网络。本文在最后一层全连接层前添加Dropout结构,在避免BN与Dropout简单结合导致方差偏移问题的同时,可以进一步降低CNN的过拟合现象。
1.2 基于迁移学习的遥感图像场景分类
传统的深度学习方法假设训练数据和测试数据输入特征和分布分别相同,而在实际应用中,获取与测试数据有相同特征空间和分布的训练数据十分困难。迁移学习通过模型与参数迁移的方式解决了少量标记样本的训练问题,提高了模型学习的效率。
迁移学习通过从相关领域(源域)传输信息来提高一个领域(目标域)的学习训练效率,可以有效地解决信息孤岛问题。利用深层神经网络和图像网络数据集的强大功能,可将适用于大数据量的自然图像处理模型中学习到的知识转移到适用于小数据量的高分遥感影像领域,实现个性化迁移。设源域为
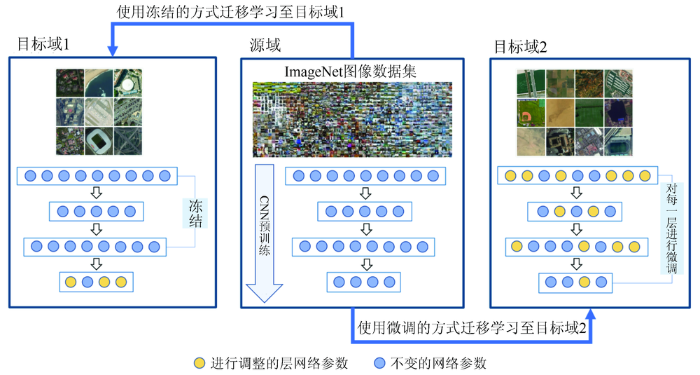
对于CNN来说,使用迁移学习有2种策略: 冻结和微调。这2种策略如图3所示,其中,黄色圆圈表示进行调整的层网络参数,蓝色圆圈表示不变的网络参数。微调首先利用预训练后的模型得到的训练参数对目标网络进行初始化,然后利用目标数据进行训练。冻结是指冻结某些层,即保持某些层的权重不变,并训练其余层。
图3
1.3 基于改进的Inception-V3的高分遥感影像场景分类
随着影像分辨率的提高,高分遥感影像与自然光学影像在光谱、纹理和空间特征方面越来越接近。由于深度学习网络的前几层是用于获取影像的局部特征[28],本文将基于ImageNet大型自然影像集上预训练好的Inception-V3的前3层网络参数进行冻结迁移,对后面的网络层的权值参数进行训练微调。改进的Inception-V3的最后一层全连接层是在新增加的Dropout之后,因此需要进行重新训练,迁移过程如图4。同时,考虑到是在2个数据集上实验,首先将ImageNet中训练好的模型参数迁移至数据量较小、类别较少的Aerial Images Datasets(下文简称AID)遥感数据集进行微调训练,再将AID上的训练好的参数迁移至数据量更大的Remote Sens-ing Image Scene Classification(下文简称NWPU-RESISC45)遥感数据集。
图4
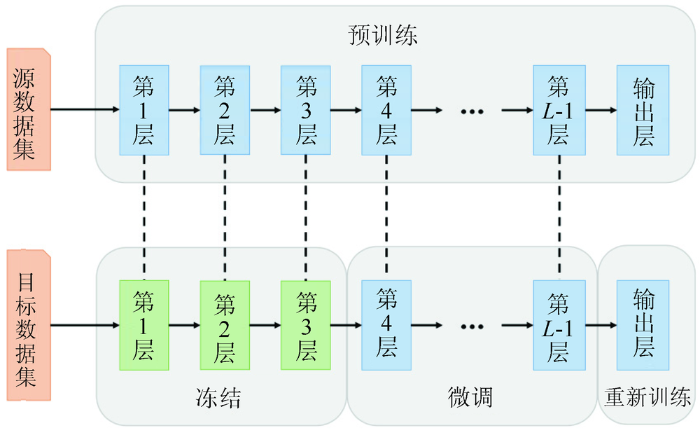
本文的分类流程如图5所示,第一阶段,将对ImageNet数据集上预训练好的Inception-V3进行结构改进,表示为Inception-L1网络,而后迁移至高分场景数据集上训练微调,将微调后的Inception-L1网络用于提取高分场景影像的特征向量。这一阶段充分利用知识迁移,使用在ImageNet上的预训练权值作为初始值进行微调,与随机设置初始值相比,训练时间大幅缩短。接着,将提取的特征输入全连接神经网络,由于微调后的Inception-L1网络可学习获取到场景图像的更抽象、更易分类的特征,使用Softmax全连接神经网络,经高分遥感影像数据训练后即可得到最终分类结果。
图5
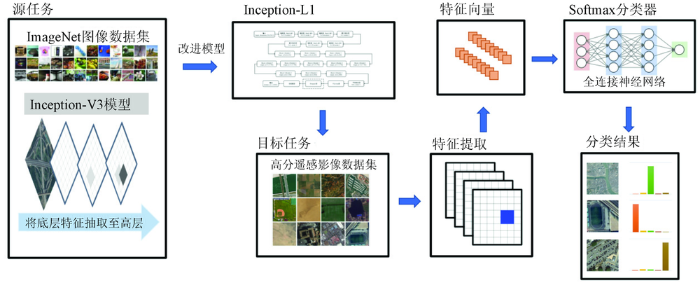
图5
高分遥感影像场景分类流程
Fig.5
Flow chart of scene classification for high-resolution remote sensing images
2 高分遥感影像场景分类实验
2.1 实验数据集
AID数据集是武汉大学2016年发布的大型高分遥感场景数据集。该数据集共有30个类别10 000张影像。影像主要从Google Earth影像上采集。场景影像的空间分辨率为0.5~8 m,影像大小为600×600像素,每类有220~420张不等数量的影像。
NWPU-RESISC45数据集是由西北工业大学于2016年发布的高分遥感影像场景分类数据集。数据集共有45个场景类别,共31 500张场景图像,每个场景类别包含700张256×256像素的图像,空间分辨率在0.2~30 m之间。
2.2 实验评价指标
