

0 引言
然而,由于遥感图像的空间特殊性,卷积架构也面临许多难题,如定位目标的空间尺度小,特征像素少,背景信息量大且复杂,移动端计算资源受限,延时性差等。其中,不同空间分辨率的遥感目标实例的识别精度严重不平衡是阻碍其发展的主要问题。解决方法主要包括构建混合尺度卷积实现层内特征融合和构建特征金字塔网络(feature pyramid network,FPN)[5]实现层间特征融合2方面。前者主要利用感受野的宽度和网络层深度对遥感目标的细节进行分离和强化。Inceptionv3利用特征瓶颈与因子分解提高了三维卷积核的提取效率[6]; SENet构建一条针对不同特征通道的全连接权重分支,评价不同特征的重要性,实现注意力机制[7]; ResNet引入直连通路,将需要学习的输出过滤为特征与原图的差异,解决了梯度稀释的问题[8]; DenseNet介绍了一种强梯度流,通过密集连接和特征压缩使得低维和高维特征可以等价地获得深度监督[9]。这些模块的本质是对感受野的尺寸进行了控制和评价。后者则在假定层内信息固定,通过层间横向连接双向特征流,对遥感目标的强语义、低分辨率的高阶特征进行上采样,并与高分辨率特征组合以生成像素信息丰富、语义清晰的特征表示。PANet在FPN特征上添加额外的自下而上的卷积分支,进而改善低分辨率特征的定位精度[10]; RON利用反向金字塔连接和目标先验图解决了多尺度负样本搜索空间过大的问题[11]; PFPNet对输入多路提取细节,实现了信息的多尺度上下文融合(multi-scale context aggregation,MSCA)[12]; EfficientNet则针对每一路特征金字塔引入了低计算成本的横向连接和斜向特征流,进一步强化网络提取特征的能力[13]。然而,人工设计的特征模块与融合模式难以适应任何一种场景或数据集,表现为小物体召回率较低,相似物体准确率较低,且往往以过拟合的形式要求设计人员反复实验不同架构的性能,消耗了大量的计算成本,制约了开发效率。
最近,神经架构搜索算法[14]被证明是可以在巨大的搜索空间中有效发现性能最高的体系架构。它构建了一个搜索空间,并从空间中初始化一个子网络,通过遥感数据的训练得到当前架构的最高性能,并将该性能指标作为奖励函数,重新在搜索空间寻找更优的子网络架构,循环迭代直到奖励函数收敛,得到当前数据集下最优的架构参数。层内搜索融合的典型网络包括MnasNet[15],FBNet[16]和MixNet[17]等,它们都基于强化学习对架构参数进行了搜索,但由于设计空间为ImageNet数据集[18],因此在遥感数据空间移植性较低; 对于层间搜索融合,如Liu等[19]和Ghiasi等[20]提出了可重复堆叠的自适应金字塔伸缩结构,但搜索空间庞大,提取效率低。为了使网络能够快速学习,更好地利用特征层内与层间关系,而非用枚举法预先设计各层之间的不加区别的输入(即直接添加操作),本文利用强化学习和监督学习算法搜索特征融合模型的架构参数,将特征金字塔参数设计与混合分离式卷积参数设计结合起来,针对像素尺度不同的同类遥感数据进行网络建模,生成一种自适应伸缩的遥感目标检测的模型,满足不同城市或地区的实例尺寸差异性。
1 遥感图像数据集概况
深度学习图像处理方法在自然图像中取得了巨大的成功,但是很难将其目标检测算法直接迁移到光学遥感图像中。这是由于二者存在视角差异,空间传感器捕获的鸟瞰图比自然场景图像的轮廓和纹理信息少,而数据集的语义质量和数量恰恰是决定测试精度的主要因素。因此,这对深度网络模型的泛化能力又提出了进一步要求。为了解决这一问题,一些遥感图像数据已经开源,如NMPU,UCAS-AOD,COWC,DOTA和DIOR[21]等。
