0 引言
基于高分辨率遥感影像的建筑物提取对地图制作、城市乡村规划、违建监测、数字城市建立、人口估计等应用具有重要意义,随着越来越多的高分辨遥感卫星投入使用,在提高地物光谱特征,突出地物结构、纹理和细节等信息的同时,也因为卫星观测角度问题造成地物遮挡,尺度的增大带来了严重的异物同谱现象,以及影像噪声增加等问题,限制了遥感影像建筑物自动提取精度。
传统方法主要是基于影像的光谱和空间特征信息,通过图像分割和特征提取技术,如尺度不变特征变换(scale-invariant feature transform,SIFT)、方向梯度直方图(histogram of oriented gradient,HOG)、面向对象[1 ,2 ] 等,获得遥感影像中的特征或分割对象,再选取支持向量机(support vector machine,SVM)、决策树、随机森林、条件随机场等分类器进行类别划分[3 ,4 ] 。然而,基于光谱和空间特征信息的分类方法在处理背景复杂、地物繁多的影像时都显得不足,其中最大缺陷是泛化能力较差,即训练后的模型或规则难以适用不同地区、不同数据源的遥感影像。
2006年Hinton等[5 ] 提出了深度学习的理论,深度学习是一种通过构建神经网络来模拟学习和人脑思维方式的自主特征学习方法,通过非线性表达来获取数据中的高级抽象特征,并构建数学模型以提高分类精度和检测准确率。近年来各种深度学习网络,如卷积神经网络(convolutional neural network,CNN)[6 ] 、递归神经网络(recurrent neural network,RNN)[7 ] 完成了各种高性能的计算机视觉任务,如图像分类[8 ] 、自然语言处理[9 ] 、语音识别[10 ] 等。
由于CNN在图像分类方面取得了较好的效果,许多学者基于CNN发展了遥感影像语义分割算法。2015年,从CNN发展而来的全卷积神经网络(fully convolutional networks,FCN)[11 ] 语义分割方法,采用全卷积层代替传统CNN中的全连接层,可以直接获得像素级别的分类结果,是第一个真正的端到端的像素分类模型[12 ,13 ] ,目前已经有多种语义分割网络,如Segnet[14 ] ,U-net[15 ] ,PSPNet[16 ] 和DeepLab[17 ] 等,这些语义分割网络的提出为遥感影像建筑物自动提取提供了可能性。但是将FCN应用到遥感影像建筑物提取时,需要通过逐像素标记类别构建样本数据集,这也阻碍了FCN在遥感影像分类中的深入应用。
目前,国际上已经有少量开源的遥感影像建筑物样本数据集,如ISPRS的Vaihingen和Potsdam数据集( http: //www2.isprs.org/commissions/comm3/wg4/semantic-labeling.html )、Massachusetts数据集[18 ] 、Inria数据集[19 ] 、WHU数据集[20 ] 等,以上数据集主要是以航空影像为主,仅WHU数据集包含一部分卫星影像,但在一些重大项目中,如第三次全国国土调查、地理国情监测、全球地理信息资源建设等,仍需要构建大量的样本以满足重大项目建筑物自动提取的需求。
针对建筑物自动提取的难题,本文提出基于高分卫星遥感影像和地理国情监测矢量数据快速构建大规模的建筑物样本数据集,并采用一种注意力增强的全卷积神经网络,实现从卫星遥感影像中自动提取建筑物。
1 研究方法
1.1 基于注意力增强的特征金字塔建筑物提取网络
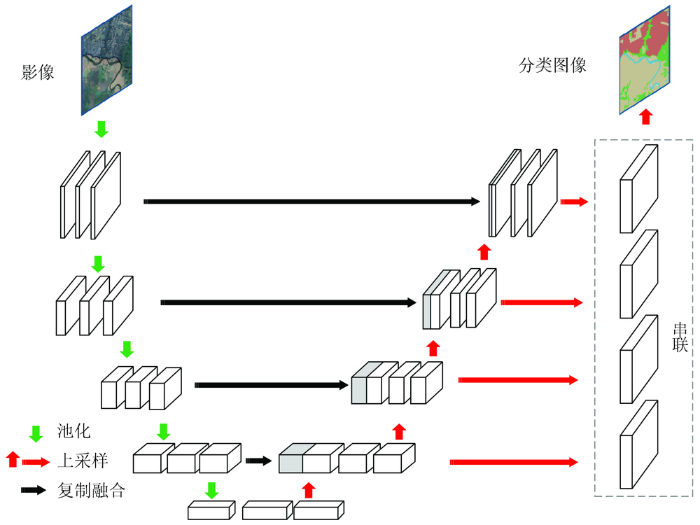
针对遥感影像的多尺度问题,传统的方式是通过多尺度输入图像的方式来构建多尺度特征,特征金字塔网络(feature pyrimad network,FPN)[21 ] 借鉴了这一思想,但是在网络内部构建特征金字塔,实现多尺度特征融合,将包含更多语义信息的高层网络特征与包含更多几何细节信息的浅层网络特征串联融合。本文针对高分卫星遥感影像的建筑物自动提取,采用一种基于FPN的语义分割网络FPN-SENet,提升遥感影像建筑物分类精度,FPN-SENet主体网络框架如图1 所示,而在特征图提取部分,采用了SE (squeeze-and-excitation) 模块[22 ] ,如图2 所示。
图1
图1
FPN-SENet网络框架
Fig.1
Structure diagram of FPN-SENet
图2
图2
SE模块单元
Fig.2
Squeeze-and-excitation block
一个SE模块单元中,F tr 为传统的卷积结构,X 和U 分别为输入(H' ×W' × C' )和输出(H×W× C),U =[u 1 , u 2 , …, uc ],公式为:
(1) u c = v c × X = ∑ s = 1 C ' v c s · x s
式中: xs 为第c个通道的输入特征图; uc 为第c个通道的输出特征图; vc 为第c个卷积核的参数; C'为输入通道数量。
增加SE 模块后,首先对卷积层输出的特征图U ,采用全局平均池化(global average pooling ,GPA )进行压缩操作Fsq
(2) z c = F sq ( u c ) = 1 H × W ∑ i = 1 H ∑ j = 1 W u c i , j
然后对压缩后的z,使用2个全连接层进行激励操作Fex / r个通道来降低计算量,其中r是压缩的比例,后面跟了ReLU 函数,第二个全连接再恢复回C个通道,后面跟接Sigmoid 函数,公式为:
$s =F ex (z ,W )=σ (g (z ,W )=σ (W 2 δ (W 1 z )) $ (3)
式中: δ为 ReLU 函数; σ为 Sigmoid 函数; W 1 为C /r ×C 的降维矩阵; W 2 为C ×C /r 的升维矩阵。
通过压缩和激励操作,学习到各个通道间的关系,得到不同通道的权重,然后将SE模块计算出的各通道权重值分别与原特征图对应通道的二维矩阵相乘,得出的结果输出,公式为:
(4) X ~ c = F scale ( u c , s c ) = s c · u c
SE 模块为网络模型提供了一种通道域注意力机制,让模型更加关注信息量较大的特征图,而抑制那些不重要特征图。
1.2 交叉熵与dice 系数结合的损失函数
交叉熵损失函数是遥感影像分类任务中最常用的一种损失函数(L_bce ),可从预测值(pr)与真值(gt)之间的交叉熵计算得到,公式为:
本文引入dice 系数,将交叉熵与dice 系数之和作为新的损失函数,对FPN -SENet 网络模型进行训练,定义为:
(6) L_bce_dice =L_bce +L_dice
(7) L_dice =1-F
(8) F = 1 + β 2 precision · recall β 2 · precisiom + recall
式中: precision为准确率; recall为召回率; β为准确率和召回率之间的平衡系数,本文β取值为1,表示准确率和召回率同等重要。
1.3 基于窗函数平滑预测的分类后处理方法
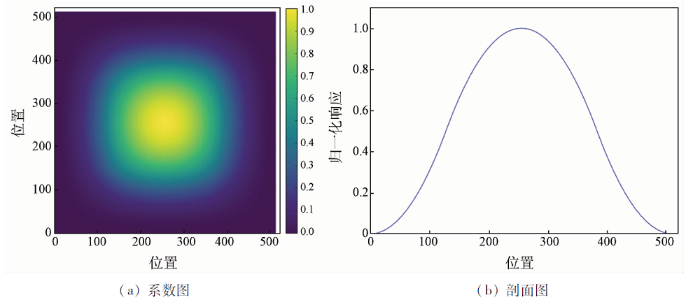
由于受计算机硬件设备的限制,采用FCN 对遥感影像进行训练和预测时,需将遥感影像和样本图像裁剪成较小尺寸的图像进行处理,但是在分块进行遥感影像预测分类时,2块之间的边界附近可能存在明显拼接缝的现象,常见的方法是通过重叠切割减少分块拼接痕迹[23 ] ,提升分类效果,而本文引入一种二次样条窗函数,进行平滑拼接预测分类,该窗函数由一维二次样条窗函数扩展而来,公式为:
(9) w ( n ) = w 1 n + w 2 n w n ¯ , 1 ≤ n ≤ M ,
(10) w 1 (n )=2t (n )2 ,1≤n ≤0.25M ,0.75M ≤n ≤M
(11) w 2 (n )=1-2(t (n )-1)2 ,0.25M <n <0.75M
(12) t ( n ) = 0 . 5 1 - cos cos 2 π n M + 1 , 1 ≤ n ≤ M ,
式中:$\overline{w(n)}$为w(n)的平均值; M为窗口大小; t(n)为三角窗函数。
该窗函数的一维剖面和二维形状如图3 所示,将该窗函数的权重系数与模型预测分类的二维图斑矩阵相乘,可以突出分块图斑中心区域,而抑制分块图斑边缘区域,并以图像块边长的1/ 2作为滑动步长,在整幅待预测影像上进行滑动预测,获得平滑预测的分类图斑。
图3
图3
二次样条窗函数
Fig.3
Spline window function
2 基于多源卫星影像和矢量成果数据的建筑物样本集制作
深度学习模型训练需要大量的样本库,本文制作了大规模的逐像素标注样本数据集: 首先,收集整理地理国情监测成果数据中的地表覆盖矢量数据和对应的高分辨率卫星遥感影像,该地表覆盖数据是基于高分辨率遥感影像进行人工目视解译,并结合一定的指标和规则制作完成,其主要内容和采集指标参考《地理国情普查内容与指标》[24 ] ; 然后,选取地表覆盖矢量数据中房屋建筑较多的地区作为样本制作区域,同时去除卫星影像中有云覆盖的区域,裁剪出房屋矢量数据和对应区域的卫星影像,再将房屋矢量数据转化为栅格格式,形成与卫星影像逐像素对应的标签数据,完成建筑物的样本标注; 最终,选取了200景卫星遥感影像完成多源卫星遥感建筑物样本数据制作,其中高分二号影像约占1/2,北京二号和高景一号影像各占1/4。
本文将制作的建筑物样本数据集简称为SCRS Buildings Dataset,样本影像的覆盖范围约1万km2 ,总像素约10亿个,其中,建筑物占比为8%。初始的样本数据尺寸大小并不一致,在模型训练之前,可以根据神经网络模型的输入尺寸将初始样本裁剪成固定大小的小样本,若按照512像素×512像素裁剪,可以制作约50 000个小样本。由于样本制作采用了融合后的卫星遥感影像,每个样本影像包含4个波段,样本影像的空间分辨率为0.5~0.8 m,样本示例如图4 所示,分别是3种卫星的真彩色影像、假彩色影像、标签数据。由于样本标签从地理国情监测成果数据而来,许多建筑物标签有图斑综合现象,即房屋建筑区内面积小于1 600 m2 的绿化林地、绿化草地、硬化平地等综合成建筑物类别,如图5 所示。
图4
图4
卫星遥感影像建筑物样本
Fig.4
Examples of dataset with satellite image and label
图5
图5
图斑综合样例
Fig.5
Examples of path generalization
3 试验与分析
试验基于TensorFlow和Keras深度学习开源框架,采用python语言编程实现,试验操作系统为Ubuntu 16.04,GPU显卡选用NVIDIA GTX1080TI。模型训练时,将训练样本分为训练集和验证集,验证集占总样本的1/3,Batch_size设置为6,样本图像输入尺寸为512像素×512像素,利用Adam算法进行网络优化,学习率设置为0.000 1。
精度评估采用基于误差矩阵为核心的分类精度评价方法[25 ] ,评价指标包括总体精度(OA)和Kappa系数、F1分值和IoU(交并比)[26 ] ,公式为:
(13) F 1 = 2 precision · recall precisiom + recall
(14) precision = TP TP + FP , recall = TP TP + FN
(15) IoU = TP TP + FP + FN
式中: TP 为属于类别C 被正确分到类别C 的样本; FN 为不属于类别C 的样本被错误分类到类别C ; FP 为不属于类别C 的样本被正确分类到了类别C 的其他类。F 1和IoU 取值为0~1之间,值越大,分类精度越好。
3.1 与WHU卫星数据集比较
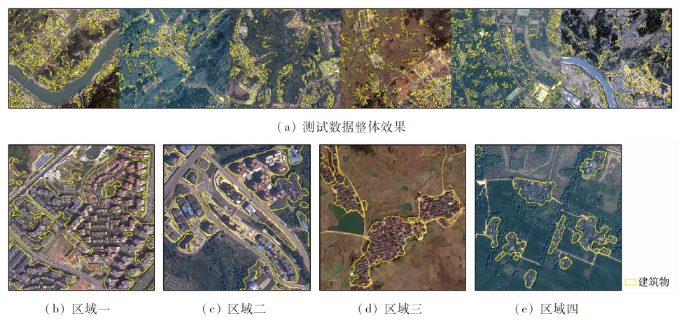
为了分析SCRS数据集的性能,采用FPN-SENet分别在WHU数据集和SCRS数据集上进行训练、测试: ①WHU 卫星数据II(Satellite dataset Ⅱ (East Asia)),包含2幅训练数据和1幅测试数据,将训练数据裁切成512像素×512像素大小,2/3为训练集,1/3为验证集,利用训练后的模型对测试数据进行分类和精度评估; ②SCRS数据集,将训练数据裁切成512像素×512像素大小的图像,2/3为训练集,1/3为验证集,利用训练后的模型对测试数据进行分类和精度评估。其中,SCRS的测试数据,分别在不同区域选取高分二号2景、北京二号2景、高景一号2景影像,从每一景中裁剪出高宽为5 000像素×5 500像素建筑物丰富的影像,拼接成一幅高宽为5 000像素×33 000像素的测试数据,如图6 所示。
图6
图6
建筑物测试数据
Fig.6
Test images and ground-truth of building
表1 给出了FPN-SENet分别在WHU数据集和SCRS数据集上的测试精度,表明SCRS建筑物提取的精度接近目前国际上精度最高的开源卫星影像建筑物数据集(WHU数据集),但是WHU数据集的影像只有3个波段,而SCRS数据集的影像有4个波段,可以选择用真彩色影像或假彩色影像,从表 1 可以看出,假彩色影像的F 1值和IoU 比真彩色影像高2.9和4.0百分点。
3.2 常用FCN模型比较
目前遥感影像的像素级分类几乎都是基于FCN,于是本文以SCRS数据集中的真彩色影像为输入,对目前较为流行的几种FCN模型进行评估,表 2 给出了FCN-8s,Segnet,U-net,PSPNet和本文方法(FPN-SENet)的分类精度,测试数据仍选择图5 的影像。从测试结果来看,FPN-SENet取得了最优的结果,相对于表现次之的U-net,本文方法的F 1值和IoU 高出2.4和3.1百分点,比PSPNet的结果高出5.7和7.4百分点。从文献中得知,传统方法的准确率难以超过50%[20 ] ,而表2 中语义分割模型的F1-score均超过了70%,说明深度学习方法在卫星影像建筑物提取中具有很好的应用前景。
3.3 不同损失函数的比较
为了提升FPN-SENet在SCRS数据集上提取建筑物的性能,本文尝试用多种损失函数对SCRS数据集进行训练和测试,表3 显示了不同损失函数模型在测试数据的精度,影像输入波段为假彩色3波段,L_bce模型的建筑物提取准确率最高,达到了84.7%,L_dice模型的召回率最高,达到了83.3%,而L_bce-dice能够在准确率和召回率之间取得平衡,保证提取精度最优,F1分值和IoU分别达到了81.7%和69.1%。
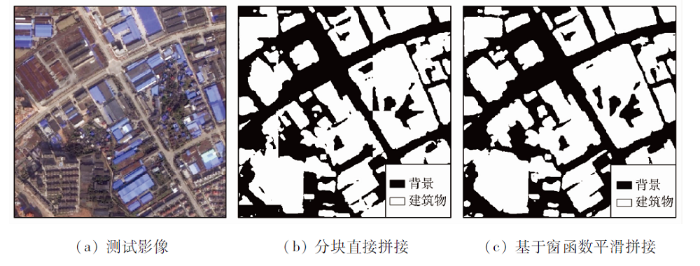
3.4 基于窗函数平滑拼接的效果
本文在整幅测试影像进行分类时,采用了平滑预测的后处理方式,图7 显示了基于窗函数平滑拼接的效果,可以看出,采用分块直接拼接时,图像块之间存在明显的拼接痕迹,分块边缘处的地物不连续; 而基于窗函数平滑拼接的结果中,地物在块与块之间过渡更自然,图斑连续性更好,边界更整齐。采用精度最优的模型,对测试影像的自动提取效果如图8 所示,可以看出本文方法能够很好地从高分辨率卫星影像中提取建筑物。
图7
图7
平滑预测的效果
Fig.7
Results with smooth prediction
图8
图8
测试数据提取效果
Fig.8
The classified result of test images
4 结论
本文基于国产高分卫星影像和地理国情监测成果数据,制作卫星影像建筑物数据集,该方法能够快速制作大规模的像素级标注数据集,且采用一种基于注意力增强的特征金字塔建筑物提取网络对数据集进行测试,主要结论如下:
1)本文制作的卫星影像数据集的建筑物提取精度接近国际先进的开源卫星影像建筑物数据集,且数据集影像为4波段。
2)本文提出的网络模型,在建筑物提取上的精度优于其他常用的FCN网络。
3)通过改进损失函数、基于窗函数平滑拼接的技术手段,能够进一步提高建筑物提取精度和效果。本文结合国家重大项目需要提出的卫星影像建筑物自动提取方法,能够为深度学习方法在遥感解译领域的深入应用提供借鉴意义。未来将继续研究深度学习方法针对不同数据源、不同时相卫星影像的适用性,并制作更多地物类型、更大规模的遥感影像样本数据,推广深度学习方法在遥感自动解译领域的应用。
参考文献
View Option
[2]
Yang Y Newsam S . Geographic image retrieval using local invariant features
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2013 , 51 (2 ):818 -832 .
