

0 引言
合成孔径雷达(synthetic aperture Radar, SAR)是一种主动侧视雷达系统,其成像方式与光学成像有着显著差异,具有独特的几何和辐射特性。SAR的成像处理过程是一种在点目标散射模型约束下的数据空间到图像空间的映射[1]。SAR图像的信息主要源于地物目标的后向散射,反映的灰度值受后向散射的影响。这使得SAR图像呈现以下特性:图像亮度代表后向散射的强度;粗糙表面产生强后向散射;平滑表面产生弱后向散射;含水量越大,后向散射越强。SAR图像的纹理特征主要通过灰度变化来描述,这些变化反映了地表的粗糙度和空间分布[2]。粗糙的表面能得到更高的后向散射,形成亮区;而平整表面则形成暗区,这使得SAR图像具有鲜明且丰富的上下文信息。
传统SAR图像船舶目标检测算法通常依赖单通道SAR数据,其中包含与船舶相关的强度信息。这些算法一般分为检测和区分2个步骤。其中,恒虚警率(constant false-alarm rate, CFAR)检测算法被广泛应用,其通过选择合适的杂波模型来计算最佳阈值,以保持恒定的虚警率,区分背景和目标[3]。CFAR算法首先使用杂波模型和恒定虚警率计算出一个分割阈值,然后基于此阈值对SAR图像中的像素进行分类[4]。然而,CFAR算法只考虑灰度对比度,忽略了目标的结构信息。为克服此限制,一些研究采用了极化SAR(polarization SAR,PolSAR)数据,能更有效反映船舶目标与海杂波之间的散射差异。例如,Sugimoto[5]通过极化分解处理协方差矩阵并去除旋转角度以提高船舶目标的二次散射; Wang等[6]提出一种基于极化特征的船舶目标检测方法,以解决SAR图像中船舶方向的模糊性; Liu等[7]通过新的邻域极化协方差矩阵(neighborhood polarization covariance matrix, NPCM)提高了船舶目标与海杂波之间的可分离性。此外,还有研究利用极化沿轨干涉SAR(polarization along-track Interference SAR,PolATInSAR)系统提高小型和缓慢移动目标的检测概率,并提高径向速度估计的准确性[8]。例如,张鹏等[9]开发的创新技术显著提高了沿轨干涉系统在识别和跟踪目标方面的性能。
近年来,深度学习技术的迅速发展,特别是其深度特征提取和强大的自适应学习能力,推动了其在SAR图像目标检测领域的应用,克服了传统目标检测模型的诸多限制。深度学习模型的目标检测技术主要分为两阶段检测和一阶段检测2类。两阶段检测算法先提取图像中的候选框,然后在区域建议和目标检测这2个阶段中对检测结果进行细化。此方法以较慢的检测速度换取较高的准确性。其中,以Girshick[10]开发的Fast R-CNN算法为代表,该方法利用卷积神经网络(convolutional neural network, CNN)从输入图像中提取特征,然后使用感光趣区域(region of interest,ROI)池化技术确保区域具有一致的大小,并将特征传入全连接网络进行分类。一阶段检测算法则直接从图像中计算检测结果,无需单独的区域建议阶段,速度更快,但准确性通常较两阶段检测算法低。作为代表的有SSD模型,该模型在特征图上生成多种不同尺度的候选框,并直接进行分类和回归,少了候选框筛选的过程[11]。但在传统和基于深度学习的SAR图像目标检测算法中,小目标检测仍然存在挑战。
