

0 引言
遥感影像建筑物分割的本质是建立起遥感影像与待分割的建筑物目标之间的映射模型,在此过程中需要对输入遥感影像进行特征提取,构建高效的特征空间。目前,用于遥感影像建筑物特征提取的传统方法可以分为基于形状[5]、基于支持向量机[6](support vector machine,SVM)和基于随机森林分类器[7]的方法。基于形状的方法在处理复杂建筑物形状时可能存在困难; 基于SVM的方法在处理建筑物和非建筑物样本数量不平衡的数据时,容易倾向于预测样本数量较多的类别,从而降低对少数类别的预测精度,进而影响整体精度; 当特征数量很高时,随机森林分类器可能会出现过拟合的问题。此外,这些传统方法对于中低分辨率、信息量少且简单的遥感影像虽然有较好的检测效果,但随着遥感影像分辨率的提高,所包含的信息量增大,这些传统方法的误检率和漏检率都会增大。当前在高分辨率遥感影像目标识别和分割领域中,深度神经网络的研究和应用也愈发广泛。Wang等[8]利用全卷积神经网络(fully convolutional network,FCN)对遥感影像进行处理,从而实现了对水域、建筑物以及植被的分类识别,虽然FCN可以通过端到端的训练和推断,避免了手工操作,从而简化了建筑物提取的流程,但是仅利用卷积操作会导致边缘模糊和细节信息丢失,导致语义信息不够准确,难以准确提取建筑物边缘和细节; 在该领域中,具有代表性的模型有U-net[9]和Deeplab[10]系列等。其中,U-net模型由Ronneberger等[9]在2015年提出,由对称的编码器和解码器结构组成,U-net中的跳跃连接可以捕捉更多的上下文信息,从而提高图像分割的准确性,但是对于对于遥感图像中存在的光照变化、背景遮挡等情况的适应性较弱,会导致分割效果不佳; Chen等[10]提出的DeepLab系列采用空白金字塔池化(atrous spatial pyramid pooling,ASPP)模块对目标进行多尺度的特征提取,利用解码器融合不同尺度的特征进行精细分割,但在高分辨率遥感图像的分割任务中仍存在细节丢失严重等问题; Fu等[11]提出了一个名为双重注意力网络(dual attention network,DANet)的模型,用于解决场景分割任务,该模型基于双重注意力机制,能够捕捉丰富的上下文依赖关系; 2022年,金澍等[12]提出了一种引入卷积块注意力模块和ASPP的MA-Unet,该网络通过加强建筑物特征和获取建筑物更精细的边缘特征提高了建筑物的分割精度; Yu等[13]将一系列注意力门控模块与单个U-net网络集成在一起,抑制输入图像中无关和嘈杂的特征响应,提高了提取精度,但是仅引入注意力机制并不能更好地关注小目标建筑物; He等[14]提出了一种用于遥感图像语义分割的新型框架,名为ST-UNet,该框架将Swin Transformer嵌入传统的基于CNN的U-net模型中,以获得全局上下文信息,同时克服了传统CNN在直接获取全局上下文方面的困难。此外,遥感影像建筑物分割是一种像素级的语义分割任务,现有基于深度学习的遥感影像分割方法在对目标进行分割时,存在像素关联度低、特征细节信息丢失等问题,从而出现误分割、分割边界不连续的结果[15⇓⇓-18]。在实际应用中,建筑物提取存在以下难点: 首先,遥感图像的复杂性是建筑物提取的难点之一,遥感图像中不仅包含建筑物本身的信息,还包含了各种地物和环境的干扰信息; 其次,建筑物的多样性也是建筑物提取的难点之一; 另外,建筑物的遮挡和重叠也是建筑物提取的难点。
本文基于U-net网络提出融合混合注意力机制与多尺度特征增强的高分辨率遥感影像建筑物分割模型(building mining net,BMNet)。为使模型具备一定的鲁棒性和适应性,能够处理各种类型的建筑物,适应不同的背景复杂度,在网络中加入串联型注意力机制。然后,在网络中增设建筑物信息挖掘模块(building mining module,BMM),对背景噪声进行滤除,降低建筑物周围复杂背景信息对前景建筑物特征信息的干扰,以优化建筑物边缘结构; 提出上下文信息探索模块(context exploration block,CEB),引入不同尺度的空洞卷积以丰富模型感受野,提高对小型建筑物的特征提取能力。
