

0 引言
在光学遥感影像中,地表有效信息常常被云、雾天气和积雪遮挡,使遥感影像中许多地物特征信息被掩盖。因此,需要对遥感影像中的云、雪、雾区域进行检测,通过剔除无效信息占比过大的影像,从而提高有效遥感数据的使用效率。
1 云、雪、雾特征提取
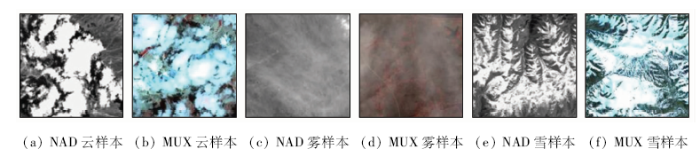
在可见光遥感影像中,云、雪对光线的反射率均达到90%以上,具有十分相似的光谱特征; 雾中的水滴一般比云中的水滴小得多,使云对可见光形成反射,而雾则形成米氏散射,由此引起云、雾的辐射特性的差异。如图1(a)—(d)所示,全色(panchromatic,PAN)与多光谱(multispectral,MUX)影像中云区域比雾区域的平均亮度要高很多,本文通过提取灰度均值、方差等特征量可以区分目标灰度特征的差异。在纹理特征方面,云、雪、雾有着明显的区别。如图1(a),(b)的云样本,其纹理属于随机纹理,多变且难测,表现杂乱没有规律,边缘纹理较粗且模糊; 图1(c),(d)的雾样本纹理则比较均匀,平滑度较好,边缘形态规则; 图1(e),(f)的积雪样本受到地面纹理的影响,具有更好的方向性,梯度变化大。针对上述分析,本文利用梯度、灰度共生矩阵、一阶差分、分数维等纹理特征量来描述目标纹理的复杂度和粗糙程度,对云、雪、雾表现的不同纹理特征进行分辨。
图1
2 面向对象随机森林的遥感影像云、雪、雾分类检测方法
2.1 随机森林算法
随机森林(random forest,RF)[12]是一种高准确度的分类算法,可以用于处理大批量的输入数据,且计算效率高、速度快,目前被广泛运用于各个领域。
RF以CART(classification and regression tree)决策树为基础学习器进行集成学习,决策树是由根节点、中间节点和叶子节点构成的树状数据结构。利用Bagging算法[13]从训练集T中随机获得k个独立同分布的训练子集T={T1,T2,…,Tk},并根据不同的训练子集构造生成对应k棵不同的决策树F={F1,F2,…,Fk}。CART树通过Gini系数作为节点特征选择的标准,如果样本集T中有N种类别实例,Gini系数计算公式为:
式中,P(i)为当前节点上数据集中第i类样本的比例,当特征属性f将样本集合T分为T1和T2两个样本子集时,Gini系数定义为:
选取使Gini系数最小的属性作为该节点的分裂属性,并设定节点阈值和满足停止分裂的标准。对于第i棵CART树,将样本子集从根节点开始训练,如果达到终止条件,则设置当前节点为叶子节点; 如果没有达到终止条件,则利用Gini系数从N维特征中选取一个最佳特征,将当前节点上的样本划分到左、右子节点中,继续训练其他节点,直到所有节点都训练过了或者被标记为叶子节点。所有CART都被训练过后,每棵树能根据节点阈值对测试样本集进行预测,综合每棵树的分类结果投票决定整个随机森林最终的分类结果。
2.2 遥感影像云、雪、雾分类检测
为提高分类检测效率,先对原始遥感影像进行降采样处理,得到该影像对应1 024×1 024像素大小的快视图。基于随机森林的光学卫星遥感影像云、雪、雾分类检测方法的具体过程见下文。
2.2.1 样本集构建
选取大量具有不同特征的云、雪、雾和地物影像对象,对影像对象进行分块处理,得到对象的正方形影像块,构成训练样本集。
2.2.2 特征提取
云、雪、雾和地物具有非常丰富的光谱、几何和纹理信息,利用不同对象的特征差异可以对其进行区分。分析并提取各类样本对象的光谱、几何和纹理特征,将每个样本的特征信息存储在一个向量中,计算所有样本的特征信息,最终得到样本的8维特征向量,本方法选取的特征如下:
1)灰度均值。表示一定大小的图像内所有像素的灰度算术平均值,即
式中: N为一定大小的图像中所有像素的数量;
2)灰度标准差。反映图像各像素灰度值相对于灰度均值的偏离值,即
式中:
3)平均梯度。表示图像细微特征的不同,可以评价图像的清晰程度,即
式中: M,N为图像的长和宽;
4)信息熵。反映图像数据源信息的不确定性,以此衡量数据中的信息量大小,即
式中
5)对比度。反映图像中某个像素和其周边像素的灰度值对比,若对比度高,则图像的亮度信息变化较大,即
式中:
6)逆差矩。反映图像的同质性,并度量图像中纹理变化的大小,即
式中: k为影像的灰度级;
7)自相关性。反映出图像中局部范围内的纹理一致程度,相关度大,则说明图像中部分区域的灰度差异小,灰度分布均匀; 反之则图像灰度值相差大,即
