

0 引言
目前,从高分辨率遥感图像中提取建筑地物,主要有以下2类方法: ①基于传统的计算机视觉方法[6],使用人工特征,如植被指数、纹理和颜色特征; ②传统的机器学习分类器(如AdaBoost、支持向量机(support vector machine, SVM)、随机森林)实现建筑地物提取,并且通常会采用相应的后处理步骤来细化分割结果[7,8]。然而,此类方法不仅具有较高的模型复杂度,需大量人机交互,而且往往受制于人工知识与经验的限制[7,8]。而诸如完全卷积网络(fully convolutional network, FCN)或基于编码器与解码器体系结构的卷积神经网络(convolutional neural network, CNN)已经成功应用于该领域且优于传统的计算机视觉方法[9]。Yuan[10]使用FCN来预测像素到边界的距离,并对其进行阈值处理以获得最终的分割结果; Zhang等[11]在Google Earth图像上训练CNN并使用最大抑制的后处理步骤移除虚假建筑地物。但是,这些方法由于使用池化层进行下采样,尽管增加卷积核的感受野可以提取图像的全局特征,但同时丢失图像中的高频细节致使分割结果中缺失边界信息,易将建筑地物分割成许多“圆斑”,难以提取建筑地物完整边界[12]。为此,研究人员使用串联连接重新引入高频细节[13,14],或扩张卷积[15,16],以及相应的后处理(如条件随机场(conditional random field, CRF))[15]来解决这个问题。Maggiori等[17,18]在FCN之上,训练多层感知器(multi-layer perceptron, MLP)以结合网络中不同卷积层提取的局部特征,实现前端细节信息与后端抽象信息的结合,从而界定出建筑地物的位置; Marmanis等[19]和Peng等[20]提出将来自不同尺度的多个网络的特征图组合起来,并在这些连接的特征图之上进行最终预测以识别建筑地物; Huang等[21]提出不依赖于额外后处理步骤的方法,使用RGB和NRG波段组合2个并行流训练反卷积网络,并融合这2个流的预测结果; Li等[5]和Bischke等[22]也使用类似的2个流网络,并行处理RGB和数字高程模型(digital elevation model,DEM),以保留分割结果的边界信息,该方法首先使用SegNet网络作为特征提取器并应用边缘检测网络来提取边缘信息,之后将SegNet的特征图与边缘预测连接,将边界预测注入网络。尽管上述研究取得较好的建筑地物提取效果,但存在2个较为严重的问题[14]: ①加入后处理步骤的建筑地物分割方法,存在模型过于复杂且模块之间整合困难的问题; ②通过多种不同的网络提取不同特征并融合这些特征的方法,存在网络复杂、硬件设备要求高且训练时间长的问题。为此,研究人员将应用于医学图像,且可高精度提取目标物边界的具有编码与解码层结构的Unet网络[23]引入到遥感图像建筑地物提取的任务中,Iglovikov等[24]利用VGG11重新搭建Unet网络二值化提取建筑地物,在仅使用单个网络的情况下其提取精度获得巨大提升; Xu等[25]结合ResNet网络[26]与Unet网络搭建Res-Unet网络,既可实现图像的边界提取,又可准确地获取建筑地物位置,且网络参数共享,不仅降低模型的整体复杂性,而且避免边缘检测不准确的问题。
1 多任务网络
本文提出的多任务网络,通过使用多任务学习,不仅将建筑地物分割结果加入到目标损失函数中,而且引入建筑地物分割结果的边界信息,以改进建筑地物的最终分割结果。
1.1 边界距离图
多任务网络的目标是让网络除具有分割建筑地物的语义信息之外,还能在训练中赋予提取建筑地物边界信息的几何属性。从建筑地物真值图中,可方便提取建筑地物边界信息的多种几何属性,如形状、边缘信息。本文采用建筑地物像素到边界的距离作为训练网络产生几何属性的训练数据。使用该训练数据可使网络具备以下优点: ①可从现有的建筑地物真值图中,通过距离变换快捷地制作出边界距离图; ②使用边界距离图设计的损失函数(如均方差或负对数),计算形式方便,从而使网络学习到图像中每个像素的边界位置信息并隐式地捕获其几何属性。
为此,假设
式中:
然后,均匀地量化连续距离值以便于训练。将边界距离图使用one-hot编码为K维二进制矢量
式中
至此,训练多任务网络的数据已生成。表1展示了10幅训练样本图像及其对应的语义分割和边界距离真值,其中,两两相似的图像用于测试网络的鲁棒性及对小规模建筑地物分割的有效性。其中,第三列表示建筑地物到边界的距离,其距离越大说明该像素越不属于边界像素,值越小说明该值最有可能是边界像素,由此边界距离真值图训练的网络可最大限度保留建筑地物的边界信息。

1.2 多任务网络结构
图1
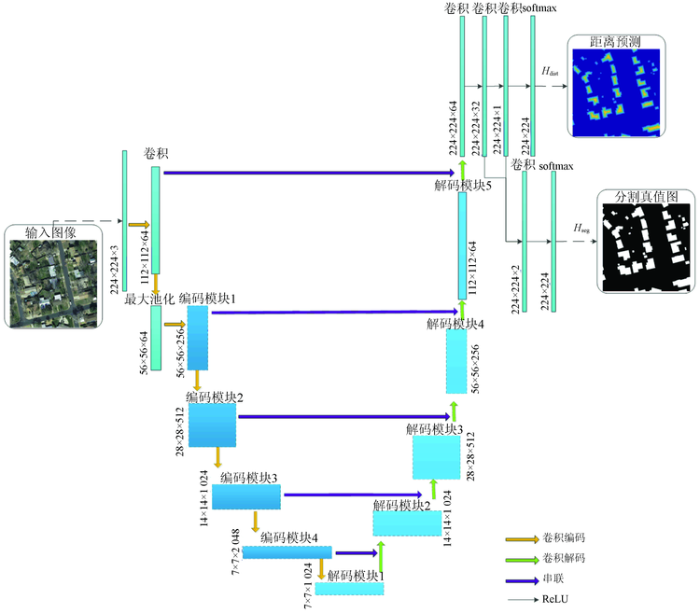
图1中,多任务网络由卷积编码(下采样)和卷积解码(上采样) 2条路径组成。卷积编码部分是ResNet网络(本文选择的是ResNet50[26]),用于提取输入图像的特征。首先,输入图像通过卷积、标准化和激活函数操作进入卷积层和最大池化层,以提高网络对失真和迁移的鲁棒性。之后,在特征提取期间,有4个编码模块,每个模块包括几个ResNet网络的残余块。同一模块中的特征图具有相同的大小,下层模块的特征图是上层模块的一半。不同模块中的特征映射具有不同的缩放特征。而相对应的卷积解码部分旨在使用卷积编码获得的特征图提取建筑地物。参考Unet的特征金字塔设置[23],为获得多尺度的特征,在卷积解码部分中设计与卷积编码部分相应模块的串联。卷积解码部分中的每个模块都包括对应卷积编码和下层模块的输入,以此使卷积解码部分重新获得高频信息。在网络的末端,添加2个卷积层,分别用于预测图像中每个像素到建筑地物边界的距离
1.3 基于不确定性的多任务损失
在多任务网络中,其损失函数
式中:
式中:
将每个分类任务模型可能性使用模型输出
式中:
对式(5)使用负对数似然,用不确定性表示分类损失,即
式中
假设网络的多个输出由连续输出和离散输出组成,分别用高斯似然和softmax似然建模[27],可进一步简化损失函数,即
故结合式(6)—(7)的多任务网络的损失函数为:
式中使用近似方程自适应地组合2个分类任务边界预测
1.4 训练多任务网络
在完成多任务网络搭建,以及自适应损失函数定义之后,使用动量与RMSProp算法结合的Adam优化算法[30]训练该网络,以优化更新网络参数,即
式中:
在式(9)中,为加速收敛多任务网络,使用离散指数衰减动态调整当前迭代的学习速率,即
式中:
2 实验与分析
2.1 数据集及数据增广
数据增广的目的是生成新的样本实例,并且当训练样本较少时,数据增广对于提高网络的鲁棒性非常有用。对于遥感图像,有许多常用的数据增广方法,如颜色抖动、随机裁剪、水平/垂直翻转、移位、旋转/反射、噪声、切割和切换频带等。由于大多数遥感图像是正射影像,因此变化主要反映在方向和尺度上。然而,本文使用的数据集中的图像具有相同的空间分辨率,没有大的尺度变化,因此仅使用其中3种常见的增广方法: 水平/垂直翻转、旋转和随机裁剪。从原始图像中随机提取尺寸为224像素×224像素的图像块,对其进行水平和垂直翻转以及不同角度的旋转。经过数据增广后,原数据集可扩大14倍。需说明的是,仅对原数据训练集进行增广,并不再为验证集进行数据增广。
2.2 评价指标
为验证提出方法的语义分割性能,采用2种评价指标来评估不同方法在数据集上的表现: ①准确度(accuracy, Acc),表示正确分类像素的百分比; ②交并比(intersection over union, IoU),其被定义为预测结果与真值图均是建筑地物的交集除以其并集,即
式中:
2.3 实验平台
采用高性能服务器实验平台: 操作系统为Ubuntu18.04; CPU为Intel(R) Xeon(R) cpu E5-2650 V2 @2.6 GHz (×2); 内存为64 GB; GPU为Tesla K40m (×3); 显存为23 GB; 深度学习平台为Keras 2.2.4; 数据可视化工具为Matplotlib 2.2.0; 编程语言为Python 3.6.4。
2.4 实验结果与分析
表2 不同方法的实验结果
Tab.2
