

0 引言
传统的目标检测方法对于水坝的检测精度和自动化程度都比较低[1]。如朱然[2]通过阈值分割水域目标、几何特性定位等方法,基于航拍影像实现了对桥梁水坝轮廓的检测; 邱丹丹等[4]结合多源卫星影像以及特征级融合的模式,提取得到水坝目标。这些方法的特征提取能力有限,难以达到很高的精度。近些年来,深度学习技术快速发展,在目标检测领域也达到了很高的精度[5⇓⇓-8]。目前,深度学习方法被广泛应用于飞机[9⇓-11]、舰船[11⇓-13]、车辆[14-15]、房屋建筑[16-17]等地物的提取中,但对于水坝检测的研究较少。现有研究中, Jing等[18]基于YOLO网络结构,利用谷歌影像成功检测到了112座水坝,并找到了39个未知水坝。该研究通过开放街道地图(OpenStreetMap, OSM)等在线数据约束桥梁等背景干扰信息。然而,OSM等数据在不同地理区域精细度和准确度不同,因此提取结果精度也不易控制。许泽宇等[19]基于改进的YOLO网络和高分二号影像数据研究了大面幅遥感影像中水利设施的提取,但其使用的近红外波段数据在一些实际应用中不易获取,且没有开展对完整地学区域(如流域)的检测。
部分桥梁和水坝光谱和形状纹理信息以及所处环境非常相似,且桥梁通常与陆地上的道路直接相连,部分水坝也与道路相连通,因此,对两者的目标检测容易发生混淆,尤其是在大区域内,桥梁的数量会远远高于水坝数量,混淆问题更为明显。本文引入难分样本的思想以优化水坝的提取,将桥梁样本视为难以分辨的负样本。难分负样本挖掘[20]是一种常用的解决方法,在计算机视觉[21]以及遥感目标检测[22]等领域均有成功应用。目前应用思路是首先通过深度学习训练,选出容易与目标产生混淆的负样本,再对其针对性训练,通过多次循环逐渐优化训练模型。而在本文的水坝检测中,桥梁可直接被认为是负样本而不需要初步训练后再确定。难分负样本挖掘通常使用同一神经网络结构,而本文则测试多种网络结构,以探索适合区分水坝和桥梁的神经网络解决方案。
1 研究区概况与数据源
1.1 研究区概况
研究区域为大清河流域(图1)。
图1
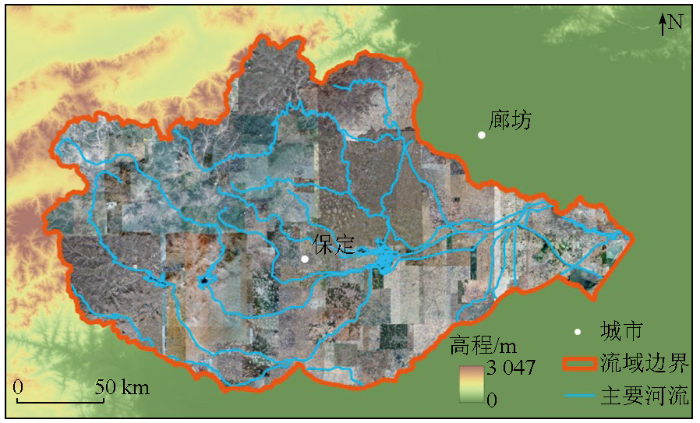
大清河是中国海河流域支流之一,发源于山西省任丘市,流经山西、河北、北京、天津4省市,流域主体位于河北省保定市,总面积达43 296 km2[25]。
1.2 数据源
第一阶段,由于水坝属于稀少地物,在研究区内取样则数据量不足以支撑网络结构的对比研究。因此在第一阶段选用DIOR公开数据集[26]。DIOR数据集是一个公开的光学遥感目标检测数据集,包含23 463幅图像,共有192 472个实例,包括飞机、机场、桥梁、水坝等20个类别。该数据集的图像分辨率、成像条件、天气、季节等都有变化,因此适合验证深度学习模型的检测能力。本文研究中,只提取该数据集中的桥梁和水坝2个类别进行研究。经过提取后,共得到3 035景影像,其中1 311景为训练集数据,1 724景为测试集数据。