为了解决上述问题,本文提出一种SAR图像船舶检测模型YOLO-HD。模型以YOLOv7[12]为基准,引入高维上下文注意力和双感受野增强技术,通过增大模型特征感受野,提高模型特征感受能力,并对图像的上下文信息进行特征信息高维提取,从而提高船舶图像中小目标的检测能力。此外,通过引入轻量级卷积模块、轻量化非对称多级压缩检测头和新的损失函数XIoU,降低了模型的计算量,优化了模型的性能。
1 本文方法
1.1 改进YOLOv7模型
本文选择YOLOv7作为基础模型来搭建SAR图像船舶检测模型YOLO-HD,具体如图1所示。首先在主干网络阶段,输入图像经过普通卷积层(conv-batch normalization-SiLU, CBS)处理和最大池化层(maxpool, MP)降维后馈入到轻量化高效层聚合网络中,从而对输入的图像像素和目标的位置实现匹配,完成特征提取。双感受野增强模块放置在网络的主干网络和头部网络之间,可以对主干网络中3个主要特征层进行多尺度感受野增强,进而从3个主要特征层中提取到更加详细的特征信息。接着在头部网络阶段,结合跨阶段部分卷积的空间金字塔池化(spatial pyramid pooling cross stage partial conv, SPPCSPC)将主干网络的输出调整成固定长度的特征向量,为后续的网络层提供有效的输入。
图1
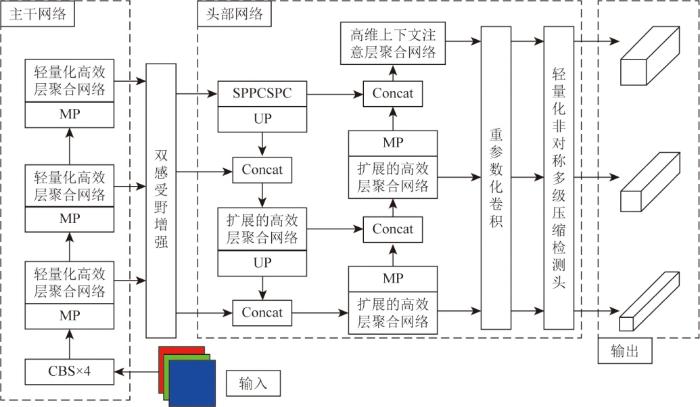
提取出的特征进行自下而上的上采样(UP),并将其相同尺寸大小的网络层特征进行拼接融合(Concat),通过扩展的高效层聚合网络引导不同的计算块组学习更多不同的特征。然后,高维上下文注意层聚合网络通过门控机制增强了上下文注意力对特征信息的利用,从而增强了模型对小目标的检测能力。最后,头部网络根据特征记忆将特征进行重参数化卷积并通过轻量化非对称多级压缩检测头检测图像中的目标。
1.2 高维上下文注意
图2
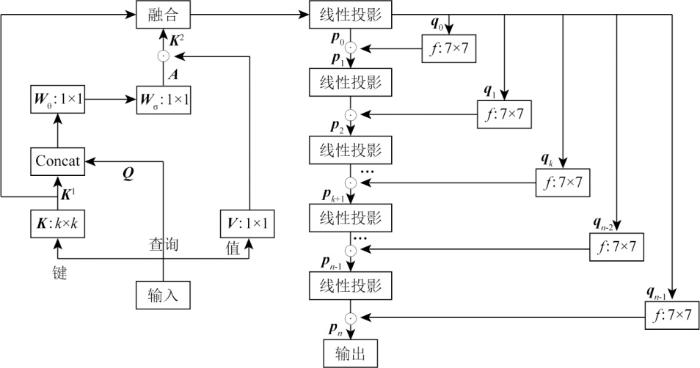
图2
高维上下文注意结构实现细节
Fig.2
Implementation details of high-dimensional contextual attention structure
首先,该模块利用输入的上下文信息来指导动态注意力矩阵的学习,从而增强视觉表征能力。CoT将特征图I∈RH×W×C(H为高度,W为宽度,C为通道数)转换为键K=I、查询Q=I、值V=IWV,其中WV为一个1×1的嵌入卷积。对于K,没有采用传统的1×1卷积,而是首先在空间上对k×k网格内的所有相邻的键采用k×k组卷积以上下文化每个键的表示。这样得到的上下文键K1∈RH×W×C,自然地反映相邻位置的静态上下文信息并将K1作为输入I的静态上下文表示。然后在K1和Q串联的条件下,通过2个连续的1×1卷积(带有ReLU激活函数的Wθ和不带激活函数的Wσ)获得注意力矩阵A,其公式为:
因此对于每个头部,A的每个空间位置的局部注意力矩阵是基于查询特征和上下文的键特征,而不是孤立的Query-Key对来学习的。这种方式通过静态上下文K1的额外指导增强了自注意力学习。此外根据上下文注意力矩阵A,通过聚合值V来计算特征图K2:
鉴于特征映射K2捕获了输入之间的动态特征交互,因此将K2命名为输入的动态上下文表示。最终CoT块的输出通过注意机制计算为静态上下文K1和动态上下文K2的融合。Vision Transformer[15]在基于点积自注意的空间建模机制驱动下,在更高阶对空间交互进行建模,受此启发,本文使用循环门控机制对静态和动态上下文表示的融合结果进行高阶空间交互,这样就实现了对融合结果进行的由粗到精的特征提取。循环门控机制的基础为一阶空间交互,在一阶空间交互中,首先将输入特征I经过线性投影,得到p0和q0。q0经过深度卷积(depthwise convolution,DWConv)后再与p0做点积得到p1。p1经过另一个线性投影得到输出O,此时一阶空间交互完成,相关公式为:
式中:f为DWConv;Linear为执行通道混合的线性投影层。设在n阶空间交互过程中的第k阶空间交互时得到p0和qk(k=0,1,…,n-1),继续循环地执行门控机制,可以依次得到pk+1,公式为:
式中:gk用来在不同阶进行维度对齐;α为输出缩放倍数以稳定训练。可见,每循环一次阶数就增加1,因此门控机制可以建模n阶空间交互。为了保证不增加太多计算量,第k阶的维度设置为:
由公式可见,整个特征提取过程是一个由粗到精的过程,在低阶时使用较少的通道。通过该模块,模型学习了上下文信息并进行了由粗到细的高维特征提取。
1.3 双感受野增强
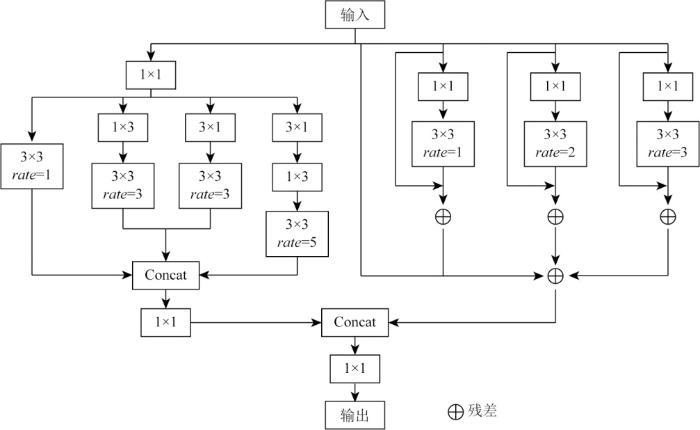
为了充分利用SAR图像中丰富的上下文特征,本文提出了双感受野增强模块,其目的是扩大特征层的感受野,进而提高舰船检测的精度。具体来说,采用了2种策略来实现感受野的增强,如图3所示。首先引入了一种利用平行的非对称卷积策略的感受野增强模块[16]。在该模块第1种策略中,特征层首先通过一个1×1的卷积减少特征层的通道维度;接着采用2个并行的卷积分支(1×3卷积分支和3×1卷积)以在宽度上增强特征,同时使用堆叠的1×3和3×1的卷积层,在高度上增强特征的卷积分支;最后使用膨胀率为1,3,3和5的膨胀卷积来获取具有更大感受野的特征图。这种设计使得特征层的感受野得到了扩大,从而更好地保留了图像的空间特征。第2种策略采用了基于膨胀卷积和采集加权层的多分支策略[17]。使用固定的卷积核大小为1×1以及不同的膨胀率(1,2,3)进行卷积,同时添加了残差连接,以防止训练期间的梯度爆炸或消失问题。采集和加权层用于收集不同分支的信息,并对每个分支的特征进行加权,以平衡不同分支的表示。最后,所有分支的结果被连接起来,并通过ReLU激活函数得到包含更多上下文信息的特征图。通过这2种策略,不仅增强了视觉表征的能力,还有效地提高了模型的性能。
图3
1.4 轻量化卷积
部分卷积(partial convolution,PConv)[18]利用了特征图的冗余,对于输入特征图I∈RH×W×C,如图4(a)所示,I的输入通道被分为Cp和C-Cp,PConv仅在输入通道的Cp部分上应用常规卷积进行空间特征提取,并使用滤波器F∈Rk×k进行处理,从而保持其余通道(C-Cp)不变。对于连续或规则的内存访问,将第一个或最后一个连续的通道视为整个特征图的代表进行计算。在不丧失一般性的情况下认为输入和输出特征图具有相同数量的通道。因此,PConv的计算量仅为H×W×k2×
图4
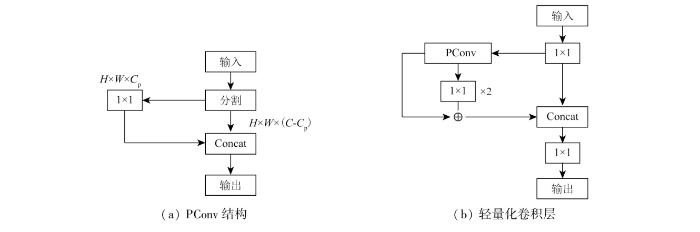
图4
轻量化卷积层实现细节
Fig.4
Implementation details of lightweight convolution layer structure
基于PConv,构建了轻量化卷积层模块,如图4(b)所示,该模块由PConv和常规卷积构成。首先对输入特征进行常规卷积;然后,对部分输出应用PConv,并使用残差模块避免梯度消失问题;最后,将经过PConv的输出特征与剩余输出进行连接,以稳定模块的效果。这种设计有效地平衡了网络复杂度和视觉表征能力。使用轻量化卷积层替换高效层聚合网络中的普遍卷积,构成轻量化高效层聚合网络。