本文使用Tensorflow1.2实现Inception-V3(以下简称为“Inception”)和改进的Inception-V3模型(以下简称为“Inception-L1”),并在百度云深度学习平台测试运行,平台环境为40 GB内存和Nvidia K40。实验使用4个指标进行性能评估: 训练精度(train_accuracy)、测试精度(test_accuracy)、训练损失(train_loss)、测试损失(test_loss)。
1)训练精度。训练集的分类准确度,训练精度的计算公式为:
式中:
2)测试精度。测试集的分类准确度,测试精度的计算公式为:
式中:
3)训练损失。训练集的交叉熵损失值,训练模型通过考察有标签样本的测试值与真实值之间的偏差。通常情况,随着模型的收敛,训练损失将趋近于0。训练损失的计算公式为:
式中:
4)测试损失。测试集的交叉熵损失值,深度学习算法的目的是最大限度地减少模型的损失,所以数据集的测试损失越小,表明网络模型的拟合效果越好; 反之,数据集的测试损失越大,则表明网络模型的分类效果越差。训练损失的计算公式为:
式中:
此外,实验使用Adam算法更新Inception参数,用式(5)计算损失值,初始学习速率设为0.2,即
式中: lr为学习率; factor为学习率的衰减因子,下限设置为0。训练集的批大小设置为64,epochs编号设置为30。AID和NWPU-RESISC45数据集对每一类别场景按20%和80%的比例构建训练集和测试集。
2.3 实验结果分析
2.3.1 不同数据集上的训练情况对比
图6为Inception和Inception-L1在AID数据集上的训练情况,图中Inception的train_loss和test_loss指标情况分别用蓝色和绿色实线表示,Inception-L1的train_loss和test_loss指标情况分别用黄色和红色虚线表示。由图6(a)可知,在训练初期,由于Inception处于欠拟合的状态,train_loss和test_loss值较高,但随着epochs的增加,train_loss值不断下降,test_loss值在训练过程中偶尔出现波动,但是约在第9个epochs之后,train_loss和test_loss值趋于稳定,参数基本收敛。从图6(b)中可知,Inception训练初期,由于梯度下降可能会落在非最优解的局部最小值上,test_accuracy在初期的迭代会出现波动情况,但在第13个epochs后,train_accuracy和test_accuracy均趋于稳定,达到了最高的分类精度。对于Inception-L1,对比图6(a)和(b)可知,无论是在训练集和测试集,Inception-L1中的loss和accuracy的波动程度相对Inception都有明显改善,均在第8个epochs后趋于稳定。同时,根据图6(b)的绿色实线和红色虚线的对比可知Inception-L1的test_accuracy略高于Inception。可知,虽然Inception-L1的待训练参数减少,仍能够很好地提取高分场景影像的高层次特征,从而提升了高分场景影像的分类精度。同时,由于Dropout的应用,在小训练样本的前提下,Inception-L1能有效降低过拟合的同时,提高了训练速度,降低了训练难度。
图6
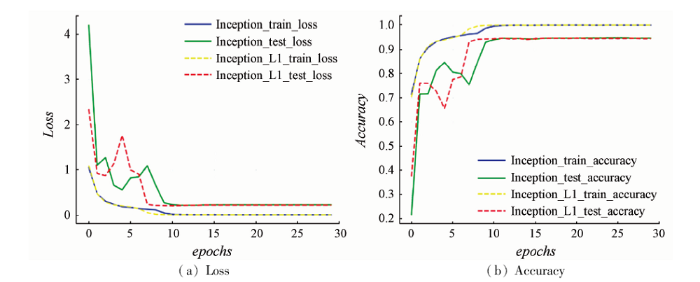
图6
Inception和Inception-L1在AID数据集上的训练情况
Fig.6
Inception and Inception-L1 training on AID datasets
类似地,图7为Inception和Inception-L1在NWPU-RESISC45数据集的训练情况。
图7
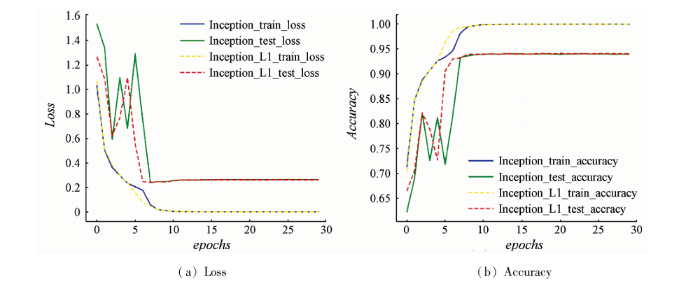
图7
Inception和Inception-L1在NWPU-RESISC45数据集上的训练情况
