

0 引言
人口是社会学、地理学、环境学等学科研究的重要基础,准确估计人口对许多国家都具有重要意义。精确的人口空间分布情况,不仅为政府制定合适的人口相关政策奠定重要基础,制定区域长远发展计划提供参考,还对人口分布与社会经济协调发展有着重要的参考价值,为资源配置和行政管理提供依据。目前,世界上大多数国家或地区实现人口调查的主要渠道是统计和分析,包括抽样调查和全体普查2种方式[1]。虽然人口调查和统计具有权威、系统、规范等优势,但是存在时间分辨率低、更新周期长、空间化精度低、不利于可视化和空间分析操作等问题,对人口空间分布的研究难以满足[2]。而人口空间化可以弥补人口统计数据的缺陷和不足,并且可以与其他更精细的空间数据集结合进行分析,以促进人口相关研究的发展。
DMSP/OLS夜间灯光数据最初是用来探测云层对月光的反射以分析云层分布信息,后来被广泛用于获取地表夜间灯光以反映人类活动情况[3],并且证明有着极好的适用性[4]。但是夜间灯光数据的分辨率较低,且存在着像元饱和、溢出等现象,导致单一的夜间灯光数据只适用于大中尺度人口空间化的相关研究[5,6]。目前,基于人口统计数据和空间变量之间的关系来建立数学模型从而获取人口格网数据是研究人口空间化的热点。常用的方法主要有多源数据融合法[7,8]、夜间灯光与土地利用结合方法[9,10]、空间插值模型[11]等。此外,部分学者结合传统最小二乘线性(ordinary least square,OLS)全局模型将人口统计数据重新分配在地理空间上,默认模型所有参数都不随地理位置变化,即在空间上是平稳的,保持全局一致性,导致各变量在不同位置上的“平均行为”[12]。有些学者利用局部地理加权回归(geographically weighted regression,GWR)建模的方法进行人口数据空间化研究,默认所有参数在不同地理空间位置是不一样的,具有空间非平稳性[13,14],而实际上有的变量在不同地理空间位置的参数是相同的,即具有全局效应。也有学者使用分区建模对变量特征进行重分类,优化原有模型方法[15,16],尽管强调了分区间的差异,但是对分区内的差异仍然无法揭示[17]。因此,鉴于上述空间化方法的优缺点,本研究考虑变量的空间平稳性,采用变量的局部和全局模式进行混合地理加权回归,以提高人口空间化精度。
综上,本文旨在利用夜间灯光数据、土地利用数据和人口统计数据,基于半参数地理加权回归模型(semi-parametric geographically weighted regression,S-GWR),提出了一种新的考虑参数平稳性的人口精确空间化方法,以四川省为研究区域进行比较和验证。本文以夜间灯光与土地利用数据为权重因子,建立人口模型; 在分析变量特征的基础上,采用S-GWR模型处理变量的空间平稳性,减少区域误差。最后生成四川省2010年1 km分辨率的人口空间分布图(spatial distribution of population,SDP),并利用2个常用的数据集进行县乡分级精度验证。此外,本文通过OLS,GWR和S-GWR 3种回归模型进行比较和评价,分析不同模型的变量参数不同对人口空间化的影响。
1 研究区概况及数据源
1.1 研究区概况
四川省位于中国大陆西南腹地,地处长江上游,青藏高原和长江中下游平原的过渡带,介于E97°21'~108°33'和N26°03'~34°19'之间,总辖区面积约484 144.02 km2。辖区有21个市级行政区,包括18个地级市和3个少数民族自治区,共计181个县级行政区[18]。四川省具有联动东西、带动南北的区位优势,是我国实施西部大开发战略的重点地区之一,是中国“一带一路”倡议下的丝绸之路的重要陆上出口区域[19]。四川省是中国西部人口重要的聚居地之一,2010年常住人口8 041.75万人,其中城镇人口3 231.2万人,农村人口4 810.55万人。由于经济和地理上的差异,总体呈现川东地区人口密度高于川西地区的格局。四川省地震、洪涝和泥石流等自然灾害多发,加上其地形地貌复杂,所以研究四川省的人口空间分布可以为防灾减灾提供技术支持和维持区域平衡发展提供决策。
1.2 数据源及其预处理
1)夜间灯光数据。本研究使用的夜间灯光数据(图1(a))来源于美国地球物理国家数据中心(National Geophysical Data Center,
图1
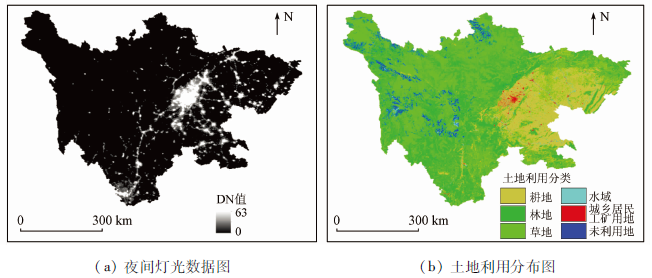
图1
四川省夜间灯光数据图和土地利用分布图
Fig.1
Night light data map and land use distribution map of Sichuan Province