在第二阶段,以18级谷歌影像为基础提取大清河流域的水坝。数据总量达1.03 TB,影像示意图见图1中底图。研究使用大清河流域水坝及桥梁样本各40景。由于样本量依然较少,本研究加入课题组在新疆科考中得到的30景水坝样本数据,并基于DIOR数据的训练模型进行微调。3种样本数据示意图如图2所示。同时,为了评估本文检测结果,使用2个公开数据集: 第一个是全球水坝数据集(global reservoir and dam database,GRandD)[27],包含全球7 320个水库及相关大坝的数据,该数据集标记了水坝位置等信息; 第二个是中科院南京地理所发布的全国水库数据集(China reservoir dataset,CRD)[28],CRD数据集共提供全国97 435个水库的空间位置信息。
图2

图2
第二阶段使用的3种样本数据示意图
Fig.2
Schematic diagram of the three types of sample data used in the second stage
2 研究方法
2.1 U-CenterNet网络
2.1.1 CenterNet网络
卷积神经网络(convolutional neural network,CNN)[29]是一种基础网络结构,可以拓展得到多种网络[30-31],在图像识别[30⇓-32]、目标检测[5,7,8]、语义分割[31,33]等领域都展现出了很好的效果。CenterNet网络是一种典型的无锚框CNN,在CornerNet的基础上发展而来。首先根据样本中目标框的大小,结合高斯滤波器生成热度图; 再通过特征提取网络及上采样提取热度图,得到物体的中心点,并回归目标的宽度和高度。该方法直接在热度图上进行了过滤操作,去掉了耗时的非极大值抑制(non-maximum suppression,NMS)处理过程。然而,在对于桥梁和水坝提取的具体问题中,该网络的部分内容需要进一步考虑,另外NMS等算法操作也需要进一步评估。
2.1.2 改进后的U-CenterNet网络
本文中,将改进后的CenterNet网络命名为U-CenterNet网络。在通过高分辨率遥感影像得到的样本中,桥梁和水坝尺度不统一,部分桥梁和水坝属于较大目标,如图3所示,因此使用原始方法通过热度图进行回归时容易出现较大误差。
图3
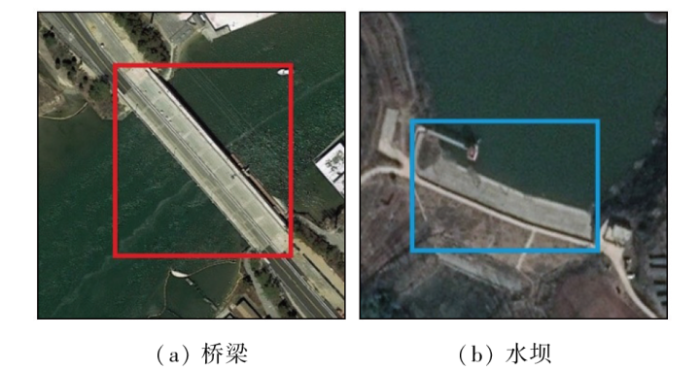
图3
存在大目标的桥梁和水坝样本数据示意图
Fig.3
Schematic diagram of sample data of bridge and dam with large objects
由于部分桥梁和水坝形态特征相似,因此在网络中,需要保留足够多的细节。改进后的U-CenterNet网络结构如图4所示。对第三次上采样后得到的特征图,经过卷积得到中心点位置、检测框的宽高信息和目标的类别信息。
图4
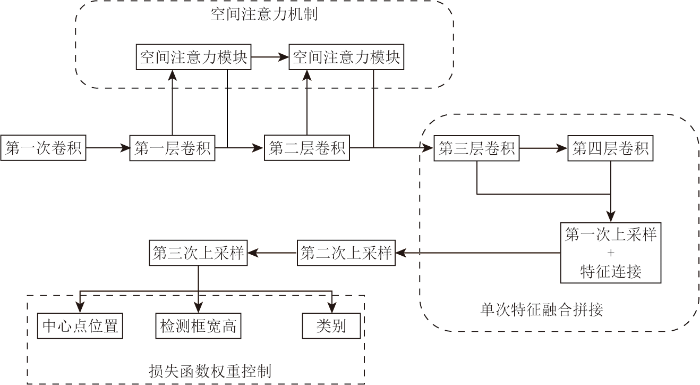
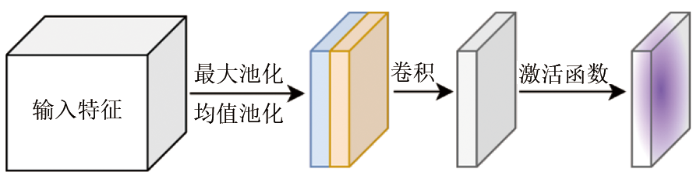
1)融合空间注意力机制,提升对空间信息特征的提取效果。空间注意力机制首先通过最大池化和均值池化处理,并将结果拼接成特征图,再通过卷积和激活函数处理,过程如图5所示。通过空间注意力机制,可以突出空间上的局部信息。由于遥感影像中各种地物空间分布存在多种情况,因此空间注意力机制可以增强对目标特征的提取效果。
图5