Fig.7
Inception and Inception-L1 training on NWPU-RESISC45 datasets
对比图7(a)和(b)可知,在NWPU-RESISC45数据集上,Inception-L1的loss和accuracy的波动程度较原始的Inception模型也有改善,其收敛也更快,即训练更为稳定。此外,由于NWPU-RESISC45较AID数据集场景数据量更大,在训练初期,由于梯度下降可能会落在非最优解的局部最小值上,Inception-L1的test_accuracy在初期的迭代出现轻微波动情况,但在第7个epochs后,train_accuracy和test_accuracy均趋于稳定,收敛迭代次数比在AID数据集上早2个epochs收敛。从图7中的红色虚线和绿色实线对比可知,在提高训练速度的同时,Inception-L1仍能够很好地提取高分场景影像的高层次特征。
2.3.2 不同Dropout率对Inception-L1网络的影响
图8展示了不同的Dropout率在AID数据集上的训练情况对比。可明显看出,随着Dropout率的提高,Inception-L1网络的收敛速度越来越快,由此可见,加入了Dropout操作后,Inception-L1网络的分类效率得到了提高。当Dropout率为0.2时,Inception-L1网络的收敛速度最快,且训练过程更为稳定。
图8
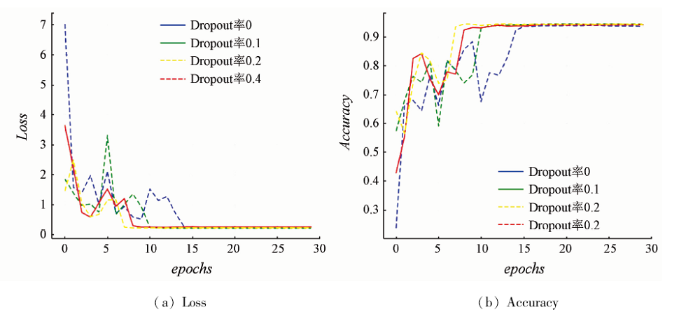
图8
不同Dropout率在AID数据集上的训练情况
Fig.8
Different Dropout rate training on AID datasets
图9展示了不同Dropout率在NWPU-RESISC45数据集的训练情况,由图可知,Dropout率为0.4时,Inception-L1网络的训练情况最为稳定。但对于分类精度而言,Dropout率为0时分类精度最高。这是由于NWPU-RESISC45数据集虽数据量大,但其场景类别多,故场景数据没有过分冗余,但此时若加入Dropout层,训练过程更加平稳,并且分类精度保持稳定。
图9
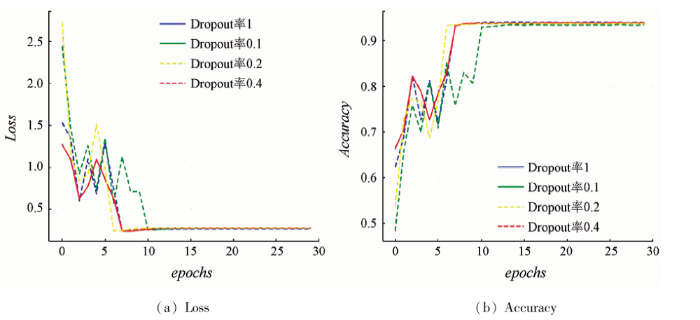
图9
不同Dropout率在NWPU-RESISC45数据集上的训练情况
Fig.9
Different Dropout rate training on NWPU-RESISC45 datasets
表1显示了在AID和NWPU-RESISC45数据集上不同Dropout率对Inception-L1的分类性能的影响。可知,在AID数据集上,当Dropout率为0.2时,Inception-L1的分类精度最高。在NWPU-RESISC45数据集上,当Dropout率为0.4时,Incep-tion-L1的分类精度最高。因此,在实验中,分别将Dropout率设置为0.2与0.4。
表1 不同Dropout率分类test_accuracy对比
Tab.1
| Inception-L1 | test_accuracy | ||
|---|---|---|---|
| Dropout率0.1 | Dropout率0.2 | Dropout率0.4 | |
| AID | 94.30±0.25 | 94.44±0.23 | 94.40±0.31 |
| NWPU-RESISC45 | 93.70±0.28 | 93.91±0.15 | 3.95±0.26 |
表2综合比较了低层视觉特征、中层视觉表示和高层语义特征3类层次的特征分类方法进行30次随机试验后的平均分类精度和标准差。
表2 各类方法分类test_accuracy对比
Tab.2
| 方法 | test_accuracy | 方法 | test_accuracy | ||
|---|---|---|---|---|---|
| AID | NWPU-RESISC45 | AID | NWPU-RESISC45 | ||