3)人口统计数据。本研究的人口统计数据指的是常住人口数据,来源于四川省统计局的《四川省统计年鉴2010》。由于行政单元边界与人口普查数不据不完全匹配,需要利用ArcGIS软件将属性数据与行政单位相应的空间数据进行关联,最终获得181个县有效数据。
4)行政区划数据。县乡两级行政区划数据来源于原国家测绘局。
5)其他辅助数据。本研究还采用中国科学院资源环境科学数据中心发布的中国格网人口分布数据集(grid population distribution of China,CGPD)和美国国际地球科学网络中心发布的第四版世界格网人口(grid population of world,GPWv4)。将上述数据集投影为 Krasovsky_1940_Alebers 坐标系,采用双线性重采样算法将分辨率重采样为1 km,然后根据研究区域行政边界对影像进行提取。具体数据如表1所示。
表1 数据类型及来源
Tab.1
| 数据类型 | 数据年份 | 分辨率 (比例尺) | 数据来源 |
|---|---|---|---|
| DMSP/OLS数据 | 2010年 | 30″ | 美国地球物理国家数据中心 |
| 土地利用数据 | 2010年 | 1:10万 | 中国科学院资源环境科学数据中心 |
| 人口统计数据 | 2010年 | 县、乡镇 | 四川省统计局 |
| 行政区划 | 2010年 | 1:10万 | 原国家测绘局 |
| CGPD | 2010年 | 1 km | 中国国家资源环境科学数据中心 |
| GPWv4 | 2010年 | 30″ | 美国国际地球科学网络中心 |
2 空间化方法与模型构建
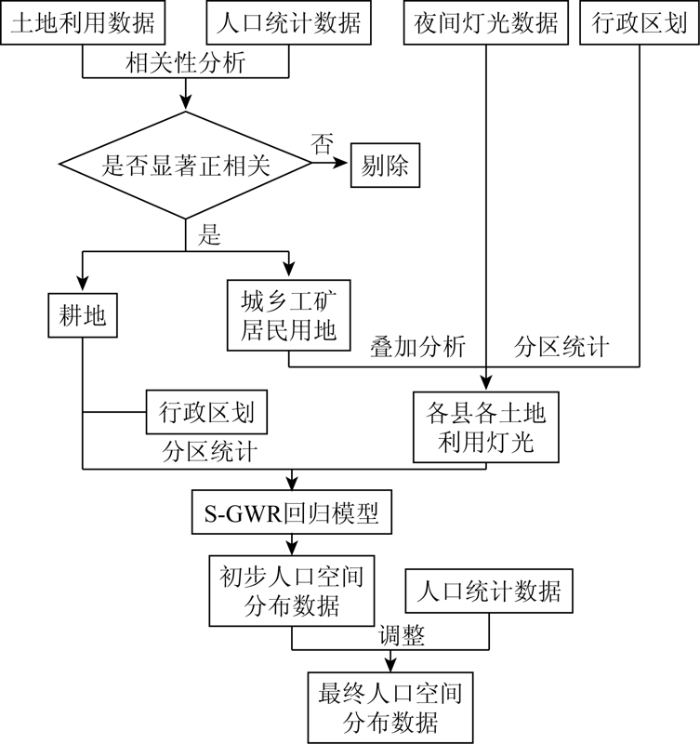
在SPSS软件下,将土地利用和人口数据进行相关性分析,得出与人口分布显著正相关的土地利用类型。然后基于ArcGIS提取DMSP/OLS的亮元、暗元和灯光辐射区域,再与选定的土地利用类型进行叠加分析,得到各土地利用类型的灯光。通过行政区划分区统计后,将变量空间平稳性纳入人口空间化模型,利用GWR4.0软件对变量进行地理变异性检验,以区分变量的全局和局部模式,最后通过S-GWR模型生成研究区的像元人口数据。具体流程如图2所示。
图2
2.1 相关性检验与空间叠加分析
本研究利用皮尔逊相关系数(Pearson correlation coefficient,PCC)检验方法来获取与人口相关的土地利用类型。在统计学中, 皮尔逊相关系数可简称为相关系数 (R), 是一个用来衡量变量x和y之间的线性相关关系的指标。计算公式为:
式中: R为相关系数的值; xi为第i县的统计人口数据; yi为第i县的某一土地利用类型面积; n为县的个数。
根据人口分布的实际情况,本研究在土地利用数据与人口统计数据叠加过程中,水域和未利用土地不参与空间化分析。利用ArcGIS将不同土地利用类型面积根据县界进行分区统计,基于SPSS软件对土地利用与人口进行相关性检验。然后通过ArcGIS提取DMSP/OLS数据的灯光区、无灯光区和灯光辐射区,选取与人口数据显著正相关的土地利用类型,采用空间分析工具中的叠加分析,将上述数据分别进行叠加统计,根据县级行政区划数据进行分区统计,最后得到各区县各类土地的灯光区面积像元数(the number of light pixels,NL)、无灯光区面积像元数(the number of unlit pixels,NU)和灯光辐射总亮度值(light emission in pixels,LE)。在实际人口分布中,人口只存在于城乡及建设用地等建成区,而本研究考虑了耕地是由于卫星遥感对土地利用产品解译时的精度问题和像元混合问题,忽略了在林地、草地等都有可能存在零星分布农村居民点、农牧民独立房屋、帐篷、毡房等设施,这些分散零星但数量众多的居住设施在1:10万的土地利用中是无法展现出来但又是确实存在的。因此,为了不影响对农村人口估计的低估和对城市人口的高估,将其他土地利用类型赋予一定的权重并纳入人口建模,并基于ArcGIS在县一级对其面积进行分区统计。
2.2 人口空间化模型
