

0 引言
伴随着城市化以及矿产、电镀、冶金等产业的不断发展,因工业和生活污水灌溉、涉重金属企业“三废”排放、矿产开发等原因导致的土壤重金属污染问题已经被广泛关注[1]。重金属因其不易被土壤微生物分解、易于积累的特性,在土壤中不断富集。当土壤中重金属含量超过界限值时,会影响作物对氮、磷、钾营养元素的吸收从而抑制作物的生长,甚至会通过食物链在人体内蓄积,间接危害人体的健康[2]。探寻高效准确地获取大区域土壤重金属含量信息的方法对进行污染风险评价与土壤修复工作具有重要意义。相比于传统实验室理化分析方法,高光谱技术以其快速、无损、无污染、低成本等优势,近年来被广泛的应用于森林生态系统结构参数估算[3]、食品品质检测[4]、煤矿分类[5]和土壤理化性质预测[6,7]等领域中。
然而利用高光谱技术中的可见光—近红外光谱数据建立目标成分定量分析模型时,由于光谱波段数众多,常常面临着建模样本量远远小于光谱变量数而导致模型预测结果不佳的问题。此外由于近红外波段受到C-H,C-O和N-H等官能团的合频和倍频吸收峰相互重叠的影响,波长变量之间高度相关,多重共线性显著[8]。上述问题连同波段中大量存在的无信息与干扰变量将会严重影响模型的可解释性、计算复杂性、稳定性与泛化性能。因此,通过波长选择算法从可见光—近红外全谱数据中优选出最佳波长组合提高预测模型性能显得尤为重要。基于Li等[9]提出的模型集群分析(model population analysis,MPA)策略开发的波长选择算法近年来逐渐展露头角,开始被应用于各类高光谱反演模型之中。于雷等[10]利用迭代和保留信息变量法(iteratively retains informative variables,IRIV)算法对大豆叶片叶绿素含量进行了预测,结果表明IRIV算法能有效保留光谱中与叶绿素有关的弱信息变量,提升模型估测能力; 刘贵珊等[11]对比区间变量迭代空间收缩算法(interval variable iterative space shrinkage approach,IVISSA)、变量组合集群分析法(variable combination population analysis,VCPA)、竞争适应性重加权采样算法(competitive adaptive reweighted sampling,CARS)和连续投影算法(successive projection algorithm,SPA)4种算法估算冷鲜滩羊肉嫩度,得出IVISSA算法的预测精度与模型鲁棒性要高于其他算法。基于MPA的波长选择算法打破了以往基于单一模型或目标函数进行变量筛选的思路,通过大量建立子模型,从模型集总体来分析特定评价参数,并根据参数值赋予各波长高低不同的采样权重,从而逐步优化收缩变量空间,达到特征波长筛选目的。能够充分挖掘出小样本数据的有用信息,减小偶然性误差,提升模型稳定性与泛化性能[12]。
变量空间迭代收缩算法(variable iterative space shrinkage approach,VISSA)[13]、迭代变量子集优化算法(iteratively variable subset optimization,IVSO)[14]、区间组合优化算法(interval combination optimization,ICO)[15]和CARS是4种基于MPA策略的代表性波长选择算法。相比于CARS,另外3种算法在土壤成分高光谱预测研究中鲜有文献报道。因此,本研究以国控重金属污染重点防控区龙海市为研究区,选择重金属Pb为研究对象,综合对比这4种波长优选算法,并联合线性模型偏最小二乘回归(partial least squares regression,PLSR)、非线性模型支持向量机(support vector machine,SVM)和神经网络模型极限学习机(extreme learning machine,ELM),研究各波长选择算法耦合各类型回归模型在土壤重金属反演领域的预测表现,探寻研究区内土壤重金属Pb含量的最佳反演模型,为区域重金属污染高效监测提供理论和技术支持。