DOI:10.1109/TGRS.2012.2205158
URL
[本文引用: 1]
[3]
Li E Femiani J Xu S B , et al . Robust rooftop extraction from visible band images using higher order CRF
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2015 , 53 (8 ):4483 -4495 .
DOI:10.1109/TGRS.2015.2400462
URL
[本文引用: 1]
[4]
Melgani F Bruzzone L . Classification of hyperspectral remote sensing images with support vector machines
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2004 , 42 (8 ):1778 -1790 .
DOI:10.1109/TGRS.2004.831865
URL
[本文引用: 1]
[6]
Lecun Y Bottou L Bengio Y , et al . Gradient-based learning applied to document recognition
[C]. Proceedings of the IEEE , 1998 , 86 (11 ):2278 -2324 .
[本文引用: 1]
[7]
Graves A Liwicki M Fernandez S , et al . A novel connectionist system for unconstrained handwriting recognition
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2009 , 31 :855 -868 .
DOI:10.1109/TPAMI.2008.137
PMID:19299860
[本文引用: 1]
Recognizing lines of unconstrained handwritten text is a challenging task. The difficulty of segmenting cursive or overlapping characters, combined with the need to exploit surrounding context, has led to low recognition rates for even the best current recognizers. Most recent progress in the field has been made either through improved preprocessing or through advances in language modeling. Relatively little work has been done on the basic recognition algorithms. Indeed, most systems rely on the same hidden Markov models that have been used for decades in speech and handwriting recognition, despite their well-known shortcomings. This paper proposes an alternative approach based on a novel type of recurrent neural network, specifically designed for sequence labeling tasks where the data is hard to segment and contains long-range bidirectional interdependencies. In experiments on two large unconstrained handwriting databases, our approach achieves word recognition accuracies of 79.7 percent on online data and 74.1 percent on offline data, significantly outperforming a state-of-the-art HMM-based system. In addition, we demonstrate the network's robustness to lexicon size, measure the individual influence of its hidden layers, and analyze its use of context. Last, we provide an in-depth discussion of the differences between the network and HMMs, suggesting reasons for the network's superior performance.
[8]
Krizhevsky A Sutskever I Hinton G E . Imagenet classification with deep convolutional neural networks
[C]// International Conference on Neural Information Processing Systems , 2012 .
[本文引用: 1]
[9]
Mikolov T Deoras A Kombrink S , et al . Empirical evaluation and combination of advanced language modeling techniques
[C]// Florence:Conference of the International Speech Communication Association , 2011 .
[本文引用: 1]
[10]
Dahl G E Yu D Deng L , et al . Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition
[J]. IEEE Transactions on Audio, Speech and Language Processing , 2012 , 20 (1 ):30 -42 .
DOI:10.1109/TASL.2011.2134090
URL
[本文引用: 1]
[11]
Long J Shelhamer E Darrell T . Fully convolutional networks for semantic segmentation
[C]// IEEE Conference on Computer Vision and Pattern Recognition,Boston,MA,USA , 2015 .
[本文引用: 1]
[12]
Wu G M Shao X W Guo Z L , et al . Automatic building segmentation of aerial imagery using multi-constraint fully convolutional networks
[J]. Remote Sensing , 2018 , 10 (3 ):407 -424 .
DOI:10.3390/rs10030407
URL
[本文引用: 1]
[13]
Zhang W K Huang H Schmitz M , et al . Effective fusion of multi-modal remote sensing data in a fully convolutional network for semantic labeling
[J]. Remote Sensing , 2018 , 10 (52 ):1 -14 .
DOI:10.3390/rs10010001
URL
[本文引用: 1]
[14]
Badrinarayanan V Kendall A Cipolla R . Segnet:A deep convolutional encoder-decoder architecture for image segmentation
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2015 , 39 (12 ):2481 -2495 .
DOI:10.1109/TPAMI.34
URL
[本文引用: 1]
[15]
Ronneberger O Fischer P Brox T . U-Net:Convolutional networks for biomedical image segmentation
[C]// Medical Image Computing and Computer-Assisted Intervention , 2015 .
[本文引用: 1]
[16]
Zhao H S Shi J P Qi X J , et al . Pyramid scene parsing network
[C]. IEEE Conference on Computer Vision and Pattern Recognition , 2017 .
[本文引用: 1]
[17]
Chen L C Papandreou G Kokkinos I , et al . Deeplab:Semantic image segmentation with deep convolutional nets,atrous convolution,and fully connected CRFS
[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence , 2018 , 40 :834 -848 .
[本文引用: 1]
[18]
Mnih V . Machine learning for aerial image labeling
[M]. Toronto:Toronto University of Toronto , 2013 .
[本文引用: 1]
[19]
Maggiori E Tarabalka Y Charpiat G , et al . Can semantic labeling methods generalize to any city? The inria aerial image labeling benchmark
[C]// IEEE International Geoscience and Remote Sensing Symposium(IGARSS),Fort Worth,United States , 2017 .
[本文引用: 1]
[20]
季顺平 , 魏世清 . 遥感影像建筑物提取的卷积神经元网络与开源数据集方法
[J]. 测绘学报 , 2019 , 48 (4 ):448 -459 .