全局OLS模型是假定全部变量之间的空间关系都是稳定的,即得到的回归系数估计值就是整个研究区域内的平均值。而GWR模型是全局回归模型的扩展,即在计算回归参数时加入变量的空间地理位置信息,使得不同地理位置的回归参数值不同,因而提高人口空间化建模的精度。然而,由于生活环境和经济水平的不同,参数在不同地理位置有可能是会发生变化的,也有可能是固定的。因此,本研究利用混合固定系数和变化系数的S-GWR模型对人口空间化进行建模。与单纯性的全局或局部的方法相比,混合全局固定参数和局部变化参数实现了半参数空间平稳,而且模拟效果比其他模型表现得更好。在建立模型之前有必要对统计人口数进行空间自相关检验,采用ArcGIS软件中的空间统计工具分析空间自相关情况,通过Moran’s I指数值反映出研究区人口分布的集聚程度,取值范围介于[-1,1]之间。S-GWR模型计算公式为:
式中: pi为第i县的估计人口数; m为模型中变量的个数; k为模型中全局变量的个数; αl为第l个全局变量zil的固定系数; (ui,vi)为第i县的质心坐标; xij为第i县的第j个局部变量; βj(ui,vi)为第j个局部变量xij的地理变化系数; εi为满足球面摄动假设的随机误差。此外,当k=0时,式(2)就变成了局部GWR模型。
计算出像元级的估计人口数据后,对初步估计人口结果进行优化和校正,确保预测的SDP总人口等于县级行政单位的人口普查数据。计算公式为:
式中: po
为区分变量的全局和局部模式,基于GWR4.0软件对全部变量进行地理变异性测试。具体参数模型设置是选用自适应的二次平方空间核函数(Bi-square)进行建模,带宽选取采用默认的黄金分割搜索程序,以赤池信息量准则(Akaike information criterion,AIC)作为信息评价准则,决定系数R2和调整决定系数adjR2对回归性能进行评价。其中,在样本小的情况下,AIC转变为AICc,AICc值可以反映模型的拟合优度和模型复杂度,在针对同一套因变量和自变量数据时,根据经验法则,当差值大于或等于3,就表明模型有了明显改善。
2.3 精度评价
对得到的模拟结果有必要进行精度评估和误差分析,除了上述提到的相关系数R、调整决定系数adjR2、赤池信息量准则AICc等对模型进行评估外,本研究还选取平均绝对误差(mean absolute error,MAE)、平均相对误差(mean relative error,MRE)、均方根误差(root mean square error, RMSE)、相对误差(relative error,RE)、平均误差(mean error,ME)来对结果进行评价。计算公式如下:
式中: n为研究区域县的个数; pi为第i个县的人口估计数据;
3 结果与讨论
3.1 模型自变量参数
3.1.1 人口与土地利用相关性
通过SPSS软件计算各土地利用类型和人口之间的相关性,考虑到人口分布的实际情况,水域和未利用土地未参与相关性分析。结果表明,耕地下的2个二级子类(水田、旱地)和城乡工矿居民用地的3个子类(城镇用地、居民用地、其他建成区)同人口数据显著正相关,而林地、草地、水域和未利用土地均与人口显著负相关或不相关。其中,在双尾检测时,城乡居民工矿用地下的其他建成区检测结果显示为不相关,但在单尾检测时结果是显著正相关的。因此,为了提高对人口估计的精度,本研究将其作为一个变量纳入人口空间化模型。表2显示了土地利用与人口之间的相关性。
表2 各土地利用类型与人口数据的相关系数
Tab.2
| 土地利用类型 | 相关系数 | 土地利用类型 | 相关系数 |
|---|---|---|---|
| 水田 | 0.734**① | 中覆盖度草地 | -0.448** |
| 旱地 | 0.555** | 低覆盖度草地 | -0.323** |
| 有林地 | -0.438** | 水域 | — |
| 灌木林 | -0.488** | 城镇用地 | 0.554** |
| 疏林地 | -0.108 | 农村居民用地 | 0.387** |
| 其他林地 | -0.115 | 其他建成区 | 0.144* |
| 高覆盖度草地 | -0.356** | 未利用地 | — |
①**表示在 0.01 级别(双尾)相关性显著; *表示在 0.05 级别(单尾)相关性显著。
3.1.2 空间模型参数
对人口做自相关检验,得到县级人口Moran’s I指数值为0.358,z值为21.95,表示人口数据在0.01水平上显著自相关,说明181个县域的人口分布具有明显的集聚性。在分析土地利用与人口数据的相关性后,选取城镇用地、农村居民用地、其他建成区与DMSP/OLS灯光数据进行叠加分析,得到3个子类的灯光区面积像元数(NL)、无灯光区面积像元数(NU)、灯光辐射总亮度值(LE)。然后对水田和旱地赋予一定的权重,将上述11个参数作为人口空间化模型的变量。基于GWR4.0软件对全部变量进行参数估计及参数平稳性检验,利用参数在没有空间变异性的情况下,参数的F统计量就遵循一定自由度的F分布,最后通过“DIFF of Criterion”结果以区分全局变量和局部变量(表3)。