DIOR由23 463张图片和192 472个对象实例组成,覆盖20个类别,图像尺寸为800像素×800像素,空间分辨率范围为0.5~30 m。由于传感器空间分辨率和类别内外的尺寸变化,DIOR中实例大小变化范围很大,如图1所示。另外从图1箱体图的尺寸分布重心可以看出,空间实际尺寸小的遥感实例总体具有较小的像素尺寸,但也包含与实际尺寸较大的实例相同像素级别的训练数据,这使得最终的遥感检测器具有一定的泛化能力。每类实例对象的尺寸(平均边长)都覆盖了0~800像素,面积均值也更为分散,这样可以更准确地描绘飞行器感知的地形信息。此外,DIOR覆盖80多个国家并兼顾不同的天气、季节、成像条件和图像质量,如图2所示。
图1
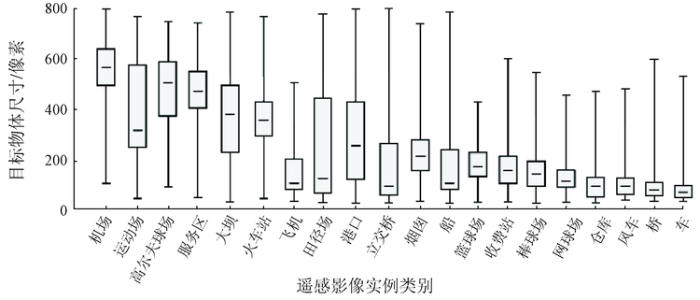
图2-1
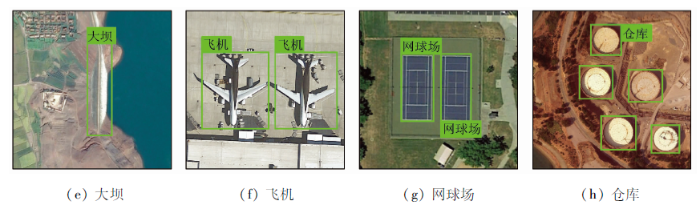
图2-2
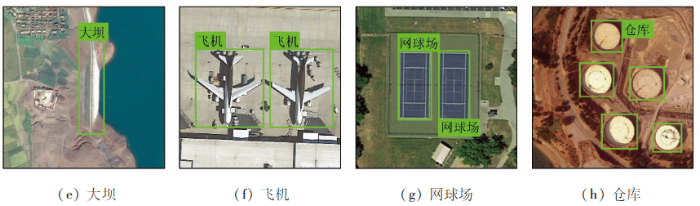
因此,该数据集在每个对象类的视角、位移、照明、背景、外观和遮挡等方面拥有丰富的变化。更重要的是,DIOR具有类间相似性,即语义高度重叠的细粒度特性,例如“桥”与“立交桥”、“运动场”与“田径场”、“网球场”与“篮球场”等,这提高了对模型泛化能力的要求。
2 金字塔架构搜索原理
金字塔架构搜索算法包含搜索空间、搜索策略和评价预估3个部分。本文将介绍基于强化学习的设计空间和多尺度架构搜索算法,将评价预估体系融合到策略中,从而自适应多目标,多规模的遥感图像集。由于DIOR等遥感数据集规模较小,本文将不使用代理模型来迁移低保真参数。
2.1 架构搜索空间
架构搜索空间是所有候选网络单元的集合,决定了搜索过程的时间和搜索结果的准确性。搜索空间的设计应满足3个要求: ①足够大且包含有效架构; ②验证集准确率和训练集准确率相近; ③计算成本不应过大。遥感图像的特征空间较自然图像小,因此本文将压缩模型训练权重矩阵,防止过拟合问题(针对要求②),节约计算时间(针对要求③),而对于要求①,架构规模则由混合卷积与FPN的搜索参数共同保证。
2.1.1 层内尺度搜索空间
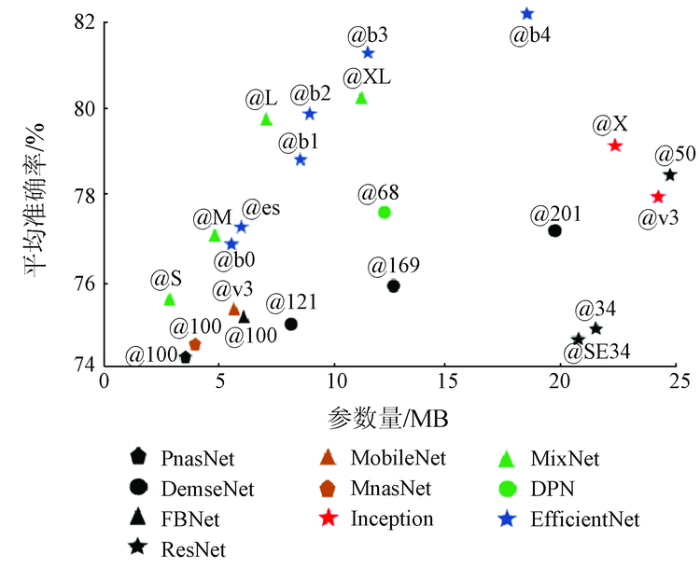
分离式卷积是轻量级的主干模型,它将3D卷积强制分解成单层卷积和点深度卷积,在保证精度不损失过多的前提下,压缩了几倍到十几倍的参数量,如MobileNet-v1,v2和v3[22,23,24]。而3D卷积是全层卷积,将所有特征图的边缘特征重新融合,达到更好的提取效果。因此,在单层和全层之间一定存在某种多层分组的方式,使得对于当前数据集的感知能力强于前两者,即混合分离式卷积[17]。为了验证混合分离式卷积的感知效率,本文对几种有代表性的分类模型绘制了参数量-准确率(ImageNet-1k)分布,如图3所示,其中inception@v3代表inceptionv3模型,resnet@34代表34层的残差网络等。准确性越好,参数越少,证明网络的效率越高,即图3中左上方的MixNet-S,MixNet-M,MixNet-L。MixNet系列的核心思想是将3D卷积的通道进行分组,在固定组数和总通道数的前提下,搜索不同组对应的卷积核尺寸,从而高效利用深度方向的差异化细节信息。本文在MixNet的基础上,扩展了通道卷积的搜索范围,使它不仅在层内搜索,也接收层间信息误差的监督,从而强化架构搜索能力。
图3
由于DIOR数据集中的实例对象的尺寸跨度较大,因此对相似却不同类的细粒度划分就尤为重要,而不同卷积核尺寸可以抽象出来不同感受野的局部特征,保证细节的特征提取效率,且卷积核尺寸越大,提取大感受野的能力越强,但参数量也越大。如图4所示,对于任意一个输入特征图(含原始3通道数据),假设分辨率为W×H(宽×高),总通道数为
图4
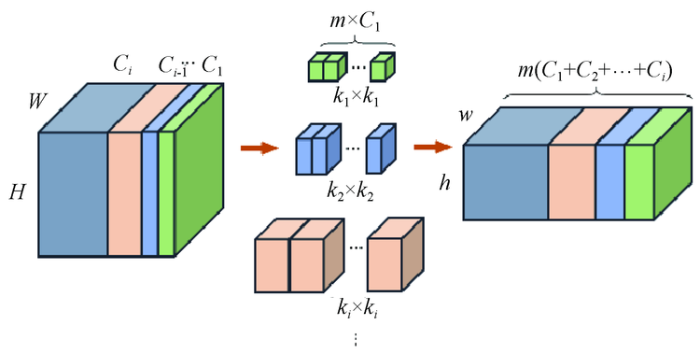
2.1.2 层间尺度搜索空间
层间尺度融合与感知的典型网络为FPN网络,其将序列化尺寸的特征图输出作为反向上采样的输入,并由每一层上采样的特征层输出边界回归损失与分类损失,从而反向传播优化参数矩阵。本文在RetinaNet[29]和NAS-FPN的结构设计基础上,根据遥感数据低频信息较多的性质,调整层间的搜索范围。由于DIOR数据集的实例短边长d范围为16~800像素,为了保证实例特征的完整性,须使得滑移尺寸Smin>dmin,为了使得最大尺寸和最小尺寸的卷积后保持同一尺度,须使得dmax/dmin>Smax,为了压缩计算时间,层数不能过大,因此计算得输入特征层{I3,I4,I5,I6}对应的特征滑移尺寸为{8,16,32,64}。
