

0 引言
基于深度卷积人工神经网络的深度学习技术在图像分割和目标检测领域取得巨大突破,显著提升视觉、图像领域识别精度[12-13]。目前基于深度学习技术的目标检测和语义分割模型已用于松材线虫病识别,例如,徐信罗等[3]使用Faster R-CNN模型开展变色木识别与定位研究; 金远航等[14]基于YOLOv4网络和改进的前端特征提取网络构成新的网络模型,相比于YOLOv4-tiny,YOLOv4和SSD算法,精度分别提升9.58%,12.57%和10.54%,能够较好地实现对于枯死树木的检测。目标检测模型较语义分割模型运行效率高,但目标检测模型仅提供变色木的大致空间位置,无法基于此信息进一步的获取变色木的详细形态信息,例如变色木大小、形态等。上述形态信息对于后续评估染病松树的枯死阶段,确定受感染的松树冠层大小等至关重要。语义分割模型可提供逐像素的变色木分割结果,能够基于分割结果进一步提取变色木的详细形态信息,但当前仅有少量研究使用语义分割模型开展变色木分割研究[7],主流的语义分割模型用于松材线虫病变色木识别精度尚待研究。因此,本研究获取区域的无人机遥感影像,人工目视解译标注训练样本,研究当前主流的深度语义分割网络对松材线虫病变色木识别精度,期望有助于当前松材线虫病变色木防控工作的实施。
1 研究区概况与数据源
1.1 研究区概况
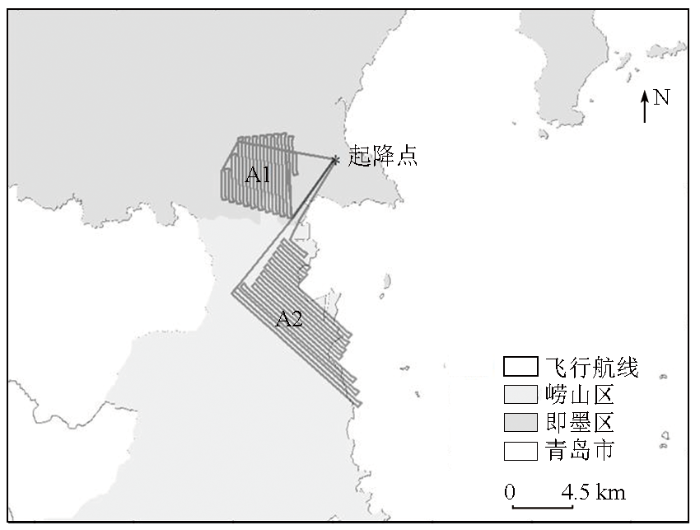
研究区域位于青岛市即墨区西南区域(A1)与青岛市崂山区北部(A2),如图1所示。研究区西部是青岛市城市建成区,东部临海,平均海拔360 m,最高海拔1 132.7 m,年平均温度14.2~15.0 ℃,年均降水约650 mm,植被覆盖以常绿针叶林为主,主导树种为黑松和赤松。采集变色木影像试验区域位于即墨区西南区域(A1)和崂山区北部(A2),其中A1区域面积25.26 km2,A2区域面积33.97 km2。
图1
1.2 数据源及样本获取
航拍使用DB-II固定翼型无人机,相机设备采用Sony Alpha 7R II相机,采集影像尺寸为7 952像素×4 472像素。航拍分2个架次完成,航线设计如图1所示,A1区域航拍时间为2018年10月9日,A2区域航拍时间为2018年10月6日。无人机飞行高度700 m,飞行速度100 km/h,飞行方向重叠度不低于75 %,旁向重叠度不低于50 %,采集影像地面分辨率7 cm。飞行作业期间,天气状况良好,晴空、微风、无云雾干扰,航拍飞行获得A1区域1 241张影像,A2区域1 447张影像。
航拍飞行设置较大重叠率,获取的无人机影像间重叠大,并且大部分影像不含有变色木,为此本研究选择航拍区域变色木较多影像开展目视解译。具体选择36幅无人机影像,使用ENVI软件感兴趣区域工具完成对变色木标记,如图2(a)和(b)所示。本文生成训练样本的流程如下。首先归一化处理无人机图像值至0~1,然后分别在尺寸为7 952像素×4 472像素无人机图像中随机截取200张尺寸为256像素×256像素的图像,每张截取图像均包含变色木像元。最后将无人机图像旋转5°,10°和15°,并对每个旋转图像随机剪切获得200个尺寸为256像素×256像素的图像。完成操作后获得训练样本28 800个,其中60%样本用于模型训练,20%用于模型验证,20%用于模型精度测试,部分样本数据如图2(c)—(l)所示。
图2

2 研究方法
2.1 深度语义分割模型
基于深度卷积神经网络的深度语义分割网络自2015年以来发展迅速,已形成一系列优秀的分割模型,如全卷积网络(fully convolutional networks,FCN)[15],PSPNet[16],SegNet[17],U-Net[18],Dense-ASPP[19]和DANet[20]等。根据模型设计的理念,可大致划分为4类: 语义分割模型的里程碑模型、对称结构的代表性模型、空洞卷积代表性模型和基于注意力机制的模型。具体的,本研究探究现阶段具有代表性的4种语义分割模型: 语义分割模型的里程碑模型FCN[15]、对称结构的代表性模型U-Net[18]、空洞卷积代表性模型DeepLabV3+[21]和基于注意力机制的OCNet[22]模型。
FCN是深度语义分割网络中里程碑分割模型,首次发表于2015年计算机视觉和模式识别大会。FCN在网络深度结构与深度分类网络VGG-Net[23]类似,其特点在于将分类模型的全连接层转换为卷积层,因此FCN 是端到端、像素到像素的分割网络。FCN网络池化层pool5的输出通过上采样与另一池化层融合获得更精细的特征图。FCN网络通过融合不同分辨率的特征层生成不同的分辨率网络,例如 FCN-32s,FCN-16s和FCN-8s。在本研究选择具有最精细特征细节的FCN-8s 作为测试模型。