结果表明,城镇用地NU和其他建成区的LE,NL,NU的“DIFF of Criterion”大于2,说明在空间上不具备空间非平稳性,故将其作为全局变量,而将其余7个变量作为S-GWR模型的局部变量。此外,可以通过AICc值来选取最优带宽值,本研究最佳带宽值为62。基于GWR4.0软件进行地理变异性测试结果如表4,该表显示了全局OLS、局部GWR和半参数混合S-GWR模型的性能及拟合优度,评价标准包括R2,adjR2和AICc值。当所有变量都作为全局变量的时候,OLS回归模型的解释力达到0.798; 当把所有变量作为局部变量时,考虑到变量的局部影响,解释力进一步增加到0.877,而AICc值从4 846降到了4 810,模型得到显著提升; 而当采用变量的混合模式时,S-GWR模型的解释力增加为0.903,同时AICc值下降到4 786。虽然全局OLS模型和局部GWR模型都能得到较好的人口空间化结果,但是S-GWR模型进一步提高了人口空间化的解释力,并且提高了人口空间化的精度。因此,考虑参数的空间平稳性,能够使得模型拟合得更好。
表3 地理加权模型参数估计及参数平稳性检验
Tab.3
| 变量 | F统计量 | F检验自由度 | DIFF of Criterion |
|---|---|---|---|
| 水田 | 2.755 253 | 2.266 149.509 | -0.721 729 |
| 旱地 | 6.148 736 | 2.850 149.509 | -11.687 572 |
| 城镇用地LE | 22.965 443 | 2.377 149.509 | -49.330 235 |
| 城镇用地NL | 11.587 845 | 2.045 149.509 | -20.590 824 |
| 城镇用地NU | 1.382 923 | 1.882 149.509 | 2.441 081 |
| 农村居民用地LE | 1.663 454 | 0.495 149.509 | 0.483 673 |
| 农村居民用地NL | 0.761 547 | 0.615 149.509 | 1.267 335 |
| 农村居民用地NU | 5.406 091 | 3.707 149.509 | -11.939 404 |
| 其他建成区LE | 0.089 571 | 2.341 149.509 | 6.646 620 |
| 其他建成区NL | 0.666 850 | 2.706 149.509 | 5.785 913 |
| 其他建成区NU | 0.627 823 | 1.342 149.509 | 2.966 391 |
| 最优带宽 | 62.000 | 最小AICc | 4 786.266 |
表4 3种模型的拟合优度评价
Tab.4
| 评价指标 | 全局OLS | 局部GWR | 半参数S-GWR |
|---|---|---|---|
| R2 | 0.798 | 0.877 | 0.903 |
| adjR2 | 0.785 | 0.843 | 0.867 |
| AICc | 4 846.167 | 4 810.764 | 4 786.267 |
3.2 人口空间化结果
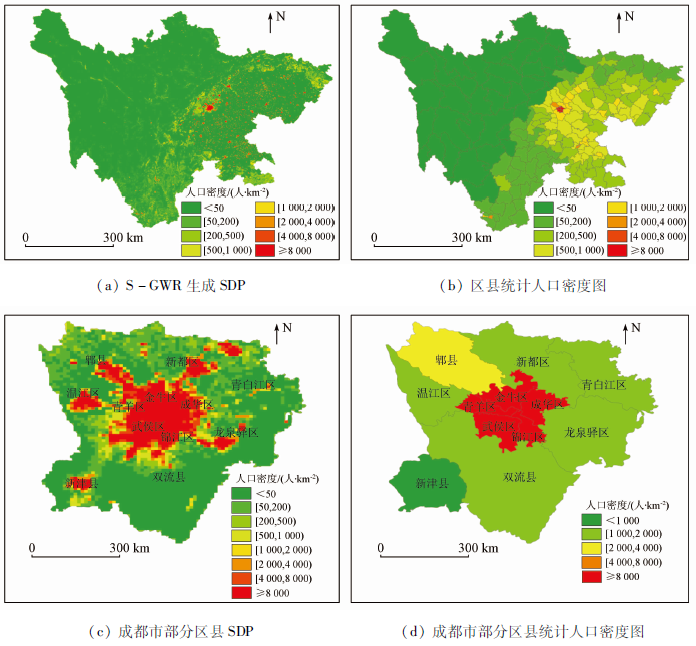
基于土地利用和DMSP/OLS数据,利用S-GWR模型生成了四川省2010年的SDP(图3(a)),和人口统计数据的人口密度分布图相比较(图3(b)),两者有相同的人口分布趋势,但是前者更突出了人口分布的细节。为了可以更清晰地看到两者的区别,提取了成都市部分区县SDP(图3(c)),并与县级统计数据人口密度图进行对比(图3(d)),可以看出人口空间分布情况大致相同,但是SDP可以提供更小的像元人口密度,将人口分配到了更细致的空间尺度上,更符合实际人口的分布情况。人口主要集中在居民地和城镇建设用地上,各区县的人口密度高值区主要集中在县城所在地,同时,人口空间分布图显示的中心城区与周边城区人口密度变化更加自然,印证了当代中国人口分布的实际情况。而稀疏零散的农村人口则被分配到耕地上,大多是无光或者光值很低的农村地区。当与夜间灯光数据(图1(a))比较时,灯光越亮的地方,人口密度越高,人口密度低的地方,灯光亮度也相应较低。因此,利用S-GWR模型来生成人口空间分布图在很大程度上符合人口实际分布。
图3
3.3 分级验证评估
精度评估是人口空间化研究的重点也是难点,基于前人的经验和方法,本研究2010年世界格网人口第四版GPWv4和中国格网人口分布数据CGPD,分别在县乡两级进行对比验证。此外,县乡人口统计数据默认为真实人口数据。