[本文引用: 2]
Ji S P Wei S Q . Building extraction via convolutional neural networks from an open remote sensing building dataset
[J]. Acta Geodaetica et Cartographica Sinica , 2019 , 48 (4 ):448 -459 .
[本文引用: 2]
[21]
Lin S Y Doll'ar P Girshick R , et al . Feature pyramid networks for object detection
[C]// IEEE Conference on Computer Vision and Pattern Recognition , 2017 .
[本文引用: 1]
[22]
Hu J Shen L Sun G . Squeeze-and-excitation networks
[C]// IEEE Conference on Computer Vision and Pattern Recognition , 2018 .
[本文引用: 1]
[23]
杨建宇 , 周振旭 , 杜贞容 , 等 . 基于segnet语义模型的高分辨率遥感影像农村建设用地提取
[J]. 农业工程学报 , 2019 , 35 (5 ):251 -258 .
[本文引用: 1]
Yang J Y Zhou Z X Du Z R , et al . Rural construction land extraction from high spatial resolution remote sensing image based on segnet semantic segmentation model
[J]. Transactions of the Chinese Society of Agricultural Engineering , 2019 , 35 (5 ):251 -258 .
[本文引用: 1]
[24]
国务院第一次全国地理国情普查领导小组办公室 . 地理国情普查内容与指标 [M]. 北京 : 测绘出版社 , 2013 .
[本文引用: 1]
The First National Geographic National Conditions Census Leading Group Office of State Council . Geographic national conditions census content and indicator [M]. Beijing : Surveying and Mapping Press , 2013 .
[本文引用: 1]
[26]
Maggiori E Tarabalka Y Charpiat G , et al . Convolutional neural networks for large-scale remote-sensing image classification
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2017 , 55 :645 -657 .
DOI:10.1109/TGRS.2016.2612821
URL
[本文引用: 1]
Object based image analysis for remote sensing
1
2010
... 传统方法主要是基于影像的光谱和空间特征信息,通过图像分割和特征提取技术,如尺度不变特征变换(scale-invariant feature transform,SIFT)、方向梯度直方图(histogram of oriented gradient,HOG)、面向对象[1 ,2 ] 等,获得遥感影像中的特征或分割对象,再选取支持向量机(support vector machine,SVM)、决策树、随机森林、条件随机场等分类器进行类别划分[3 ,4 ] .然而,基于光谱和空间特征信息的分类方法在处理背景复杂、地物繁多的影像时都显得不足,其中最大缺陷是泛化能力较差,即训练后的模型或规则难以适用不同地区、不同数据源的遥感影像. ...
Geographic image retrieval using local invariant features
1
2013
... 传统方法主要是基于影像的光谱和空间特征信息,通过图像分割和特征提取技术,如尺度不变特征变换(scale-invariant feature transform,SIFT)、方向梯度直方图(histogram of oriented gradient,HOG)、面向对象[1 ,2 ] 等,获得遥感影像中的特征或分割对象,再选取支持向量机(support vector machine,SVM)、决策树、随机森林、条件随机场等分类器进行类别划分[3 ,4 ] .然而,基于光谱和空间特征信息的分类方法在处理背景复杂、地物繁多的影像时都显得不足,其中最大缺陷是泛化能力较差,即训练后的模型或规则难以适用不同地区、不同数据源的遥感影像. ...
Robust rooftop extraction from visible band images using higher order CRF
1
2015
... 传统方法主要是基于影像的光谱和空间特征信息,通过图像分割和特征提取技术,如尺度不变特征变换(scale-invariant feature transform,SIFT)、方向梯度直方图(histogram of oriented gradient,HOG)、面向对象[1 ,2 ] 等,获得遥感影像中的特征或分割对象,再选取支持向量机(support vector machine,SVM)、决策树、随机森林、条件随机场等分类器进行类别划分[3 ,4 ] .然而,基于光谱和空间特征信息的分类方法在处理背景复杂、地物繁多的影像时都显得不足,其中最大缺陷是泛化能力较差,即训练后的模型或规则难以适用不同地区、不同数据源的遥感影像. ...
Classification of hyperspectral remote sensing images with support vector machines
1
2004
... 传统方法主要是基于影像的光谱和空间特征信息,通过图像分割和特征提取技术,如尺度不变特征变换(scale-invariant feature transform,SIFT)、方向梯度直方图(histogram of oriented gradient,HOG)、面向对象[1 ,2 ] 等,获得遥感影像中的特征或分割对象,再选取支持向量机(support vector machine,SVM)、决策树、随机森林、条件随机场等分类器进行类别划分[3 ,4 ] .然而,基于光谱和空间特征信息的分类方法在处理背景复杂、地物繁多的影像时都显得不足,其中最大缺陷是泛化能力较差,即训练后的模型或规则难以适用不同地区、不同数据源的遥感影像. ...
A fast learning algorithm for deep belief nets
1
2006
... 2006年Hinton等[5 ] 提出了深度学习的理论,深度学习是一种通过构建神经网络来模拟学习和人脑思维方式的自主特征学习方法,通过非线性表达来获取数据中的高级抽象特征,并构建数学模型以提高分类精度和检测准确率.近年来各种深度学习网络,如卷积神经网络(convolutional neural network,CNN)[6 ] 、递归神经网络(recurrent neural network,RNN)[7 ] 完成了各种高性能的计算机视觉任务,如图像分类[8 ] 、自然语言处理[9 ] 、语音识别[10 ] 等. ...
Gradient-based learning applied to document recognition
1
1998
... 2006年Hinton等[5 ] 提出了深度学习的理论,深度学习是一种通过构建神经网络来模拟学习和人脑思维方式的自主特征学习方法,通过非线性表达来获取数据中的高级抽象特征,并构建数学模型以提高分类精度和检测准确率.近年来各种深度学习网络,如卷积神经网络(convolutional neural network,CNN)[6 ] 、递归神经网络(recurrent neural network,RNN)[7 ] 完成了各种高性能的计算机视觉任务,如图像分类[8 ] 、自然语言处理[9 ] 、语音识别[10 ] 等. ...