1.5 检测头和损失函数
为了在降低网络模型复杂度的同时保持效能,引入一种轻量化非对称多级压缩检测头。该检测头针对各种任务类型进行优化,每个任务通过特定的网络路径完成。特别加深了专用于对象评分任务的网络路径,并使用3个卷积来扩展该任务的感受野和参数数量。同时,每个卷积层的特征都经过通道维度的压缩,从而缓解了与目标评分任务相关的训练难度,提高了模型性能,并显著提高了推理速度。
然而,直接对目标检测算法网络模块结构进行轻量化处理可能会导致检测性能下降。因此引入新的损失函数XIoU,以优化模块结构以外的部分,而不增加网络复杂度。XIoU惩罚项梯度更平缓,对异常具有更强的鲁棒性,能够更好地降低回归误差。XIoU损失函数的计算公式为:
式中:IoU为交并比;
2 实验及结果分析
2.1 数据集介绍
本文在扩充的高分辨率SAR图像数据集(expanded high resolution SAR images dataset, E-HRSID)上进行主要的实验。为了进一步验证模型性能,本文在E-HRSID和SAR舰船检测数据集(SAR ship detection dataset, SSDD)上进行了对比实验。HRSID数据集是高分辨率SAR图像中可用于船舶检测、语义分割和实例分割任务的数据集。该数据集包含5 604张高分辨率SAR图像和16 951个舰船实例,覆盖了不同的分辨率、极化、海况、海域和沿海港口[21]。HRSID数据集中SAR图像的分辨率分别为0.5 m,1 m和3 m。为了增强训练网络的鲁棒性,对这个数据集进行了负样本的扩充,使得数据集的总图片量达到了13 565张。这种丰富的数据集扩充将有助于提高模型的泛化能力和稳定性。SSDD 是第一个开放数据集,广泛用于基于深度学习的SAR图像舰船检测技术。SSDD总共包含1 160张图片,2 456舰船,平均每张图片的舰船数量为2.12艘。SSDD数据集中SAR图像的分辨率从1 m到15 m不等[22]。
2.2 实验环境及设置
实验在Ubuntu 20.04 LTS系统下进行,网络框架使用Pytorch 1.11搭建,CPU为Intel Xeon Gold 5320,内存32 GB,GPU为NVIDIA RTX A4000,显存16 GB。Batchsize设置为16,Epoch设置为200次,使用随机梯度下降法对网络参数进行调整。初始学习率0.01,权重衰减 0.000 5。将图像的宽和高均固定为640。
2.3 算法评价
对SAR图舰船检测的效果用召回率(recall,R)、精确率(precision,P)和平均精度(mean average precision,mAP)来表示,计算公式分别为:
式中:TP为舰船目标被标记为舰船的数量;FN为舰船目标被标记为非舰船的数量;FP为非舰船目标标记为舰船的数量。因为E-HRSID数据集中只有1个类别,所以mAP=AP。为了更好地衡量该模型二分类精确度,引入了F1分数[23]作为评估标准,计算公式为:
2.4 对比实验
本文在E-HRSID数据集和SSDD数据集上,对各种模型的性能进行了比较。CenterNet采取了创新的方法,从目标的中心点检测,而不是依赖左上角和右下角2个关键点,这使得其能够真正摆脱Anchor的限制[24]。Efficientdet延续了EfficientNet的复合缩放思路,使得模型在速度和精度之间取得了平衡[25]。Faster R-CNN是第一个端到端,接近实时性能的深度学习检测算法,其创新之处在于提出了区域选择网络用于生成候选框,极大提升了检测框的生成速度[26]。RetinaNet提出了Focal Loss损失函数,用以降低大量easy negatives在标准交叉熵中的权重,提高hard negatives的权重[27]。SSD通过设定先验框,采用多尺度特征图进行检测,同时使用卷积进行检测。YOLO将目标检测任务定义为端到端的回归问题,这是单阶段目标检测的开创之作[28],YOLOv8则是该系列最新的模型结构。
