

0 引言
地球观测早期发展阶段侧重于观测数据的开放共享[1-
地球观测组织(Group on Earth Observations,GEO)是地球观测领域最大和最权威的政府间国际组织,建立了全球综合地球观测系统(Global Earth Observation System of Systems,GEOSS),实现了全球地球观测数据资源的汇聚,从“少”到“多”,使海量数据可查询可访问[2]。GEO在2015—2025新十年战略计划中确立了提供关键地球观测数据、信息和知识的目标,从而为应对全球变化挑战提供决策参考[4]。在2019年GEO第五次部长级峰会暨第十六届全会上正式提出了构建知识枢纽(GEO Knowledge Hub,GKH)的蓝图,同时迅速组建了GEO基础设施开发工作组(GEOSS Infrastructure Development Task Team, GIDTT),负责 GEO 内部协调,推动从“开放数据”向“开放知识”的深入,持续实现数据、信息和知识资源的管理和共享。GKH作为一个地球观测应用数字图书馆,其目标受众是世界各地地球观测应用领域需要利用信息做出决策的专家学者。这些专家学者可能在大学、研究机构、政府部门,或是私人公司工作,他们的共同点是都需要体系化、权威性的信息,从而为决策提供可行性建议。因此他们需要知道可用的数据、算法和工具,以及是否已经有类似的成果可借鉴。以此为目标,GKH将完成数据、算法、代码、论文、研究案例、研究人员等领域的知识建模,形成一个可运行、可展示的系统,并和GEOSS互补和集成,从而提升对地观测应用的可发现、可访问、可互操作和可重用能力。但目前GKH还处于研发的探索阶段,GEOSS的架构和能力目前仍存在不足,从“地球观测资源多”到“地球观测资源好”的转变尚未实现。
地球观测应用的知识服务可以有效地借鉴语义网(Semantic Web)本体理论和技术。从基于实体链接的语义网,到用图模型描述知识和建模世界万物关联关系的知识图谱(Knowledge Graph),计算机可理解、可推理、可计算、可呈现的语义描述能力体系基本形成[5-
在这项研究中展示了一个地球观测知识库(Earth Observation Knowledge Base,EOKB),该知识库提供了地球观测数据到应用的整体和多模式视图,其表达结果已在GitHub上开放共享(
1 地球观测数据资源
本文地球观测知识库所采用的重要数据源主要分为地球科学变量概念体系、地球观测卫星和载荷、观测和模拟数据产品以及学术文献开放知识库4部分内容。
1.1 地球科学变量概念体系
地球科学变量是表征地球环境组成的重要知识,也是地球卫星遥感数据所观测或反演的对象。准确、全面的地球系统“圈层-变量”体系是表征全球变化和卫星遥感数据语义的基础性知识。
美国航空航天局(National Aeronautics and Space Administration,NASA)全球变化主目录(Global Change Master Directory,GCMD)是一组分层的地球科学词汇表,有助于确保以一致和全面的方式描述地球科学数据、服务和变量,并支持对元数据的精确搜索[12]。地球观测系统数据和信息系统 (Earth Observing System Data and Information System,EOSDIS) 以及许多国际机构使用GCMD词汇表作为权威词汇、分类法或词库,来描述地球科学数据、服务和可视化,并在在线元数据目录中搜索和访问地球科学数据。GCMD Earth Science Keywords从大气、地表、海洋等14个主题出发划分了6级体系,涵盖了超过1 000个基础变量,是当前地球科学领域最为庞大的“圈层-变量”体系,包含地球系统组成及其变化方面的6级关键词体系: 14个主题、125个术语、976个一级变量、1 068个二级变量、322个三级变量和四级自定义变量。主题表示学科和高级概念,术语和变量定义主题领域和参数,自定义变量是不受控值,用户可以添加这些值以更具体地描述数据。以“地表(land surface)”主题为例,包含“土地利用/土地覆盖(land use/land cover)”术语、“土地利用/土地覆盖分类(land use/land cover classification)”一级变量、“植被指数(vegetation index)”二级变量、“归一化植被指数(normalized difference vegetation index,NDVI)”三级变量。每个主题、术语和变量都提供了具体释义。