A novel connectionist system for unconstrained handwriting recognition
1
2009
... 2006年Hinton等[5 ] 提出了深度学习的理论,深度学习是一种通过构建神经网络来模拟学习和人脑思维方式的自主特征学习方法,通过非线性表达来获取数据中的高级抽象特征,并构建数学模型以提高分类精度和检测准确率.近年来各种深度学习网络,如卷积神经网络(convolutional neural network,CNN)[6 ] 、递归神经网络(recurrent neural network,RNN)[7 ] 完成了各种高性能的计算机视觉任务,如图像分类[8 ] 、自然语言处理[9 ] 、语音识别[10 ] 等. ...
Imagenet classification with deep convolutional neural networks
1
2012
... 2006年Hinton等[5 ] 提出了深度学习的理论,深度学习是一种通过构建神经网络来模拟学习和人脑思维方式的自主特征学习方法,通过非线性表达来获取数据中的高级抽象特征,并构建数学模型以提高分类精度和检测准确率.近年来各种深度学习网络,如卷积神经网络(convolutional neural network,CNN)[6 ] 、递归神经网络(recurrent neural network,RNN)[7 ] 完成了各种高性能的计算机视觉任务,如图像分类[8 ] 、自然语言处理[9 ] 、语音识别[10 ] 等. ...
Empirical evaluation and combination of advanced language modeling techniques
1
2011
... 2006年Hinton等[5 ] 提出了深度学习的理论,深度学习是一种通过构建神经网络来模拟学习和人脑思维方式的自主特征学习方法,通过非线性表达来获取数据中的高级抽象特征,并构建数学模型以提高分类精度和检测准确率.近年来各种深度学习网络,如卷积神经网络(convolutional neural network,CNN)[6 ] 、递归神经网络(recurrent neural network,RNN)[7 ] 完成了各种高性能的计算机视觉任务,如图像分类[8 ] 、自然语言处理[9 ] 、语音识别[10 ] 等. ...
Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition
1
2012
... 2006年Hinton等[5 ] 提出了深度学习的理论,深度学习是一种通过构建神经网络来模拟学习和人脑思维方式的自主特征学习方法,通过非线性表达来获取数据中的高级抽象特征,并构建数学模型以提高分类精度和检测准确率.近年来各种深度学习网络,如卷积神经网络(convolutional neural network,CNN)[6 ] 、递归神经网络(recurrent neural network,RNN)[7 ] 完成了各种高性能的计算机视觉任务,如图像分类[8 ] 、自然语言处理[9 ] 、语音识别[10 ] 等. ...
Fully convolutional networks for semantic segmentation
1
2015
... 由于CNN在图像分类方面取得了较好的效果,许多学者基于CNN发展了遥感影像语义分割算法.2015年,从CNN发展而来的全卷积神经网络(fully convolutional networks,FCN)[11 ] 语义分割方法,采用全卷积层代替传统CNN中的全连接层,可以直接获得像素级别的分类结果,是第一个真正的端到端的像素分类模型[12 ,13 ] ,目前已经有多种语义分割网络,如Segnet[14 ] ,U-net[15 ] ,PSPNet[16 ] 和DeepLab[17 ] 等,这些语义分割网络的提出为遥感影像建筑物自动提取提供了可能性.但是将FCN应用到遥感影像建筑物提取时,需要通过逐像素标记类别构建样本数据集,这也阻碍了FCN在遥感影像分类中的深入应用. ...
Automatic building segmentation of aerial imagery using multi-constraint fully convolutional networks
1
2018
... 由于CNN在图像分类方面取得了较好的效果,许多学者基于CNN发展了遥感影像语义分割算法.2015年,从CNN发展而来的全卷积神经网络(fully convolutional networks,FCN)[11 ] 语义分割方法,采用全卷积层代替传统CNN中的全连接层,可以直接获得像素级别的分类结果,是第一个真正的端到端的像素分类模型[12 ,13 ] ,目前已经有多种语义分割网络,如Segnet[14 ] ,U-net[15 ] ,PSPNet[16 ] 和DeepLab[17 ] 等,这些语义分割网络的提出为遥感影像建筑物自动提取提供了可能性.但是将FCN应用到遥感影像建筑物提取时,需要通过逐像素标记类别构建样本数据集,这也阻碍了FCN在遥感影像分类中的深入应用. ...
Effective fusion of multi-modal remote sensing data in a fully convolutional network for semantic labeling
1
2018
... 由于CNN在图像分类方面取得了较好的效果,许多学者基于CNN发展了遥感影像语义分割算法.2015年,从CNN发展而来的全卷积神经网络(fully convolutional networks,FCN)[11 ] 语义分割方法,采用全卷积层代替传统CNN中的全连接层,可以直接获得像素级别的分类结果,是第一个真正的端到端的像素分类模型[12 ,13 ] ,目前已经有多种语义分割网络,如Segnet[14 ] ,U-net[15 ] ,PSPNet[16 ] 和DeepLab[17 ] 等,这些语义分割网络的提出为遥感影像建筑物自动提取提供了可能性.但是将FCN应用到遥感影像建筑物提取时,需要通过逐像素标记类别构建样本数据集,这也阻碍了FCN在遥感影像分类中的深入应用. ...
Segnet:A deep convolutional encoder-decoder architecture for image segmentation
1
2015
... 由于CNN在图像分类方面取得了较好的效果,许多学者基于CNN发展了遥感影像语义分割算法.2015年,从CNN发展而来的全卷积神经网络(fully convolutional networks,FCN)[11 ] 语义分割方法,采用全卷积层代替传统CNN中的全连接层,可以直接获得像素级别的分类结果,是第一个真正的端到端的像素分类模型[12 ,13 ] ,目前已经有多种语义分割网络,如Segnet[14 ] ,U-net[15 ] ,PSPNet[16 ] 和DeepLab[17 ] 等,这些语义分割网络的提出为遥感影像建筑物自动提取提供了可能性.但是将FCN应用到遥感影像建筑物提取时,需要通过逐像素标记类别构建样本数据集,这也阻碍了FCN在遥感影像分类中的深入应用. ...