表1为本文YOLO-HD模型与以上基本模型的精度对比结果。在E-HRSID数据集中,本文模型的mAP达到91.36%,F1分数达到了0.87。与基础模型YOLOv7相比,本文模型的mAP提高了4.56百分点,F1分数上升了0.04;与最新的模型YOLOv8相比,本文模型在mAP上提高了0.89百分点,F1分数上升了0.01。在SSDD数据集中,本文模型的mAP达到97.64%,F1分数达到了0.95。与基础模型YOLOv7相比,本文模型的mAP提升了9.83百分点,F1分数上升了0.11;与YOLOv8相比,本文模型的mAP有0.54百分点的提升。
表1 E-HRSID和SSDD数据集对比实验结果
Tab.1
| 模型 | E-HRSID | SSDD | ||||||
|---|---|---|---|---|---|---|---|---|
| P/% | R/% | mAP/% | F1 | P/% | R/% | mAP/% | F1 | |
| CenterNet | 96.63 | 60.95 | 76.77 | 0.75 | 97.46 | 75.42 | 89.04 | 0.83 |
| Efficientdet | 97.29 | 22.36 | 34.73 | 0.36 | 95.77 | 25.09 | 73.83 | 0.40 |
| Faster R-CNN | 34.3 | 35.71 | 26.95 | 0.35 | 73.50 | 68.07 | 88.12 | 0.71 |
| RetinaNet | 93.31 | 27.65 | 34.35 | 0.43 | 86.81 | 63.14 | 80.86 | 0.73 |
| SSD | 88.79 | 16.34 | 40.64 | 0.28 | 95.80 | 42.07 | 89.58 | 0.58 |
| YOLOv7 | 88.16 | 78.16 | 86.80 | 0.83 | 90.80 | 78.00 | 87.81 | 0.84 |
| YOLOv8 | 89.53 | 83.27 | 90.47 | 0.86 | 95.40 | 91.80 | 97.10 | 0.94 |
| YOLO-HD | 90.65 | 84.36 | 91.36 | 0.87 | 95.25 | 95.55 | 97.64 | 0.95 |
E-HRSID数据集数据量比SSDD数据集的数据量多,这使得本文算法在SSDD数据集上的检测精度和F1分数更高。此外,由于E-HRSID数据集是在HRSID数据集基础上进行负样本扩充,本文算法并未像Faster R-CNN等算法那样,在E-HRSID数据集上出现检测精度下降的情况,这证明了本文算法具有良好的鲁棒性。
图5
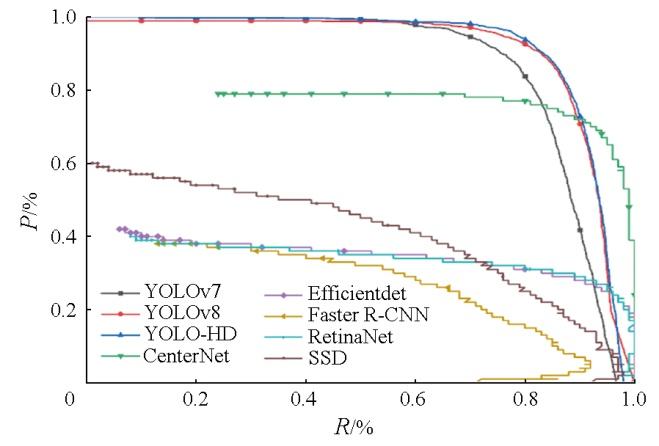
表2 4种模型的检测结果
Tab.2
| SAR图像 | 真实值 | YOLOv7 | YOLO-HD | YOLOv8 | CenterNet |
|---|---|---|---|---|---|
| 图像1 |  | ||||