1 研究区及其数据源
1.1 研究区概况
龙海市(E117°29'~118°14',N24°11'~24°36')地处福建省东南部,位于九龙江出海口处。中部为冲积平原,北部、西部、南部三面环山,东南部临海,总占地面积约1 128 km2。该地属于亚热带季风气候,年均气温为21.5 ℃,年均降雨量为1 563.2 mm。主要土壤类型包括红壤、水稻土、滨海砂泥及潮土等。龙海市涉重金属企业分布较多,长期以来的污染排放以及农业不合理的耕作施肥等原因,导致龙海市土壤中以Pb为代表的部分重金属含量超出了环境背景值[16]。
1.2 土壤样品采集和理化分析
利用卫星影像图对龙海市进行样本初步布设,共设代表性样本点数79个,涉及土地利用类型耕地、林地、园地等。根据初始布点坐标实地采样时,避开田埂、沟渠及马路边缘等特殊区域,利用蛇形采样法对每个采样点挖取0~20 cm表层土壤5份,每份土样挖取时用竹片刮去与金属制铁铲接触面,均匀混合后用四分法取500 g装进密封袋内作为一份样本。同时利用手持GPS校正样本真实经纬度坐标,最终采集的样本分布见图1。
图1
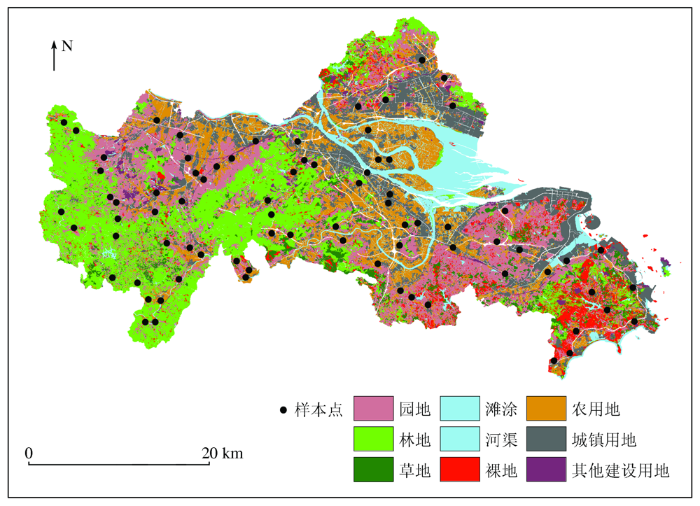
图1
研究区位置及采样点分布
Fig.1
Location of the study area and distribution of soil sampling sites
采回的样本放置室内风干数日,之后去除植物残体、小石块等杂质,用木棒研磨至过100目尼龙筛。研磨后的土样按样本号分成2份,分别用于光谱数据及Pb含量的测定。检测Pb含量时,将土样经氢氟酸-高氯酸-硝酸反复消煮等处理后由电感耦合等离子体质谱仪(ICP-MS)最终测定。
1.3 光谱数据采集
土壤光谱数据的采集使用美国ASD(Analytical Spectral Device)公司生产的ASD FieldSpec 3 Pro地物光谱仪。光谱波段范围为350~2 500 nm,其中350~1 000 nm和1 000~2 500 nm之间采样间隔分别为1.4 nm与2 nm,经光谱重采样后的间隔为1 nm。为了减少非环境光源对光谱测试的影响,实验在一个封闭的暗室内进行。测定前先将光谱仪开机预热15 min以上,之后进行暗电流校准以及对参考板进行优化。将待测土样放置于60 mm规格的玻璃培养皿中,样品浸没深度大于0.5 cm,以免光源透射对光谱测定精度产生影响。选用1 000 W的卤素灯作为光源,卤素灯天顶角为15°,光谱仪探头距离样品10 cm。探头垂直于土壤表面进行测量,每个土壤样品共采集10条光谱曲线,取平均值作为原始光谱数据。由于光谱边缘波段产生了大量不稳定的噪声,所以最终去除边缘波段后取400~2 400 nm范围内共2 001个波段数据进行研究。
2 研究方法
2.1 建模集样本划分与光谱数据预处理
表1 土壤Pb含量统计特征
Tab.1
| 重金属 类型 | 样本集 | 最小值/ (mg·kg-1) | 最大值/ (mg·kg-1) | 均值/ (mg·kg-1) | 标准差/ (mg·kg-1) | 变异系 数/% |
|---|---|---|---|---|---|---|
| Pb | 全样本 | 15.88 | 95.01 | 50.98 | 15.83 | 0.31 |
| 建模集 | 18.87 | 84.39 | 50.80 | 15.46 | 0.30 | |
| 验证集 | 31.99 | 65.48 | 49.50 | 10.72 | 0.22 |