在县一级,分别计算了3种数据结果在研究区内的所有区县的RE。为了揭露误差的细节和总体情况,将3种数据的相对误差用箱线图表示出来(图4(a)),图中散点代表每个区县的相对误差值,两端的短横线代表最大值和最小值,而1%~99%之间的误差显示在交叉线中。可以看出,GPWv4的RE最大是0.7,最小是-0.42,ME为1%; CGPD的RE最大是0.58,最小是-0.4,CGPD的ME为7%。而由于SDP人口经过式(3)的系数调整,其RE和ME都接近于0。另外2种数据集对区县不同程度的高估或低估,可能是由于这些县的人口密度与其他县的人口密度不一致,影响人口分布的因素不一样,不能很好地从基于回归模型中得出。上述3种数据都分别经过不同方法的调整,但通过上述分析可以知道,通过县级人口统计数据来调整SDP是有必要的。在乡镇一级,根据随机数的生成,随机选取500个乡镇进行精度评价。将500个乡镇的人口统计数据视为真实人口值,分别计算估计人口与统计人口之间的RE,并分级统计分析,再分别计算整体的MAE,MRE,RMSE。
图4
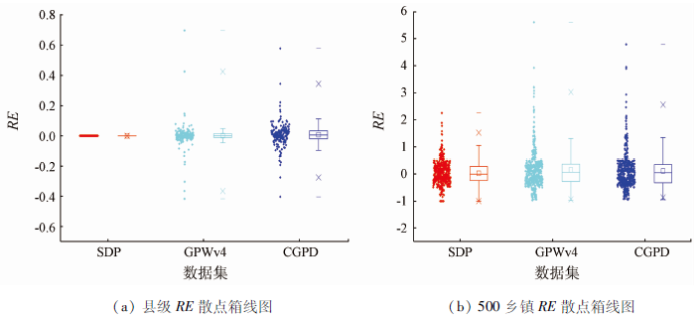
表5统计了3种数据集的误差指标,可以看出SDP的3种误差均小于其他两种数据集,GPWv4和CGPD的MRE分别为47.48%和45.43%,而用S-GWR得到的SDP仅为34.54%; 在MAE方面,GPWv4和CGPD分别为7 997.774人和7 256.342人,而SDP为5 715.703人; RMSE可以反映预测结果与实际数据的偏差,GPWv4和CGPD分别为18 846.285人和16 997.919人,两者有相似的离散度,而且均高于SDP的12 085.932人。由此可以看出,SDP比其他两种数据得到的结果更好,精度更高,说明SDP预测人口更接近于人口普查数据,具有更高的可信度。
表5 3种数据集精度对比
Tab.5
| 误差指标 | SDP | GPWv4 | CGPD |
|---|---|---|---|
| MAE/人 | 5 715.703 | 7 997.774 | 7 256.342 |
| MRE/% | 34.54 | 47.48 | 45.43 |
| RMSE/人 | 12 085.932 | 18 846.285 | 16 997.919 |
为了可以直观地看出3种数据的在局部乡镇上的差异和细节,同样将乡镇误差显示在箱线图中(图4(b))。可以看出,GPWv4的相对误差最大是5.61,最小是-0.97,CGPD的相对误差最大是4.79,最小是-0.94,SDP的相对误差最大是2.26,最小是-0.88。异常值分布在高值区域,低值区域无较大差别,且大多都是由于对人口的高估所导致,说明GPWv4和CGPD这2种全球性数据集不适合在局部进行回归,而SDP由于考虑了回归变量的非平稳性,在局部获得了较好的结果。SDP比另外2种数据的散点分布更集聚一些,其相对误差更集中在0附近,与真实人口数据比较接近。
表6 500个乡镇相对误差分级统计表
Tab.6
| 相对误差分级 | SDP | GPWv4 | CGPD |
|---|---|---|---|
| 严重低估 | 48 | 51 | 56 |
| 一般低估 | 97 | 101 | 114 |
| 准确估计 | 185 | 151 | 158 |
| 一般高估 | 107 | 107 | 97 |
| 严重高估 | 63 | 90 | 75 |
图5
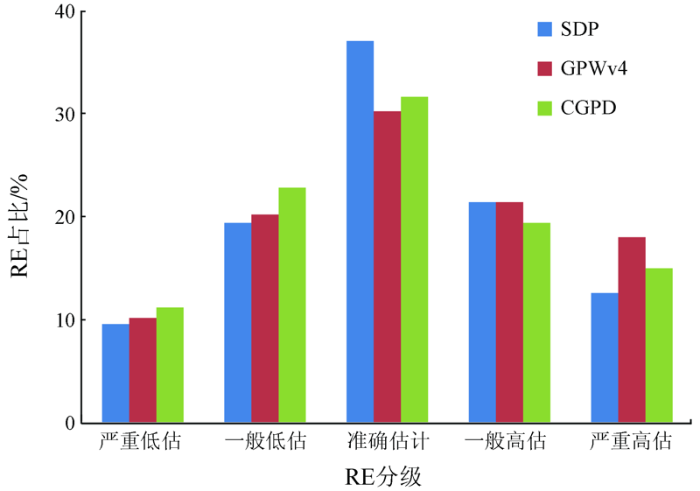
SDP的乡镇误差分级统计个数分别是48,97,185,107和63个,误差占比为9.6%,19.4%,37%,21.4%和12.6%; GPWv4分别为51,101,151,107和90个,误差占比为10.2%,20.2%,30.2%,21.4%和18%; CGPD分别为56,114,158,97和75个,误差占比为11.2%,22.8%,31.6%,19.4%和15%。可以看出,3种结果均存在不同程度的高估,而人口高估的乡镇大多位于青藏高原东部和邛崃山脉以西的川西高原。此外,分析出现明显高估和明显低估的原因可能与该地区的气候、海拔等其他影响人类分布的因素有关。在3种数据结果中,SDP准确估计的乡镇最多,多达185个,占比达到了37%,出现低估和高估的乡镇个数比另外两个数据集要少,而且分布更为分散。因此,考虑参数的空间平稳性可以较好的提高人口空间化的精度和减少对乡镇人口的高估。