| 城市 | FCN+MLP | VGG16 | VGG16+边界预测 | ResNet50 | 本文方法 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| IoU | Acc | IoU | Acc | IoU | Acc | IoU | Acc | IoU | Acc | |
| Austin | 61.20 | 94.20 | 70.66 | 95.28 | 72.81 | 95.82 | 72.38 | 95.79 | 74.41 | 96.09 |
| Chicago | 61.30 | 90.43 | 66.37 | 91.44 | 67.38 | 91.92 | 66.12 | 91.50 | 67.76 | 92.02 |
| Kitsap Co. | 51.50 | 98.92 | 57.55 | 98.19 | 57.54 | 98.90 | 58.68 | 98.95 | 60.19 | 98.63 |
| West Tyrol | 57.95 | 96.66 | 67.82 | 95.35 | 67.18 | 97.01 | 67.32 | 97.07 | 69.09 | 97.74 |
| Vienna | 72.13 | 91.87 | 77.01 | 93.28 | 77.19 | 93.31 | 76.86 | 93.21 | 78.21 | 93.63 |
| 均值 | 64.67 | 94.42 | 69.82 | 94.71 | 71.61 | 95.39 | 71.08 | 95.30 | 72.53 | 96.10 |
从表2可以看出,本文的多任务网络具有以下优势。
1) 具有更深的编码与解码层搭建的Unet网络可取得较优的建筑地物分割结果。表2中,FCN+MLP方法采用简单的4层卷积编码层搭建的FCN,之后使用MLP组合不同层的特征映射以输出最终建筑地物预测结果,尽管MLP组合来自不同层的特征映射,但因本身的编码与解码层较浅,无法充分提取建筑地物本身的多变特征致使建筑地物提取结果较差。为了验证编码器和解码层的深度对构建Unet网络的重要性,本文分别使用VGG16与ResNet50重新搭建Unet网络。新搭建的Unet网络中的编码层的网络权重分别使用VGG16与ResNet50网络在ImageNet[28]上预训练的网络权重初始化,以及使用高斯分布初始解码层的网络权重; 之后,使用Adam优化算法,设置初始学习速率率为0.01,采用指数的衰减速率,速率衰减因子为0.7,使用预测结果与分割标签的负对数似然函数计算损失并传递损失优化网络。从表2中所得到的不同网络搭建的Unet网络的实验结果可以看出: 由于编码层与解码层采用更深层网络架构,相比于FCN+MLP方法,VGG16网络[24]、VGG16+边界预测、ResNet50网络和本文方法的IoU均值分别提升5.15,6.94,6.41和7.86百分点,Acc均值分别提升至94.71%,95.39%,95.30%和96.10%,这表明FCN+MLP方法所提取的特征对于遥感图像建筑地物分割任务来说难以提取图像的深度抽象特征; 采用深层网络搭建编码与解码层在语义分割任务中起着至关重要的作用,相对于VGG16网络,ResNet50网络的IoU和Acc均值分别提高了1.26和0.59百分点。
2) 距离预测的重要性。为验证本文提出的加入边界距离预测的多任务网络的优势,分别在基于VGG16与ResNet50搭建的Unet网络中加入边界距离预测层,即除了用于分割结果预测层
为进一步验证本文方法的有效性,不同方法遥感图像建筑地物的分割结果如表3所示。
表3 不同方法遥感图像建筑地物分割结果
Tab.3
 |
从表3可以看出,不同方法提取10幅遥感图像建筑地物的结果中,仅FCN+MLP方法的分割结果表现出明显的“圆斑”效应,而其他方法的分割结果与真值十分接近。这也可以从表2中看出,相比于FCN+MLP方法,其他4种方法的IoU和Acc值均有较大提升,因此其分割结果会出现较大差异; 而其他4种方法的IoU和Acc值的差异较小,并且表3中的10幅图像的尺寸为500像素×500像素,仅仅是一景遥感图像的万分之一,故视觉效果较差。但细致观察图像1与2的分割结果,本文方法相比其他4种方法可更加准确地分割小规模建筑地物。图像4的分割结果中,由于建筑地物之间间隔较小,很容易造成分割结果中出现不同程度的合并以及边界出现毛边,而ResNet50的分割结果合并与分割边界出现毛边的现象较少。图像5—10中,VGG16+边界预测方法和本文方法的分割结果更接近真值,其边界更准确可辨。