在进行光谱测量时,实验环境、机器自身误差、土壤基质与背景干扰等因素引起的随机噪声会将数据中有用信息遮蔽,从而影响模型回归结果。故本文分别利用Savizky Golay(SG)平滑、小波变换(wavelet transform,WT)、高斯滤波(Gaussian filter,GF)和多元散射校正(multiple scatter correction,MSC)4种预处理方法对原始光谱数据进行处理,以此提升数据信噪比。其中WT变换利用MATLAB2017a软件小波工具箱实现,其余预处理方法采用The Unscrambler X软件完成。
2.2 光谱特征波长选择方法
2.2.1 VISSA
VISSA首次引入了加权二进制采样方法(weighted binary matrix sampling,WBMS),每轮采样根据上轮不同变量在表现最佳的模型集里出现的频率赋予各个变量新的权重,以达到不断优化收缩变量空间的目的,最终获取最优的变量组合。主要步骤如下:
1)利用WBMS对光谱变量空间进行随机采样,每个变量初始采样权重设为0.5,随机采样N次,共生成N个波长变量子集。
2)基于每个波长子集分别建立PLSR模型,计算每个模型的交叉验证均方根误差(RMSECV)。选出RMSECV最低的一部分模型作为最优模型集,选取比例记为α。之后计算每个变量在最优模型集的出现频率,作为下次采样该变量的权重。同时记录最优模型集的RMSECV均值。第k个变量权重计算公式为:
式中: w为权重; f为变量出现在最优模型集的频次; Nbest为最优模型集的数量。
3)重复执行1)—2)步骤,其中WBMS采样权重每轮根据式(1)进行更新,直至新一轮RMSECV均值无法进一步改善。此时根据前一轮采样权重,将权重为1的光谱波段记为信息波段,权重为0的记为干扰波段,其余波段记为弱信息波段。
4)将信息波段、干扰波段、弱信息波段按权重值进行降序排序,从大到小逐个加入变量集建立PLSR模型计算RMSECV,取RMSECV最小值对应的模型变量组合做为最终的特征波长集。
2.2.2 IVSO
IVSO以不同模型变量的回归系数为研究对象进行统计分析,以此决定每一轮迭代不同波长变量的权重,从而逐步优选出最佳波长子集。IVSO的实现步骤为:
1)使用WBMS生成N个波长变量子集,记录该轮WBMS选中的变量数为L1。
2)基于每个波长子集分别建立PLSR模型,建立回归系数矩阵
式中bj(1<j<N)代表第j个波长子集建立PLSR模型每个变量的回归系数绝对值(absRC)。接着将bj中每个变量的absRC进行归一化处理,即
式中: bij为bj中第i个变量的absRC; max(bj)表示bj中所有absRC的最大值; cij为经处理后的bij,所有cij组合成归一化回归系数矩阵
3)在下一次迭代中,变量采样权重被定义为:
式中:
4)重复步骤1)—3),直至L1=L2。比较每轮迭代生成的minRMSECV,最小值对应的波长组合即为最终的特征波长集。
2.2.3 ICO
ICO区别于本文其他波长选择算法,以波长区间代替波长点作为优化对象,利用加权自举采样(weighted bootstrap sampling,WBS)逐步收缩优化波长区间组合,最后结合局部搜索策略进一步优化各个波长区间边缘波段。ICO的具体步骤为:
1)将光谱变量空间均匀分成M个等长的波长子区间。
2)利用WBS从M个波长区间里采样出N个不同波长区间组合,每个波长区间初始权重设置为1。根据权重决定各个波长区间被选中概率,即
式中: 波长数量为n; pk表示第k条波长被选择的概率; wk表示第k条波长的采样权重。
3)基于N个波长区间组合分别建立PLSR模型,计算各个模型的RMSECV,取RMSECV最小值的部分模型集为最优模型集,选取比例记为α。计算每个波长区间在最优模型集内出现的频率,做为下次采样的权重,同公式(1)。同时记录这轮采样最优模型集的RMSECV均值。