U-Net 是一种广泛使用的图像分割深度学习模型,最初在2015年国际医学图像计算和计算机辅助干预(medical image computing and computer-assisted intervention,MICCAA)会议发表,用于生物医学图像分割[18]。U-Net网络由下采样(编码)和上采样(解码)2个部分构成,形成“U”型架构。下采样用于提取图像特征,上采样用于恢复下采样学习获取的特征细节。具体的,U-Net网络下采样4次,累计降低图像分辨率16倍,对称地上采样4次,恢复下采样生成的高级语义特征图至输入图片分辨率。
表1 模型参数表
Tab.1
2.2 损失函数
式中:
2.3 模型训练
用于模型训练的工作站配置为: Intel Xeon E5-2630处理器,64 GB内存,1 TB磁盘,NVIDIA P100 16 GB显卡。表1中所示模型基于Pytorch1.6构建,Adam优化器学习率0.001,训练100次,块(batch)大小16。每个模型单独训练3次,保存验证数据集对应loss值最小的模型参数为最优模型参数。
2.4 精度评估
本研究采用召回率(Recall)、精确率(Precision)、F1值和交并比(intersection over union,IoU)评估各模型分割精度,计算公式分别为:
式中:
3 结果与分析
图3所示是各模型训练损失值和F1值,从图中可知随着迭代次数增加,模型逐渐收敛,损失值趋近于0.1,F1值接近0.9,表明各模型能够正确地完成训练。
图3
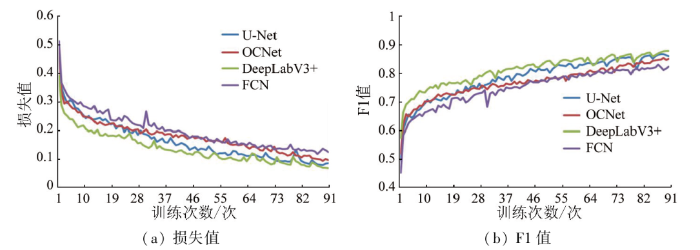
表2 模型分割结果
Tab.2
| 序号 | 无人机影像 | 地面真值 | FCN结果 | U-Net结果 | DeepLabV3+结果 | OC-Net结果 |
|---|---|---|---|---|---|---|
| a |  |  |  |  |  |  |
| b |  |  |  |  |  |  |
| c |  |  |  |  |  |  |
| d |  |  |  |  |  |  |
| e |  |  |  |  |  |  |
分析表2可知,上述4种网络均能够较好地对松材线虫病变色木进行分割,无明显误报,表明深度语义模型对颜色相近的地物,如岩石、黄色裸土有较强的分辨力。具体对比不同分割网络对变色木分割结果可知,FCN网络具有最粗糙的分割边缘,这是由于FCN网络对低分辨率、高等级特征与高分辨率、低等级特征融合较为简单,导致最终获得的特征图像分辨率较低。相比FCN网络,U-Net和DeepLabV3+改进了不同深度特征融合方式,具有更为精细的分割边缘结果。
不同分割模型的识别总体精度均高于0.9,具体精度如表3所示。从表中可知,DeepLabV3+具有最高的分割精度,IoU与F1值分别为0.711和0.829,FCN模型分割精度最低,IoU与F1值分别为0.699和0.812。U-Net网络具有较高精度,IoU与F1值均高于OCNet与FCN模型。因此,基于空洞卷积、编码和解码结构的DeepLabV3+模型具有最高的变色木分割精度,能够获得更为精确的变色木分割边缘。从表中还可知4种模型的训练与预测性能,DeepLabV3+具有最低的训练耗时,在结果预测上,FCN具有优势,DeepLabV3+耗时低于U-Net和OCNet。
表3 模型精度与性能
Tab.3
| 模型 | IoU | F1 | Precision | Recall | 训练/(ms·幅-1) | 预测/(ms·幅-1) |
|---|---|---|---|---|---|---|
| FCN | 0.699 | 0.812 | 0.821 | 0.804 | 53.1 | 7.2 |
| U-Net | 0.710 | 0.825 | 0.821 | 0.828 | 44.5 | 20.5 |
| DeepLabV3+ | 0.711 | 0.829 | 0.826 | 0.833 | 27.2 | 14.8 |
| OCNet | 0.706 | 0.820 | 0.824 | 0.817 | 47.6 | 16.9 |
4 讨论
4.1 特征提取网络的深度对变色木识别精度影响