此外,国际卫星对地观测委员会(Committee on Earth Observation Satellites,CEOS)建立了MIM Measurement Keywords[13],涵盖了与地球遥感观测卫星数据直接相关的关键观测变量,分为三级体系: 主题、一级变量和二级变量。以“陆地(land)”主题为例,包含“植被(vegetation)”一级变量、“归一化植被指数(NDVI)”二级变量。此外,每个二级变量都具有到GCMD Earth Science Keywords的映射结果。
1.2 地球观测卫星和载荷
地球观测卫星和载荷提供有关地球及其环境的重要数据,有助于了解基本的地球系统以及人类对其的影响。这些数据涵盖了非常广泛的地球环境参数,包括大气、陆地、海洋和冰雪在内的整个环境范围。卫星和载荷既是地球卫星遥感数据(各级原始观测或测量结果和各类高级数据产品)的基础溯源信息,也是多种数据间的重要联系桥梁。
基于web的观测系统,世界气象组织(World Meteorological Organization,WMO)建立了面向公众的能力分析和评估工具(Observing Systems Capability Analysis and Review Tool,OSCAR),该工具主要包括天基能力模块(OSCAR Space)和观测需求模块(OSCAR Requirements),用于分析WMO应用领域的观测需求和观测能力[14]。OSCAR Space是为支持地球观测研究和全球卫星任务协调而提供的观测卫星和载荷资源,由WMO秘书处、空间机构和应用专家密切合作,共同更新信息,目前收录了862颗已退役、在轨和计划发射的地球观测卫星,及其搭载的1 088颗观测载荷。卫星信息包含轨道、运行状态、发射时间等16个重要参数,载荷信息包含观测目标、光谱波段、时间分辨率、空间分辨率等24个重要参数。在数据获取方式上,OSCAR Space除了基于web的在线交互展示,还提供了Excel格式导出和调用JSON应用程序编程接口(application programming interface,API)2种方法,其中在线访问页面信息最为全面,Excel格式导出和JSON API获取的数据资源各有缺失。
1.3 观测和模拟数据产品
大型遥感数据中心提供的观测数据产品的可发现、可访问、可互操作和可重用能力在全球范围有了大规模提升,这一提升集中表现在国家遥感数据中心、国际合作组织和第三方集成商对其的应用上。国家遥感数据中心承担卫星遥感原始数据的接收、处理和数据产品共享的职责,代表性的有NASA的EOSDIS、欧空局哥白尼地球观测计划(Europe’s Copernicus Programme)、美国地质勘探局地球资源观测与科学中心(Earth Resources Observation and Science,EROS)等,提供观测数据并实现对地球科学数据产品的存档、管理和分发[15]。卫星遥感领域的国际合作组织进一步整合和集成不同国家和机构的遥感数据管理和服务能力,GEO研制的GEOSS实现了对超过150个自主数据目录和信息系统中约4亿数据和信息资源的聚合搜索[2]。在第三方集成商方面,以谷歌地球引擎(Google Earth Engine,GEE)[16]为代表的解决方案则重在加强数据“可访问”能力,提供了高性能交互式的数据分析网站。
在模拟数据产品的共享上,国际耦合模式比较计划(Coupled Model Intercomparison Project,CMIP)是由世界气候研究计划(World Climate Research Programme,WCRP)耦合模拟工作组(Working Group on Coupled Modelling,WGCM)于1995年发起和组织的,以“推动模式发展和增进对地球气候系统的科学理解”为目标。迄今为止,WGCM先后组织了6次模式比较计划(CMIP1—6)。CMIP6是CMIP计划实施以来参与的模式数量最多、设计的科学试验最为完善、所提供的模拟数据最为庞大的一次。