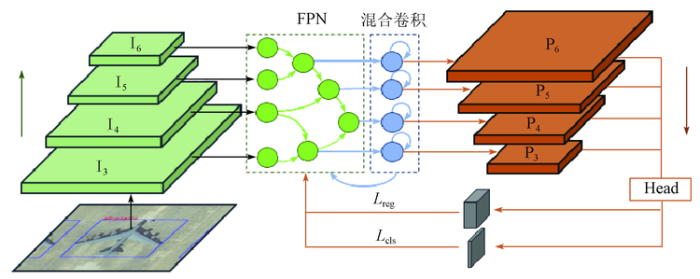
经过初步特征提取的网络层将输入到金字塔网络中两两融合,获得更丰富的语义信息。金字塔网络的本质是不同尺度的交叉连接,本文定义其连接节点如图5所示。
图5

2.2 搜索策略与评价预估
架构搜索常用的算法包括梯度松弛、强化学习与遗传算法,本文使用奖励易于定制的强化学习方法为该搜索问题找到最优解。层内的设计空间主要为卷积核尺寸序列,层间主要为合并节点序列对其标记后通过一系列动作确定状态的最大化奖励。本文基于“采样-评估-更新”的策略,由控制器首先通过来自循环神经网络(recurrent neural networks,RNN)的Softmax函数预测节点序列并进行采样。对于每个采样模型,计算其在当下配置环境中的最低训练损失值,而不用平均准确率(average precision,AP),因为在训练初期,AP精度的差别较小,收敛慢。
搜索空间的规模由合并单元与混合卷积尺寸共同构成,如图6所示,每一张图像由下至上抽象出不同分辨率的特征层,通过RNN控制器随机选取多组候选特征图在FPN模块中进行节点融合操作。为了保证初始搜索精度,金字塔网络的输入层与其相邻层的合并层作为FPN的初始候选层。新生成的特征层将附加到现有输入候选列表中,并成为下一个合并单元格的新候选层。在架构搜索期间,可能有多个候选层共享相同的分辨率。为了减少搜索过程的计算量,本文降低了中间合并单元选择滑移尺寸为8的概率。当节点合并后,并不直接输出到Head中处理感兴趣区域,而是进行混合卷积强化特征空间,并突出局部变化,通过注意力模型进行特征图筛选。卷积后保证图像尺度仍封闭于FPN的设计空间。当验证集AP收敛时,最终的4个合并单元作为输出特征金字塔{P3,P4,P5,P6},输出特征级别的顺序由控制器预测并给出损失值进行反向优化。损失值的形式延续传统2阶段识别框架,并作为RNN控制器的奖励,即
图6
式中: Lreg为边界框预测的回归损失; Lcls为候选框图的分类损失; R(a)为在当前子网络(即当前动作Action下)的对于输入数据和标签训练后对验证集Dval的奖励函数。
3 实验与分析
在大型的感知任务中(如COCO或VOC)[31,32],直接进行CNN架构搜索的时间成本非常昂贵,每种模型需要花费数天的时间才能收敛。为了降低初始搜索阶段的耗时,一般将原始数据集随机抽取部分数据,作为每类的代理数据集进行预搜索,但代理数据集越小,搜索效果越低,往往没有明显的效果。因此,本文直接将DIOR数据集按1∶2∶7的比例随机划分为验证集、测试集和训练集,不设置代理任务,图像大小为800像素×800像素。为了有效利用主干网络的缓存,首先使用MixNet-M的开源预训练模型来初始化特征层,然后使用FPN的训练策略对DIOR进行微调。并且相应地,训练周期降低为120,学习率提高为0.008,实验硬件条件为2个TITAN RTX,平均每次搜索时间为20.6 GPU/d。实验使用衰减率为0.85,动量为0.9的RMS优化器。针对不同卷积核尺寸k×k,将每次搜索得到的奖励曲线进行横向比较,单一核的特征抽象的能力较低,混合尺寸的较高,如图7所示。
图7
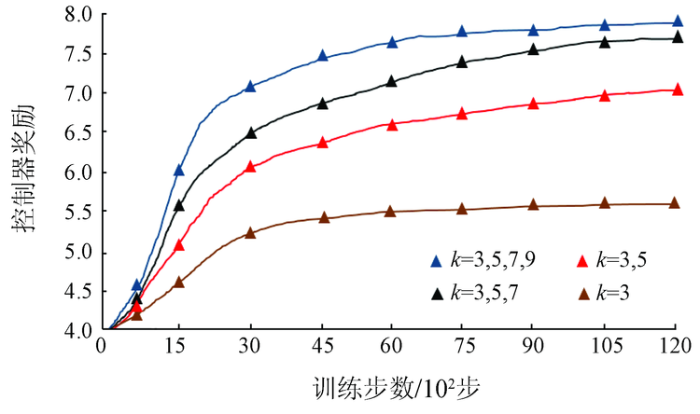
图7
不同卷积核尺寸组对搜索结果的影响
Fig.7
Influence of different convolution kernel size groups on search results