式中: k是影像的灰度级;
8)分数维。表示了纹理的破碎程度,可用来度量图像中纹理特征是否规则,分数维大则图像越破碎,反之图像越光滑,即
式中:
式中
2.2.3 随机森林模型训练和分类
基于随机森林对样本数据集进行训练,构造得到训练后的随机森林云、雪、雾分类模型。选取待检测影像中3×3的结构对象,利用训练好的随机森林模型,输入结构对象的特征向量,统计各决策树的投票结果,得到各结构对象属于云、雪、雾和地物的投票数量,根据各对象属于云、雪、雾和地物得票数多少,对影像对象进行分类划分,遍历以上过程直至影像末端,得到云、雪、雾分类检测结果。
2.2.4 形态学运算
由于云、雪、雾区域内部的光谱特征相似且纹理特征不明显,利用随机森林完成分类后会出现大量云、雾、雪区域的误检。本文利用图像形态学原理,对二值化后的云、雪、雾3幅图像进行先膨胀后腐蚀的形态学“闭”运算,将云、雪、雾的区域连成一片,消除云、雪、雾边缘的噪声区域。
2.2.5 融合云、雪、雾的二值化图像
判断云、雪、雾区域的位置关系,确定目标区域最终类别。融合后的影像中存在部分类别重叠的区域,若某一类区域包含于另一类别的区域范围,则判定该区域与外接区域的类别一致,否则判定原分类结果为该区域的类别,判定后的结果为云、雪、雾的检测范围。本文采用随机森林模型的云雪雾分类检测过程如图2所示。
图2

遥感影像中常常出现“同谱异物”的情况,地物和云、雾、雪样本亮度值非常接近,如图3所示。在随机森林分类器完成第一次检测后,存在部分高亮地物和云、雪、雾区域发生错检,通过增加“二次检测”环节,降低云、雪、雾和地物间的错检率,提高检测精度。“二次检测”是在第一次检测结果的基础上,重新选择云、雪、雾和高亮地物样本,利用随机森林模型分别对云与地物、雾与地物、雪与地物样本进行训练并分类,只有当目标区域的两次检测结果类别判定一致时,才能定该区域为云、雪或雾,否则判定该区域类别为地物。
图3

3 实验结果
3.1 实验数据
本文以国产光学卫星遥感影像数据为研究对象,分别选取1 023幅资源三号(ZY-3)号卫星全色遥感影像,554幅资源一号02C(ZY1-02C)号卫星全色遥感影像,832幅高分一号(GF-1)号卫星多光谱遥感影像和317幅天绘一号01号(TH01-01)卫星多光谱遥感影像作为实验数据(数据来源:
全色影像采用32×32像素的影像块作为基础处理单元,多光谱影像则采用16×16像素的影像块。分别选取1 500个地物样本,1 000个云样本,1 000个雪样本,1 000个雾样本作为训练样本数据,重新选取各500个云与地物、雾与地物、雪与地物样本进行“二次检测”。所有实验均在Inteli7 3960X内存64 GB的高性能计算机平台上完成。
3.2 遥感影像云、雪、雾分类
本文先从降采样后全色、多光谱遥感影像快视图中选取云雪雾和地物样本,计算样本特征信息,利用随机森林模型对实验数据进行训练和分类。通过增加“二次检测”减少云、雪、雾和有效区域之间的错检情况。图4中(a)—(d)分别是随机森林对ZY-3全色影像、02C全色影像、GF-1多光谱影像、TH01-01多光谱影像的一次与二次分类检测结果,其中红色区域表示云,蓝色区域表示雾,紫红色区域表示雪。
图4

图4
不同卫星云、雪、雾分类检测结果
Fig.4
Cloud, snow, fog classification results of each satellite
3.3 实验结果分析
3.3.1 定量评价
以图4中的ZY-3号卫星全色影像分类检测结果为例,采用混淆矩阵法对第一次检测结果和二次检测后的结果进行定量评价,混淆矩阵中列数据表示该类别的真实像素数量,行数据表示遥感影像分类得到的像素个数,如表1和表2所示。从表中可以看出,经过二次检测后的总体分类精度和Kappa系数都要明显高于第一次分类检测的结果。从混淆矩阵中可以发现,经过二次检测的地物错检成云、雪、雾的像元数量减少,正确分类的云、雪、雾像元数量增加。根据混淆矩阵得到分类精度指标,其中第一次检测Kappa系数为0.741,达到分类精度“一般”的标准,而经过二次检测的分类结果Kappa系数达到0.8以上,说明云、雪、雾的检测结果和参考影像中的真实范围很吻合。综上所述,增加二次检测可以有效提高光学卫星遥感影像云、雪、雾的分类检测精度。
表1 第一次检测混淆矩阵
Tab.1
| 类别 | 地物/像素 | 云/像素 | 雾/像素 | 雪/像素 | 总计/像素 |