| LBP | 26.26±0.52 | 21.74±0.18 | SPM+CH | 41.27±0.49 | 41.82±0.21 |
| CH | 34.29±0.40 | 27.52±0.14 | VLAD+CH | 44.78±0.28 | 50.57±0.48 |
| SIFT | 13.24±0.74 | 11.48±0.21 | AlexNet | 86.34±0.43 | 79.24±0.10 |
| GIST | 30.61±0.63 | 17.88±0.22 | VGG-16 | 86.87±0.41 | 82.21±0.32 |
| BoVW+CH | 47.77±0.52 | 49.87±0.23 | GooLeNet | 83.84±0.36 | 78.47±0.28 |
| IFK+CH | 64.83±0.42 | 66.47±0.27 | ResNet50 | 89.70±1.05 | 88.35±0.49 |
| LLC+CH | 49.36±0.57 | 46.81±0.30 | Inception-V3 | 94.18±0.40 | 93.40±0.28 |
| pLSA+CH | 42.87±0.54 | 41.97±0.43 | Inception-L1 | 94.44±0.23 | 93.95±0.15 |
低层视觉特征选取LBP,CH,GIST和SIFT这4个特征,其中对于LBP,CH和SIFT特征,实验中使用16×16的窗口以8个像素为步长滑动提取局部特征,然后通过平均池化的方式获得最终的特征向量。相较于中、高层视觉特征方法,低层视觉特征方法的分类精度最差,其中CH的分类精度在AID和NWPU-RESISC45上都优于其他3种低层特征,这是因为2个数据集中绝大部分类别的遥感场景影像都具有颜色一致性,使用CH能够提取各类别的光谱信息。相对NWPU-RESISC45数据集,GIST在AID数据集上取得了更好的分类精度,这是由于AID数据集中包含大量由各种建筑物构成的人工场景类别,GIST可以充分提取这些类别影像的空间结构; 而NWPU-RESISC45数据集用地类型更多且类间差异性更小,GIST无法提取足够的空间结构信息加以区分,导致GIST在NWPU-RESISC45测试集上的分类效果不够理想。
中层视觉表示方法采用BoVW,IFK,LLC,pLSA,SPM和VLAD这6种编码方法,结合低层特征中分类效果最佳的CH特征进行编码。BoVW,IFK,LLC,pLSA,SPM和VLAD的字典大小分别设置为4 096,128,4 096,1 024,256和128,pLSA的主题数设置为64,SPM的金字塔层数设置为2,分类器使用线性核的支持向量机。由表2可知,采用IFK的编码方法的分类精度优于其他几个编码方法。这是因为BoVW,LLC和VLAD是基于特征字典进行编码,而IFK是通过高斯混合模型计算出局部特征的概率密度分布来刻画场景影像,这一编码方式能更好地刻画出遥感场景影像的空间分布特征。
选择常用的4个深度学习网络AlexNet,VGG-16,GooLeNet,ResNet50和原始的Inception-V3网络进行实验,并与Inception-L1进行对比,可知使用深度学习网络获取高层次语义特征的方法分类精度最高,较中层视觉表示方法有30百分点左右的提升; 且Inception-L1的分类精度优于其他5种深度学习网络。这是由于迁移学习的使用,Inception-L1能利用大型自然数据集的知识,通过大量的卷积和池化,反复使用Inception Block,利用多尺度的卷积核提取不同比例特征分布的图像信息,从而获取遥感场景的复杂特征信息; 同时,Inception-L1通过在最后一层前加入随机失活机制,进一步减少了过度拟合现象发生,提高了训练效率。