2)结合并调整U-Net网络结构,增强编码器-解码器之间的信息连接和融合。在生成热度图时,其结构与语义分割网络类似,因此,融入典型语义分割网络U-Net的部分结构,以增强编码器和解码器的连接,优化热度图的获取效果。首先将深层特征进行上采样,再与浅层特征拼接,然后通过卷积得到上采样后的综合特征,如图6所示。通过该方法,可以融合浅层特征中的细节信息。与U-Net不同之处在于,本文结构中的方法是为了得到热度图而不是语义分割结果,不需要特别详细的形状信息,因此仅在第一次上采样后的特征进行信息连接和融合,对于更浅层的特征,其包含更多目标形状细节信息干扰,不再进行拼接。
图6
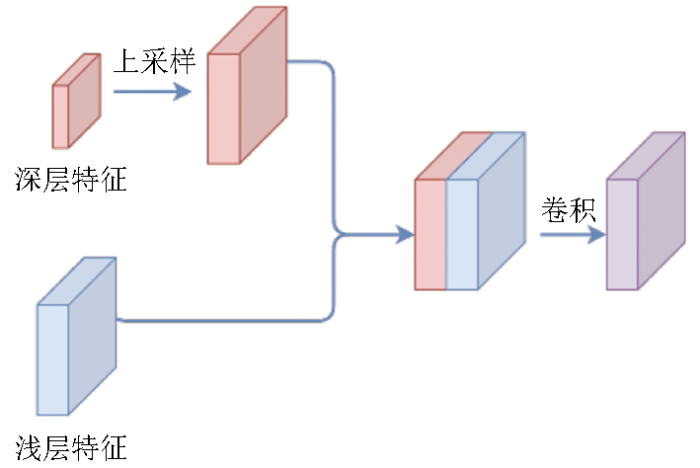
图6
特征拼接融合过程示意图
Fig.6
Schematic diagram of the feature splicing and fusion process
3)调整损失函数中宽高损失的权重。在基于遥感数据的桥梁和水坝检测任务中,主要提取目标的类型和位置,其边界框的宽、高形状不是提取的关键任务,因此降低宽高损失权重,本文中,将宽、高损失降低为原方法的1/10。
2.2 精度评价方案
评价指标采用精确度(Precision)、召回率(Recall)和F1分数。精确度即查准率,表示预测的结果中准确预测的目标所占的比例; 召回率即查全率,表示真实目标中有多少比例目标被正确检测出来。设TP为样本真实数据和模型输出的预测框都为正确的分类目标的数量; FN为样本真实数据为正确目标,但模型输出没有检测出的数量; FP为样本真实数据没有正确目标,但该位置模型输出了目标的数量。根据上述的3个精度指标,可以得到精确度和召回率,公式为:
在此基础上,得到F分数:
式中β为参数值,可以影响精确度和召回率在综合精度评价时的权重。虽然水坝检测更关注召回率,但本阶段使用了桥梁样本,过多的假阳性桥梁样本会对水坝识别形成干扰,因此本文采用β=1,即采用F1精度作为综合精度指标,不侧重单一指标。
3 实验与分析
3.1 实验设置
本文实验环境为Windows 11 操作系统,NVIDIA GeForce RTX 3070 GPU 显卡,实现程序为 Python语言和PyTorch 深度学习框架。
第一阶段实验设置训练过程为300个epoch,使用ResNet50预训练模型,所有的网络结构都使用Adam优化器和基于余弦退火的学习率衰减方案。由于本文提出的网络中包含新的结构,因此在新的网络中,只加载与预训练模型中相同结构部分。实验设置对比网络为: Faster R-CNN[8],YOLO v3[6],YOLO v7x[34]和原始CenterNet。Faster R-CNN[8]和YOLO[6]是2种典型且高效的目标检测网络结构。Faster R-CNN由R-CNN[20]和Fast R-CNN[35]逐渐发展而来,有很高的检测精度。该网络流程主要分为2步,第一步找到图片中待检测物体的锚框,第二步对锚框进行分类。Faster R-CNN已成功应用于建筑、飞机、船舶等遥感地物目标的提取[36-37]。YOLO是典型的单阶段检测器,可以一步直接检测到目标。目前YOLO 的多个版本被应用于遥感地物检测中[9,10,18],本文对比的是经典的YOLO v3和新提出的v7增强版本YOLO v7x。
第二阶段实验使用在DIOR数据集中得到的模型,并结合大清河流域的水坝和桥梁样本数据各40景,引入30景新疆水坝数据作为补充,并结合GRandD和CRD公开数据集评估结果。