通过多次搜索,发现RNN控制器可以在早期学习阶段快速获取一些重要的跨尺度连接,如图8所示。例如,它发现高分辨率输入和输出要素图层之间的连接,这对于生成用于检测小物体的高分辨率特征图至关重要。随着控制器的收敛,控制器会自然地呈现出自上而下和自下而上连接的架构,以及更抽象的特征图重用,这与普通FPN形式不同,但显然是FPN思想的合理扩展。而对于卷积核尺寸k×k,在初始融合层中3×3占主导,而多层融合以及尺度跨度较大的层融合时,像7×7和9×9等大感受野滤波器就会体现出优势。FPN结构中的所有内部层都固定为32个通道,并通过1×1卷积调整最终的输出通道宽度。在DIOR上搜索1 500个样本架构后,控制器模型几乎收敛,并选择搜索效果最好的混合策略作为最终结果。
图8
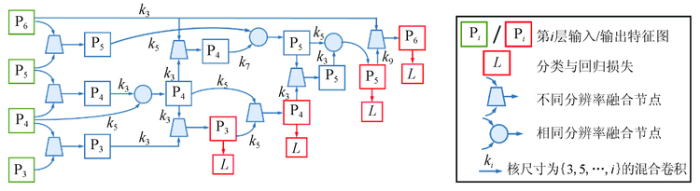
表1展示了不同检测器对于遥感图像集DIOR的感知能力,其中,mAP为平均准确率均值,即每类遥感图像识别查全率和查准率的线下平均面积,APS与APL是以实例面积为阈值划分的准确率,面积小于322为小物体,大于962为大物体。本文为了便于对比以及节约计算时间,限定了主干网络参数量,如ResNet-50。大物体目标实例的检测准确率高于同一检测条件下的小物体。随着层数加深,参数量提高,提取方式的深入,AP值呈上升趋势。实验表明,对于遥感低频数据,无边框检测的效率略低于有边框的模型,而使用FPN融合多尺度信息是有明显精度提升的。对于参数量最大的Cascade R-CNN来说,小物体和大物体的识别能力都明显优于其他网络架构。本文网络结构的mAP为70.5%,较Cascade R-CNN提高1.6百分点,APs提高2.1百分点,在压缩了一定内存的前提下,提高了准确性。与NAS-FPN相比,混合卷积的细粒度感知能力更强,APs提高6.2百分点。与CornerNet相比,mAP提高13.2百分点。总体上,混合搜索模块对低复杂度遥感图像的提取能力强于ResNet。
表1 不同网络在DIOR测试集下的准确率
Tab.1
| 模型 | 主干网络 | mAP | APS | APL |
|---|---|---|---|---|
| YOLOv3[33] | Darknet-53 | 53.1 | 22.5 | 75.7 |
| Faster R-CNN[34] | VGG16 | 54.2 | 33.9 | 78.6 |
| Faster R-CNN+FPN | ResNet-50 | 60.6 | 42.2 | 81.9 |
| RetinaNet+FPN | ResNet-50 | 62.9 | 43.5 | 86.5 |
| CornerNet[35] | Hourglass-104 | 57.3 | 31.8 | 80.4 |
| Cascade R-CNN[36] | ResNet-50 | 68.9 | 48.9 | 89.5 |
| FCOS-FPN | ResNet-50 | 59.6 | 35.7 | 85.9 |
| NAS-FPN | ResNet-50 | 64.8 | 44.8 | 84.6 |
| NAS-FCOS[37] | ResNet-50 | 60.8 | 40.3 | 79.0 |
| NAS-Mix-FPN | MixNet | 70.5 | 51.0 | 89.1 |
层输入的第一次卷积不相同,之后再满足搜索空间的随机性。由表2可知,{3×3, 5×5, 7×7, 9×9}卷积组是准确率相对较高的,而{3×3, 5×5, 7×7, 9×9, 11×11}卷积组虽然mAP比前者高1.1百分点,但是参数量比前者高,计算耗时长,一般的网络很少使用11×11卷积核。对于某一特定卷积组,如{3×3, 5×5, 7×7, 9×9, 11×11},层数和卷积尺寸种类数一致时,准确率最高。对于1×1卷积,一般用于调整输出大小,不适合高维感受野的抽象概括,因此效果较差。
表2 不同卷积搜索空间下的搜索结构在DIOR测试集上的性能
Tab.2
| 卷积搜索空间 | 金字塔 层数 | mAP | APS | APL |
|---|---|---|---|---|