1 建筑物提取网络模型
1.1 BMNet整体结构设计
将传统的U-net网络直接应用于遥感影像建筑物分割任务中会存在一些不足: 小建筑目标受像素点数量影响分割效果不佳; 建筑物前景与复杂背景之间通常存在粘连关系,这会导致建筑物前景特征提取存在干扰和噪声,进而影响模型对遥感影像中建筑物分割的最终效果。因此,本文构建了一个用于高分遥感影像的建筑物分割网络模型BMNet,其整体结构如图1所示。首先,本文使用预训练的VGG16-BN模型,将其分为5个部分。其中,第一部分为输入层,接下来是4个下采样层,每个层的输出通道数逐渐增加。在最后一层下采样层引入串联型注意力模块,以增强第4个下采样层的输出。接着,使用3个BMM将相邻2个下采样层间的特征进行融合和处理。每个BMM模块将当前下采样层的输入特征、下一层模块的输出以及对应的下采样层特征进行融合,生成新的特征图和提取结果。最后,使用双线性插值将每个下采样层的输出进行上采样,得到与原始图像相同大小的预测结果。模型的输出包括Predict4,Predict3,Predict2和Predict1,分别表示下采样层4,3,2和1的预测结果。其中,通道注意力模块用于增强特征通道之间的相关性,空间注意力模块则用于增强特征之间的空间位置相关性,二者均有助于提高模型性能。建筑物挖掘模块允许模型从多个层次获取不同抽象级别的特征,并将它们融合在一起,以生成更有意义的特征表示。
图1
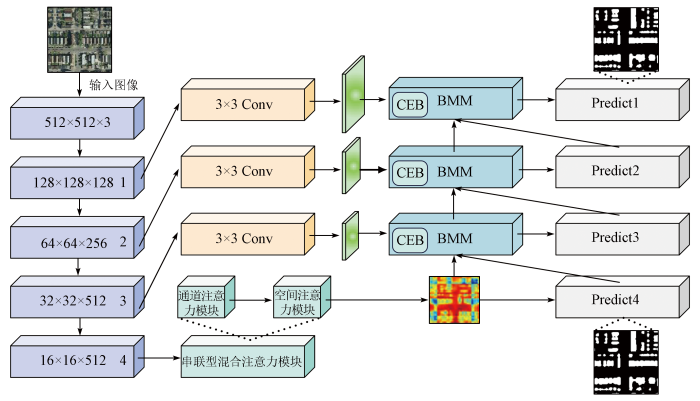
1.2 串联型混合注意力模块
图2
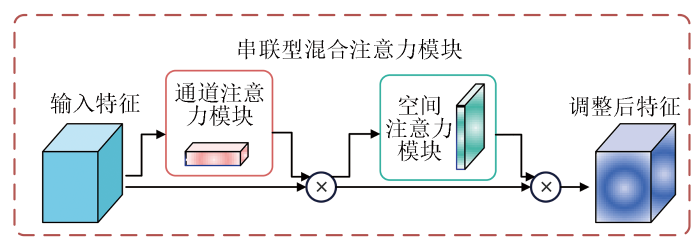
通道注意力模块旨在通过计算输入图像各个通道的权重来提高特征表示能力。借助通道注意力,可以提高深度学习网络提取特征的性能,使其能够更好地理解输入图像并提取更有意义的特征。
通道注意力机制的具体实现步骤如下: 首先,分别通过全局平均池化(global average pooling,GAP)和全局最大池化(global max pooling,GMP)将
式中:
图3
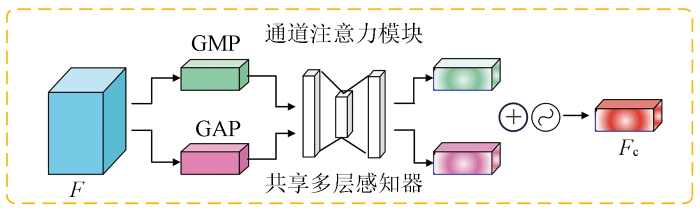
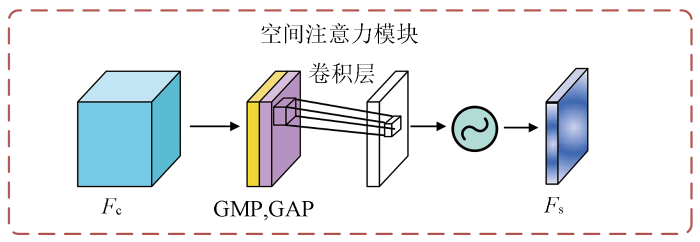
空间注意力机制的目的关注输入特征图中的空间位置,以找到关键信息在图像上的位置。通道注意力机制主要关注不同通道上的特征权重,而空间注意力机制则通过对通道注意力权重的引导,进一步关注特定位置上的信息聚集情况。
空间注意力的具体实现步骤如下: 首先沿着通道轴应用平均池化和最大池化操作,将它们连接起来生成一个有效的特征描述符。这一步骤旨在通过对不同通道之间的数值进行比较,而非同一通道不同区域的数值,得到一个能够描述通道之间关联性的特征描述符。接下来,将这个特征描述符送入一个卷积网络进行卷积操作,并通过激活函数得到最终的空间注意力特征图。这一过程通过对输入特征图中不同位置的信息进行加权融合,从而确定关键信息在图像上的位置分布,以提高网络的特征表示能力。假设空间注意力模块的输入为Fc,输出为Fs,实现过程如图4所示。每一步输出特征的计算方式为:
式中:
图4
1.3 建筑物信息挖掘模块
由于建筑物周围经常存在大量的背景干扰,如树木、道路遮挡等,经典模型对于建筑物前景和背景的划分不够清晰,难以准确地分离出建筑物,导致误检率提升,因此本文进行了如下操作: 对高层预测结果中的前景(接近1)与背景(接近0)进行
式中: 角标up为上采样操作;
BMM模块的具体框架如图5所示,图中d表示卷积操作中的膨胀率,用于控制卷积核的感受野大小。
图5
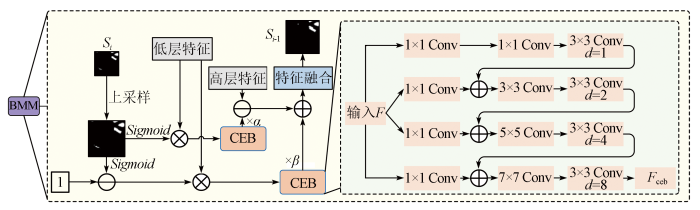
为了使模型更加关注小建筑物目标,CEB模块采用多个尺度分支并应用了空洞卷积,包含4个不同采样率的空洞卷积层,分别为1,2,4和8,以获得不同大小的感受野。这些分支通过通道维度实现多尺度的特征融合。通过CEB模块,模型能够获取对多尺度上下文信息感知的特征表示能力。假设输入特征F,则输出Fceb,如图5所示; 每一个分支(branch)b1,b2,b3,b4的输出计算公式为:
1.4 损失函数
本文采用交叉熵损失作为损失函数。一般损失函数对自变量求偏导的结果中带有Sigmoid导数因子项,而当自变量值较大时,Sigmoid导数值会趋向0,这样整个梯度会变得很小,从而在使用梯度下降法更新自变量时,迭代速度变慢,导致难以收敛或者发散,进而导致模型无法在早期阶段达到最优值。而交叉熵损失函数求导后不带Sigmoid函数导数项,梯度下降时更新很快,从而能够较早达到最优结果,加速模型的收敛速度。
为保证实验的公平性和可行性,损失函数计算公式为:
式中: M为样本总数; N为类别数量; pij为第i个样本属于第j个类别的概率; qij为模型预测的第i个样本属于第j个类别的概率。
2 实验结果与分析
2.1 数据集及评价指标
为了评估提出的BMNet的性能,综合考虑了3个公开的建筑数据集进行实验,包括武汉大学建筑数据集(
1)武汉大学建筑数据集[22]由航空影像数据集和卫星数据集2个子集组成,本实验中仅使用航空影像数据集,航空影像取自海拔0.075 m空间分辨率和450 km2覆盖土地,来自新西兰的新基督城。该数据集被裁剪为8 188个图块,训练集数量为4 736(包含130 500座建筑物),验证集数量为1 036(包含14 500座建筑物),测试集为2 416(包含42 000座建筑物)。每个图块的大小为512像素×512像素。
2)马萨诸塞州建筑数据集由波士顿地区的151张航空影像组成,每张影像均为1 500像素×1 500像素,面积为2.25 km2,覆盖面积约340 km2,地面官方数据被拆分为包含137张图像的训练集、包含10张图像的测试集和包含4张图像的验证集,为了使模型在此数据集有更好的泛化性能,采用垂直翻转和水平翻转等数据增强技术扩展了训练集,扩展后的训练集含400张图像。数据集涉及城市和郊区场景,建筑物的大小、形状、纹理和颜色都各不相同,因此这个数据集非常具有挑战性,适合用来验证模型的有效性。
3)Inria航空图像标注数据集[23]包含5个不同的城市定居点的不同建筑物和非建筑物图像,每个区域包含180张高分辨率航空图像,覆盖区域从人口密集的地区(旧金山的金融区)到高山城镇(奥地利蒂罗尔的利恩茨)。原始图像大小为5 000像素×5 000像素,为了满足计算机计算需求,首先将每张原始图像转换为RGB格式,将图片填充为5 120像素×5 120像素大小,然后将它们分割成尺寸为512像素×512像素的小块,并将符合条件(即建筑物类别像素占比不低于5%)的小块作为实验数据集,最终将9 695张作为训练集,1 945张作为验证集,1 545张作为测试集。
本文选择通用的交并比(intersection over union,IOU)、正样品分类精度(Precision)、正样品召回率(Recall)和F1分数(F1)来评估网络模型的性能,公式为:
式中: TP为判断正样本正确的数量; FP为将正确
的负样本判断为正样本; FN为将正确的正样本判断为负样本; IoU为预测结果与真实标签之间交集与并集之间的比值,IoU值越大,目标分割精度越大; F1为Precision和Recall的调和平均数,F1值越大,分类模型性能越好。
2.2 实验设置
本实验训练测试环境基于Pytorch框架,版本为Pytorch1.8.1,CUDA11.1,采用AdamW优化器,采用余弦退火和热重启学习率优化策略训练所有模型,采用随机垂直或水平旋转进行数据增强。首先对武汉大学建筑数据集进行训练,初始学习率为0.001,batch size设置为8,epoch设置为150。对于马萨诸塞州的建筑数据集和Inria航空图像标记数据集,使用在武汉大学建筑数据集上训练得到的权重进行微调,学习速率调整为0.000 5。在测试阶段,采用了测试时间增强策略,对图片进行翻转操作。
硬件环境为: 操作系统Ubuntu18.04,处理器为NTEL Intel Xeon Gold 5218R,显卡为英伟达RTX3090,内存为32 G。
2.3 消融实验及分析
表1 BMNet模型组合结构
Tab.1
| 网络组合 模块 | 说明 |
|---|---|
| BM-0 | 基线: 为仅使用VGG-16作为主干的U-net网络 |