由表3可以看出,Inception-L1在AID和NWPU-RESISC45上各类别的分类准确度都较高,其中AID的森林、裸地、棒球场、沙滩等类别分类准确度达到了100%正确率,NWPU-RESISC45中的灌木丛、梯田、海冰、小岛的场景分类精度都在99%以上。
表3 Inception-L1在AID数据集的分类结果
Tab.3
| 类别 | 准确率 | 类别 | 准确率 |
|---|---|---|---|
| 森林 | 100 | 教堂 | 96 |
| 裸地 | 100 | 储存罐 | 96 |
| 棒球场 | 100 | 飞机场 | 95 |
| 沙滩 | 100 | 桥 | 95 |
| 山脉 | 100 | 港口 | 95 |
| 稀疏住宅区 | 100 | 火车站 | 95 |
| 草地 | 100 | 商业区 | 93 |
| 体育场 | 99 | 密集住宅区 | 92 |
| 高架桥 | 99 | 中型住宅区 | 92 |
| 停车场 | 99 | 工业区 | 91 |
| 池塘 | 98 | 学校 | 85 |
| 河流 | 98 | 景区 | 82 |
| 操场 | 97 | 广场 | 82 |
| 沙漠 | 97 | 中心区 | 78 |
| 农田 | 97 | 公园 | 76 |
图10

表4 Inception-L1在NWPU-RESISC45数据集的分类结果
Tab.4
| 类别 | 准确率 | 类别 | 准确率 |
|---|---|---|---|
| 灌木丛 | 100 | 湖泊 | 95 |
| 圆形农田 | 99 | 高速公路 | 95 |
| 小岛 | 99 | 船 | 95 |
| 梯田 | 99 | 网球场 | 95 |
| 海冰 | 99 | 沙漠 | 94 |
| 棒球内场 | 98 | 稀疏住宅区 | 94 |
| 云 | 98 | 火电站 | 94 |
| 高尔夫球场 | 98 | 飞机 | 94 |
| 田径场 | 98 | 飞机场 | 94 |
| 港口 | 98 | 工业区 | 93 |
| 活动房区 | 98 | 山脉 | 93 |
| 停车场 | 98 | 跑道 | 92 |
| 雪堡 | 98 | 矩形农田 | 91 |
| 体育场 | 97 | 中型住宅区 | 91 |
| 储存罐 | 97 | 铁道 | 90 |
| 环岛 | 97 | 河流 | 90 |
| 草地 | 96 | 湿地 | 89 |
| 篮球场 | 96 | 密集住宅区 | 88 |
| 森林 | 96 | 火车站 | 88 |
| 桥 | 96 | 商业区 | 87 |
| 立交桥 | 96 | 教堂 | 79 |
| 十字路口 | 95 | 宫殿 | 71 |
| 沙滩 | 95 |
图11

3 结伦
1)本文提出了一种改进的Inception-V3的网络模型,在原始的 Inception-V3的最后一层全连接层前添加 Dropout层,以进一步解决高分遥感影像训练过程中发生过拟合现象的问题; 同时在网络训练中,进一步应用迁移学习技术,先将在 ImageNet上预训练的参数迁移至 AID 数据集上微调,而后再迁移至 NWPU-RESISC45上进一步微调,以减少训练难度和提高分类精度。
2)在 AID 和 NWPU-RESISC45两个高分遥感场景集上的实验表明,针对高分影像场景图像,改进的 Inception-V3在保持原始的 Inception-V3分类精度的同时,训练收敛速度变得更快。
3)与低层次视觉特征、中层次视觉表示和其他高层次语义特征的分类精度对比表明,改进的 Inception-V3的分类性能有较大提升; 且相较于其他常用深度学习网络, 改进的Inception-V3分类精度也有5%~10%的提高。
4)在应用层面上,建议先对国土资源遥感影像进行基于对象的场景分割,再使用本文方法对大空间范围的场景进行划分,可获得更好的分类效果。
参考文献
基于深度神经网络的遥感图像分类算法综述
[J].
Overview of remote sensing image classification algorithm based on depth neural network