| 图像2 |  | ||||
| 图像3 |  | ||||
| 图像4 |  | ||||
2.5 消融实验
为了验证每个模块的有效性,本文基于E-HRSID数据集,对双感受野增强(DRFE)、高维上下文注意(HD-ELAN)、轻量化非对称多级压缩检测头(LAMCD)、XIoU损失函数以及轻量化高效层聚合网络(L-ELAN)模块进行了消融实验。对R,P,mAP,模型参数量以及计算效率进行了比较,其中计算效率用每秒10亿次运算数(giga floating-point operations per second,GFLOPS)表示,详细结果见表3。由表3可知,原始模型效果最低。本文提出的位于主干与头部之间的双感受野增强模块,对3个有效特征层进行了多尺度感受野增强,从而丰富了模型的特征提取和融合,进而提高了网络的泛化能力。在检测中,R提升了3.23百分点,mAP提升了2.05百分点。提出的高维上下文注意模块,对双感受野增强模块提取出的特征信息进行了静态和动态的上下文表示融合,并实现了高阶空间交互。在检测中,对比基础模型R提升了2.94百分点,P提升了2.38百分点,mAP提升了2.99百分点。总体上,相较于基础模型,本文模型的R提升了6.2百分点,P提升了2.49百分点,mAP提升了4.56百分点。这些数据验证了提出的模型结构和方法的有效性。
表3 消融试验
Tab.3
| 模型 | DRFE | HD-ELAN | LAMCD | XIoU | L-ELAN | P/% | R/% | mAP/% | 参数量/MB | GFLOPS |
|---|---|---|---|---|---|---|---|---|---|---|
| 基础模型 | — | — | — | — | — | 88.16 | 78.16 | 86.80 | 38.4 | 105.4 |
| Net1 | √ | — | — | — | — | 88.14 | 81.39 | 88.85 | 43.4 | 108.7 |
| Net2 | — | √ | — | — | — | 90.54 | 81.10 | 89.79 | 39.4 | 162.1 |
| Net3 | √ | √ | — | — | — | 90.45 | 78.90 | 89.29 | 37.6 | 141.2 |
| Net4 | √ | √ | √ | — | — | 91.21 | 82.92 | 90.89 | 51.0 | 187.0 |
| 本文模型 | √ | √ | √ | √ | √ | 90.65 | 84.36 | 91.36 | 56.8 | 143.2 |
3 结论
为了更有效地利用SAR图像中丰富的上下文信息来提高SAR船舶图像中小目标的检测能力,本文提出了一种基于YOLOv7的改进目标检测模型。通过构建高维上下文注意力和双感受野增强,增强了模型对SAR图像中丰富上下文信息提取的能力,实现了由粗糙到精细的特征提取,从而增强了对SAR图像中舰船检测的感知力。
在E-HRSID和SSDD数据集上的实验结果显示,改进后的模型具有更高的检测精度,mAP比基础模型分别提高了4.56和9.83百分点。此外,对比实验表明,本文提出的改进模型的检测能力超越了现有的检测算法,能够更准确地识别出SAR图像中的舰船位置。
同时发现,在强调对于SAR船舶图像上下文信息的利用的同时,如何加强对背景影响较大的目标的检测能力,成为未来可进一步优化模型方法、提高目标检测的精度的方向。
参考文献
合成孔径雷达参数化成像技术进展
[J].