现阶段主流的深度语义分割模型结构多由前端和后端2部分构成,即特征提取网络和后端语义分割结构2个部分。特征提取网络提供模型开展语义分割所需的特征流,语义分割结构则处理后续对象分割,因此前端(特征提取网络)的性能对最终的分割结果具有显著影响[7]。例如本研究中变色木分割精度最高的DeepLabV3+模型使用ResNet网络[26]作为前端,而ResNet根据不同配置可以生成不同的网络深度,例如ResNet50, ResNet101, ResNet152等。为此,本研究使用不同深度的ResNet作为前端,比较分析在变色木分割中,最适用于DeepLabV3+模型的ResNet特征提取网络。具体的,分别使用ResNet50, ResNet101, ResNet152这3种网络作为前端,对模型进行训练和预测,表4是预测结果示例。
表4 基于不同ResNet的DeepLabV3+模型分割结果
Tab.4
| 序号 | 无人机影像 | 地面真值 | DeepLabV3+ ResNet50 分割结果 | DeepLabV3+ ResNet101 分割结果 | DeepLabV3+ ResNet152 分割结果 | DeepLabV3 ResNet50 分割结果 |
|---|---|---|---|---|---|---|
| a |  |  |  |  |  |  |
| b |  |  |  |  |  |  |
| c |  |  |  |  |  |  |
| d |  |  |  |  |  |  |
| e |  |  |  |  |  |  |
从表中示例结果可知,随着ResNet网络深度的增加,DeepLabV3+网络变色木分割精度并未显著提升。例如影像e所对应的分割结果中,随着ResNet网络深度的增加,土壤与变色木分割结果未改善,且基于ResNet152的DeepLabV3+网络对于人造建筑物的分割结果也未改善(影像e中右下角红色建筑物)。具体的,不同ResNet网络深度对应的DeepLabV3+网络分割结果的测试精度如表5所示。整体上,基于ResNet50的DeepLabV3+网络具有最高的变色木分割精度,IoU与F1分别是0.711和0.829。
表5 模型精度
Tab.5
| 模型 | IoU | F1 | Precision | Recall |
|---|---|---|---|---|
| DeepLabV3+ ResNet50 | 0.711 | 0.829 | 0.826 | 0.833 |
| DeepLabV3+ ResNet101 | 0.702 | 0.822 | 0.847 | 0.798 |
| DeepLabV3+ ResNet152 | 0.702 | 0.820 | 0.846 | 0.796 |
| DeepLabv3 ResNet50 | 0.701 | 0.812 | 0.813 | 0.811 |
4.2 DeepLabV3系列模型编解码结构对变色木识别精度影响
在相同的特征提取网络条件下,语义分割网络的后端结构直接决定分割结果的精度以及分割边缘的精细程度。DeepLabV3网络后端设计依赖于ASPP模块,DeepLabV3+模块则在DeepLabV3网络ASPP模块基础上添加类似FCN和U-Net等模型的编码和解码结构,改进分割边缘的精度,获得更为详细的分割边缘。为此本研究对比DeepLabV3和DeepLabV3+网络,分析DeepLabV3+网络中编码和解码结构对变色木分割结果的贡献。具体的,DeepLabV3和DeepLabV3+网络均使用ResNet50作为前端,训练模型并进行预测和精度验证,如表4中结果示例。由表4中可知,在相同的前端特征提取网络下,DeepLabV3+能够获得更为精细的变色木分割边缘,同时变色木分割精度也高于DeepLabV3(见表5)。这表明DeepLabV3+引入的编码和解码结构能够显著地改进DeepLabV3模型的分割精度,同时能够获得详细的分割边缘,有利于松材线虫病变色木识别。
4.3 疑似变色木识别结果受其他因素干扰
当前基于可见光无人机影像数据对疑似松材线虫变色木开展检测的原理在于松树受松材线虫菌侵染后发生枯萎,表观颜色发生明显变化。由于松树受其他病虫害危害或面临环境胁迫也存在类似的颜色变化特征,为此当前基于可见光影像数据开展变色木识别获得的结果仅为疑似变色木。对于已经明确为松材线虫病疫区的林场,基于可见光影像识别的疑似变色木由松材线虫病致病的概率高,在实际工作中一般可认为是松材线虫病变色木,对于其他地区则需要配合实验室镜检或者基因检测等手段进一步的确认。
5 结论