| {3×3, 5×5, 7×7, 9×9, 11×11} | 6 | 71.2 | 53.2 | 89.7 |
| {3×3, 5×5, 7×7, 9×9, 11×11} | 5 | 71.6 | 53.3 | 90.1 |
| {3×3, 5×5, 7×7, 9×9, 11×11} | 4 | 70.1 | 51.9 | 88.7 |
| {3×3, 5×5, 7×7, 11×11} | 4 | 70.2 | 50.9 | 89.3 |
| {3×3, 5×5, 7×7, 9×9} | 5 | 69.9 | 49.8 | 87.2 |
| {3×3, 5×5, 7×7, 9×9} | 4 | 70.5 | 51.0 | 89.1 |
| {3×3, 5×5, 7×7, 9×9} | 3 | 68.7 | 45.7 | 88.3 |
| {3×3, 5×5, 7×7} | 4 | 64.5 | 40.3 | 83.9 |
| {3×3, 5×5, 7×7} | 3 | 62.7 | 41.1 | 84.5 |
| {1×1, 3×3, 5×5} | 3 | 58.4 | 38.8 | 80.6 |
图9

图9
重庆市地标建筑、设施遥感目标检测
Fig.9
Remote sensing target detection of landmark buildings and facilities in Chongqing
4 结论
1)本文针对遥感小目标检测准确率低的问题,提出了金字塔架构搜索算法来进一步优化金字塔网络。首先引入了高效的混合分离卷积模块,压缩了计算参数,然后将传统人工设计的特征混合模块整合为强化学习的动作单元与状态单元,实现自动化搜索。
2)在DIOR数据集上进行的实验证明,通过层间跨尺度搜索和层内多感受野融合,可以提高同类不同分辨率实例的识别准确性。通过设计搜索空间,搜索策略和模型评估指标可以高效搜索可伸缩的、高精度的检测器。
因此,本文设计并搜索得到的NAS-Mix-FPN模型对低分辨率遥感图像识别效率的提升起到了促进作用,也实现了全自动遥感图像检测器的端到端训练。
参考文献
ImageNet classification with deep convolutional neural networks
[C].
人脸识别技术综述
[J].
Overview of face recognition technology
[J].
基于深度学习的智能辅助驾驶系统
[J].
Intelligent driving assistance system based on deep learning
[J].
基于深度学习的医疗图像分割
[J].
Medical image segmentation based on deep learning
[J].
Feature pyramid networks for object detection
[EB/OL]. (
Rethinking the inception architecture for computer vision
[C]//
Squeeze-and-excitation networks
[C]//
Deep residual learning for image reco-gnition
[C]//
Densely connected convo-lutional networks
[C]//
Path aggregation network for instance segmentation
[C]//
RON:Reverse connection with objectness prior networks for object detection
[EB/OL].(
Parallel feature pyramid network for object detection
[C]//
Efficientnet:Rethinking model scaling for convolutional neural networks