Research progress on synthetic aperture Radar parametric imaging methods
[J].
SAR change detection based on intensity and texture changes
[J].
Target detection in synthetic aperture Radar imagery:A state-of-the-art survey
[J].
一种改进的高分辨率SAR图像超像素CFAR舰船检测算法
[J].
An improved superpixel-based CFAR method for high-resolution SAR image ship target detection
[J].
Removal of azimuth ambiguities and detection of a ship:Usingpolarimetric airborne C-band SAR images
[J].
PolSAR ship detection based on neighborhood polarimetric covariance matrix
[J].
Constant false alarm rate detection of slow targets in polarimetric along-track interferometric synthetic aperture radar imagery
[J].
基于相干度优化的极化顺轨干涉SAR慢小目标CFAR检测
[J].
Slow and small target CFAR detection of polarimetric along-track interferometric SAR using coherence optimization
[J].
Fast R-CNN
[C]//
YOLOv7:Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
[C]//
Contextual transformer networks for visual recognition
[J].
Hornet:Efficient high-order spatial interactions with recursive gated convolutions
[J].
Attention is all you need
[J].
Lightweight multi-scale network for small object detection
[J].
YOLO-FaceV2:A scale and occlusion aware face detector
[J].
Run,don’twalk:Chasing higher FLOPS for faster neural networks
[C]//
Xception:Deep learning with depthwise separable convolutions
[C]//
Deeproots:Improving CNN efficiency with hierarchical filter groups
[C]//
HRSID:A high-resolution SAR images dataset for ship detection and instance segmentation
[J].
SAR ship detection dataset (SSDD):Official release and comprehensive data analysis
[J].
The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation
[J].
DOI:10.1186/s12864-019-6413-7
PMID:31898477
[本文引用: 1]

To evaluate binary classifications and their confusion matrices, scientific researchers can employ several statistical rates, accordingly to the goal of the experiment they are investigating. Despite being a crucial issue in machine learning, no widespread consensus has been reached on a unified elective chosen measure yet. Accuracy and F score computed on confusion matrices have been (and still are) among the most popular adopted metrics in binary classification tasks. However, these statistical measures can dangerously show overoptimistic inflated results, especially on imbalanced datasets.The Matthews correlation coefficient (MCC), instead, is a more reliable statistical rate which produces a high score only if the prediction obtained good results in all of the four confusion matrix categories (true positives, false negatives, true negatives, and false positives), proportionally both to the size of positive elements and the size of negative elements in the dataset.In this article, we show how MCC produces a more informative and truthful score in evaluating binary classifications than accuracy and F score, by first explaining the mathematical properties, and then the asset of MCC in six synthetic use cases and in a real genomics scenario. We believe that the Matthews correlation coefficient should be preferred to accuracy and F score in evaluating binary classification tasks by all scientific communities.
Objects as points
[J/OL].
EfficientDet:Scalable and efficient object detection
[C]//
FasterR-CNN:Towards real-time object detection with region proposal networks
[J].
Focal loss for dense object detection
[C]//
You only look once:Unified,real-time object detection
[C]//

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}