CMIP参研单位按照气候模式诊断和比较计划(Program for Climate Model Diagnosis & Intercomparison,PCMDI)的统一安排,建立地球系统网格联盟(Earth System Grid Federation,ESGF)数据节点,完成全球共享发布[17]。数据流包含如下步骤: 各个模式中心按照统一的实验设计完成各种模拟实验; 部署ESGF软件完成数据发布,并接入PCMDI全球数据共享网络; PCMDI构建CMIP数据检索网站,帮助模式分析评估科学家感兴趣的模式数据,提供下载脚本; 数据用户从各个模式数据中心下载数据到本地,完成后续的分析工作。
1.4 学术文献开放知识库
学术文献是地球观测应用的一个代表性研究成果,是传播知识的主要途径。随着时间的推移,研究人员在地球观测数据的应用过程中积累了大量的学术文献。目前已经有许多研究致力于提供开放或非商业使用的学术文献数据库和知识图谱,这可以为进行数据挖掘相关工作的研究人员提供大规模的基准数据集。
Crossref[18]是一个DOI注册机构,负责注册的资源类型以学术文献为代表。当出版商与Crossref合作为一篇学术文献注册DOI时,出版商需要向Crossref提供该文献的元数据,然后Crossref据此公开这些元数据(参考文献列表由出版商决定公开的权限)。Crossref本身并不主动收集和充实数据,数据的完整性和质量取决于出版商提供的内容。目前Crossref已经成为学术数据的最主要来源之一。微软基于出版商提供的公开数据、Bing索引的网页信息以及内部知识库,构建并开放了微软学术图谱(Microsoft Academic Graph,MAG)[19-20]。MAG包含科学文献、引文关系、作者、机构、期刊、会议和研究领域等资源,是最全面和开放的学术数据库之一,遗憾的是MAG在2022年正式停止了服务。Open-Alex[21]是2022年刚上线的一个完全开放(数据、API、代码)的学术元数据资源库,旨在填补MAG停止服务所带来的空缺,目前主要的数据源来自MAG,Crossref和其他一些核心资源库。
2 地球观测知识库
本文构建了包含地球科学变量、遥感卫星、观测载荷、观测和模拟数据集、期刊和学术文献共6类本体和实例的地球观测知识库,如图1所示。地球科学变量针对包括大气圈、水圈、冰冻圈、岩石圈、生物圈和日地空间内的不同概念,整理、归纳和分析包括GCMD和CEOS等在内的不同概念分类体系,将地学概念划分为大气、社会经济、陆地、海洋、冰雪5个一级类,以及总计4级的层级划分。根据WMO OSCAR Space导出的表格数据资源获取和整合遥感卫星和观测载荷的数据。参考NASA的目录交换格式标准(directory interchange format,DIF)、联邦地理数据委员会的数字空间元数据内容标准(content standard for digital geospatial metadata,CSDGM)、ISO地理信息标准委员会的ISO19115等科学数据元数据管理标准,定义数据集的属性。从NASA Common Metadata Repository数据目录提供的API接口下载和整理地球观测卫星数据集,以及从ESGF元数据目录的API接口获取CMIP6 气候变化模拟和预估数据集。学术文献和期刊的数据资源获取和整合自OpenAlex开放知识库,其中学术文献以Scientific Data期刊出版的数据文章为示例。
图1
图2以观测和模拟数据集为例展示知识本体和实例构建的流程。数据集的类名为“DatasetCollection”,基于“owl: topDataProperty”定义摘要、创建时间、所有者、时空范围和分辨率等33个数据属性。数据集实例以“DC”为编号逐个递增,将“title”数据属性作为“rdf: comment”便于查看和展示。
图2
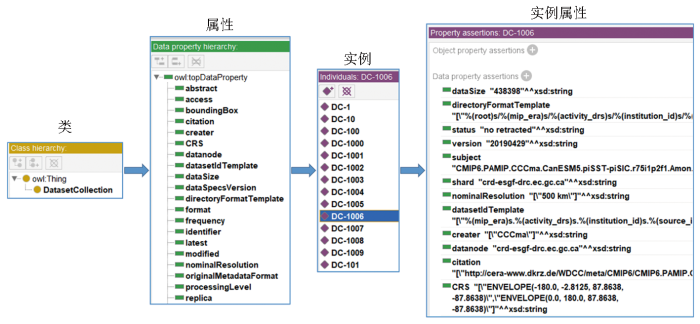
图2
知识本体和实例构建的流程示意图
Fig.2
Diagram of the construction of the knowledge ontology and instances