| BM-1 | 基线+空间注意力模块(SA) |
| BM-2 | 基线+空间注意力模块+通道注意力模块(SA+CA) |
| BM-3 | 基线+ SA+CA +BMM(不添加CEB模块) |
| BM-4 | 基线+ SA+CA +BMM(添加CEB模块) |
| BM-5 | 基线+通道注意力模块(CA) |
| BM-6 | 基线+ CA+BMM(不添加CEB) |
| BM-7 | 基线+ CA+BMM(添加CEB) |
| BM-8 | 基线+ SA+BMM(不添加CEB) |
| BM-9 | 基线+ SA+BMM(添加CEB) |
| BM-10 | 基线+BMM(不添加CEB) |
| BM-11 | 基线+BMM(添加CEB) |
表2 消融实验结果
Tab.2
| 网络组合模块 | IoU | F1 | Precision | Recall |
|---|---|---|---|---|
| BM-0 | 71.40 | 83.33 | 84.60 | 82.10 |
| BM-1 | 72.67 | 86.96 | 89.36 | 84.68 |
| BM-2 | 74.51 | 88.60 | 90.68 | 86.62 |
| BM-3 | 79.78 | 89.35 | 91.35 | 87.44 |
| BM-4 | 81.93 | 90.07 | 91.78 | 88.41 |
| BM-5 | 73.28 | 85.06 | 85.96 | 84.17 |
| BM-6 | 78.51 | 85.72 | 86.54 | 84.92 |
| BM-7 | 80.66 | 86.45 | 87.02 | 85.88 |
| BM-8 | 77.94 | 87.66 | 90.10 | 85.35 |
| BM-9 | 80.09 | 87.30 | 88.92 | 85.74 |
| BM-10 | 76.67 | 84.91 | 86.32 | 83.55 |
| BM-11 | 78.82 | 85.69 | 86.79 | 84.62 |
由表2数据可知,在加入了空间、通道混合注意力机制以及BMM后,基线网络的性能得到了显著提升。具体而言,BM-1在IoU,F1,Precision,Recall这4个指标上比BM-0提高了1.78%~5.63%; BM-2在4个指标上比BM-0提高了4.36%~7.19%; BM-3在IoU指标上比BM-0提高了11.74%; BM-4比BM-0在4个指标上平均提高了9.76%。此外,从BM-6/7,BM-8/9,BM-10/11的对比结果中验证了CEB模块的有效性。BM-1与BM-5的实验对比结果可以看出,空间注意力和通道注意力对模型的影响不相上下,但与BM-2的对比结果可以看出,空间注意力与通道注意力结合时,模型能够获得更好的性能。表2的结果进一步验证了本文所提出的方法的有效性和优越性。结果表明,混合注意力机制可以集中网络的注意力于重要区域,同时强化有用特征,减少无用信息,从而提高网络对于图像特征的感知和理解能力。BMM通过调整空洞卷积中的空洞数目,可以实现多尺度特征提取,从而使得网络可以同时关注不同尺度的特征,使模型的特征提取能力进一步增强。
图6为消融实验生成的中间结果图,即特征热图。从图(e)中可以看出前景(建筑物)和背景特征并不明显,较为粗略; 而图(h)中可以明显地看出,相比较基线的分割预测结果(e)更为精细。此结果得益于BMM对前景与背景特征的加强,CEB模块中空洞卷积可以增加特征图中的采样点数目,从而可以更好地提取图像的细节特征。
图6
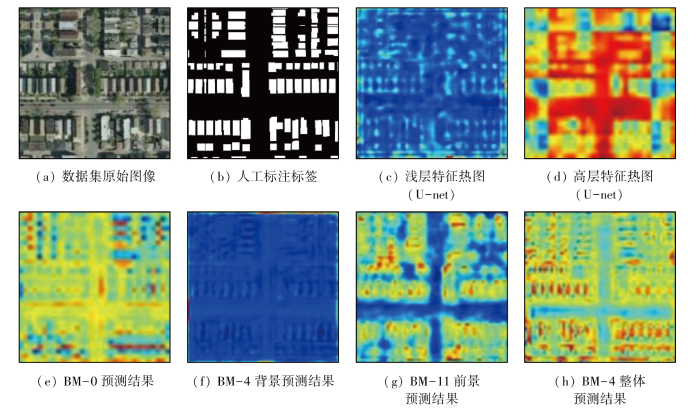
图6
消融实验中间结果图(特征图)
Fig.6
Figures of intermediate results of ablation experiment
2.4 对比实验及分析
