

0 引言
云检测的方法大致可以分为3种: 手工勾绘方法、基于波段阈值及纹理信息的检测方法与基于深度学习的检测方法[3]。其中第一种方法为最传统的方法,效率较低,本文不再赘述。第二种方法中基于波段阈值的方法需要人为监督,调整参数才可以达到较优的检测结果,基于纹理的检测算法需要后续对错误分类进行剔除。基于深度学习的云检测过程中不需要人工干预,实现了端到端的检测。基于波段阈值的云检测方法最早是Zhu等[4]提出FMask算法,通过设定波段阈值来实现Landsat卫星影像的云检测。在基于纹理的云检测方法中,Otsu算法[5]和K-means聚类法[6]等都是基于邻域的相似性进行检测,对噪声比较敏感,鲁棒性较差。康一飞等[7]利用高斯混合模型自适应获取影像的灰度阈值,从而分离ZY-3影像的前景与背景,实现云的检测,但对地表上较亮的地物的误判比较严重; 仇一帆等[8]使用CFMask算法检测Landsat8影像的云及云阴影,然后用其结果代替人工勾绘的云标签参与深度学习训练,再用训练出来的模型检测新图像的云及云阴影,结果发现其检测结果比原始标签精度更高; 栗旭升等[9]利用灰度共生矩阵提取图像的纹理特征,使用纹理特征与光谱特征结合,再使用支持向量机的方法对高分一号卫星影像进行云检测; 徐启恒等[10]使用超像素分割方法与卷积神经网络相结合,采用半监督的方式与传统的Otsu算法相比,云检测精度有较大的提高; 刘云峰等[11]将双重注意机制模型与全卷积神经网络模型相对比,发现双注意力机制模型用于云检测更为准确; 张家强等[12]对Unet网络结构进行改进,编码器与残差结构相结合,提高了模型的泛化能力,比传统的Unet模型检测精度更优; 张永宏等[13]提出解码器不仅在Unet模型的编码器中引入残差模块,而且将密集连接模块融入解码器中,可以很好地检测出薄云大量的碎云; 康超萌[14]采用自适应超像素分割算法与支持向量机相结合的方法进行云检测,可以很好地检测出薄云,但在数据量大的情况下,效率较低; 张晨等[15]针对云与云阴影的误检现象,使用ResNet作为编码器与解码器,跳跃连接部分引入双重注意力机制,编码器与解码器之间使用改进的空洞金字塔池化模块以提取图像的多尺度特征,有效提高了云检测的精度。
随着深度学习算法的不断进步,越来越多的遥感问题都可以通过深度学习的方法得到有效解决。基于上述研究,本文提出一种融入注意力机制的密集连接网络,以解决深度学习算法检测小块云朵效果差的问题。首先,借鉴D-LinkNet网络[16]的编码器解码器思想,使用DenseNet[17]作为编码器与解码器以训练到更深层的网络结构,能够提取更多特征; 然后,中间层引入自注意力机制GCNet-Block[18]可以更好地提取上下文信息,引入双注意力模块[19]增加有用信息的特征级别,降低无用信息的特征级别,使网络能够注意到有用的特征; 最后,经过级联的空洞卷积结构,使网络在不改变特征图分辨率的前提下,增大感受野,更加有利于捕获影像的全局信息,将编码器阶段得到的特征图与解码器阶段上采样得到的特征图进行跳跃拼接,实现了对编码器阶段得到的特征的复用。