3.2 结果与分析
3.2.1 第一阶段实验结果
第一阶段是基于DIOR数据集得到的桥梁水坝检测,图7展示了实验过程中损失值(Loss)的变化。需要注意的是,由于不同网络结构使用的损失函数不同,每个epoch下Loss数值的大小不代表模型的精度差异。最终得到的水坝和桥梁的检测精度如表1所示。本阶段所用数据直接从DIOR数据集中提取而来,其测试样本数大于训练样本数,因此得到的精度值偏低,但也可以表征算法的检测能力。根据表1,U-CenterNet有最高的水坝检测精度,YOLO v7x的水坝检测精度略低于U-CenterNet接近。原始CenterNet没有使用NMS机制,同一目标的重复预测过多,因此精确度下降,其最终的F1平均分数也低于Faster R-CNN,YOLO v3,YOLO v7x网络。虽然CenterNet是根据热度图峰值得到中心点,进而生成预测框,从原理上可以降低重叠预测框的问题,但对于目标较大的地物,其热度图峰值可能不止一个,因此可能出现重叠较多的情况。而在加入NMS后,可以得到明显改善; 同时结合U-Net结构的特征融合能力,进一步提高提取精度。YOLO v7x虽然是比较新的网络,但其计算资源消耗也更大,且是基于通用计算机视觉数据集对前代版本所作的优化,在本文的水坝检测中没有体现出明显优势。为了展示不同网络结构检测结果的细节,表2展示了典型检测结果的示意。
图7
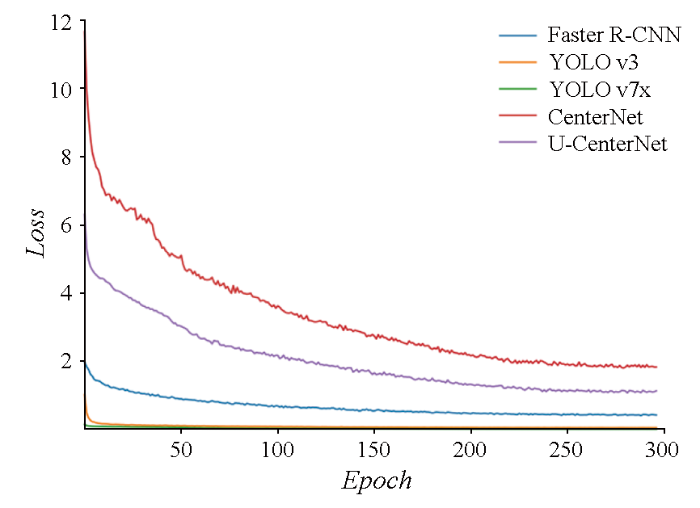
图7
训练中各模型Loss值随epoch的变化
Fig.7
Changes in the Loss values of each model during training with epochs
表1 DIOR数据集检测精度
Tab.1
| 深度学习网络 | 类别 | 精确度 | 召回率 | F1分数 |
|---|---|---|---|---|
Faster R-CNN | 桥梁 | 0.540 | 0.646 | 0.588 |
| 水坝 | 0.648 | 0.896 | 0.752 | |
YOLO v3 | 桥梁 | 0.578 | 0.780 | 0.664 |
| 水坝 | 0.627 | 0.814 | 0.708 | |
YOLO v7x | 桥梁 | 0.662 | 0.517 | 0.541 |
| 水坝 | 0.702 | 0.803 | 0.780 | |
CenterNet | 桥梁 | 0.548 | 0.797 | 0.649 |
| 水坝 | 0.577 | 0.765 | 0.658 | |
U-CenterNet | 桥梁 | 0.639 | 0.775 | 0.700 |
| 水坝 | 0.773 | 0.793 | 0.783 |
表2 各网络结构典型检测结果对比示例
Tab.2
 |