为了验证所提出的BMNet的有效性,本文将BMNet与现有方法在马萨诸塞州建筑数据集、武汉大学建筑数据集和Inria航空建筑数据集上进行了比较。选择经典的分割方法进行对比,并且每个方法在相应数据集上取得较为先进的指标,因此对比方法有U-net[9],DeepLabV3+[10],ST-UNet[14],SwinUperNet[15],BANet[16]和STT[17]。定量分析采用的实验评价指标为交并比(IoU)、F1分数(F1)、精确度(Precision)、召回率(Recall)和参数量(Param)。表3为各类对比方法在武汉大学建筑数据集部分可视化分割结果。红色框表示待分割目标,从图中分割的位置准确性和目标完整性可以看出,本文所提方法在所选的3张图片中均取得了最优的分割效果。
表3 武汉大学建筑数据集定对比实验结果
Tab.3
 |
上述不同算法在武汉大学建筑数据集上分割结果的各指标定量分析见表4。由表4可知,提出的 BMNet算法IoU为91.73%,Precision为 95.01%,Recall为95.27%,Param为21.34 MB。实验表明: 相较于VGG16-U-net,DeeplabV3+,STT等对比算法,对比指标IoU分别提升了5.54%,2.99%,1.25%; 指标Precision提升了0.17%~5.09%; 指标Recall提升了0.19%~1.00%; 指标F1分别提升了2.94%,0.97%和0.18%。总体参数量高于U-net和STT,小于DeeplabV3+和ST-Unet。综上所述,与对比算法相比,本文提出的BMNet算法在武汉大学建筑数据集上具有较好的分割效果,且计算参数量都在可接受的范围。但是由于该数据集影像分辨率高,建筑物与其他地物区分比较明显,建筑的边缘比较清晰,所以在可视化对比实验中的各种算法差距不大。
表4 武汉大学建筑数据集定量对比实验结果
Tab.4
| 方法 | IoU/% | F1/% | Precision/% | Recall/% | Param/MB |
|---|---|---|---|---|---|
| VGG16-U-net | 86.91 | 92.42 | 90.41 | 94.52 | 18.26 |
| DeepLab V3+ | 89.07 | 94.23 | 94.15 | 94.32 | 30.61 |
| STT | 90.48 | 94.97 | 94.85 | 95.09 | 21.02 |
| ST-UNet | 89.65 | — | 95.16 | — | 26.47 |
| BMNet | 91.73 | 95.14 | 95.01 | 95.27 | 21.34 |
表5为各类对比方法在马萨诸塞州建筑数据集上的部分可视化分割结果。从表中可以看出,本文所提方法在所选的3张图片中均取得了最优的分割效果。
表5 马萨诸塞州建筑数据集定性对比实验结果
Tab.5
 |
表6 马萨诸塞州建筑数据集定量对比实验结果
Tab.6
| 方法 | IoU/% | F1/% | Precision/% | Recall/% | Param/MB |
|---|---|---|---|---|---|
| VGG16-U-net | 66.92 | 80.65 | 79.15 | 82.21 | 18.26 |
| DeepLab V3+ | 69.16 | 81.38 | 83.85 | 79.05 | 30.61 |
| BANet | 72.20 | 83.86 | 83.07 | 84.66 | 38.72 |
| ST-UNet | 71.26 | — | 86.49 | — | 26.47 |
| BMNet | 75.79 | 85.58 | 87.02 | 84.19 | 21.34 |
实验表明,相较于4种对比算法,BMNet在IoU,Precison和F1 3个指标上均有提升。尽管BMNet在Recall上略低于BANet,但都高于其余对比算法。综上所述,与对比算法相比,本文提出的BMNet算法在马萨诸塞州建筑数据集上具有较好的分割效果,且计算参数量都在可接受的范围,并且相比其余对比模型有显著的优势,验证了BMNet模型的鲁棒性和泛化性。
表7 Inria航空图像数据集定性对比实验结果
Tab.7
 |
表8为Inria航空图像标注数据集定量对比实验结果,从中可以看出,对于Inria航空图像标记数据集,本文所提方法仍然保持了更先进的性能,其IoU为81.93%,F1达到90.06%。