[J].
基于CNN模型的遥感图像复杂场景分类
[J].
Classification of complex scene of remote sensing image based on CNN model
[J].
Land-use scene classification using multi-scale completed local binary patterns
[J].
AID:A benchmark data set for performance evaluation of aerial scene classification
[J].DOI:10.1109/TGRS.2017.2685945 URL [本文引用: 1]
Color indexing
[J].DOI:10.1007/BF00130487 URL [本文引用: 1]
Modeling the shape of the scene:A holistic representation of the spatial envelope
[J].
DOI:10.1023/A:1011139631724
URL
[本文引用: 1]

In this paper, we propose a computational model of the recognition of real world scenes that bypasses the segmentation and the processing of individual objects or regions. The procedure is based on a very low dimensional representation of the scene, that we term the Spatial Envelope. We propose a set of perceptual dimensions (naturalness, openness, roughness, expansion, ruggedness) that represent the dominant spatial structure of a scene. Then, we show that these dimensions may be reliably estimated using spectral and coarsely localized information. The model generates a multidimensional space in which scenes sharing membership in semantic categories (e.g., streets, highways, coasts) are projected closed together. The performance of the spatial envelope model shows that specific information about object shape or identity is not a requirement for scene categorization and that modeling a holistic representation of the scene informs about its probable semantic category.]]>
Multiresolution gray-scale and rotation invariant texture classification with local binary patterns
[C]//
Distinctive image features from scale-invariant keypoints
[J].