在示例1中,对于河流上的水坝,多数算法结果有重叠及错检现象,如YOLO v3错误地识别出了桥梁信息。在示例2中,原始CenterNet和桥梁和部分陆地地物识别为了水坝,YOLO v3则将与桥梁连接的部分道路识别为了水坝,而改进后的U-CenterNet网络没有错误识别。在示例3中,原始CenterNet,Faster R-CNN和YOLO v7x将桥梁错误识别为了水坝,YOLO v3和改进后的U-CenterNet网络正确检测到了桥梁,但YOLO v3结果出现重复。在示例4中,原始CenterNet的结果存在重叠,且其中一个重叠框将桥梁识别为水坝。而U-CenterNet可以准确识别。整体上看,U-CenterNet结果中将桥梁误检测为水坝的情况最少,可以明显降低桥梁这一难分地物信息带来的干扰。
3.2.2 第二阶段提取结果
图8

整体检测结果如图9所示。由图9可看出,本文得到的水坝大部分在主要河流区域,也有部分位于平原区。为了更好地评估数据结果,同时参考公开的GRandD水坝数据集和CRD水库数据集。GRandD数据集主要是大型水坝,在大清河流域只有5处目标,这5处水坝在本文的方法中全部被成功识别; 而CRD水库数据,图9中所示为水库中心点,水库主要位于山脉与平原交界附近的山区,与本文得到的水坝点基本重合。由于CRD数据集本身的误差,以及部分水库没有建设明显的水坝,因此部分水库点没有在本文方法中被检测出来,共26处,尤其集中在东侧接近海洋的区域。部分未检测示意图如图10所示。图10(a)中,该区域不存在明显的水坝,因此没有被检测; 而在图10(b)中,有一个小型水坝没有被检测出来,属于漏检。从整体上看,公开数据集中的水坝和水库信息与本文结果基本相符,且本文检测到了更多的小型水坝,比现有数据集结构更详细精确。
图9
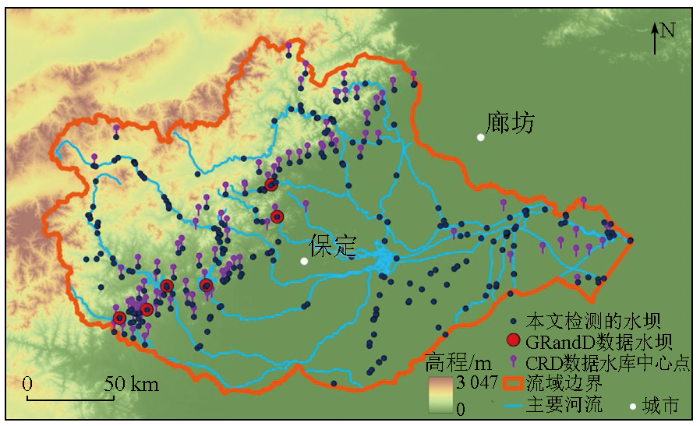
图9
大清河流域水坝检测结果示意图
Fig.9
Detection results of water conservancy facilities in the Daqing River basin
图10

图10
本文未检测到的CRD水库区示意图
Fig.10
Schematic diagram of CRD reservoir not detected in this paper
4 结论
本文基于大清河流域数据研究了大区域的水坝信息检测。通过将桥梁样本设置为难分负样本参与训练,降低桥梁信息对水坝检测的干扰。研究包括2个阶段,第一阶段研究检测水坝以及负样本桥梁的网络结构,基于CenterNet网络,结合桥梁和水坝目标的特点,进行了以下改进: ①编码器中加入空间注意力机制模块; ②融入调整后的U-Net网络结构,强化特征编码器-解码器之间的连接; ③调整边界框形状损失值的权重; ④结合NMS处理得到了改进后的U-CenterNet网络结构。第二阶段,结合DIOR数据集中的桥梁与水坝的训练模型参数与大清河流域的样本,引入新疆水坝样本作为扩充样本集,进行大清河流域的水坝检测。
实验结果表明,本文提出的方法可以有效避免桥梁和水坝的混淆,水坝检测F1分数达0.783。在大清河流域的水坝检测实践中,得到水坝目标330处,该结果比目前的水坝或水库等公开资料更为详细精确。本文的研究在结合桥梁负样本的基础上实现了完整区域的水坝提取实践,体现了算法的实际应用价值。
但结果仍然存在一定的漏检、误检问题,一个重要原因是由于整个流域空间范围大,影像光谱和空间特征不一致,因此针对这些特点进行优化是下一步的研究方向。
参考文献
基于高分影像的水利空间要素提取规则集构建
[J].