4)重复步骤2)—3),直至此轮RMSECV均值高于上一轮。记录上一轮迭代产生的所有模型中RMSECV最小值的模型对应的波长区间组合。
5)基于上一步产生的最优波长区间组合,采用局部搜索策略优化每个波长区间边缘波段,将波长区间边缘相邻的波长点分别纳入或剔除进行建模,通过RMSECV变化来判断该波长点的选入或排除。重复进行数次,直至RMSECV不受波长点的加入或剔除所影响,此时所选中的波长区间组合即为最优特征波长集。
2.2.4 CARS
不同于上述算法从变量空间进行随机采样生成模型子集,CARS利用蒙特卡洛采样法从样本空间随机选取样本建立PLSR模型,之后以变量回归系数大小作为权重判别指标,结合指数衰减函数(exponentially decreasing function,EDF)与适应性重加权采样法(adaptive reweighted sampling,ARS)对低权重样本进行剔除达到变量优选目的。最后通过迭代建立大量子模型确定最优特征波长集。
2.3 回归模型
基于特征波长选择算法优选出的波长子集,选择线性回归模型PLSR、非线性模型SVM和神经网络模型ELM进行土壤重金属Pb含量的预测。其中PLSR与SVM因其应对小样本多变量数据的出色能力,而被广泛应用于高光谱数据的研究之中; ELM是一种前向传播神经网络,由输入层、隐含层及输出层3层网络结构组成。在运行前只需设置隐含层神经元的个数,并且可随机生成输入层到隐含层的权重以及隐含层各节点阈值,省去了反复训练调参的时间,因此具有训练速度快、泛化能力强等优点[18]。
模型评价指标选用决定系数(R2)、均方根误差(RMSE)、相对分析误差(RPD)、四分位相对预测误差(RPIQ)。其中RPIQ为验证集四分位距(第三四分位数与第一四分位数的差值)与RMSE的比值,由于土壤重金属含量分布并不对称,不符合正态分布规律,RPIQ被认为比RPD更适合评价土壤重金属反演模型[19]。R2越接近1,RMSE越小以及RPD和RPIQ越高则模型回归表现越佳。本研究各波段选择算法及回归模型均基于MATLAB2017a软件实现。
3 结果与讨论
3.1 光谱数据预处理结果
基于不同光谱预处理方法分别建立PLSR模型,结果如表2所示。WT中不同基函数的选择,会造成模型结果的差异,通过多次试验比较,最终选用db4作为基小波。光谱数据经WT多尺度分解后,最后通过逆变换得到8层特征光谱,各层重构光谱用WT1~WT8进行表征。由表2可知,除MSC外,其他3种预处理方法模型精度都得到了不同程度的提升,这可能是因为本次实验土壤经研磨后颗粒大小相对均匀,颗粒间散射影响较小造成。其中基于WT7构建的模型回归效果最优,验证集R2相比原始光谱提升了4.69%,RPIQ提高了7.02%。WT7与原始光谱如图2所示。相比于原始光谱图像,重构后的光谱曲线2 200 nm附近因水分子吸收形成的波谷与590 nm处小波峰的特征被淡化,1 420 nm和1 936 nm附近的水分吸收深度也都不同程度的降低,并且波谷向右发生了些微偏移。但同时也平滑了大量的“毛刺”噪声,尤其是2 200~2 400 nm之间光谱曲线变得光滑,使得模型总体信噪比提升,回归精度得到了有效改善,因此后续研究将基于WT7展开。
表2 基于PLSR模型的不同预处理方法
Tab.2
| 预处理 方法 | 建模集 | 验证集 | ||||
|---|---|---|---|---|---|---|
| R2 | RMSE | R2 | RMSE | RPD | RPIQ | |
| None | 0.659 | 8.580 | 0.703 | 5.807 | 1.846 | 2.392 |
| WT1 | 0.659 | 8.583 | 0.714 | 5.655 | 1.896 | 2.456 |