为进一步分析本文提出的多任务网络中的边界距离预测层对上述分割结果的直观视觉作用,可视化VGG16+边界预测方法与本文方法的边界预测层的输出结果如表4所示。

从表4可以看出,VGG16+边界预测方法和本文方法与边界距离真值非常接近,从10组图像中均可观察到完整的建筑地物边界。因此,这也是在同种框架下,加入边界预测层的多任务网络提取的遥感图像建筑地物优于单任务网络的直接原因; 另外,加入边界预测层的多任务网络可充分发挥Unet网络提取建筑地物边界的优势,从而为分割结果预测层提供建筑地物边界的更多几何信息。需注意的是,在图像3,4和10的边界距离图中,本文方法要明显优于VGG16+边界预测的方法,从而侧面验证了具有更深编码与解码层的Unet网络具有较强的提取遥感图像建筑地物细节特征的能力。
2.5 效率分析
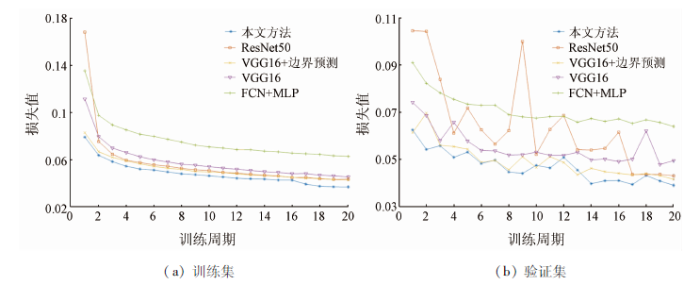
影响基于深度学习的语义分割方法时效性的2个关键因素为将所有训练样本输入到网络训练一个周期所需的时间和网络的收敛速率。为此,不同方法分别在训练集与验证集上进行测试时,其损失值随训练周期增加的变化趋势如图2所示。为了进行公平对比,5种不同方法训练的优化均采用Adam算法。
图2
3 实际应用
河南省新乡市高新区的覆盖范围达52 km2,包含建筑、道路、植被、裸地和水体等多种地物类型。以我国高分2号卫星于2018年4月16日拍摄的该区域实际遥感图像为例,不同方法分割该实际遥感图像建筑地物的实验结果如图3所示。
图3

图3
不同方法的实际遥感图像建筑地物分割结果
Fig.3
Building object segmentation results of a factual remote sensing image by using different methods
结合图3(a)遥感图像的目视解译,从图3可以看出FCN-MLP和VGG16方法存在过分割现象,究其原因是它们将部分道路或邻近建筑地物误分割为同一建筑地物,尤其FCN+MLP方法的误分割现象较为严重; VGG16+边界检测方法,较VGG16方法建筑地物边缘部分更为准确; 而ResNet50方法对建筑地物则存在欠分割现象,这是由于该方法对边缘检测不够准确的缘故。如上节所述,本文方法擅长准确地分割小规模建筑地物,故其对该覆盖范围较大、包含较多类型地物的实际遥感图像的建筑地物分割较为准确。通过对图3(f)像素数目的计算,并与该研究区域2017年的统计年鉴资料对比,本文方法对该实际遥感图像建筑地物的分割准确度Acc值为86.93%。
4 结论
为实现高精度分割遥感图像中建筑地物,本文提出一种多任务学习的基于ResNet50搭建的Unet网络。该网络主要从2方面提高遥感图像的建筑地物语义分割结果: ①采用更深层的ResNet网络搭建Unet网络; ②使用级联多任务学习,使搭建的Unet网络可结合建筑地物的几何边界信息,输入到FCN进行有效语义分割。
实验结果表明,本文方法可使遥感图像建筑地物语义分割结果的IoU均值提高至72.53%,Acc均值提高至96.10%,能够在一定程度上满足实际遥感图像的建筑地物分割的准确性与时效性要求。在实际应用中,对新乡市高新区遥感图像建筑地物的分割准确度达到86.93%。但是,本文网络的深度仍然有限,其边界距离采用的是简单欧氏距离。为此,接下来拟采用ResNet101和ResNet200网络继续加深Unet网络的编码和解码层,以及采用马氏距离等生成边界距离预测图,来提升遥感图像的建筑地物语义分割精度。
参考文献
Fully connected conditional random fields for high-resolution remote sensing land use/land cover classification with convolutional neural networks
[J].