Rule sets building of water conservancy facilities spatial element extraction based on high resolution remote sensing image
[J].
结合随机擦除和YOLOv4的高空间分辨率遥感影像桥梁自动检测
[J].
High spatial resolution automatic detection of bridges with high spatial resolu tion remote sensing images based on random erasure and YOLOv4
[J].
基于多源卫星图像融合的水坝检测方法的研究
[J].
A study of dam detection based on multi-source satellite images fusion
[J].
You only look once:Unified,real-time object detection
[C]//
YOLOv3:An incremental improvement
[J/OL].
SSD:Single shot MultiBox detector
[C]//
Faster R-CNN:Towards real-time object detection with region proposal networks
[J].
基于YOLO v3的机场场面飞机检测方法
[J].
Airport scene aircraft detection method based on YOLO v3
[J].
遥感图像中飞机的改进YOLOv3实时检测算法
[J].
Real-time airplane detection algorithm in remote-sensing images based on improved YOLOv3
[J].
光学遥感图像舰船目标检测与识别综述
[J].
State-of-the-art of ship detection and recognition in optical remotely sensed imagery
[J].
基于深度学习的高分辨率遥感图像车辆检测
[J].
Vehicle detection in high-resolution remote sensing images based on deep learning
[J].
基于旋转框回归的YOLOV5遥感图像车辆目标检测
[C]//
Vehicle target detection in YOLOV5 remote sensing image based on rotating box regression
[C]//
基于生成对抗网络的地面新增建筑检测
[J].
DOI:10.11772/j.issn.1001-9081.2018102083
[本文引用: 1]

针对传统的基于地物纹理和空间特征的方法很难精确识别地面新增建筑的问题,提出了一种基于生成对抗网络的新增建筑变化检测模型(CDGAN)。首先,使用Focal损失函数改进传统图像分割网络(U-net),并以此作为模型的生成器(G),用于生成遥感影像的分割结果;然后,设计了一个16层的卷积神经网络(VGG-net)作为鉴别器(D),用于区分生成的结果和人工标注(GT)的真实结果;最后,对生成器和判别器进行对抗训练,从而得到具有分割能力的生成器。实验结果表明,CDGAN模型的检测准确率达到92%,比传统U-net模型的平均区域重合度(IU)提升了3.7个百分点,有效地提升了遥感影像中地面新增建筑物的检测精度。
Detection of new ground buildings based on generative adversarial network
[J].
DOI:10.11772/j.issn.1001-9081.2018102083
[本文引用: 1]
Aiming at the inaccuracy of the methods based on ground textures and space features in detecting new ground buildings, a novel Change Detection model based on Generative Adversarial Networks (CDGAN) was proposed. Firstly, a traditional image segmentation network (U-net) was improved by Focal loss function, and it was used as the Generator (G) of the model to generate the segmentation results of remote sensing images. Then, a convolutional neutral network with 16 layers (VGG-net) was designed as the Discriminator (D), which was used for discriminating the generated results and the Ground Truth (GT) results. Finally, the Generator and Discriminator were trained in an adversarial way to get a Generator with segmentation capability. The experimental results show that, the detection accuracy of CDGAN reaches 92%, and the IU (Intersection over Union) value of the model is 3.7 percentage points higher than that of the traditional U-net model, which proves that the proposed model effectively improves the detection accuracy of new ground buildings in remote sensing images.