本研究采用航拍获取大区域无人机松材线虫病疑似变色木影像,通过手动解译绘制训练样本,研究当前主流语义分割网络对变色木识别性能。研究结果表明在不同的光照、地物颜色特征相近的复杂背景条件下,当前主流的语义分割网络均可以较好地识别变色木,FCN,U-Net,DeepLabV3+和OCNet网络的IoU值分别达到0.699,0.710,0.711,0.706。在识别边缘精度上,FCN网络由于不同分辨率特征混合方式单一,分割边缘精度最低,U-Net和DeepLabV3+保持高分辨率特征、改进不同分辨特征混合方式,具有更为精细的分割边缘。
DeepLabV3+与DeepLabV3对比分析表明,DeepLabV3+引入的编码解码结构显著地改进了变色木分割边缘的精度,有利于获得更为详细的变色木形态信息,基于ResNet50的DeepLabV3+网络具有最高的变色木分割精度,IoU与F1分别达到0.711和0.829,前端特征提取网络ResNet的网络深度,如ResNet50,ResNet101和ResNet152,对DeepLabV3+变色木分割精度并无显著影响。
参考文献
Understanding pine wilt disease:Roles of the pine endophytic bacteria and of the bacteria carried by the disease-causing pinewood nematode
[J].
基于U-Net网络和无人机影像的松材线虫病变色木识别
[J].
Recognition of wilt wood caused by pine wilt nematode based on U-Net network and unmanned aerial vehicle images
[J].
基于Faster R-CNN的松材线虫病受害木识别与定位
[J].
Detection and location of pine wilt disease induced dead pine trees based on faster R-CNN
[J].
松材线虫病在中国的流行现状、防治技术与对策分析
[J].
Epidemic status of pine wilt disease in China and its prevention and control techniques and counter measures
[J].
基于高分六号卫星数据的红树林提取方法
[J].
Information extraction method of mangrove forests based on GF-6 data
[J].
Evaluation of deep learning segmentation models for detection of pine wilt disease in unmanned aerial vehicle images
[J].
无人机监测松材线虫病的精度比较
[J].
Precision comparison for pine wood nematode disease monitoring by UAV
[J].
A machine learning approach to detecting pine wilt disease using airborne spectral imagery
[J].
Detection of the pine wilt disease tree candidates for drone remote sensing using artificial intelligence techniques
[J].
A full resolution deep learning network for paddy rice mapping using Landsat data
[J].
基于深度学习的空谱遥感图像融合综述
[J].
A review of pansharpening methods based on deep learning
[J].
基于改进YOLOv4-tiny的无人机影像枯死树木检测算法
[J].
A dead tree detection algorithm based on improved YOLOv4-tiny for UAV images
[J].
Fully convolutional networks for semantic segmentation
[J].