Large-scale oil palm tree detection from high-resolution satellite images using two-stage convolutional neural networks
[J].
基于全卷积神经网络的多源高分辨率遥感道路提取
[J].
Road extraction from multi-source high resolution remote sensing image based on fully convolutional neural network
[J].
DeepGlobe 2018:A challenge to parse the earth through satellite images
[C]//
A multiple-feature reuse network to extract buildings from remote sensing imagery
[J].DOI:10.3390/rs10091350 URL [本文引用: 3]
基于邻域总变分和势直方图函数的高分辨率遥感影像建筑物提取
[J].
Building extraction from high-resolution remotely sensed imagery based on neighborhood total variation and potential histogram function
[J].
High-resolution remote sensing data classification over urban areas using random forest ensemble and fully connected conditional random field
[J].
Stereo-based building detection in very high resolution satellite imagery using IHS color system
[C]//
A review on deep learning techniques applied to semantic segmentation
[EB/OL]. (
Automatic building extraction in aerial scenes using convolutional networks
.[EB/OL]. (
CNN based suburban building detection using monocular high resolution Google Earth images
[C]//
Scene parsing through ade20k dataset
[C]//
Fully convolutional networks for semantic segmentation
[C]//
SegNet:A deep convolutional encoder-decoder architecture for image segmentation
[J].
DOI:10.1109/TPAMI.2016.2644615
URL
PMID:28060704
[本文引用: 2]

We present a novel and practical deep fully convolutional neural network architecture for semantic pixel-wise segmentation termed SegNet. This core trainable segmentation engine consists of an encoder network, a corresponding decoder network followed by a pixel-wise classification layer. The architecture of the encoder network is topologically identical to the 13 convolutional layers in the VGG16 network [1] . The role of the decoder network is to map the low resolution encoder feature maps to full input resolution feature maps for pixel-wise classification. The novelty of SegNet lies is in the manner in which the decoder upsamples its lower resolution input feature map(s). Specifically, the decoder uses pooling indices computed in the max-pooling step of the corresponding encoder to perform non-linear upsampling. This eliminates the need for learning to upsample. The upsampled maps are sparse and are then convolved with trainable filters to produce dense feature maps. We compare our proposed architecture with the widely adopted FCN [2] and also with the well known DeepLab-LargeFOV [3] , DeconvNet [4] architectures. This comparison reveals the memory versus accuracy trade-off involved in achieving good segmentation performance. SegNet was primarily motivated by scene understanding applications. Hence, it is designed to be efficient both in terms of memory and computational time during inference. It is also significantly smaller in the number of trainable parameters than other competing architectures and can be trained end-to-end using stochastic gradient descent. We also performed a controlled benchmark of SegNet and other architectures on both road scenes and SUN RGB-D indoor scene segmentation tasks. These quantitative assessments show that SegNet provides good performance with competitive inference time and most efficient inference memory-wise as compared to other architectures. We also provide a Caffe implementation of SegNet and a web demo at http://mi.eng.cam.ac.uk/projects/segnet.
Multi-scale context aggregation by dilated convolutions
[EB/OL]. (
Rethinking atrous convolution for semantic image segmentation
[EB/OL]. (
Can semantic labeling methods generalize to any city? The inria aerial image labeling benchmark
[C]//
High-resolution semantic labeling with convolutional neural networks
[EB/OL]. (
Classification with an edge:Improving semantic image segmentation with boundary detection
[J].
Large kernel matters:Improve semantic segmentation by global convolutional network
[C]//
Building extraction from multi-source remote sensing images via deep deconvolution neural networks
[C]//
Multi-task learning for segmentation of building footprints with deep neural networks
[EB/OL]. (
U-net:Convolutional networks for biomedical image segmentation
[C]//
Ternausnet:U-net with VGG11 encoder pre-trained on ImageNet for image segmentation
[EB/OL]. (
Building extraction in very high resolution remote sensing imagery using deep learning and guided filters
[J].
Deep residual learning for image reco-gnition
[C]//
Multi-task learning using uncertainty to weigh losses for scene geometry and semantics
[C]//
Imagenet large scale visual recognition challenge
[J].
Boundary-aware instance segmentation
[C]//

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}