Detecting unknown dams from high-resolution remote sensing images:A deep learning and spatial analysis approach
[J].
结合E-YOLO和水体指数约束的大面幅影像水利设施检测
[J].
Detection of water conservancy facilities in large-format image combining E-YOLO algorithm and NDWI constraint
[J].
Rich feature hierarchies for accurate object detection and semantic segmentation
[C]//
基于难分样本挖掘的快速区域卷积神经网络目标检测研究
[J].
Research on faster RCNN object detection based on hard example mining
[J].
迁移学习结合难分样本挖掘的机场目标检测
[J].
Airport object detection combining transfer learning and hard example mining
[J].
Objects as points
[J/OL].
大清河流域土地利用变化的地形梯度效应分析
[J].
Analysis of terrain gradient effects of land use change in Daqing River basin
[J].
Object detection in optical remote sensing images:A survey and a new benchmark
[J].
High-resolution mapping of the world’s reservoirs and dams for sustainable river-flow management
[J].
A comprehensive geospatial database of nearly 100 000 reservoirs in China
[J].
Backpropagation applied to handwritten zip code recognition
[J].
Very deep convolutional networks for large-scale image recognition
[J/OL].
U-net:Convolutional networks for biomedical image segmentation
[C]//
Deep residual learning for image recognition
[C]//
SegNet:A deep convolutional encoder-decoder architecture for image segmentation
[J].
DOI:10.1109/TPAMI.2016.2644615
PMID:28060704
[本文引用: 1]
We present a novel and practical deep fully convolutional neural network architecture for semantic pixel-wise segmentation termed SegNet. This core trainable segmentation engine consists of an encoder network, a corresponding decoder network followed by a pixel-wise classification layer. The architecture of the encoder network is topologically identical to the 13 convolutional layers in the VGG16 network [1]. The role of the decoder network is to map the low resolution encoder feature maps to full input resolution feature maps for pixel-wise classification. The novelty of SegNet lies is in the manner in which the decoder upsamples its lower resolution input feature map(s). Specifically, the decoder uses pooling indices computed in the max-pooling step of the corresponding encoder to perform non-linear upsampling. This eliminates the need for learning to upsample. The upsampled maps are sparse and are then convolved with trainable filters to produce dense feature maps. We compare our proposed architecture with the widely adopted FCN [2] and also with the well known DeepLab-LargeFOV [3], DeconvNet [4] architectures. This comparison reveals the memory versus accuracy trade-off involved in achieving good segmentation performance. SegNet was primarily motivated by scene understanding applications. Hence, it is designed to be efficient both in terms of memory and computational time during inference. It is also significantly smaller in the number of trainable parameters than other competing architectures and can be trained end-to-end using stochastic gradient descent. We also performed a controlled benchmark of SegNet and other architectures on both road scenes and SUN RGB-D indoor scene segmentation tasks. These quantitative assessments show that SegNet provides good performance with competitive inference time and most efficient inference memory-wise as compared to other architectures. We also provide a Caffe implementation of SegNet and a web demo at http://mi.eng.cam.ac.uk/projects/segnet.
YOLOv7:Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
[C]//
Fast R-CNN
[C]//
基于Faster R-CNN深度网络的遥感影像目标识别方法研究
[J].
DOI:10.12082/dqxxkx.2018.180237.
[本文引用: 1]
遥感影像目标识别在众多领域中具有极高的理论意义与应用价值,更快速、更精确的目标识别方法研究是目前遥感及图像研究领域的热点与难点。本文将深度学习的方法应用于遥感影像目标识别中,提出基于Faster R-CNN深度学习网络的目标快速精确识别方法。该方法采用了包括基于RPN的建议区域提取方法和VGG16训练卷积网络模型,构建了面向遥感影像目标识别的深度卷积神经网络。为验证该方法的精度及性能,在Caffe深度学习框架上,选取高分辨率遥感影像中飞机、油罐、操场及立交桥目标进行验证实验。结果表明,基于Faster R-CNN的深度学习方法能够实现对遥感影像目标的快速、准确识别,同时具有较好的推广性。通过本文的研究,证明基于Faster R-CNN深度学习的高分遥感影像目标识别方法具有显著优势和潜力,对基于其他深度学习方法的目标识别研究也有一定的参考意义。
Faster R-CNN deep learning network based object recognition of remote sensing image
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}