4 结论
1)Pearson相关检验结果显示了土地利用类型与人口分布之间的相关性。研究选取了与人口显著正相关的土地利用类型作为模型变量,根据建模结果表明,考虑人口分布建模的时候不应该只考虑与人口正相关的土地类型,其他土地类型林地、草地甚至水域都可能有人口分布。
2)该模型与传统的全局模型和局部模型相比,其考虑了空间变量的平稳性,将全局变量和局部变量混合起来,通过局部变量在不同空间地理位置上的系数不同来提高人口空间化精度。基于GWR4.0软件得出3种模型拟合优度,结果表明, S-GWR模型的拟合效果最优,决定系数R2和AICc值分别为0.903和4 786.263,较其他2个传统模型均有明显提升,进一步提高了对人口空间化的解释力。
3)本研究对SDP进行了分级精度评估。在县一级,GPWv4和CGPD这2种数据集的ME分别为1%和7%,而由于人口系数的调整,SDP的ME接近于0。在乡镇一级,随机生成的500个乡镇中,与GPWv4和CGPD相比,SDP准确估计的乡镇个数最多,达37%,极端乡镇(严重低估和严重高估)数量较少,低估和高估乡镇个数都分别比另外2个数据集要少。在RE方面,SDP的RE最大是2.26,最小是-0.88,比另外2种数据集的范围要小; 在MAE方面,SDP,GPWv4和CGPD的误差分别为5 715.703人,7 997.774人和7 256.342人; 在MRE方面,SDP,GPWv4和CGPD的误差分别为34.54%,47.48%和45.43%; 在RMSE方面,SDP,GPWv4和CGPD的误差分别为12 085.932人,18 846.285人和16 997.919人。总的来说,SDP在人口预测方面比另外2种数据表现得更好,证明了S-GWR模型生成的SPD在准确重新分配人口方面优于其他数据集。
本研究使用S-GWR模型方法,可用于在区域尺度上产生地理空间细节不同的网格人口,其人口估计结果比传统模型精度更高、效果更好,对生态学、灾害评价等相关研究具有重要意义。但夜间光照和土地利用数据在全球范围内都是免费提供的,因此更适合缺乏详细数据的大规模人口空间化。因此,在未来可以利用更高分辨率和更高精度的数据进行研究,也可以从影响人口分布因素方面以进一步提高人口空间化的精度。
参考文献
基于随机森林模型的珠江三角洲30 m格网人口空间化
[J].
DOI:10.18306/dlkxjz.2017.10.012
[本文引用: 1]

人口空间化是实现人口统计数据与其他环境资源空间数据融合分析的有效途径。本文选取夜间灯光数据、道路网数据、水域分布数据、建成区数据、数字高程模型和地形坡度数据作为影响珠江三角洲人口分布的变量因子,利用随机森林模型对珠江三角洲2010年人口数据进行了30 m格网空间化,并将模拟结果与三个公开数据集作精度对比,最后基于随机森林模型的变量因子重要性分析珠江三角洲人口空间分布的影响因素。结果表明:本文模拟整体精度达到82.32%,均优于WorldPop数据集以及中国公里网格人口数据集,接近GPW数据集,而且在人口密度中等区域模拟精度最高;通过对变量因子重要性进行度量,发现夜间灯光强度是珠江三角洲人口分布的最重要指示性指标,到水域的距离、到建成区的距离和路网密度对珠江三角洲人口分布均具有重要作用。利用随机森林模型结合多源信息能够实现高空间分辨率的人口空间化,可为精细化城市管理提供重要数据源,也可为相关政策决策制定提供支持。
Spatialization of 30 m grid population in Pearl River Delta based on stochastic forest model
[J].
人口数据空间化研究综述
[J].
DOI:10.11820/dlkxjz.2013.11.012
[本文引用: 1]
人口数据空间化研究旨在发掘和展现人口统计数据中隐含的空间信息,并以地理格网或其他区域划分的形式再现客观世界的人口分布,具有重要的科学意义。人口空间分布数据有助于从不同地理尺度和地理维度对人口统计数据形成有益补充,其应用广泛,相关研究方兴未艾。主要从以下3 个方面对人口数据空间化研究进行综述:① 主要空间化方法的原理及其适用性;② 空间化中用到的建模参考因素,并结合具体应用案例分析其作用机理;③ 典型人口空间化数据集。在此基础上,分析了现阶段人口数据空间化所运用的输入数据的质量和详细程度、尺度效应及时空分辨率、长时间序列数据集和精度检验等方面存在的问题;并探讨了人口数据空间化未来的研究方向。
Research progress in spatialization of populationdata
[J].