[EB/OL]. (
Neural architecture search with reinforcement learning
[EB/OL]. [
Mnasnet:Platform-aware neural architecture search for mobile
[C]//
Fbnet:Hardware-aware efficient convnet design via differentiable neural architecture search
[C]//
MixNet:Mixed depthwise convolutional kernels
[EB/OL]. (
Imagenet:A large-scale hierarchical image database
[C]//
Progressive neural architecture search
[EB/OL]. (
NAS-FPN:Learning scalable feature pyramid architecture for object detection
[EB/OL]. (
Object detection in optical remote sensing images:A survey and a new benchmark
[J].
MobileNets:Efficient convolutional neural networks for mobile vision applications
[EB/OL]. (
Incremental learning through deep adaptation
[J].
Searching for MobileNetV3
[J]. (
Going deeper with convolutions
[C]//
Batch normalization:Accelerating deep network training by reducing internal covariate shift
[C]//
Inception-v4,Inception-ResNet and the impact of residual connections on learning
[EB/OL]. (
Dual path networks
[EB/OL]. (
Focal loss for dense object detection
[J].
Searching for activation functions
[EB/OL]. (
Microsoft COCO captions:Data collection and evaluation server
[EB/OL]. (
The pascal visual object classes (VOC) challenge
[J].
YOLOv3:An incremental improvement
[J]. (
Faster R-CNN:Towards real-time object detection with region proposal networks
[C]//
CornerNet:Detecting objects as paired keypoints
[J].
Cascade R-CNN:Delving into high quality object detection
[EB/OL]. (
Fcos:Fully convolutional one-stage object detection
[C]//
基于面向对象与深度学习的典型地物提取
[J].
The typical object extraction method based on object-oriented and deep learning
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}