DOI:10.1023/B:VISI.0000029664.99615.94
URL
[本文引用: 1]
This paper presents a method for extracting distinctive invariant features from images that can be used to perform reliable matching between different views of an object or scene. The features are invariant to image scale and rotation, and are shown to provide robust matching across a substantial range of affine distortion, change in 3D viewpoint, addition of noise, and change in illumination. The features are highly distinctive, in the sense that a single feature can be correctly matched with high probability against a large database of features from many images. This paper also describes an approach to using these features for object recognition. The recognition proceeds by matching individual features to a database of features from known objects using a fast nearest-neighbor algorithm, followed by a Hough transform to identify clusters belonging to a single object, and finally performing verification through least-squares solution for consistent pose parameters. This approach to recognition can robustly identify objects among clutter and occlusion while achieving near real-time performance.]]>
Bag-of-visual-words and spatial extensions for land-use classification
[C]//
Beyond bags of features:Spatial pyramid matching for recognizing natural scene categories
[C]//
Locality-constrained linear coding for image classification
[C]//
Scene classification via pLSA
[C]//
Improving the fisher kernel for large-scale image classification
[C]//
Aggregating local image descriptors into compact codes
[J].
DOI:10.1109/TPAMI.2011.235
URL
[本文引用: 1]
This paper addresses the problem of large-scale image search. Three constraints have to be taken into account: search accuracy, efficiency, and memory usage. We first present and evaluate different ways of aggregating local image descriptors into a vector and show that the Fisher kernel achieves better performance than the reference bag-of-visual words approach for any given vector dimension. We then jointly optimize dimensionality reduction and indexing in order to obtain a precise vector comparison as well as a compact representation. The evaluation shows that the image representation can be reduced to a few dozen bytes while preserving high accuracy. Searching a 100 million image data set takes about 250 ms on one processor core.
Deep learning based feature selection for remote sensing scene classification
[J].DOI:10.1109/LGRS.2015.2475299 URL [本文引用: 1]
聚合CNN特征的遥感图像检索
[J].
Remote sensing image retrieval based on CNN features
[J].
Land-use classification via extreme learning classifier based on deep convolutional features
[J].DOI:10.1109/LGRS.2017.2672643 URL [本文引用: 1]
特征提取策略对高分辨率遥感图像场景分类性能影响的评估
[J].
Evaluation of the effect of feature extraction strategy on scene classification performance of high resolution remote sensing image
[J].
基于深度学习AlexNet的遥感影像地表覆盖分类评价研究
[J].
DOI:10.3724/SP.J.1047.2017.01530
URL
[本文引用: 1]
地表覆盖分类信息是反映自然、人工地表覆盖要素的综合体,包含植被、土壤、冰川、河流、湖泊、沼泽湿地及各类人工构筑物等元素,侧重描述地球表面的自然属性,具有明确的时间及空间特性。地表覆盖分类信息数据量大、现势性强、人工评价费时,其自动化评价长期以来存在许多技术难点。本文基于面向对象的图斑分类体系,引入深度卷积神经网络对现有地理国情普查-地表覆盖分类数据进行分类评价,并通过试验利用AlexNet模型实现地表覆盖分类评价验证。试验结果表明,该方法可有效判读耕地、房屋2类图斑,正确分类隶属度优于99%,而由于数据较少、训练不充分,林地、水体图斑正确分类隶属度不高,分别为62.73%和43.59%。使用本文方法,经过大量数据充分微调的深度学习AlexNet可有效地计算图斑的地类隶属度,并实现自动地表覆盖分类图斑量化评价。
Classification and evaluation of surface coverage of remote sensing images based on deep learning AlexNet
[J].
ImageNet classification with deep convolutional neural networks
[C]//
Very deep convolutional networks for large-scale image recognition
[EB/OL].(
Going deeper with convolutions
[C]//
Deep residual learning for image recognition
[C]//
改进的基于深度学习的遥感图像分类算法
[J].
Improved classification algorithm of remote sensing image based on deep learning
[J].
基于深度学习的高分辨率遥感影像分类研究
[J].
Research on high-resolution remote sensing image classification based on deep learning
[J].
Going deeper with convolutions
[C]//
Understanding the disharmony between dropout and batch normalization by variance shift
[EB/OL].(
基于FC-DenseNet的低空航拍光学图像树种识别
[J].
Tree species recognition based on FC-DenseNet in low altitude aerial optical images
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}