U-Net:Convolutional networks for biomedical image segmentation
1
2015
... 由于CNN在图像分类方面取得了较好的效果,许多学者基于CNN发展了遥感影像语义分割算法.2015年,从CNN发展而来的全卷积神经网络(fully convolutional networks,FCN)[11 ] 语义分割方法,采用全卷积层代替传统CNN中的全连接层,可以直接获得像素级别的分类结果,是第一个真正的端到端的像素分类模型[12 ,13 ] ,目前已经有多种语义分割网络,如Segnet[14 ] ,U-net[15 ] ,PSPNet[16 ] 和DeepLab[17 ] 等,这些语义分割网络的提出为遥感影像建筑物自动提取提供了可能性.但是将FCN应用到遥感影像建筑物提取时,需要通过逐像素标记类别构建样本数据集,这也阻碍了FCN在遥感影像分类中的深入应用. ...
Pyramid scene parsing network
1
2017
... 由于CNN在图像分类方面取得了较好的效果,许多学者基于CNN发展了遥感影像语义分割算法.2015年,从CNN发展而来的全卷积神经网络(fully convolutional networks,FCN)[11 ] 语义分割方法,采用全卷积层代替传统CNN中的全连接层,可以直接获得像素级别的分类结果,是第一个真正的端到端的像素分类模型[12 ,13 ] ,目前已经有多种语义分割网络,如Segnet[14 ] ,U-net[15 ] ,PSPNet[16 ] 和DeepLab[17 ] 等,这些语义分割网络的提出为遥感影像建筑物自动提取提供了可能性.但是将FCN应用到遥感影像建筑物提取时,需要通过逐像素标记类别构建样本数据集,这也阻碍了FCN在遥感影像分类中的深入应用. ...
Deeplab:Semantic image segmentation with deep convolutional nets,atrous convolution,and fully connected CRFS
1
2018
... 由于CNN在图像分类方面取得了较好的效果,许多学者基于CNN发展了遥感影像语义分割算法.2015年,从CNN发展而来的全卷积神经网络(fully convolutional networks,FCN)[11 ] 语义分割方法,采用全卷积层代替传统CNN中的全连接层,可以直接获得像素级别的分类结果,是第一个真正的端到端的像素分类模型[12 ,13 ] ,目前已经有多种语义分割网络,如Segnet[14 ] ,U-net[15 ] ,PSPNet[16 ] 和DeepLab[17 ] 等,这些语义分割网络的提出为遥感影像建筑物自动提取提供了可能性.但是将FCN应用到遥感影像建筑物提取时,需要通过逐像素标记类别构建样本数据集,这也阻碍了FCN在遥感影像分类中的深入应用. ...
Machine learning for aerial image labeling
1
2013
... 目前,国际上已经有少量开源的遥感影像建筑物样本数据集,如ISPRS的Vaihingen和Potsdam数据集( http: //www2.isprs.org/commissions/comm3/wg4/semantic-labeling.html )、Massachusetts数据集[18 ] 、Inria数据集[19 ] 、WHU数据集[20 ] 等,以上数据集主要是以航空影像为主,仅WHU数据集包含一部分卫星影像,但在一些重大项目中,如第三次全国国土调查、地理国情监测、全球地理信息资源建设等,仍需要构建大量的样本以满足重大项目建筑物自动提取的需求. ...
Can semantic labeling methods generalize to any city? The inria aerial image labeling benchmark
1
2017
... 目前,国际上已经有少量开源的遥感影像建筑物样本数据集,如ISPRS的Vaihingen和Potsdam数据集( http: //www2.isprs.org/commissions/comm3/wg4/semantic-labeling.html )、Massachusetts数据集[18 ] 、Inria数据集[19 ] 、WHU数据集[20 ] 等,以上数据集主要是以航空影像为主,仅WHU数据集包含一部分卫星影像,但在一些重大项目中,如第三次全国国土调查、地理国情监测、全球地理信息资源建设等,仍需要构建大量的样本以满足重大项目建筑物自动提取的需求. ...
遥感影像建筑物提取的卷积神经元网络与开源数据集方法
2
2019
... 目前,国际上已经有少量开源的遥感影像建筑物样本数据集,如ISPRS的Vaihingen和Potsdam数据集( http: //www2.isprs.org/commissions/comm3/wg4/semantic-labeling.html )、Massachusetts数据集[18 ] 、Inria数据集[19 ] 、WHU数据集[20 ] 等,以上数据集主要是以航空影像为主,仅WHU数据集包含一部分卫星影像,但在一些重大项目中,如第三次全国国土调查、地理国情监测、全球地理信息资源建设等,仍需要构建大量的样本以满足重大项目建筑物自动提取的需求. ...
... 目前遥感影像的像素级分类几乎都是基于FCN,于是本文以SCRS数据集中的真彩色影像为输入,对目前较为流行的几种FCN模型进行评估,表 2 给出了FCN-8s,Segnet,U-net,PSPNet和本文方法(FPN-SENet)的分类精度,测试数据仍选择图5 的影像.从测试结果来看,FPN-SENet取得了最优的结果,相对于表现次之的U-net,本文方法的F 1值和IoU 高出2.4和3.1百分点,比PSPNet的结果高出5.7和7.4百分点.从文献中得知,传统方法的准确率难以超过50%[20 ] ,而表2 中语义分割模型的F1-score均超过了70%,说明深度学习方法在卫星影像建筑物提取中具有很好的应用前景. ...
遥感影像建筑物提取的卷积神经元网络与开源数据集方法
2
2019
... 目前,国际上已经有少量开源的遥感影像建筑物样本数据集,如ISPRS的Vaihingen和Potsdam数据集( http: //www2.isprs.org/commissions/comm3/wg4/semantic-labeling.html )、Massachusetts数据集[18 ] 、Inria数据集[19 ] 、WHU数据集[20 ] 等,以上数据集主要是以航空影像为主,仅WHU数据集包含一部分卫星影像,但在一些重大项目中,如第三次全国国土调查、地理国情监测、全球地理信息资源建设等,仍需要构建大量的样本以满足重大项目建筑物自动提取的需求. ...