1 融入注意力机制的密集连接网络
1.1 DenseNet结构
式中:
ResNet模型结构如图1所示。
图1
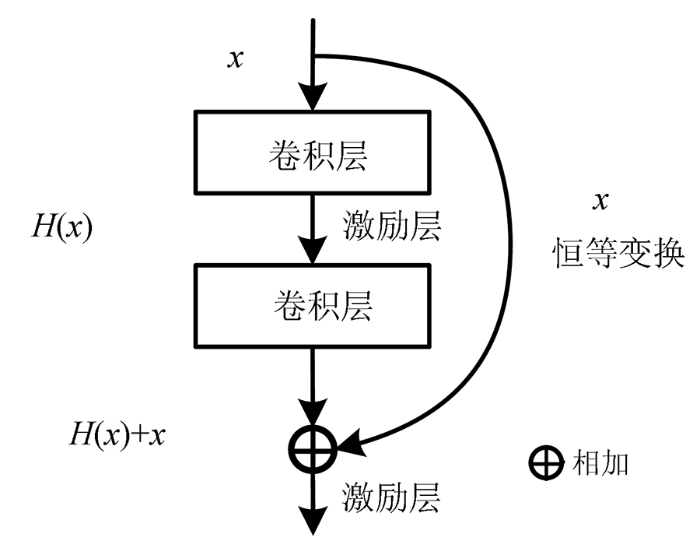
而DenseNet不同的是其互相连接所有的层,具体来说就是每个层都会接受其前面所有层作为其额外的输入,密集连接模块(densely connected block)结构如图2所示,其公式为:
式中[x0,x1…,xl-1]表示前l-1层的输出的特征图的拼接。
图2
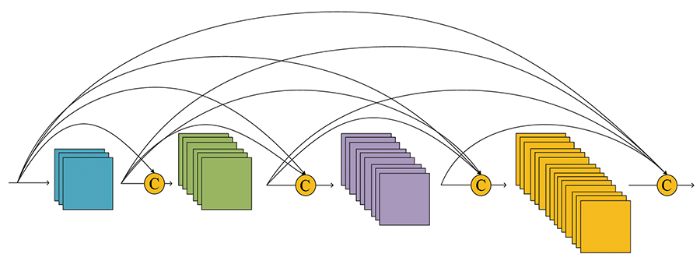
虽然通过跳跃拼接的方式保留了原始的特征,减轻了梯度传播过程中消散现象,但随着网络层数越来越深,通道数也越来越大,参数量也越来越多,从而也难以训练到更深的网络。为此DenseNet还包含了一个重要的转换模块(transition block),如图3所示,用在密集连接模块之后,将得到的特征图的通道数减小为原来的一半。但仅仅这样还是会大大增加通道数,所以在密集连接模块中每次拼接之前都加入一个瓶颈(bottleneck)结构,将其特征图的通道数减小为增长率,这样就可以大幅度减小通道数。则经过一个密集连接模块之后的特征数就可以表示为:
式中: C'为经过密集连接模块之后的通道数; C为经过密集连接模块之前的通道数; g为通道数的增长率; n为层数量。
图3
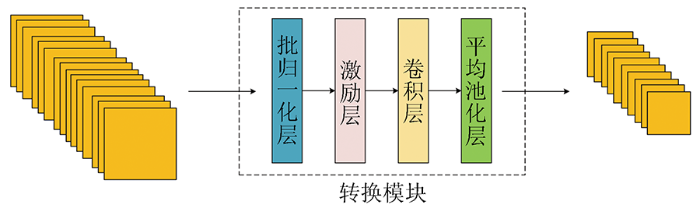
通过密集连接模块后经过转换模块(transition block)可将其通道数降为原始的一半,并进行下采样减半尺寸大小,从而更加简化了计算量,提升计算效率。
1.2 注意力机制
1.2.1 双注意力机制
随着计算机视觉的发展,各种注意力机制相继被提出,从而使计算机关注有用信息,忽略不感兴趣的信息。注意力机制分为通道注意力机制与位置注意力机制。
图4
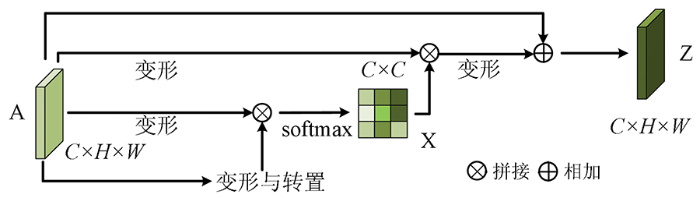
通道注意力模块的具体流程如下: 首先将特征图A变形成C×N(其中N = H×W)大小,再转置成N×C大小,与另一个只变形的特征图矩阵相乘得到C×C大小的特征图,再经过softmax层,得到不同通道的权值特征图X,再与变形过后的A进行矩阵相乘得到C×N大小的特征图,再变形成C×H×W大小的特征图,最后与原始的A进行矩阵相加,得到通道加权后的特征图Z。
位置注意力模块的最早应用是CBAM中的空间注意力(spatial attention model,SAM)模块,其首先将原始的特征图分别对同一位置不同通道进行全局最大池化与全局平均池化,分别生成通道数为1的特征图,然后将两者拼接起来,继而通过一个卷积核尺寸为7,填充尺寸为3的卷积将拼接起来的特征图的通道数降为1,从而达到获取其位置权重的目的。
而双注意力机制中的位置注意力模块则是使用通过自相关矩阵的变换得到位置权重,可以更注意全局特征。其模型结构如图5所示。
图5
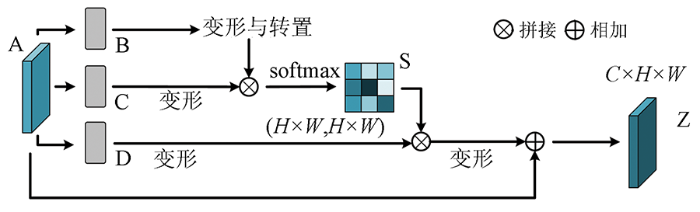