DOI:10.1109/TPAMI.2016.2572683
PMID:27244717
[本文引用: 3]

Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixels-to-pixels, improve on the previous best result in semantic segmentation. Our key insight is to build "fully convolutional" networks that take input of arbitrary size and produce correspondingly-sized output with efficient inference and learning. We define and detail the space of fully convolutional networks, explain their application to spatially dense prediction tasks, and draw connections to prior models. We adapt contemporary classification networks (AlexNet, the VGG net, and GoogLeNet) into fully convolutional networks and transfer their learned representations by fine-tuning to the segmentation task. We then define a skip architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations. Our fully convolutional networks achieve improved segmentation of PASCAL VOC (30% relative improvement to 67.2% mean IU on 2012), NYUDv2, SIFT Flow, and PASCAL-Context, while inference takes one tenth of a second for a typical image.
Pyramid scene parsing network
[C]//
SegNet:A deep convolutional encoder-decoder architecture for image segmentation
[J].
DOI:10.1109/TPAMI.2016.2644615
PMID:28060704
[本文引用: 1]
We present a novel and practical deep fully convolutional neural network architecture for semantic pixel-wise segmentation termed SegNet. This core trainable segmentation engine consists of an encoder network, a corresponding decoder network followed by a pixel-wise classification layer. The architecture of the encoder network is topologically identical to the 13 convolutional layers in the VGG16 network [1]. The role of the decoder network is to map the low resolution encoder feature maps to full input resolution feature maps for pixel-wise classification. The novelty of SegNet lies is in the manner in which the decoder upsamples its lower resolution input feature map(s). Specifically, the decoder uses pooling indices computed in the max-pooling step of the corresponding encoder to perform non-linear upsampling. This eliminates the need for learning to upsample. The upsampled maps are sparse and are then convolved with trainable filters to produce dense feature maps. We compare our proposed architecture with the widely adopted FCN [2] and also with the well known DeepLab-LargeFOV [3], DeconvNet [4] architectures. This comparison reveals the memory versus accuracy trade-off involved in achieving good segmentation performance. SegNet was primarily motivated by scene understanding applications. Hence, it is designed to be efficient both in terms of memory and computational time during inference. It is also significantly smaller in the number of trainable parameters than other competing architectures and can be trained end-to-end using stochastic gradient descent. We also performed a controlled benchmark of SegNet and other architectures on both road scenes and SUN RGB-D indoor scene segmentation tasks. These quantitative assessments show that SegNet provides good performance with competitive inference time and most efficient inference memory-wise as compared to other architectures. We also provide a Caffe implementation of SegNet and a web demo at http://mi.eng.cam.ac.uk/projects/segnet.
U-net:Convolutional networks for biomedical image segmentation
[C]//
DenseASPP for semantic segmentation in street scenes
[C]//
Dual attention network for scene segmentation
[C]//
Encoder-decoder with atrous separable convolution for semantic image segmentation
[C]//
Xception:Deep learning with depthwise separable convolutions
[C]//
Deep residual learning for image recognition
[C]//
Robust liver vessel extraction using 3D U-Net with variant dice loss function
[J].
DOI:S0010-4825(18)30238-5
PMID:30144657
[本文引用: 1]
Liver vessel extraction from CT images is essential in liver surgical planning. Liver vessel segmentation is difficult due to the complex vessel structures, and even expert manual annotations contain unlabeled vessels. This paper presents an automatic liver vessel extraction method using deep convolutional network and studies the impact of incomplete data annotation on segmentation accuracy evaluation.We select the 3D U-Net and use data augmentation for accurate liver vessel extraction with few training samples and incomplete labeling. To deal with high imbalance between foreground (liver vessel) and background (liver) classes but also increase segmentation accuracy, a loss function based on a variant of the dice coefficient is proposed to increase the penalties for misclassified voxels. We include unlabeled liver vessels extracted by our method in the expert manual annotations, with a specialist's visual inspection for refinement, and compare the evaluations before and after the procedure.Experiments were performed on the public datasets Sliver07 and 3Dircadb as well as local clinical datasets. The average dice and sensitivity for the 3Dircadb dataset were 67.5% and 74.3%, respectively, prior to annotation refinement, as compared with 75.3% and 76.7% after refinement.The proposed method is automatic, accurate and robust for liver vessel extraction with high noise and varied vessel structures. It can be used for liver surgery planning and rough annotation of new datasets. The evaluation difference based on some benchmarks, and their refined results, showed that the quality of annotation should be further considered for supervised learning methods.Copyright © 2018 Elsevier Ltd. All rights reserved.
Focal loss for dense object detection
[C]//

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}