表8 Inria航空图像标注数据集定量对比实验结果
Tab.8
| 方法 | IoU/% | F1/% | Precision/% | Recall/% | Param/MB |
|---|---|---|---|---|---|
| VGG16-U-net | 70.92 | 83.12 | 85.07 | 81.26 | 18.26 |
| DeepLab V3+ | 74.52 | 83.47 | 81.82 | 85.19 | 30.61 |
| SwinUperNet | 79.37 | 88.19 | 87.43 | 88.96 | 65.84 |
| ST-UNet | 70.14 | — | 91.36 | — | 26.47 |
| BMNet | 81.93 | 90.06 | 91.78 | 88.41 | 21.34 |
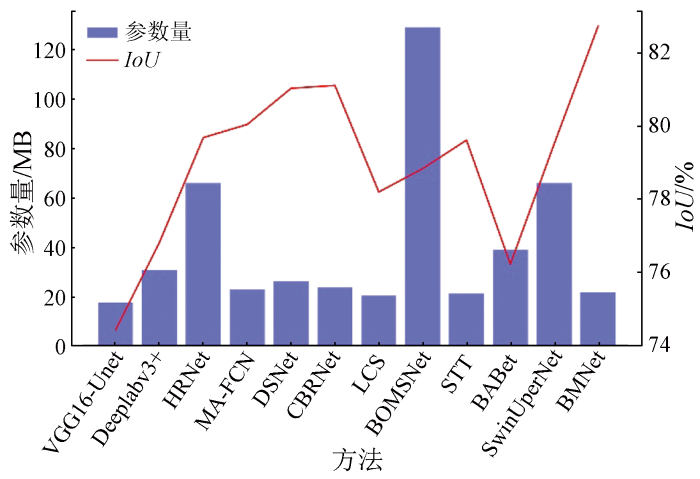
对于大规模遥感图像分割,有的模型要么结构复杂[23-24],要么捕获的建筑物语义信息不够丰富[25⇓⇓-28],因此需要建立高效的建筑物提取算法,能够在保证高精度的同时,快速处理大量的遥感图像数据,满足实际应用需求。VGG16中的卷积层使用了非常小的卷积核,并且每个卷积层都有多个通道。这种设计使得模型参数的数量大大减少,从而减少了过拟合的风险。相比于传统的卷积操作,空洞卷积可以在不改变特征图大小的情况下,增加卷积核中的空洞数目,使模型在计算中不增加过多的参数数量。这在大规模的神经网络中尤为重要,因为可以有效地减少模型的复杂度和训练时间。由图7可以看出(蓝色柱状表示参数量,红色折线表示IoU值),本文的方法在满足精度优势的同时,少量增加模型的参数量,可以运用到实际提取任务中。
图7
3 结论
与之前的研究工作类似,本文选择经典的U-net网络作为基础网络提出了一个用于高分辨率遥感影像建筑物分割的模型BMNet。
1)通过混合空间、通道注意力提高对各类型建筑物的分割能力,以提高模型的鲁棒性和适应性; 引入建筑物信息挖掘模块BMM,降低与建筑物前景粘连在一起的复杂背景信息对建筑物特征提取的干扰; 结合所设计的上下文信息探索模块CEB对背景噪声进行滤除,通过引入不同尺度的空洞卷积以丰富模型的感受野。
2)与主流方法的对比实验结果表明,本文所提出的模型在武汉大学建筑数据集、马萨诸塞州建筑数据集和Inria航空图像标注数据集上都取得了相对更优的分割性能,对目标分割的准确率高。大量的消融实验也验证了本文所提模型中各个部件的有效性。
但出于对模型实际应用的考量,尤其是在移动端设备上的应用,未来将更多地关注于在保证模型精度的前提下,设计更加轻量化的模型。
参考文献
遥感技术在城市洪涝模拟中的应用进展
[J].
Review on applications of remote sensing in urban flood modeling
[J].
深度学习支持下的宅基地复垦项目真实性智能审查技术研究与应用
[J].
DOI:10.13474/j.cnki.11-2246.2023.0028
[本文引用: 1]

全域综合整治背景下的宅基地复垦项目审查是保证复垦项目合法性合规性的有效手段,针对当前宅基地复垦项目审查效率低的问题,本文提出了基于遥感影像的农村宅基地复垦项目立项真实性审查方法。首先以重庆市农村宅基地复垦项目为例,建立宅基地复垦项目立项真实性审查模型,利用改进的U-Net模型准确提取建筑物,然后与复垦红线叠加实现复垦项目真实性的智能审查。试验结果表明,该方法能够快速准确地审查复垦项目真实性,对优化土地结构、促进土地流转、实现乡村振兴具有重要意义,可为全域综合整治背景下宅基地复垦项目真实性审查提供技术参考。
Research and application of intelligent verification technology for authenticity of homestead reclamation project based on deep learning
[J].
DOI:10.13474/j.cnki.11-2246.2023.0028