其结构与通道注意力模块类似,区别是其进行矩阵相乘时得到的特征图大小为(H×W,H×W),将所有通道信息进行了压缩,然后进行softmax,得到各个位置的权值S。
1.2.2 全局上下文建模模块
双注意力机制可以融合通道注意力机制与位置注意力机制,虽然其加入了自相关矩阵大大改善了注意力陷入局部的问题,但充分利用全局的上下文信息是有必要的。所以在进行融合双重注意力机制之前,先将全局的上下文信息提取出来。
图6
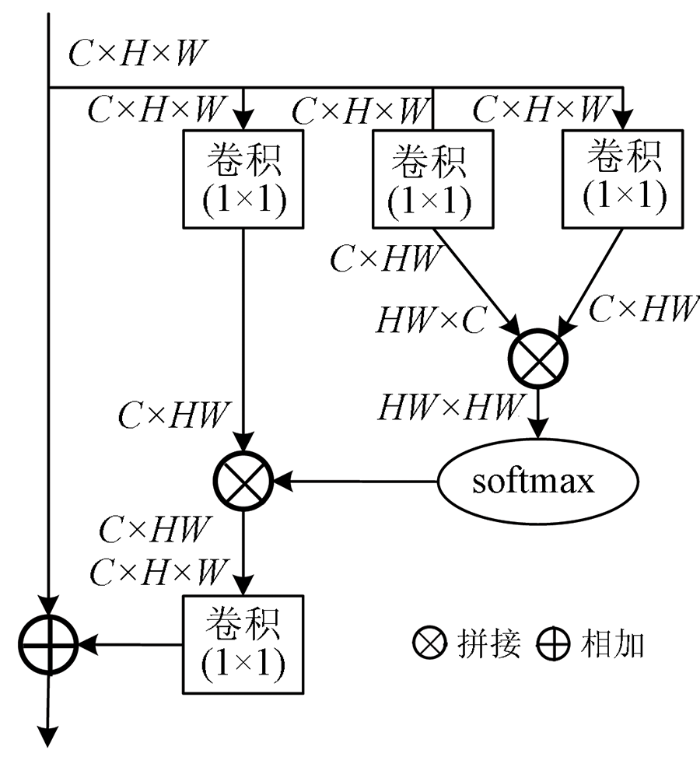
但是由于NLNet内部有较多的矩阵变换运算,导致计算量大大增加,所以极大地限制了NLNet的使用,为此GCNet提出了简化NLNet版本,即Simple-NLNet,并结合了SENet计算量少的优点,从而不仅有效地建立远程依赖,又节省了网络结构的计算量。GCNet的GC-Block模块如图7所示。
图7
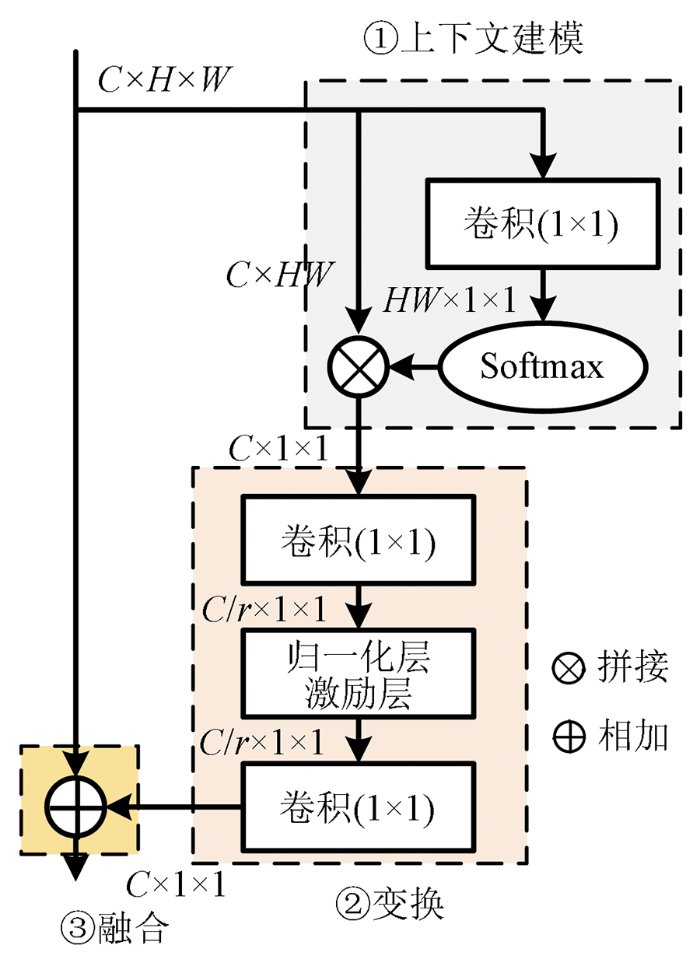
对于GCNet其可以分为3个步骤: 首先是需要使用全局平均池化进行上下文建模(context modeling),原始大小为C×H×W一方面先将其变形成C×HW大小的特征图,另一方面使用1×1卷积降低通道数为1,生成1×H×W大小的特征图,再变形成HW×1×1大小的特征图,经过softmax层后与C×HW大小的特征图进行矩阵相乘,得到C×1×1大小的特征图,至此每个通道的特征图的大小都变为1×1,完成了上下文建模。第二步捕获通道间的依赖,先将C×1×1大小的特征图经过一个瓶颈结构,降低通道数,图中r为通道数减少的倍数,从而减小了计算量,然后加入归一化层提高泛化能力,使用ReLU函数进行激励,得到非线性关系,最后还原通道数。第三步是将原始的特征图与变换后的特征图使用相加操作进行融合。
1.3 空洞卷积模块
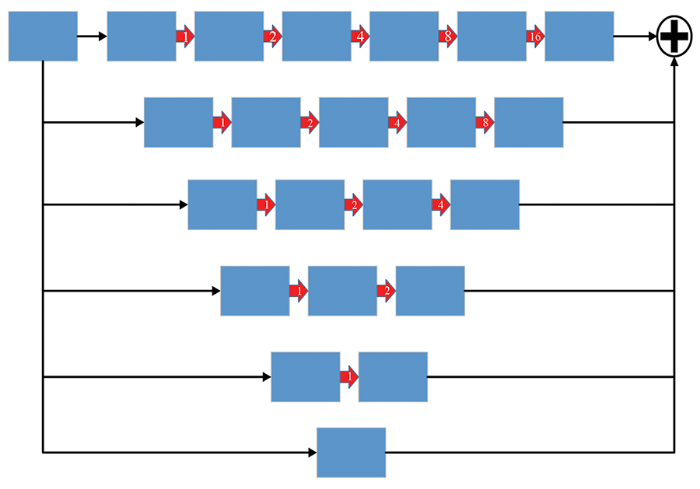
感受野表示单个像素点在上层卷积网络特征图中的区域范围大小,感受野越大,则表示通过卷积得到一个像素点所使用的上层特征图的像素个数越多,即所使用到的特征越多。感受野的大小决定了网络能否获取特征图的全局信息。扩大感受野最简单的方法就是增大卷积核的大小,但是卷积核大小的增大一定会使计算量增加,所以随着Deeplab V1[25]提出的空洞卷积,即扩大卷积核并在卷积核中使用部分用0来填充,从而可以简单方便地解决计算量增加的问题。如图8所示,特征图分为同等的6份,第一层为分别使用1,2,4,8,16大小空洞率进行空洞卷积,后面5层类似,最后将空洞卷积后的特征图与最后一层的原始特征图相加,从而可以增大感受野。
图8
1.4 融合注意力机制的密集连接网络
在上述研究的基础上,本文提出融合注意力机制的密集连接网络,具体模型结构如图9所示。
图9
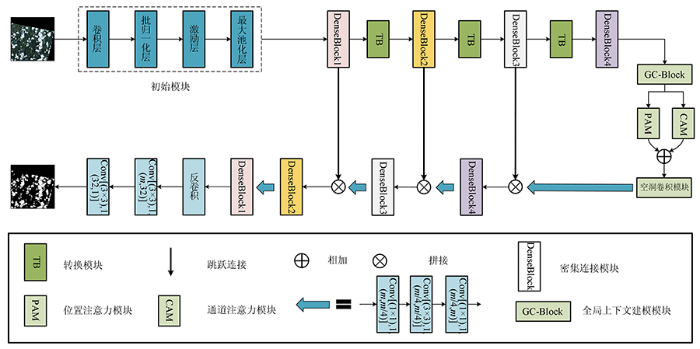