图3展示了地球观测知识本体和实例之间的关联示范。以“土地覆盖”地球科学变量为研究主题,在Scientific Data期刊上发表有“文章-1”,同时引用了“数据集-1/2”。其中“数据集-1”基于Sentinel-1卫星搭载的SAR-C载荷所观测的数据,“数据集-2”获取自Landsat7卫星搭载的ETM+观测载荷。
图3
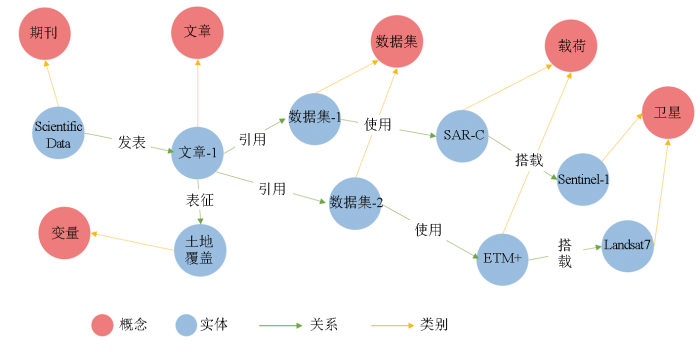
图3
地球观测知识本体和实例的关联可视化示例
Fig.3
Example of linking Earth observation ontology and instances
近年来,随着社交网络和语义网等应用领域的兴起,频繁的模式变化、海量数据的管理、实时查询响应时间以及纷繁复杂的数据关系等需求增加,图数据库的优越性渐渐显示出来。图数据库不仅能有效存储数据点之间的关系,而且在添加新的关系或者根据新的业务需求调整数据模型方面也很灵活。本文目前采用GraphDB图数据库来存储、管理和可视化这个地球观测知识本体和实例。GraphDB是一个高效、健壮且可扩展的图形数据库,实现了RDF4J框架接口、W3C SPARQL协议规范,并支持所有 RDF 序列化格式。
3 结论
本文以GEO提出的地球观测GKH的目标为出发点,基于语义网本体理论和技术,构建了包含地球科学变量、遥感卫星、观测载荷、观测和模拟数据集、期刊和学术文献共6类本体和实例的地球观测知识本体和实例。这项工作是地球观测领域知识表达的初步尝试,其语义网和知识图谱相关技术可以较好地描述地球观测领域概念之间的关联关系。本研究的知识表达结果对未来地球观测领域的数据和关联的描述,以及从数据共享到动态的知识服务等方面都会有很大的应用场景。本工作为中国参与国际地球观测GKH提供了技术支撑。
参考文献
Satellites:Make Earth observations open access
[J].
Big data challenges in building the Global Earth Observation System of Systems
[J].
Benefits of the free and open Landsat data policy
[J].
Towards a knowledge base to support global change policy goals
[J].DOI:10.1080/17538947.2018.1559367 URL [本文引用: 1]
知识图谱划分算法研究综述
[J].
Research on knowledge graph partitioning algorithms:A survey
[J].
知识图谱综述——表示、构建、推理与知识超图理论
[J].
DOI:10.11772/j.issn.1001-9081.2021040662

针对知识图谱(KG)在知识驱动的人工智能研究中发挥的强大支撑作用,分析并总结了现有知识图谱和知识超图技术。首先,从知识图谱的定义与发展历程出发,介绍了知识图谱的分类和架构;其次,对现有的知识表示与存储方式进行了阐述;然后,基于知识图谱的构建流程,分析了各类知识图谱构建技术的研究现状。特别是针对知识图谱中的知识推理这一重要环节,分析了基于逻辑规则、嵌入表示和神经网络的三类典型的知识推理方法。此外,以异构超图引出知识超图的研究进展,并提出三层架构的知识超图,从而更好地表示和提取超关系特征,实现对超关系数据的建模及快速的知识推理。最后,总结了知识图谱和知识超图的典型应用场景并对未来的研究作出了展望。
Knowledge graph survey:Representation,construction,reasoning and knowledge hypergraph theory
[J].
面向知识图谱的知识推理综述
[J].
Overview on knowledge reasoning for knowledge graph
[J].
OpenKG chain:A blockchain infrastructure for open knowledge graphs
[J].
A Chinese geographic knowledge base for GIR
[C]//2017 IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing (EUC).