基于夜间灯光数据的人口空间分布研究综述
[J].DOI:10.6046/gtzyyg.2019.03.02 [本文引用: 1]
A survey of population spatial distribution based on night light data
[J].DOI:10.6046/gtzyyg.2019.03.02 [本文引用: 1]
Radiance calibration of DMSP-OLS low-light imaging data of human settlements
[J].DOI:10.1016/S0034-4257(98)00098-4 URL [本文引用: 1]
Mapping urbanization dynamics at regional and global scales using multi-temporal DMSP/OLS nighttime light data
[J].DOI:10.1016/j.rse.2011.04.032 URL [本文引用: 1]
基于土地利用数据和夜间灯光数据的人口空间化模型对比分析——以黄河三角洲高效生态经济区为例
[J].
Comparison of population spatialization models based on land use data and DMSP/OLS data respectively:A case study in the efficient ecological economic zone of the Yellow River Delta
[J].
基于多源遥感数据及DEM的人口统计数据空间化——以浙江省为例
[J].
Spatialization of population statistics based on multi-source remote sensing data and DEM:A case study of Zhejiang Province
[J].
基于多源遥感数据的武汉市人口空间分布格局演化
[J].
Spatial distribution pattern evolution of Wuhan population based on multi-source remote sensing data
[J].
基于夜间灯光与LUC数据的川渝地区人口空间化研究
[J].
DOI:10.12082/dqxxkx.2018.170224
[本文引用: 1]
高精度的人口空间分布数据是开展小尺度人口活动变化规律研究的关键数据。夜间遥感影像对于反映人类社会活动具有独特的能力,因而被广泛的应用于社会经济领域的空间数据挖掘。本研究以DMSP/OLS夜间灯光数据、NPP/VIIRS夜间灯光数据、常住人口统计数据、土地利用数据为数据源,在县级尺度上建立逐步回归模型,构建川渝地区人口空间分布数据;并随机抽取研究区内500个乡镇,以常住人口统计数据为真实数据,对人口空间化结果进行精度检验。结果表明:① 2种夜间灯光数据与人口均有较高的相关性,相关系数均在0.76以上,NPP/VIIRS夜间灯光数据与人口的相关性要高于DMSP/OLS,且受拟合模型的影响不大。② 与人口相关性较高的土地利用类型有多种,耕地、林地对人口空间分布也有影响,在建模时不应只考虑建成区。③ 在2种夜间灯光数据分别与土地利用与土地覆被数据(Land Use/ Land Cover, LUC)结合时,使用DMSP/OLS夜间灯光数据和NPP/VIIRS夜间灯光数据得到的逐步回归模型的复相关系数R<sup>2</sup>分别为0.796、0.817,模型拟合率较高,而基于NPP/VIIRS夜间灯光数据得到的人口空间化结果分辨率(500 m)相比DMSP/OLS提高了一倍(1 km),中心城区与周边城区人口密度变化更加自然,更符合实际人口分布情况。④ 与LUC数据结合时,使用NPP/VIIRS夜间灯光数据得到的人口空间化结果精度要高于DMSP/OLS夜间灯光数据,表明NPP/VIIRS夜间灯光数据相比DMSP/OLS更适用于人口数据空间化研究。
Population spatialization in Sichuan and Chongqing based on night lighting and LUC data
[J].
基于DMSP/OLS与土地利用的江苏省人口数据空间化研究
[J].
Spatial analysis of population data in Jiangsu Province based on DMSP/OLS and land use
[J].
基于土地利用分类模型和重力模型耦合的人口分布模拟——以武汉市人口数据为例
[J].
Population distribution simulation based on coupling of land use classification model and gravity model:A case study of Wuhan population data
[J].
Local forms of spatial analysis
[J].DOI:10.1111/gean.1999.31.issue-4 URL [本文引用: 1]
多元统计回归及地理加权回归方法在多尺度人口空间化研究中的应用
[J].
DOI:10.18306/dlkxjz.2016.12.006
[本文引用: 1]
对统计型人口数据进行格网形式的空间化可更直观地展示人口的空间分布,但不同的人口空间化建模方法和不同的格网尺度在表达人口空间化结果方面存在差异。本文在人口特征分区的基础上,引入DMSP/OLS夜间灯光对城镇用地进行再分类,采用多元统计回归和地理加权回归方法(GWR),开展人口统计数据空间化多尺度模型研究,生成1 km、5 km和10 km等3个尺度的2010年安徽省人口空间数据,并对3个尺度下2个模型结果进行精度评价与比较。结果表明:人口空间数据精度不仅与建模所用方法关系密切,还受到建模格网尺度大小的影响。基于多元统计回归方法的模型估计人口数与实际人口的平均相对误差值随着尺度的增加而降低,而基于GWR方法获得的人口空间数据误差值随着尺度的增加而升高。整体来看,基于GWR方法的1 km研究尺度的人口空间数据平均相对误差最低(22.31%)。区域地形地貌条件与人口空间数据误差有较强的关联,地貌类型复杂的山区人口空间数据误差较大。
Application of multivariate statistical regression and geographically weighted regression in the study of multi-scale population spatialization
[J].
基于土地利用类型的村级人口空间分布模拟——以湖北鹤峰县为例
[J].