1)编码器阶段: 将裁剪好的3通道影像经过一个初始模块,初始模块由4个部分组成,第一部分为卷积核大小为7,填充大小为3的卷积层以不改变特征图的大小,输出通道数为64以减弱网络对影像失真影响; 第二部分为批归一化层,其作用加速模型收敛以及一定程度上缓解深层网络的梯度弥散问题; 第三部分为激励层,ReLU可以增加网络的非线性,并使一部分神经元的输出变为0,减少了参数之间的相互依赖,防止过拟合; 第四部分为最大池化层,最大池化层将原始特征图的宽高尺寸减半,减少了参数量,并一定程度上增加了网络的非线性关系。然后分别经过4个密集连接模块与转换模块提取特征,密集连接模块有效地减弱了梯度消散问题,转换模块有效地减少了参数量,使网络不至于“参数爆炸”。其中4个密集连接模块的层数量分别为6,8,12,16。
2)中间层: 首先通过GC-Block提取特征图的上下文信息,双注意力机制融合了位置注意力与通道注意力信息,使计算机更好地注意需要的特征,再将结果送入空洞卷积模块中使其在不改变特征图分辨率的前提下,增大感受野,进一步提取特征图的全局特征。
3)解码器阶段: 解码器部分首先上采样使特征图的通道数减小为刚通过编码器阶段DenseBlock3的特征图的通道数,图中m为当前层特征图的通道数; 然后与其进行跳跃拼接,从而特征图通道数变为原来的2倍,跳跃拼接可以实现特征复用,保留了更多的原始特征; 经过DenseBlock之后,通道数增加,再通过上采样降低通道数,直到最后将特征图变为通道数为1的二值图。
2 实验与分析
2.1 实验数据准备与参数设置
本文的实验均在ubantu16.04,CUDA 10.1,NVIDIA UNIX 64核的pytorch1.2.0深度学习框架下进行的。
本次实验的数据来自自然资源部国土卫星遥感应用中心提供的国产卫星遥感影像,其中包括高分一号、高分二号、高分六号、资源卫星影像,由于我国中东部地区云量相对较小,所以大部分选取新疆、西藏及内蒙古等边疆地区的遥感影像,小部分选取中东部地区的遥感影像,共596景,比例关系约为6∶4。标签制作为手工勾绘云矢量,后使用自制python脚本将其转化为二值图标签。原始标签及其真值标签部分数据如表1所示。





训练之前首先经过预处理,进行影像数据的扩充,方法有: 色彩抖动、水平翻转、垂直翻转、顺序裁剪、旋转等。首先进行顺序裁剪,将原始的影像与标签裁剪成512像素×512像素大小的影像共2 468张,再使用色彩抖动、平移、旋转、尺度缩放、水平翻转、垂直翻转进行扩充数据集,共得到12 340张,按照8∶2的比例分为训练集9 872张与测试集2 468张。预处理的目的是扩充数据量,对数据进行增广,防止过拟合,提高模型的泛化能力。增强后的影像及其真值标签见表2。
表2 增强之后的影像及真值标签
Tab.2
| 编号 | 增强后影像 | 增强后影像的真值标签 |
|---|---|---|
| 1 |  | |
| 2 |  | |
| 3 |  | |
| 编号 | 增强后影像 | 增强后影像的真值标签 |
| 4 |  | |
| 5 |  | |
参数设置: batchsize为4,步长为20,使用的优化器为Adam,初始学习率为0.001,自动调整学习率,每次调整变为原来的1/2,直到损失值7次不再下降为止。
