基于主动深度学习的极化SAR图像分类
徐佳 , 袁春琦
, 袁春琦
Active deep learning based polarimetric SAR image classification
XU Jia, YUAN Chunqi
中图分类号: TP751.1
文献标识码: A
文章编号: 1001-070X(2018)01-0072-06
责任编辑:
收稿日期: 2016-06-30
修回日期: 2016-08-9
网络出版日期: 2018-01-20
版权声明: 2018 《国土资源遥感》编辑部 《国土资源遥感》编辑部
基金资助:
作者简介:
第一作者: 徐 佳(1983-),女,博士,副教授,硕士生导师,主要从事多源遥感信息融合与应用方面的研究。Email:hhuxj@hhu.edu.cn。
展开
摘要
针对极化SAR图像在监督分类时存在人工标注样本费时费力以及浅层结构学习算法的表达能力有限等问题,提出一种基于主动深度学习的极化SAR图像分类方法。首先,对测量数据进行多种极化特征提取,以便完整地描述图像信息; 在此基础上,通过自动编码器对大量无标记样本进行非监督学习,提取更具可分性和不变性的深层特征; 然后,利用少量标记样本训练分类器,并与自动编码器连接,以监督学习的方式微调整个网络; 最后,通过主动学习,选择对当前分类器最有价值的样本(分类模糊度最大的样本)进行人工标记,并加入到训练样本中,重新训练分类器和微调网络。对RADARSAT-2和EMISAR极化SAR影像进行不同分类的实验结果表明,该方法能在更少人工标记的样本下获得较高的分类精度。
关键词:
Abstract
Supervised classification methods usually require adequate labeled samples which are difficult and time-consuming to obtain for polarimetric SAR images, while the expression capability of the shallow structure learning algorithm is limited. A novel supervised classification method for polarimetric SAR imagery based on active deep learning is proposed in this paper. Firstly, the features are extracted from an original image by multiple polarization target decomposition methods for fully describing the data,and the features which are separable and invariable can be extracted with unsupervised learning by auto-encoder. Then, the initial classifier is trained and fine-tune the whole model with a small number of labeled samples. Finally, the most valuable samples (the largest ambiguity samples for classifier)are selected to label by active learning. Experimental results in comparison with conventional methods for polarimetric SAR data sets of RADARSAT-2 and EMISAR show that the proposed method can achieve higher classification accuracy with a small number of labeled samples.