[本文引用: 1]
The review of homestead reclamation project under the background of region-wide comprehensive renovation is an effective means to ensure the legality and compliance of the reclamation project. Aiming at the low review efficiency of the current homestead reclamation project, a authenticity review method of rural homestead reclamation project was proposed based on remote sensing images. Taking the rural housing land reclamation project in Chongqing as an example, the paper establishes the authenticity review model of housing land reclamation project, and uses the improved U-Net to accurately extract buildings, and then superimpose with the reclamation red line to realize the intelligent authenticity review of the housing land reclamation project. The experimental results show that this method can quickly and accurately examine the authenticity of residential land reclamation projects, which is of great significance to optimize land structure, promote land circulation and promote rural revitalization. It can provide technical reference for the authenticity examination of residential land reclamation projects under the background of regional comprehensive renovation.
基于特征提取的SVM图像分类技术的无人机遥感建筑物震害识别应用研究
[J].
Application of SVM image classification technology based on feature extraction in seismic damage identification of buildings by UAV remote sensing
[J].
Remote sensing for urban planning and management:The use of window-independent context segmentation to extract urban features in Stockholm
[J].
Recognition-driven two-dimensional competing priors toward automatic and accurate building detection
[J].
An SVM ensemble approach combining spectral,structural,and semantic features for the classification of high-resolution remotely sensed imagery
[J].