2.2 损失函数
由于这是针对二分类问题,所以使用BCELoss作为损失函数。BCELoss是二分类问题中优秀的损失函数,其公式为:
式中: GT为标签影像(ground true); P为预测影像(predicet mask); B为批大小; W'为影像的宽度; H'为高度; gtij为标签影像在
2.3 评价指标
这里选取的指标为交并比IoU、召回率recall以及精确率precision。其计算方式分别为:
式中: TP为真阳性,表示原本为云预测为云的数量; TN为真阴性,表示原本为非云预测为非云的数量; FP为假阳性,表示原本为非云错误预测为云的数量; FN为假阴性,表示原本为云错误预测为非云的数量。其中3个指标越高表示精度越高。
2.4 云检测结果分析
由于影像不是多光谱影像,不能利用以热红外波段实施云检测的FMask算法进行检测,所以传统方法分别使用Otsu阈值算法、Otsu多阈值算法及K-means聚类算法进行云检测。深度学习算法分别使用SegNet,Unet,D-LinkNet50,未加注意力机制的本文方法(D-DenseNet)及本文方法(AD-DenseNet)对增强后的影像进行训练。首先进行定量分析,其中在训练集上的不同算法模型评价指标表现如表3所示,验证集上的不同算法模型的评价指标表现如表4所示,从表3—4中可以看出,传统算法的精度较深度学习算法的精度低,而在深度学习算法中,无论在训练集上还是在验证集上的召回率、交并比以及精确率都为本文方法精度最高。加上注意力机制后交并比增长约一个百分点,召回率与精确率也都有小幅度增长。
表3 训练集上的不同算法模型评价结果
Tab.3
| 算法模型 | Recall | Precision | IoU |
|---|---|---|---|
| Otsu阈值法 | 0.865 706 | 0.341 597 | 0.324 407 |
| Otsu多阈值法 | 0.684 431 | 0.833 832 | 0.602 283 |
| K-means聚类法 | 0.838 212 | 0.385 039 | 0.358 404 |
| SegNet | 0.908 152 | 0.936 953 | 0.855 852 |
| Unet | 0.945 295 | 0.954 285 | 0.904 343 |
| D-LinkNet50 | 0.942 009 | 0.948 958 | 0.896 580 |
| D-DenseNet | 0.947 085 | 0.955 037 | 0.906 659 |
| AD-DenseNet | 0.948 931 | 0.957 636 | 0.910 701 |
表4 验证集上的不同算法模型评价结果
Tab.4
| 算法模型 | Recall | Precision | IoU |
|---|---|---|---|
| Otsu阈值法 | 0.859 295 | 0.389 704 | 0.366 328 |