DOI:10.3724/SP.J.1047.2014.00435
[本文引用: 1]
在人口分布及其相关研究中,常常会遇到小尺度人口数据部分缺失的问题。本文以湖北省鹤峰县为例,在分析土地利用与人口分布关系的基础上,从全局与局部、线性回归与非线性回归考虑,基于土地利用类型,分别利用地理加权回归(GWR)方法、格网方法、BP神经网络方法对缺失数据的行政村人口数据进行模拟,并进行了多角度精度对比验证。研究结果表明:(1)各种土地利用类型中,耕地、林地、城镇村及工矿用地、交通用地是影响研究区村级人口分布的主要因素;(2)30个调查村中,3种方法模拟的人口总数误差小于3%,通过每个村的模拟值与实际值相比,BP神经网络方法能更好地模拟研究区村级人口的分布,格网方法次之,GWR方法最差;(3)研究区各村人口分布呈现较高的空间正相关性,各乡镇的人口密度在空间上并不独立,而是呈现紧密的集聚特征。
Simulation of rural population spatial distribution based on land use classification:A case study of Hefeng County,Hubei Province
[J].
集成土地利用数据和夜间灯光数据优化人口空间化模型
[J].
DOI:10.3724/SP.J.1047.2015.01370
[本文引用: 1]
人口统计数据空间化是解决统计数据与自然要素数据融合分析的有效途径。随着RS和GIS技术的发展,人口统计数据空间化方法推陈出新,其中,土地利用数据、夜间灯光数据是人口空间化研究中普遍利用的数据源,但各有优、缺点:土地利用数据中的城镇用地、农村居民点能准确表示人口分布的空间范围,却不能反映其内部的人口密度差异特征;夜间灯光数据的强度信息能体现人口分布的疏密程度,但其像元溢出问题显著夸大人口分布范围,像元过饱和现象也影响着人口数据空间化结果的精度。本研究以中国大陆沿海区域为例,尝试集成土地利用数据和夜间灯光数据优化人口空间化方法,设计了基于精度阈值和动态样本的渐进回归与分区建模的方法,获得了中国沿海2000、2005、2010年1 km分辨率人口空间化数据。结果表明,优化模型显著提高了研究区整体的精度,尤其适用于人口空间结构内部差异较为显著的区域。
Integrating land use data and night light data to optimize population spatialization model
[J].
基于夜间灯光与土地利用数据的山东省乡镇级人口数据空间化
[J].
DOI:10.12082/dqxxkx.2019.180497
[本文引用: 1]
格网化人口数据能够刻画实际人口空间分布状况,是实现人口数据更好地与自然、社会、经济等要素融合分析的有效途径。本文面向精细尺度格网人口数据的需求,以中国东部人口稠密的山东省为例,基于乡镇级人口统计数据,研究了结合夜间灯光和土地利用数据的空间化方法。其中以EVI修正DMSP/OLS夜间灯光数据来增加城镇用地内部人口分布的差异性,以城乡二级分区方法避免夜间灯光数据在农村低辐射亮度区模拟人口的缺点,提高了建模精度。利用其余地区的人口统计值检验建模精度,结果有78%的行政单元的相对误差绝对值小于20%。最终在2000年首次公布的乡镇级人口统计数据的基础上,生成了山东省100 m格网人口分布数据SDpop2000。通过与精度较高的全球WorldPop人口数据产品对比可见,SDpop2000和WorldPop在10 km网格尺度上的相关性系数高达0.93;SDpop2000在鲁中部、泰安西南部、济宁南部、临沂南部、枣庄北部和鲁北沿海等地的人口分布明显比WorldPop更准确;且SDpop2000较好地刻画了山东省在鲁西、鲁北平原区的人口较鲁中南山地丘陵区、鲁北沿海和山东半岛丘陵区的人口更为稠密的人口分布趋势。本文构建的基于DMSP/OLS与土地利用的乡镇级人口数据空间化方法明显提高了空间化精度,适用于乡镇尺度的人口精细模拟。
Spatialization of township population data in Shandong Province based on night lighting and land use data
[J].
Research progress and perspective on the spatialization of population data
[J].
川渝地区: “一带一路”和长江经济带的战略支点
[J].
Sichuan and Chongqing region:Strategic fulcrum of the Belt and Road initiatives and Yangtze River economic zone
[J].
2010—2015年中国土地利用变化的时空格局与新特征
[J].
DOI:10.11821/dlxb201805001
[本文引用: 1]
土地利用/覆被变化是人类活动对地球表层及全球变化影响研究的重要内容。本文基于Landsat 8 OLI、GF-2等遥感图像和人机交互解译方法,获取的土地利用数据实现了中国2010-2015年土地利用变化遥感动态监测。应用土地利用动态度、年变化率等指标,从全国和分区角度揭示了2010-2015年中国土地利用变化的时空特征。结果表明:2010-2015年中国建设用地面积共增加24.6×10<sup>3</sup> km<sup>2</sup>,耕地面积共减少4.9×10<sup>3</sup> km<sup>2</sup>,林草用地面积共减少16.4×10<sup>3</sup> km<sup>2</sup>。2010-2015年与2000-2010年相比,中国土地利用变化的区域空间格局基本一致,但分区变化呈现新的特征。东部建设用地持续扩张和耕地面积减少,变化速率有所下降;中部建设用地扩张和耕地面积减少速度增加;西部建设用地扩张明显加速,耕地面积增速进一步加快,林草面积减少速率增加;东北地区建设用地扩展持续缓慢,耕地面积稳中有升,水旱田转换突出,林草面积略有下降。从“十二五”期间国家实施的主体功能区布局来看,东部地区的土地利用变化特征与优化和重点开发区的国土空间格局管控要求基本吻合;中部和西部地区则面临对重点生态功能区和农产品主产区相关土地利用类型实现有效保护的严峻挑战,必须进一步加大对国土空间开发格局的有效管控。
Spatial and temporal patterns and new characteristics of land use change in China from 2010 to 2015
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}