CrowdGeoKG:Crowdsourced geo-knowledge graph
[C]//
WorldKG:A world-scale geographic knowledge graph
[C]//
The evolution of a geoscience standard:An instructive tale of science keyword development and adoption
[J].DOI:10.1016/j.gsf.2022.101400 URL [本文引用: 1]
The CEOS database
[DB/OL] (
The world meteorological organization and space-based observations for weather,climate,water and related environmental services
[M]//
Google Earth Engine:Planetary-scale geospatial analysis for everyone
[J].
Coordinating an operational data distribution network for CMIP6 data
[J].
DOI:10.5194/gmd-14-629-2021
[本文引用: 1]
The distribution of data contributed to the Coupled Model Intercomparison Project Phase 6 (CMIP6) is via the Earth System Grid Federation (ESGF). The ESGF is a network of internationally distributed sites that together work as a federated data archive. Data records from climate modelling institutes are published to the ESGF and then shared around the world. It is anticipated that CMIP6 will produce approximately 20 PB of data to be published and distributed via the ESGF. In addition to this large volume of data a number of value-added CMIP6 services are required to interact with the ESGF; for example the citation and errata services both interact with the ESGF but are not a core part of its infrastructure. With a number of interacting services and a large volume of data anticipated for CMIP6, the CMIP Data Node Operations Team (CDNOT) was formed. The CDNOT coordinated and implemented a series of CMIP6 preparation data challenges to test all the interacting components in the ESGF CMIP6 software ecosystem. This ensured that when CMIP6 data were released they could be reliably distributed. No. DE-ACO2-05CH11231 and authors at Lawrence Livermore National Laboratory (LLNL) under contract DE-AC52-07NA27344 with the U.S. Department of Energy. The United States Government retains and the publisher, by accepting the article for publication, acknowledges that the United States Government retains a non-exclusive, paid-up, irrevocable, world-wide license to publish or reproduce the published form of this manuscript, or allow others to do so, for United States Government purposes. The Department of Energy will provide public access to these results of federally sponsored research in accordance with the DOE Public Access Plan (http://energy.gov/downloads/doe-public-access-plan).
Crossref:The sustainable source of community-owned scholarly metadata
[J].
DOI:10.1162/qss_a_00022
URL
[本文引用: 1]
This paper describes the scholarly metadata collected and made available by Crossref, as well as its importance in the scholarly research ecosystem. Containing over 106 million records and expanding at an average rate of 11% a year, Crossref’s metadata has become one of the major sources of scholarly data for publishers, authors, librarians, funders, and researchers. The metadata set consists of 13 content types, including not only traditional types, such as journals and conference papers, but also data sets, reports, preprints, peer reviews, and grants. The metadata is not limited to basic publication metadata, but can also include abstracts and links to full text, funding and license information, citation links, and the information about corrections, updates, retractions, etc. This scale and breadth make Crossref a valuable source for research in scientometrics, including measuring the growth and impact of science and understanding new trends in scholarly communications. The metadata is available through a number of APIs, including REST API and OAI-PMH. In this paper, we describe the kind of metadata that Crossref provides and how it is collected and curated. We also look at Crossref’s role in the research ecosystem and trends in metadata curation over the years, including the evolution of its citation data provision. We summarize the research used in Crossref’s metadata and describe plans that will improve metadata quality and retrieval in the future.
Microsoft academic graph:When experts are not enough
[J].
DOI:10.1162/qss_a_00021
URL
[本文引用: 1]
An ongoing project explores the extent to which artificial intelligence (AI), specifically in the areas of natural language processing and semantic reasoning, can be exploited to facilitate the studies of science by deploying software agents equipped with natural language understanding capabilities to read scholarly publications on the web. The knowledge extracted by these AI agents is organized into a heterogeneous graph, called Microsoft Academic Graph (MAG), where the nodes and the edges represent the entities engaging in scholarly communications and the relationships among them, respectively. The frequently updated data set and a few software tools central to the underlying AI components are distributed under an open data license for research and commercial applications. This paper describes the design, schema, and technical and business motivations behind MAG and elaborates how MAG can be used in analytics, search, and recommendation scenarios. How AI plays an important role in avoiding various biases and human induced errors in other data sets and how the technologies can be further improved in the future are also discussed.
An overview of Microsoft Academic Service (MAS) and applications
[C]//

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}