| Otsu多阈值法 | 0.702 932 | 0.868 563 | 0.635 349 |
| K-means聚类法 | 0.841 581 | 0.423 713 | 0.392 414 |
| SegNet | 0.923 405 | 0.926 182 | 0.860 104 |
| Unet | 0.946 430 | 0.958 225 | 0.908 927 |
| D-LinkNet50 | 0.948 262 | 0.949 005 | 0.902 285 |
| D-DenseNet | 0.951 485 | 0.958 911 | 0.904 211 |
| AD-DenseNet | 0.953 866 | 0.961 321 | 0.918 611 |
图10
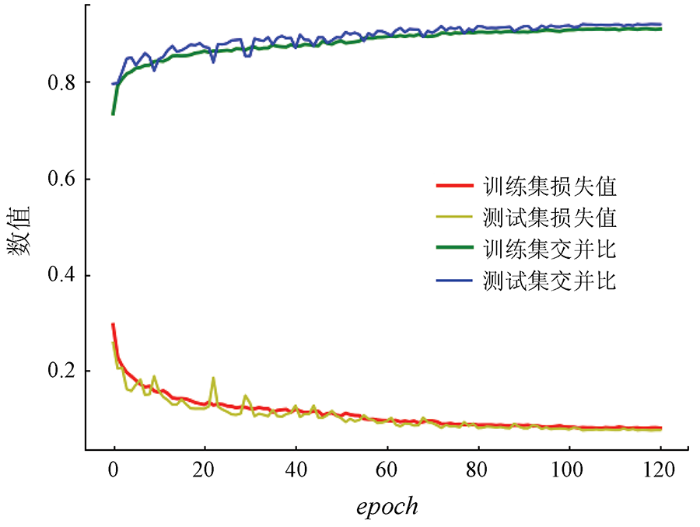
图10
AD-DenseNet算法损失值与交并比随epoch的变化曲线
Fig.10
Change curve of AD-DenseNet algorithm loss and IoU with epoch
图11
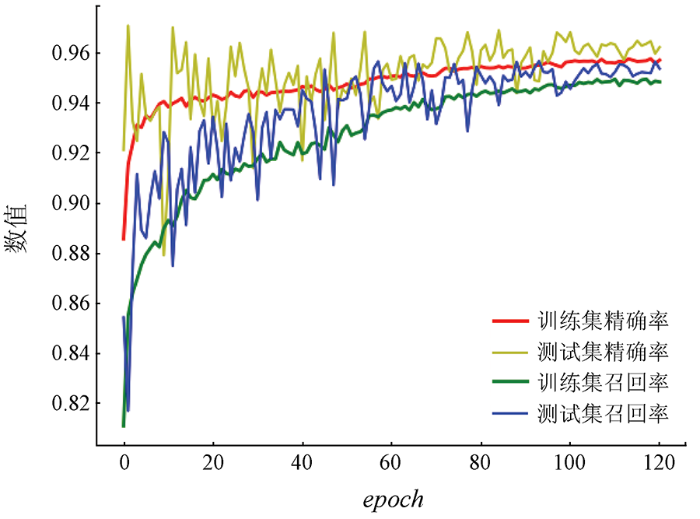
图11
AD-DenseNet算法精确率与召回率随epoch的变化曲线
Fig.11
Change curve of AD-DenseNet algorithm precision and recall with epoch
图12

图12
不同算法的云检测结果对比
Fig.12
Comparison of cloud detection results of different algorithms
首先使用传统方法Ostu阈值法、Ostu多阈值法及K-means聚类法对原始影像进行云检测,结果如图12(c)—(e)所示,从中可以看到Otsu阈值法与K-means聚类法检测效果明显不佳,由于其对噪声鲁棒性较差,Otsu多阈值法可以较好地检测出云的范围,但是从图12(d)中橙色椭圆虚线框中可以看到有明显的错检现象。对于深度学习方法,分别使用SegNet,Unet,D-LinkNet50,D-DenseNet及AD-DenseNet进行预测测试集中的影像,首先,将原始影像进行顺序切分为512像素×512像素大小的小影像,再使用训练好的网络模型进行预测,最后按照规则进行还原成原始影像大小。纵观图12的(f)—(j),其大体上没什么差别,预测精度都较高,但对于小块云朵的检测却不是如此。从图12(a)中可以看到,原始影像在红色框中有2片较小的云,由于其后方有明显的云的阴影,所以判定其为云,真值标签只勾绘出了一片云,SegNet,UNet,D-LinkNet及D-DenseNet均未预测出2片小块云,但AD-DenseNet算法却准确预测出其位置及形状。图12(a)中黄色框中,有一块较小的薄云,放大之后可清晰看到其云阴影,其中SegNet,UNet和D-LinkNet均未预测出此小块云,D-DenseNet与AD-DenseNet正确预测出其位置及形状。
3 结论