Comparing supervised and unsupervised multiresolution segmentation approaches for extracting buildings from very high resolution imagery
[J].Although multiresolution segmentation (MRS) is a powerful technique for dealing with very high resolution imagery, some of the image objects that it generates do not match the geometries of the target objects, which reduces the classification accuracy. MRS can, however, be guided to produce results that approach the desired object geometry using either supervised or unsupervised approaches. Although some studies have suggested that a supervised approach is preferable, there has been no comparative evaluation of these two approaches. Therefore, in this study, we have compared supervised and unsupervised approaches to MRS. One supervised and two unsupervised segmentation methods were tested on three areas using QuickBird and WorldView-2 satellite imagery. The results were assessed using both segmentation evaluation methods and an accuracy assessment of the resulting building classifications. Thus, differences in the geometries of the image objects and in the potential to achieve satisfactory thematic accuracies were evaluated. The two approaches yielded remarkably similar classification results, with overall accuracies ranging from 82% to 86%. The performance of one of the unsupervised methods was unexpectedly similar to that of the supervised method; they identified almost identical scale parameters as being optimal for segmenting buildings, resulting in very similar geometries for the resulting image objects. The second unsupervised method produced very different image objects from the supervised method, but their classification accuracies were still very similar. The latter result was unexpected because, contrary to previously published findings, it suggests a high degree of independence between the segmentation results and classification accuracy. The results of this study have two important implications. The first is that object-based image analysis can be automated without sacrificing classification accuracy, and the second is that the previously accepted idea that classification is dependent on segmentation is challenged by our unexpected results, casting doubt on the value of pursuing 'optimal segmentation'. Our results rather suggest that as long as under-segmentation remains at acceptable levels, imperfections in segmentation can be ruled out, so that a high level of classification accuracy can still be achieved.
Integrating H-A-α with fully convolutional networks for fully PolSAR classification
[C]//
Dual attention network for scene segmentation
[C]//
基于改进U-Net的遥感影像建筑物提取方法
[J].
Building extraction from remote sensing images based on improved U-Net
[J].
AGs-unet:Building extraction model for high resolution remote sensing images based on attention gates U network
[J].
Swin transformer embedding UNet for remote sensing image semantic segmentation
[J].
Swin transformer:Hierarchical vision transformer using shifted windows
[C]//
Transformer meets convolution:A bilateral awareness network for semantic segmentation of very fine resolution urban scene images
[J].
Building extraction from remote sensing images with sparse token transformers
[J].
Deep high-resolution representation learning for human pose estimation
[C]//
Squeeze-and-excitation networks
[C]//
Spatial transformer networks
[J].
Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set
[J].
Can semantic labeling methods generalize to any city? The inria aerial image labeling benchmark
[C]//
BOMSC-net:Boundary optimization and multi-scale context awareness based building extraction from high-resolution remote sensing imagery
[J].
Automatic brain labeling via multi-atlas guided fully convolutional networks
[J].
DOI:S1361-8415(18)30860-0
PMID:30447544
[本文引用: 1]
Multi-atlas-based methods are commonly used for MR brain image labeling, which alleviates the burdening and time-consuming task of manual labeling in neuroimaging analysis studies. Traditionally, multi-atlas-based methods first register multiple atlases to the target image, and then propagate the labels from the labeled atlases to the unlabeled target image. However, the registration step involves non-rigid alignment, which is often time-consuming and might lack high accuracy. Alternatively, patch-based methods have shown promise in relaxing the demand for accurate registration, but they often require the use of hand-crafted features. Recently, deep learning techniques have demonstrated their effectiveness in image labeling, by automatically learning comprehensive appearance features from training images. In this paper, we propose a multi-atlas guided fully convolutional network (MA-FCN) for automatic image labeling, which aims at further improving the labeling performance with the aid of prior knowledge from the training atlases. Specifically, we train our MA-FCN model in a patch-based manner, where the input data consists of not only a training image patch but also a set of its neighboring (i.e., most similar) affine-aligned atlas patches. The guidance information from neighboring atlas patches can help boost the discriminative ability of the learned FCN. Experimental results on different datasets demonstrate the effectiveness of our proposed method, by significantly outperforming the conventional FCN and several state-of-the-art MR brain labeling methods.Copyright © 2018 Elsevier B.V. All rights reserved.
A local-global dual-stream network for building extraction from very-high-resolution remote sensing images
[J].
A coarse-to-fine boundary refinement network for building footprint extraction from remote sensing imagery
[J].
LCS:A collaborative optimization framework of vector extraction and semantic segmentation for building extraction
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}