|---|---|---|---|---|---|
| 地物 | 6 737 349 | 112 378 | 93 557 | 104 046 | 7 047 330 |
| 云 | 175 042 | 898 072 | 55 769 | 15 071 | 1 143 954 |
| 雾 | 100 075 | 86 752 | 214 309 | 1 437 | 402 573 |
| 雪 | 228 746 | 8 250 | 86 | 586 876 | 823 958 |
| 总计 | 7 241 212 | 1 105 452 | 363 721 | 707 430 | 9 417 815 |
| 精度指标 | 总体分类精度: 89.6%; Kappa=0.741 | ||||
表2 第二次检测混淆矩阵
Tab.2
| 类别 | 地物/像素 | 云/像素 | 雾/像素 | 雪/像素 | 总计/像素 |
|---|---|---|---|---|---|
| 地物 | 6 851 716 | 91 773 | 57 012 | 54 405 | 7 054 906 |
| 云 | 171 944 | 928 589 | 48 496 | 14 018 | 1 163 047 |
| 雾 | 92 379 | 78 142 | 258 159 | 1 383 | 430 063 |
| 雪 | 125 173 | 6 948 | 54 | 637 624 | 769 799 |
| 总计 | 7 241 212 | 1 105 452 | 363 721 | 707 430 | 9 417 815 |
| 精度指标 | 总体分类精度: 92.1%; Kappa=0.804 | ||||
3.3.2 检测结果
将从事遥感图像目视解译人员对测试影像判读得到的云、雪、雾范围与本文方法得到的检测结果进行比较,若通过随机森林方法得到的云、雪、雾区域和目视解译范围误差小于±10%,则表示该幅影像检测准确,否则表示检测不合格。表3是本文实验数据的云、雪、雾分类检测结果精度。
表3 各卫星遥感影像云、雪、雾检测精度
Tab.3
| 影像类别 | 传感器 类别 | 影像总 数/幅 | 一检合 格数/幅 | 二检合 格数/幅 | 一检合 格率(精 度)/% | 二检合 格率(精 度)/% |
|---|---|---|---|---|---|---|
| ZY-3 | NAD | 1 023 | 934 | 995 | 91.3 | 97.3 |
| ZY1-02C | NAD | 554 | 488 | 527 | 88.1 | 95.1 |
| GF-1 | MUX | 832 | 752 | 797 | 90.4 | 95.8 |
| TH01-01 | MUX | 317 | 278 | 296 | 87.8 | 93.4 |
当云、雪、雾分类检测精度达到90%以上时,可以将该方法应用在工程实践中。从表3中可以看出,利用随机森林方法对遥感影像进行第一次检测之后,只有资源三号和高分一号卫星影像的检测精度略高于90%,而资源二号02C和天绘一号01星的检测精度分别为88.1%和87.8%。经过第二次检测后各卫星遥感影像的检测精度明显提高,其中精度最高的资源三号全色影像达到了97.3%,精度最低的天绘多光谱影像也达到了93.4%。实验测试数据的总数据量为4 361.6 MB,总计算时间3 620 s,平均每幅影像检测时间0.83s。以上检测数据说明本文分类检测云、雪、雾的方法具有较高的精度和效率,能在工程实践中应用。
4 结论
为提高海量遥感数据使用效率,基于随机森林模型对云、雪、雾和地物样本进行训练,再用训练后的模型对数据对象进行投票决策,实现遥感影像的云、雪、雾分类检测。具体结论如下:
1)对遥感影像数据降采样处理,将得到的快视图作为实验源数据,大大减少了实验的数据量,从而降低了样本数据在特征训练和影像数据在分类预测过程中的计算量,显著提高分类检测效率。
2)针对随机森林分类模型第一次检测结果中存在较多误检、错检的情况,本文采用增加第二次检测的策略,有效降低了影像有效区域的错检率。经多颗卫星、大量遥感数据的工程实践证明,本文提出的方法取得了较高的检测精度,具有较好的适用性。
参考文献
An improved method for detecting clear sky and cloudy radiances from AVHRR Data
[J].