本文针对传统的深度学习算法不能很好地检测出小块云的问题,提出了一种融合注意力机制的密集连接网络(attention DBlock densely connected networks,AD-DenseNet)。
1)首先从编码器与解码器结构出发,不再使用通用的ResNet-Block结构作为骨干网络,使用DenseNet-Block作为编码器与解码器,从而可以训练到更深层的网络,提取到更多的影像特征。
2)中间层使用GC-Block提取全局特征,防止网络陷入局部,引入双注意力机制,使网络更加注意有用信息,抑制无关信息。
3)中间层加入DBlock结构,使网络在不改变分辨率的情况下增大感受野,以提取全局特征。
从实验结果来看,交并比可以达到0.91以上,精确率可以达到0.95以上,本文方法可以很好地检测出小块云朵,较传统方法有所提高。
但是对于雪的误判还存在问题,这将是下一步需要研究的方向。
参考文献
Calculation of radiative fluxes from the surface to top of atmosphere based on ISCCP and other global data sets:Refinements of the radiative transfer model and the input data
[J].
The availability of cloud-free Landsat ETM+ data over the conterminous United States and globally
[J].DOI:10.1016/j.rse.2007.08.011 URL [本文引用: 1]
Multilevel cloud detection in remote sensing images based on deep learning
[J].DOI:10.1109/JSTARS.2017.2686488 URL [本文引用: 1]
Object-based cloud and cloud shadow detection in Landsat imagery
[J].DOI:10.1016/j.rse.2011.10.028 URL [本文引用: 1]
A Threshold selection method from gray-level histograms
[J].DOI:10.1109/TSMC.1979.4310076 URL [本文引用: 1]
基于高斯混合模型法的国产高分辨率卫星影像云检测
[J].
Gaussian mixture model based cloud detection for Chinese high resolution satellite imagery
[J].
无人工标注数据的Landsat影像云检测深度学习方法
[J].
A deep learning method for Landsat image cloud detection without manually labeled data
[J].