Keywords:
0 引言
极化SAR具有传统SAR的全天时、全天候、穿透能力强等优点,还涵盖着更加丰富的地物信息。因此,在分类和目标识别等领域有着广泛的应用前景[1]。现有的极化SAR图像分类方法中,非监督分类不需要人工标记样本,极大地减少了分类成本,但无法保证分类精度[2,3]; 监督分类通常能取得相对较好的分类结果,却要依赖大量、高质量的标记样本[4,5]; 半监督分类则综合利用少量标记样本和大量未标记样本,弥补了监督与非监督分类的不足,但在少量标记样本的情况下,分类器的性能受到限制,难以有效利用未标记样本[6,7]。
针对上述问题,不少学者将主动学习应用在SAR数据分类领域[8,9],希望通过分类器主动选择最有价值的未标记样本交给专家进行标记,而不是被动接受专家提供的标记样本,以解决分类器在小样本情况下分类精度低等问题。文献[8]在SAR数据分类效果上的研究表明,基于“最优”对“次优”(best-versus-second-best,BVSB)准则的主动学习优于传统的基于熵的主动学习。其基本思想是: 按照BVSB准则选择未标记样本中不确定性大的样本进行人工标注,即以未标记样本的后验概率中最优类别的概率与次优类别的概率之差作为对不确定性的评价指标,其差值越小,不确定性越大[10]。文献[9]将基于委员会采样的主动学习应用在极化SAR数据分类中,其主要为采用多个分类器对未标记样本进行委员会投票,将投票数作为评价样本价值的指标,即选择分类结果最不一致的样本进行人工标记。虽然上述方法均能在较少标记样本的情况下取得较好的分类效果,但是在一定程度上依赖其分类器的分类性能; 而文献[8]使用的支持向量机(support vector machine,SVM)与文献[9]使用的极限学习机(extreme learning machine,ELM)均为浅层结构学习算法,面对有限标记样本和复杂分类问题时,其分类器的泛化能力受到一定制约[11],因而影响主动选择样本的有效性。
深度学习作为一种深层非线性网络结构算法,具有在少量样本中实现复杂函数逼近、学习数据本质特征的强学习能力,能有效解决上述问题。因此,本文提出一种基于主动深度学习的极化SAR图像分类方法。该方法将基于BVSB准则的主动学习与典型的深度学习结构——自动编码器(AutoEncoder)相结合。首先,通过自动编码器对大量无标记样本进行非监督学习,提取更具有可分性和不变性的深层特征; 其次,利用少量标记样本训练softmax分类器,并与自动编码器连接,以监督学习的方式微调整个网络; 最后,通过主动学习选择对当前分类器最有价值的样本进行人工标记,并加入到训练样本中重新训练分类器和微调网络。对RADARSAT-2和EMISAR极化SAR影像进行不同分类的实验表明,本文方法相对其他方法能在更少人工标记样本下获得较高的分类精度。
1 极化SAR特征提取
极化SAR一般以测量数据(即散射矩阵、相干矩阵或者协方差矩阵)表征地物信息,虽然极化测量数据涵盖了全部的地表信息,但是没有对具体的目标地物进行相应的物理解释,不利于目标识别与分类。为此,不少学者通过极化目标分解,将测量数据分解成不同成分,以表征目标的几何结构或散射信息[12]。