Discriminating clear sky from clouds with MODIS
[J].
Probabilistic physically based cloud screening of satellite infraredimagery for operational sea surface temperature retrieval
[J].
Automated cloud classification of global AVHRR data using a fuzzy logic approach
[J].
A feasibility study of daytime fog and low stratus detection with TERRA/AQUA MODIS over land
[J].
用GMS-5气象卫星资料遥感监测白天雾的研究
[J].
Study on detection of daytime fog using GMS-5 weather satellite data
[J].
EOS/MODIS遥感在贵州积雪监测中的应用
[J].
Application of EOS/MODIS remote sensing to snow cover in Guizhou
[J].
NOAA卫星资料云雪识别方法的研究
[J].通过分析NOAA/AVHRR资料中云和雪的光谱特征,在已有的研究成果基础上做了大量的试验分析。针对青海省南部(以下简称青南)的云、雪特征,提出了新的云、雪判别因子,对于区分青南地区的云、雪有较好的效果。
Research on distinguishing between cloud and snow with NOAA images
[J].Based on the research results that already have,the new cloud and snow identificating factors were presented through analysing the spectrum characteristics of cloud and snow in the NOAA AVHRR image,moreover,the experiment proved that the identificating method between snow and cloud is good enough in southern Qinghai,it gained expected effect.
基于分形维数的全色影像云雪自动识别方法
[J].由于云、雪光谱特征在可见光谱段范围内的相似性,全色影像的云检测和云雪识别一直是对地观测遥感数据预处理及应用中的难点之一。细致分析了云、雪的纹理特征,通过训练大量的实验样本获得了表征云、雪纹理特征的分形维数值的统计规律,在此基础上综合考虑云\,雪的纹理特征与覆盖分布规律,提出了一种基于分形维数的全色影像云与积雪自动识别方法。利用"北京一号"小卫星实际图像的测试结果表明,该方法是一种有效的全色影像云\,雪自动识别方法。
Automatic identification of cloud and snow based on fractal dimension
[J].The similarity of spectral feature in visible/near-infrared band between cloud and snow has been an important influence which degrades the recognition accuracy of cloud and snow,especially the panchromatic images.In this paper,a novel and feasible method was presented to automatically identify cloud and snow from panchromatic images.The method made full use of two different analytical techniques:the spectrum threshold segmentation and the texture analysis.These two approaches discriminated the image from two different aspects.At first,the cloud or snow was distinguished from the background utilizing the difference of spectral feature,so the proportion of cloud or snow in the image was got.And then the samples’ fractal dimension which could reflect the texture feature of cloud and snow from an image were calculated to get the distribution of the fractal dimension values.At last,by comparing the proportion with the distribution,the automatic identification of cloud and snow was realized.The experimental results of the actual panchromatic images by Beijing-1 indicate the feasibility and accuracy of the method.The method could be also applied for other high-resolution panchromatic images because of the universality of the texture feature.
基于分形维数的云检测算法
[C].
A cloud detection algorithm based on fractal dimension
[C].
随机森林及其在遥感影像处理中应用研究
[D].
Random forests and its application in remote sensing image processing
[D].
Random forests
[J].
DOI:10.1023/A:1010933404324
URL
[本文引用: 1]

Random forests are a combination of tree predictors such that each tree depends on the values of a random vector sampled independently and with the same distribution for all trees in the forest. The generalization error for forests converges a.s. to a limit as the number of trees in the forest becomes large. The generalization error of a forest of tree classifiers depends on the strength of the individual trees in the forest and the correlation between them. Using a random selection of features to split each node yields error rates that compare favorably to Adaboost (Y. Freund & R. Schapire, Machine Learning: Proceedings of the Thirteenth International conference, ***, 148–156), but are more robust with respect to noise. Internal estimates monitor error, strength, and correlation and these are used to show the response to increasing the number of features used in the splitting. Internal estimates are also used to measure variable importance. These ideas are also applicable to regression.]]>

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}