结合图像特征的支持向量机高分一号云检测
[J].
Cloud detection based on support vector machine with image features for GF-1 data
[J].
结合超像素和卷积神经网络的国产高分辨率遥感影像云检测方法
[J].
Cloud detection for Chinese high resolution remote sensing imagery using combining superpixel with convolution neural network
[J].
国产高分辨率遥感卫星影像云检测方法分析
[J].
Research on cloud detection method of domestic high-resolution satellite images
[J].
基于深度残差全卷积网络的Landsat8遥感影像云检测方法
[J].
Landsat8 remote sensing image based on deep residual fully convolutional network
[J].
基于改进U-Net网络的遥感图像云检测
[J].
Cloud detection for remote sensing images using improved U-Net
[J].
双注意力RDA-Net遥感影像云与云阴影检测方法
[J/OL].
Dual attention RDA-Net for cloud and cloud shadow detection of remote sensing image
[J/OL].
D-LinkNet:LinkNet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction
[C]//
GCNet:Non-local networks meet squeeze-excitation networks and beyond
[C]//
Dual attention network for scene segmentation
[C]//
Densely connected convo-lutional networks
[C]//
Deep residual learning for image reco-gnition
[C]//
Squeeze-and-excitation networks
[C]//
CBAM:Convolutional block attention module
[C]//
Non-local neural networks
[C]//
DeepLab:Semantic image segmentation with deep convolutional nets,atrous convolution,and fully connected CRFs
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}