| WT2 | 0.658 | 8.589 | 0.714 | 5.654 | 1.896 | 2.457 |
| WT3 | 0.658 | 8.598 | 0.714 | 5.651 | 1.897 | 2.458 |
| WT4 | 0.657 | 8.611 | 0.714 | 5.655 | 1.896 | 2.456 |
| WT5 | 0.656 | 8.623 | 0.717 | 5.625 | 1.906 | 2.469 |
| WT6 | 0.670 | 8.439 | 0.703 | 5.759 | 1.862 | 2.412 |
| WT7 | 0.665 | 8.502 | 0.736 | 5.426 | 1.976 | 2.560 |
| WT8 | 0.664 | 8.524 | 0.681 | 6.018 | 1.781 | 2.308 |
| SG | 0.667 | 8.458 | 0.723 | 5.604 | 1.913 | 2.479 |
| GF | 0.660 | 8.564 | 0.718 | 5.615 | 1.909 | 2.474 |
| MSC | 0.659 | 8.582 | 0.702 | 5.818 | 1.843 | 2.387 |
图2
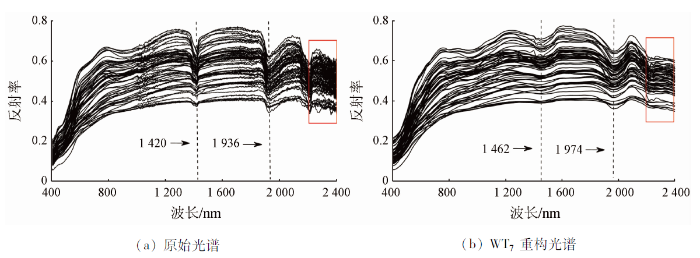
3.2 特征波长优选结果
图3
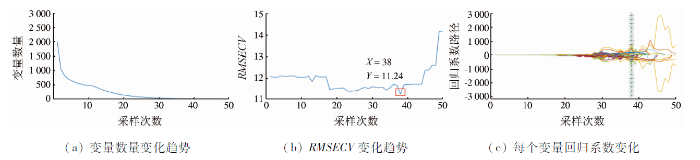
图4
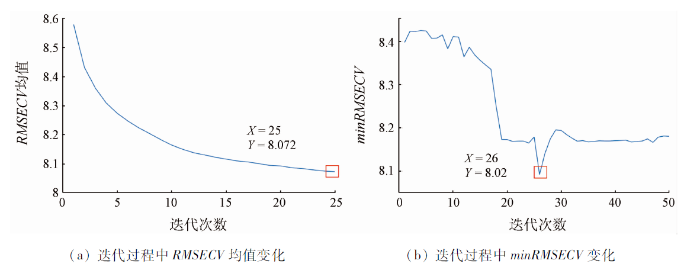
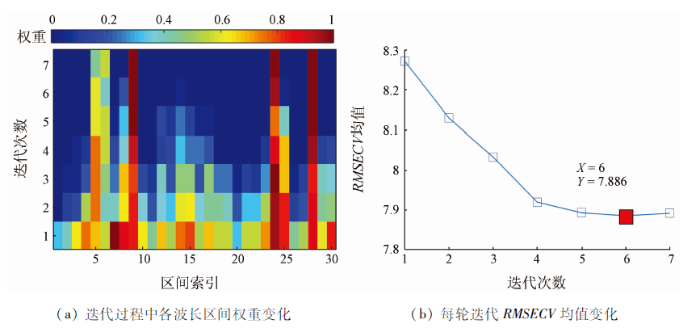
基于ICO进行优选波段时,波长子区间等分数设为30个,WBS每轮采样次数取1 000,最优模型集比例α设为0.05。图5为ICO筛选变量过程。其中图5(a)为每轮采样各区间的权重变化,深蓝到深红的颜色渐变代表权重值随迭代过程进行的不断增大。ICO利用的WBS采样方法相较于WBMS区别在于,即使某一波段因为偶然因素在前一轮采样中权重变为1,在之后的迭代中仍有可能将其排除在外。可以看出第7个子区间采样权重初始为1,但随着不断的迭代,其重要性逐渐降低,权重值在最后一次迭代中归零,因此未被选入最优子区间集,说明ICO在进行波长选择时的容错性较高。图5(b)为每轮迭代RMSECV均值的变化趋势,仅通过6轮迭代便达到收敛条件。可能是因为ICO以30个波长区间为建模对象,相对于全波长,不同变量间的组合计算量要显著下降。
图5
全光谱2 001个波段经过CARS,VISSA,IVSO和ICO这4种波段选择算法优选后变量大大减少,4种算法选出的波段数分别为119,78,98和276个。图6给出了各种波段选择方法优选出的波段分布位置。可以看出波段总体分布范围相似,主要集中在近红外光谱区域904~1 003 nm,1 927~2 055 nm,2 201~2 395 nm及可见光光谱区域627~734 nm这4个区间之内。其中600~800 nm与土壤中有机质相关; 900 nm与1 900 nm附近光谱特性主要受土壤铁氧化物、黏土矿物和有机质的综合影响; 2 250 nm附近除受水分子吸收影响外还与黏土矿物中的O-H基团伸缩振动有关。优选的波段主要分布于这4个区间内可能是因为重金属Pb离子常常吸附于铁氧化物、黏土矿物和有机质这3种物质上,所以与其呈现出较强的相关性。此外,因为光谱采样间隔较短,相邻波段往往蕴含着相似的信息特征,所以各算法选出的波段呈现出一定的连续性。
图6
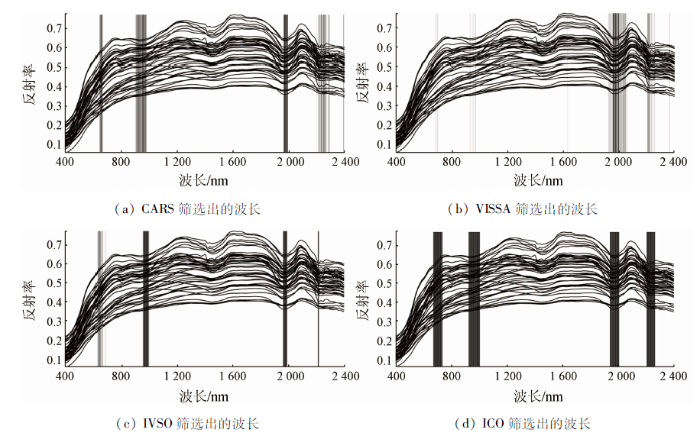
图6
不同波长选择算法优选出的波段
Fig.6