为充分利用极化SAR图像中的信息,本文除了使用相干矩阵中的9个元素作为分类的特征之外,还通过多种极化目标分解方法提取极化分解特征,共25维(表1)。将上述34个特征组成特征向量并进行归一化,以便后续处理。
表1 极化分解特征
Tab.1 Polarimetric decomposition features
| 分解方法 | 极化参数 | 维数 |
|---|---|---|
| Pauli | Pauli_a,Pauli_b,Pauli_c | 3 |
| Krogager | Krogager_KS,Krogager_KD,Krogager_KH | 3 |
| Huynen | Huynen_T11,Huynen_T22,Huynen_T33 | 3 |
| Bames | Bames_T11,Bames_T22,Bames_T33 | 3 |
| Yamaguchi | Yamaguchi_Vol ,Yamaguchi_Odd Yamaguchi_Dbl ,Yamaguchi_Hlx | 4 |
| Cloude | Cloude_T11,Cloude_T22,Cloude_T33 | 3 |
| Freeman | Freeman_Vol,Freeman_Odd,Freeman_Dbl | 3 |
| Holm | Holm_T11,Holm_T22,Holm_T33 | 3 |
2 极化SAR图像分类
2.1 基于BVSB准则的主动学习
主动学习中最大的难点是如何在未标记样本中选择对分类器价值最大的样本点。文献[10]提出按照BVSB准则衡量样本的不确定性,将不确定性大的样本视为价值大的样本。该准则可表述为
式中: p(yBest|xi)和p(ySecond|xi)为样本xi的最优类别概率和次优类别概率; U为未标记样本。
由式(1)可知,BVSB准则仅仅考虑分类结果中可能性最大的2个,是一种贪婪近似准则; 由于忽略了其他可能性较低类别的概率,因而能更直接地表达样本的不确定性。
2.2 基于自动编码器的深层特征提取
自动编码器[13]是一种典型的深度学习结构,可在非监督模式下进行特征提取。内在结构为一个3层的神经网络(分别为输入层、隐含层和输出层),且输入与输出的节点数相等。其特征提取的过程可以看作是根据数据本身在非监督模式下训练一个神经网络,使得重构的输出特征尽可能与输入特征一致。
利用自动编码器能提取出更具可分性和不变性的深层特征,然后可使用各种分类器进行分类。当顶层分类器为softmax分类器时,可以随着训练分类器而微调整个深度神经网络参数,从而取得更好的分类效果[14]。因此,本文通过一个自动编码器与一个softmax分类器构成整个深度神经网络(图1),用以对数据进行分类。
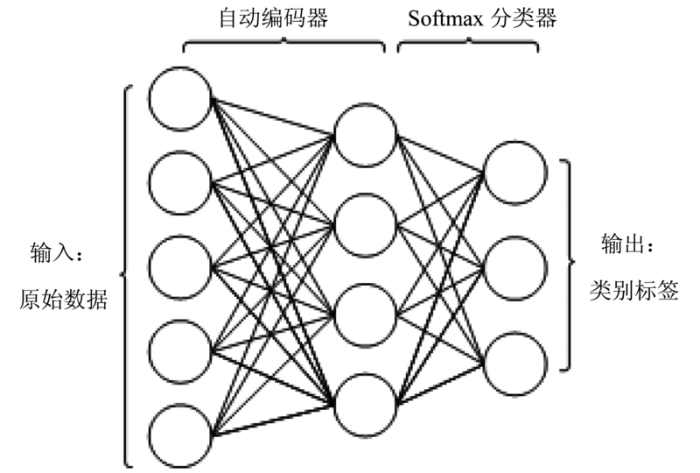
图1 基于自动编码器与softmax的分类示意图
Fig.1 Sketch map of classification based on auto-encoder and softmax
2.3 基于主动深度学习的极化SAR图像分类
基于主动学习与深度学习的极化SAR图像分类具体步骤(图2)如下:
1)对极化SAR图像进行滤波处理,并根据第2.2节所述方法组成特征向量。
2)将特征向量输入至自动编码器中提取深层特征。
3)从图像中随机选取大量未标记样本U和人工标记少量样本L。
4)利用L训练softmax分类器,并微调整个网络。
5)计算U中每个样本的各类别后验概率,并得到BVSB准则中的概率差值。
6)从U中选取N个概率差值最小的样本S进行人工标注。
7)将S加入标记样L中并从U中剔除,即L=L ∪ S,U=U\S。
8)依据新的L和U重复步骤4)―7),直至前后2次精度之差或循环次数达到阈值时,结束循环。