... 目前遥感影像的像素级分类几乎都是基于FCN,于是本文以SCRS数据集中的真彩色影像为输入,对目前较为流行的几种FCN模型进行评估,表 2 给出了FCN-8s,Segnet,U-net,PSPNet和本文方法(FPN-SENet)的分类精度,测试数据仍选择图5 的影像.从测试结果来看,FPN-SENet取得了最优的结果,相对于表现次之的U-net,本文方法的F 1值和IoU 高出2.4和3.1百分点,比PSPNet的结果高出5.7和7.4百分点.从文献中得知,传统方法的准确率难以超过50%[20 ] ,而表2 中语义分割模型的F1-score均超过了70%,说明深度学习方法在卫星影像建筑物提取中具有很好的应用前景. ...
Feature pyramid networks for object detection
1
2017
... 针对遥感影像的多尺度问题,传统的方式是通过多尺度输入图像的方式来构建多尺度特征,特征金字塔网络(feature pyrimad network,FPN)[21 ] 借鉴了这一思想,但是在网络内部构建特征金字塔,实现多尺度特征融合,将包含更多语义信息的高层网络特征与包含更多几何细节信息的浅层网络特征串联融合.本文针对高分卫星遥感影像的建筑物自动提取,采用一种基于FPN的语义分割网络FPN-SENet,提升遥感影像建筑物分类精度,FPN-SENet主体网络框架如图1 所示,而在特征图提取部分,采用了SE (squeeze-and-excitation) 模块[22 ] ,如图2 所示. ...
Squeeze-and-excitation networks
1
2018
... 针对遥感影像的多尺度问题,传统的方式是通过多尺度输入图像的方式来构建多尺度特征,特征金字塔网络(feature pyrimad network,FPN)[21 ] 借鉴了这一思想,但是在网络内部构建特征金字塔,实现多尺度特征融合,将包含更多语义信息的高层网络特征与包含更多几何细节信息的浅层网络特征串联融合.本文针对高分卫星遥感影像的建筑物自动提取,采用一种基于FPN的语义分割网络FPN-SENet,提升遥感影像建筑物分类精度,FPN-SENet主体网络框架如图1 所示,而在特征图提取部分,采用了SE (squeeze-and-excitation) 模块[22 ] ,如图2 所示. ...
基于segnet语义模型的高分辨率遥感影像农村建设用地提取
1
2019
... 由于受计算机硬件设备的限制,采用FCN 对遥感影像进行训练和预测时,需将遥感影像和样本图像裁剪成较小尺寸的图像进行处理,但是在分块进行遥感影像预测分类时,2块之间的边界附近可能存在明显拼接缝的现象,常见的方法是通过重叠切割减少分块拼接痕迹[23 ] ,提升分类效果,而本文引入一种二次样条窗函数,进行平滑拼接预测分类,该窗函数由一维二次样条窗函数扩展而来,公式为: ...
基于segnet语义模型的高分辨率遥感影像农村建设用地提取
1
2019
... 由于受计算机硬件设备的限制,采用FCN 对遥感影像进行训练和预测时,需将遥感影像和样本图像裁剪成较小尺寸的图像进行处理,但是在分块进行遥感影像预测分类时,2块之间的边界附近可能存在明显拼接缝的现象,常见的方法是通过重叠切割减少分块拼接痕迹[23 ] ,提升分类效果,而本文引入一种二次样条窗函数,进行平滑拼接预测分类,该窗函数由一维二次样条窗函数扩展而来,公式为: ...
1
2013
... 深度学习模型训练需要大量的样本库,本文制作了大规模的逐像素标注样本数据集: 首先,收集整理地理国情监测成果数据中的地表覆盖矢量数据和对应的高分辨率卫星遥感影像,该地表覆盖数据是基于高分辨率遥感影像进行人工目视解译,并结合一定的指标和规则制作完成,其主要内容和采集指标参考《地理国情普查内容与指标》[24 ] ; 然后,选取地表覆盖矢量数据中房屋建筑较多的地区作为样本制作区域,同时去除卫星影像中有云覆盖的区域,裁剪出房屋矢量数据和对应区域的卫星影像,再将房屋矢量数据转化为栅格格式,形成与卫星影像逐像素对应的标签数据,完成建筑物的样本标注; 最终,选取了200景卫星遥感影像完成多源卫星遥感建筑物样本数据制作,其中高分二号影像约占1/2,北京二号和高景一号影像各占1/4. ...
1
2013
... 深度学习模型训练需要大量的样本库,本文制作了大规模的逐像素标注样本数据集: 首先,收集整理地理国情监测成果数据中的地表覆盖矢量数据和对应的高分辨率卫星遥感影像,该地表覆盖数据是基于高分辨率遥感影像进行人工目视解译,并结合一定的指标和规则制作完成,其主要内容和采集指标参考《地理国情普查内容与指标》[24 ] ; 然后,选取地表覆盖矢量数据中房屋建筑较多的地区作为样本制作区域,同时去除卫星影像中有云覆盖的区域,裁剪出房屋矢量数据和对应区域的卫星影像,再将房屋矢量数据转化为栅格格式,形成与卫星影像逐像素对应的标签数据,完成建筑物的样本标注; 最终,选取了200景卫星遥感影像完成多源卫星遥感建筑物样本数据制作,其中高分二号影像约占1/2,北京二号和高景一号影像各占1/4. ...
A review of assessing the accuracy of classifications of remotely sensed data
1
1991
... 精度评估采用基于误差矩阵为核心的分类精度评价方法[25 ] ,评价指标包括总体精度(OA)和Kappa系数、F1分值和IoU(交并比)[26 ] ,公式为: ...
Convolutional neural networks for large-scale remote-sensing image classification
1
2017
... 精度评估采用基于误差矩阵为核心的分类精度评价方法[25 ] ,评价指标包括总体精度(OA)和Kappa系数、F1分值和IoU(交并比)[26 ] ,公式为: ...








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}