Selected wavelengths of different wavelength selection methods
3.3 回归模型选择
利用CARS,VISSA,IVSO和ICO优选出的波段分别建立PLSR,SVM和ELM这3种回归模型,并将PLSR结合全波段建模结果进行对比,以此探寻波段优选算法的实质表现。其中ELM和SVM模型参数设置如下: SVM核函数选择高斯核; ELM最佳隐含层神经元个数设为20,激活函数选择ReLU函数,结果如表3所示。
表3 3种回归模型联合各波段选择算法预测结果
Tab.3
| 模型 | 波长选择方法 | 变量数量 | 建模集 | 验证集 | ||||
|---|---|---|---|---|---|---|---|---|
| R2 | RMSE | R2 | RMSE | RPD | RPIQ | |||
| 全波段 | 2 001 | 0.702 | 8.450 | 0.736 | 5.426 | 1.976 | 2.560 | |
| CARS | 119 | 0.726 | 6.958 | 0.759 | 5.235 | 2.048 | 2.653 | |
| PLSR | VISSA | 78 | 0.720 | 7.033 | 0.780 | 5.003 | 2.143 | 2.777 |
| IVSO | 98 | 0.718 | 7.050 | 0.802 | 4.748 | 2.258 | 2.926 | |
| ICO | 276 | 0.720 | 7.023 | 0.813 | 4.610 | 2.325 | 3.013 | |
| SVM | CARS | 119 | 0.643 | 7.939 | 0.735 | 5.485 | 1.954 | 2.532 |
| VISSA | 78 | 0.645 | 7.915 | 0.745 | 5.385 | 1.991 | 2.579 | |
| IVSO | 98 | 0.630 | 8.075 | 0.757 | 5.252 | 2.041 | 2.645 | |
| ICO | 276 | 0.631 | 8.069 | 0.770 | 5.116 | 2.095 | 2.715 | |
| ELM | CARS | 119 | 0.814 | 6.338 | 0.806 | 4.703 | 2.279 | 2.953 |
| VISSA | 78 | 0.861 | 4.948 | 0.837 | 4.304 | 2.491 | 3.227 | |
| IVSO | 98 | 0.899 | 4.229 | 0.858 | 4.013 | 2.671 | 3.461 | |
| ICO | 276 | 0.877 | 4.653 | 0.863 | 3.953 | 2.712 | 3.514 | |
相比于以全波段为自变量进行建模,PLSR各模型结果都得到了明显的改善,说明4种波段选择算法通过优选变量,不但能减少模型的计算复杂度,还能有效提升模型的预测性能。对比3种回归模型里4种波长选择算法的表现,发现CARS回归精度普遍低于VISSA,IVSO和ICO这3种方法。可能是因为CARS每轮采样后利用EDF函数对波段进行了强制性剔除,从而误将部分对模型回归有用的弱信息波段也排除在外,导致模型拟合效果下降。相比于CARS,另外3种算法则采用了一种柔性收缩变量空间的策略[20]。每轮采样并不会硬性剔除波长变量,而是根据不同权重赋值方法,给予各个波长或波长区间高低不同的权重值,使得即使在前一轮因偶然因素表现欠佳的部分信息变量仍然有机会在下一轮被选中。VISSA的精度低于IVSO和ICO的原因可能是其意外选出了4个相关区间外的波长,导致模型混入无信息或干扰变量。总体而言,基于MPA策略的波长选择算法,通过迭代建立大量子模型,具有较强的稳定性与泛化性能。但由于模型数量庞大,VISSA与IVSO以单一波长点为建模变量,计算量较大。CARS迭代模型数量较少,且利用EDF函数每轮强制剔除一定数量变量后,计算复杂度降低,但泛化表现低于其他算法。4种方法中ICO在3种回归模型中的表现最优。具有优秀泛化能力的同时,其以波长区间作为建模变量,不但能提升模型的解释能力和运算效率,因参与变量过多而容易引发的过拟合概率也大大下降。