9)用最终训练的softmax分类器对整景图像进行分类,得到分类专题图。
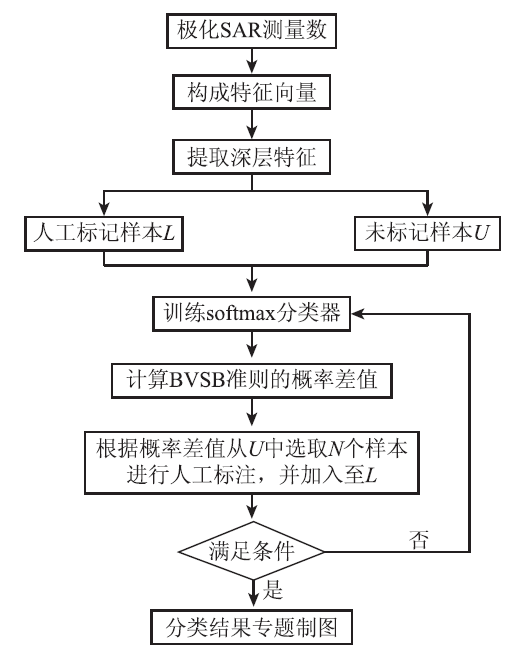
图2 基于主动深度学习的极化SAR图像分类流程图
Fig.2 Flowchart of polarimetric SAR image cassification based on active deep learning
3 实验结果与分析
3.1 试验数据
为验证本文算法的有效性,选取2组国际通用的极化SAR数据进行验证,真实地物参考图根据文献[9]所示,以人工标注方式获取。试验以整体精度作为评价指标,且整体精度均为10次试验结果的平均值。其中: 基于SVM的分类方法,选取径向基作为核函数,涉及到的参数C和σ的值在0.001~1 000之间进行网格法搜索获得; 基于自动编码器与softmax的分类方法(为便于表述,本文简称为Deep方法),涉及到的参数主要有自动编码器的隐含层节点数为25,衰减参数为0.003,稀疏性惩罚因子为3,稀疏性参数为0.1。
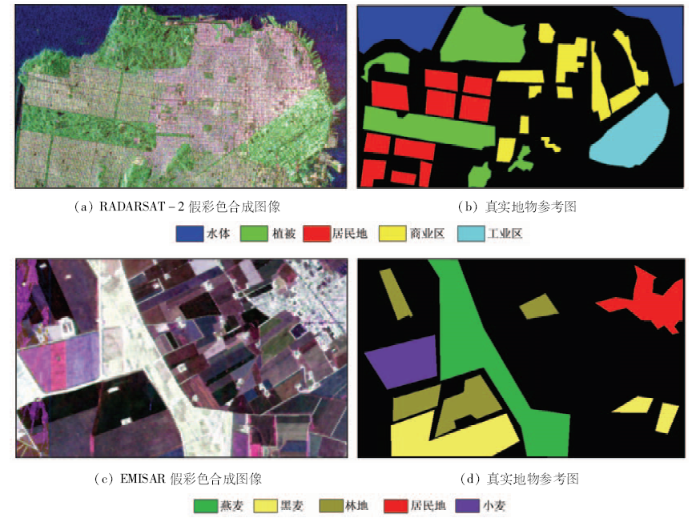
数据1: RADARSAT-2 全极化SAR(以下简称RADARSAT-2)数据,为2008年4月覆盖的美国旧金山部分区域,实验数据大小为600像素×1 200像素,空间分辨率为8 m,地物类别主要为水体、植被、居民地、商业区和工业区共5类(图3(a)―(b))。
数据2: EMISAR Foulum全极化SAR(以下简称EMISAR)数据,为1998年4月17日覆盖的丹麦Foulum区域,实验数据大小为480像素×800像素,空间分辨率为5 m,地物类别主要为燕麦、黑麦、林地、居民区和小麦共5类(图3(c)―(d))。
3.2 试验分析
为减少相干斑噪声的影响,首先对2组原始数据进行滤波处理(本实验采用Refined Lee滤波,窗口大小为 5×5); 然后根据第2节所述方法组成特征向量,以真实地物参考图标注的点作为本实验的未标记样本U和测试样本T。为分析样本数目对分类结果的影响,从2组试验数据中,每类别随机选取5,10,15,20,25,30,35和40个样本分别进行SVM和Deep分类,分类精度见表2。表中所列的为总体精度(overoll accuracy,OA)。
表2 随机选取不同数目样本的SVM和Deep分类精度
Tab.2 Classification accuracy for SVM and Deep based methods of different scale samples random selected(%)
| 每类样本数目 | RADARSAT-2 | EMISAR | ||
|---|---|---|---|---|
| SVM | Deep | SVM | Deep | |
| 5 | 66.58 | 69.93 | 78.29 | 82.14 |
| 10 | 72.31 | 75.39 | 81.23 | 86.23 |
| 15 | 78.20 | 80.27 | 84.48 | 89.39 |
| 20 | 80.93 | 81.15 | 87.30 | 90.10 |
| 25 | 81.19 | 82.23 | 88.64 | 90.61 |
| 30 | 81.94 | 82.90 | 89.72 | 90.94 |
| 35 | 82.18 | 83.22 | 90.46 | 91.82 |
| 40 | 82.34 | 83.33 | 90.95 | 91.90 |