ELM各模型回归总体表现显著优于SVM,CARS-ELM,VISSA-ELM,IVSO-ELM和ICO-ELM相较于CARS-SVM,VISSA-SVM,IVSO-SVM和ICO-SVM,验证集R2分别提升了9.66%,12.35%,13.34%和12.08%,RPIQ提升了16.63%,25.13%,30.85%和29.43%。基于特征波长建立的SVM模型在土壤重金属Pb含量预测研究中相比另外2种模型表现一般,3种模型按回归总体表现排序为: ELM>PLSR>SVM。PLSR模型的精度高于SVM可能是因为SVM很大程度上依赖核函数与参数的选择,加上研究所用波长选择算法是基于PLSR建立的大量子模型,不能较好地适用于SVM。而神经网络模型ELM因其处理非线性数据泛化能力强、不易陷入局部最优解等优点,能很好地弥补PLSR面对非线性的高光谱数据的不足。回归模型与波长选择算法的各种耦合中,ICO-ELM表现最为优异,其验证集R2和RPIQ达到了0.863及3.514。ICO-ELM模型验证集样本预测值与实测值如图7所示。
图7
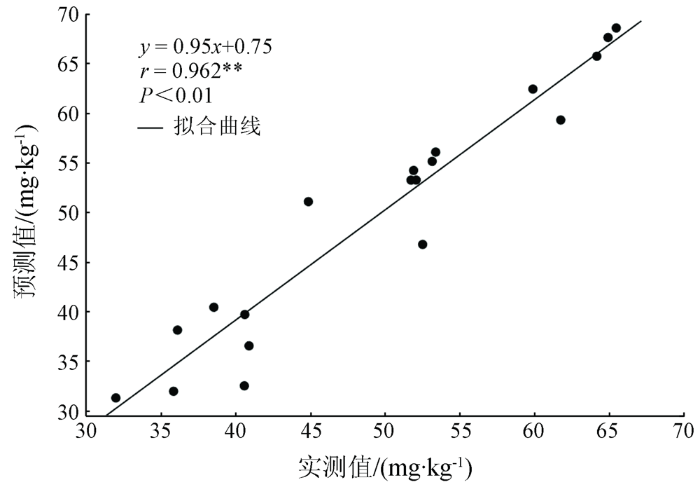
图7
ICO-ELM模型验证集实测值与预测值关系
Fig.7
Relationship between measured and predicted values of validation set based on ICO-ELM model
其相关系数r通过了P=0.01水平上的显著性检验,表现出很强的相关性。说明ICO-ELM具有出色的预测能力,能有效反演土壤重金属Pb的含量,为土壤其他重金属成分乃至其他理化属性成分含量反演提供了一种快速高效的耦合模型参考。
4 结论
以龙海市为研究区,对数据进行前期处理后引入基于模型集群分析策略的波长选择算法CARS,VISSA,IVSO和ICO分别对光谱变量进行优选,并分别建立PLSR,SVM及ELM这3种回归模型对龙海市土壤重金属Pb含量进行预测,主要结论如下:
1)对比小波变换、SG平滑、高斯滤波和多元散射校正4种光谱预处理方法,基于小波变换第七层重构后光谱数据建立的模型表现最佳。其验证集R2=0.736,RMSE=5.426,RPD=1.976,RPIQ=2.560。
2)CARS,VISSA,IVSO和ICO各自耦合PLSR的回归结果表明,相比于全波段建模,剔除无信息与干扰变量后,模型的预测精度、可解释性、计算复杂度等都得到了明显改善,证明基于模型集群分析策略的波长选择算法能有效应用于土壤重金属Pb含量的回归预测之中。总体表现排序为: ICO>IVSO>VISSA>CARS。
3)相较于SVM及PLSR这2种回归模型,各波段选择算法耦合ELM后,预测精度得到了较高的提升。其中ICO-ELM模型表现最佳,其验证集R2=0.863,RMSE=3.953,RPD=2.712,RPIQ=3.514,进一步提升了模型的泛化性能。
考虑到不同类型波长选择算法对变量筛选的原理不同,本文筛选变量时仅用到单一算法,且ICO挑选出的特征波长数量是否可以继续精简有待考证。为了充分发挥算法之间的互补性,在进一步的研究中,可以将例如智能优化算法、连续投影算法等方法与本文方法进行双重耦合甚至三重耦合,以此探讨最佳的算法组合。
参考文献
中国耕地土壤重金属污染概况
[J].
Soil heavy metal pollution of cultivated land in China
[J].
基于偏最小二乘的土壤重金属镉间接反演模型
[J].
Research on indirect hyperspectral estimating model of heavy metal Cd based on partial least squares regression
[J].
融合影像纹理、光谱与地形特征的森林冠顶高反演模型
[J].
Inversion model of forest canopy height based on image texture,spectral and topographic features
[J].
基于GA和CARS的真空包装冷却羊肉细菌菌落总数高光谱检测
[J].
Hyperspectral imaging detection of total viable count from vacuum packing cooling mutton based on GA and CARS algorithms
[J].
可见、近红外光谱和深度学习CNN-ELM算法的煤炭分类
[J].
Coal classification based on visible,near-infrared spectroscopy and CNN-ELM algorithm
[J].
土壤碱解氮含量可见/近红外光谱预测模型优化
[J].
Optimization for Vis/NIRS prediction model of soil available nitrogen content
[J].DOI:10.3788/fgxb URL [本文引用: 1]
基于高光谱的土壤碳酸钙含量估算模型研究
[J].
Estimation of soil calcium carbonate content based on hyperspectral data
[J].
窗口竞争性自适应重加权采样策略的近红外特征变量选择方法
[J].
A variable selection approach of near infrared spectra based on window competitive adaptive reweighted sampling strategy
[J].
Model population analysis for variable selection
[J].DOI:10.1002/cem.1300 URL [本文引用: 1]
基于IRIV算法优选大豆叶片高光谱特征波长变量估测SPAD值
[J].
Determination of soybean leaf SPAD value using characteristic wavelength variables preferably selected by IRIV algorithm
[J].
IVISSA算法冷鲜滩羊肉嫩度的高光谱模型优化
[J].
Hyperspectral model optimization for tenderness of chilled tan-sheep mutton based on IVISSA
[J].
化学建模与模型集群分析
[J].
Progress of chemical modeling and model population analysis
[J].
A novel variable selection approach that iteratively optimizes variable space using weighted binary matrix sampling
[J].DOI:10.1039/C4AN00730A URL [本文引用: 1]
Iteratively variable subset optimization for multivariate calibration
[J].DOI:10.1039/C5RA08455E URL [本文引用: 1]
A novel algorithm for spectral interval combination optimization
[J].DOI:10.1016/j.aca.2016.10.041 URL [本文引用: 1]
福建龙海土壤重金属含量特征及影响因素研究
[J].
Study on concentration characteristics and influencing factors of heavy metals in soils in Longhai,Fujian Province
[J].
蒙特卡洛交叉验证用于近红外光谱奇异样本的识别
[J].
Identification of NIR outlier samples by MCCV
[J].
Trends in extreme learning machines:A review
[J].
Extreme learning machine (ELM) has gained increasing interest from various research fields recently. In this review, we aim to report the current state of the theoretical research and practical advances on this subject. We first give an overview of ELM from the theoretical perspective, including the interpolation theory, universal approximation capability, and generalization ability. Then we focus on the various improvements made to ELM which further improve its stability, sparsity and accuracy under general or specific conditions. Apart from classification and regression, ELM has recently been extended for clustering, feature selection, representational learning and many other learning tasks. These newly emerging algorithms greatly expand the applications of ELM. From implementation aspect, hardware implementation and parallel computation techniques have substantially sped up the training of ELM, making it feasible for big data processing and real-time reasoning. Due to its remarkable efficiency, simplicity, and impressive generalization performance, ELM have been applied in a variety of domains, such as biomedical engineering, computer vision, system identification, and control and robotics. In this review, we try to provide a comprehensive view of these advances in ELM together with its future perspectives.
An improved estimation model for soil heavy metal(loid) concentration retrieval in mining areas using reflectance spectroscopy
[J].DOI:10.1007/s11368-018-1930-6 URL [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}