从表2可以看出,SVM和Deep分类精度均随着样本数目的增加而提高; 在样本数目相同的情况下,Deep分类精度比SVM分类精度更高; 每类样本数目为5时,精度均大于60%,能保证 BVSB准则的有效性。所以主动选择样本过程为起初每类选择5个样本点,之后每次迭代选择5个样本进行人工标记并加入至训练样本; 为保持分类精度与计算量之间的平衡,选取前后2次精度之差的阈值为0.1%及迭代次数为15次。基于主动学习的SVM和Deep分类精度见图4(为便于表述,将主动选择样本的SVM和Deep方法分别称为AL-SVM与AL-Deep,随机选取样本的SVM和Deep方法分别称为RS-SVM与RS-Deep)。
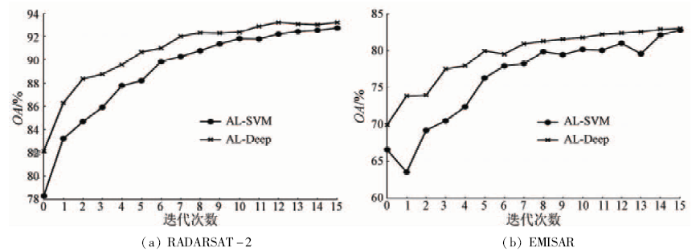
图4 基于主动学习的SVM和Deep分类精度
Fig.4 Classification accuracy for SVM and Deep based on active learning
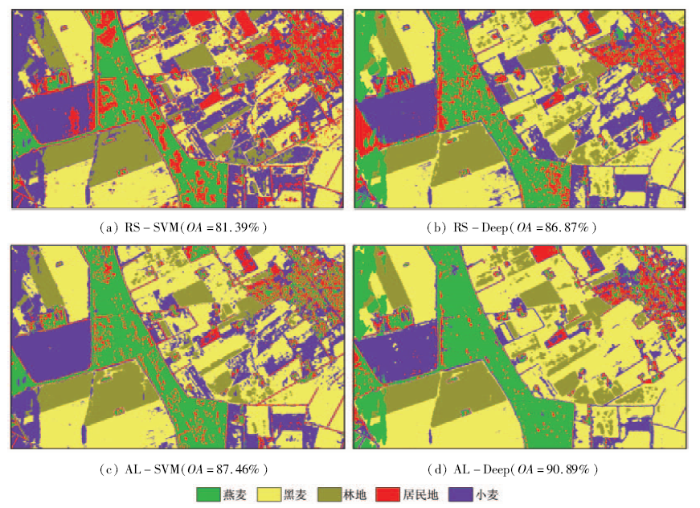
从图4中可以看出,随着逐次迭代的进行,Al-SVM与AL-Deep分类精度逐渐提高,且AL-Deep在每次迭代过程中的分类精度均高于AL-SVM; 在迭代次数为5(即人工标记50个样本)时,AL-Deep分类效果与随机选取100个样本(每类20个样本)时的分类效果相似; 迭代次数为15(即人工标记100个样本)时,AL-Deep分类效果与随机选取200个样本(每类40个样本)相似或者更好。在迭代次数为5时,RADARSAT-2数据的AL-Deep分类精度已经达到80%,比随机选取每类10个样本(5类,共50个样本)的RS-Deep分类精度高约5%,比RS-SVM分类精度高约8%; EMISAR数据的AL-Deep分类精度达到90%以上,比随机选取每类10个样本(5类,共50个样本)RS-Deep分类精度高约5%,比RS-SVM分类精度高约10%。后续迭代时,分类精度提升相对较小,但计算量却大大增加,因此试验的定性分析选择第5次迭代(即人工标记50个样本)的AL-Deep,AL-SVM,RS-Deep和RS-SVM这4种方法进行。图5和图6分别示出 RADARSAT-2和EMISAR数据不同方法分类结果。
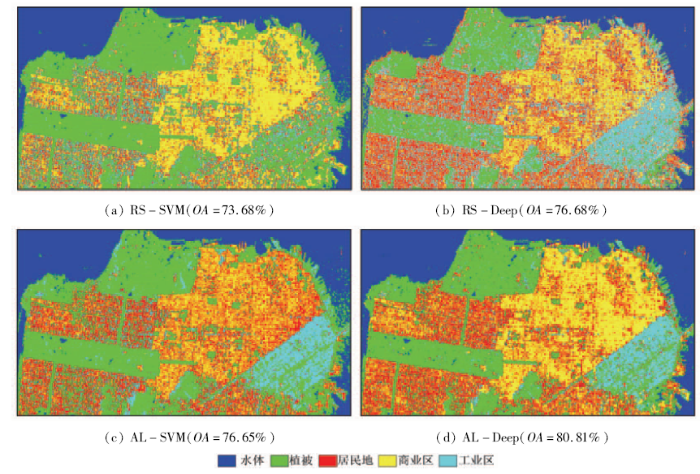
图5 RADARSAT-2数据不同方法分类结果图
Fig.5 Classification results comparison of different methods for RADARSAT-2 data
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
图6 EMISAR数据不同方法分类结果图
Fig.6 Classification results comparison of different methods for EMISAR data
从图5中可以看出,Deep方法相对浅层学习结构模型的SVM方法能获得更高的分类精度,RS-SVM中的工业区被错分成植被,而RS-Deep中的工业区能够得到较好识别; 在相同数目样本情况下,通过主动学习获得更有价值的样本,能够改善分类结果,AL-SVM相对RS-SVM能更好地判别工业区和居民地,但是商业区错分较为严重; 本文方法AL-Deep能较好地识别各类地物且分类精度最高。
从图6中可以看出,RS-SVM方法燕麦与居民地之间混淆较为严重,大部分的黑麦被错分成了小麦,而RS-Deep和AL-SVM能较好地改善上述错误,整体精度有一定提升。本文方法的AL-Deep分类效果最好,燕麦和黑麦都被很好地识别,且精度达到90%以上,可满足分类需求。
4 结论
本文针对极化SAR图像分类,提出了一种基于主动深度学习的极化SAR图像分类方法。实验表明,本文方法具有以下优点:
1)能在更少人工标记的样本下获得较好分类效果。
2)通过利用自动编码器与softmax分类器构成的深度神经网络能取得比浅层结构算法更高的分类精度。
3)将主动学习与深度学习相结合,能选择对分类器价值更大的样本进行人工标记,降低分类成本。
4)下一步的研究将聚焦在提取更加有效的特征和提高算法效率上。
(责任编辑: 李 瑜)
The authors have declared that no competing interests exist.
参考文献
| [1] |
Monthly short-term detection of land development using RADARSAT-2 polarimetric SAR imagery [J]. |
| [2] |
Unsupervised polarimetric SAR image segmentation and classification using region growing with edge penalty [J]. |
| [3] |
一种改进的全极化SAR图像MCSM-Wishart非监督分类方法 [J].An improved unsupervised classification scheme for polarimetric SAR image with MCSM-Wishart [J]. |
| [4] |
Ensemble learning with multiple classifiers and polarimetric features for polarized SAR image classification [J]. |
| [5] |
Land cover classification from polarimetric SAR data based on image segmentation and decision trees [J]. |
| [6] |
Semi-supervised learning for ill-posed polarimetric SAR classification [J]. |
| [7] |
Large polarimetric SAR data semi-supervised classification with spatial-anchor graph [J]. |
| [8] |
基于主动学习和半监督学习的多类图像分类 [J].Multi-class image classification with active learning and semi-supervised learning [J]. |
| [9] |
Active extreme learning machines for quad-polarimetric SAR imagery classification [J]. |
| [10] |
Multi-class active learning for image classification [C]// |
| [11] |
Learning deep architectures for AI [J]. |
| [12] |
A review of target decomposition theorems in radar polarimetry [J]. |
| [13] |
Learning representations by back-propagating errors [J]. |
| [14] |
Deep learning-based classification of hyperspectral data [J]. |

/
| 〈 |
|
〉 |