0 引言
目前,由于传感器技术的限制,单一传感器还不能直接获取到同时具有高光谱分辨率、高空间分辨率的图像,卫星遥感平台上一般同时安装有两台传感器,分别用于获取高空间分辨率的全色图像和多光谱图像[1 ] 。在应用时,通常需要先利用图像融合技术对全色图像和多光谱图像进行融合,以获取同时具有高光谱分辨率和高空间分辨率的图像[2 ] 。
传统的图像融合方法主要有成分替代(component substitution,CS)[3 ] 、多分辨率分析(multiresolution analysis,MRA)[4 ] 和稀疏表示(spare representation,SR)[5 ] 。CS融合方法首先将多光谱图像(multispectral,MS)转化到另一个空间,将空间结构和光谱信息分离为不同的成分; 然后,将转化后的MS图像中具有空间结构的分量替换为全色图像(panchromatic,PAN)。经典的基于CS的融合方法包括强度-色调-饱和度(intensity-hue-saturation,IHS)融合方法[6 ] 、主成分分析(principal component analysis,PCA)融合方法[7 ] 和施密特正交化方法(gram-schmidt,GS)[8 ] 。基于CS的方法可以获得丰富的细节,但光谱失真往往比较严重。MRA融合方法的核心是多尺度细节提取和注入。通常采用MRA方法从PAN图像中提取空间细节,然后将其注入上采样的多光谱图像中。广泛使用的MRA方法包括拉普拉斯金字塔[9 ] 、小波变换[10 ,11 ] 、curvelet变换[12 ] 、非下采样contourlet变换[13 ,14 ] 、sheartlet变换[15 ] 、非下采样sheartlet变换[16 ] 。与基于CS的方法相比,基于MRA的方法将提取到的全色图像的细节信息注入到多光谱图像中能够更好地保持光谱特性。稀疏表示的核心思想是将图像表示为一个过完整字典中最少原子的线性组合,但是该方法比较复杂和费时[17 ] 。
近年来,基于深度学习的遥感图像融合方法受到了广泛的关注,如以卷积神经网络为基础的融合网络 (pansharpening by convolutional neural networks,PNN)[18 ] ,基于卷积神经网络的目标自适应融合网络(target-adaptive CNN-based pansharpening,Target-PNN)[19 ] ,多尺度多深度卷积神经网络(multi-scale and multi-depth convolutional neural network,MSDCNN)[20 ] ,采用深度网络结构的图像融合(a deep network architecture for pan-sharpening,PanNet)[21 ] ,遥感图像融合深度卷积神经网络(remote sensing image fusion with deep convolutional neural network,RSIFNN)[22 ] ,基于卷积自编码器的MS融合(convolutional autoencoder-based multispectral image fusion,CAE)[23 ] 。其中,PNN网络首次在图像融合任务中使用卷积神经网络,其将插值后的多光谱图像和全色图像拼接起来输入网络中进行端对端的训练,网络直接学习输入和高分辨率图像之间的关系; PanNet网络将全色图像和多光谱图像的高频细节信息拼接起来输入到残差网络中进行特征提取与融合,然后将提取到的高频细节信息注入上采样后的低分辨率多光谱图像中。与传统的基于CS和基于MRA的算法相比,基于CNN的方法显著提高了图像融合的性能,但这些方法还存在一些问题,主要有: Target-PNN和RSIFNN都缺乏具体的纹理细节处理,导致融合后的图像纹理细节不够清晰。PNN只是单纯地将全色图像和上采样的多光谱图像输入卷积神经网络进行训练,没有根据全色图像和多光谱图像各自的特点有针对的进行特征提取和融合,可能会导致一些光谱和空间结构的失真。PanNet虽然增强了纹理细节,但没有考虑MS图像光谱通道之间的关系,可能会导致一些光谱失真。
注意力机制源于对人类视觉的研究,在认知学中,人类会有选择地关注所有信息的一部分,同时忽略其他可见信息。该思想最早应用在自然语言的处理中。后来,研究者提出了注意力机制模型(squeeze-and-excitation networks,SENet),该模型通过对输入的信息进行挤压、激励和特征重标定,对每个特征通道赋予不同的权重[24 ] 。该网络结构被广泛应用于目标检测、图像分类等任务中,取得了很好的效果。在图像融合任务中,需要通过神经网络对全色和多光谱图像的所有特征进行融合操作,但是这样会产生大量的冗余信息,如何更准确高效地融合特征信息成为了一个亟待解决的问题。注意力机制则可以通过对特征赋予权重来解决这个问题。
先验知识是人们通过经验或者数理统计等方法得到的对于事物特性的描述,被广泛应用于自然图像去模糊、自然图像去噪中[25 ] 。常用的自然图像先验知识有自然图像的局部平滑性、非局部自相似性、稀疏性等特征。受自然图像先验知识的启发,考虑到归一化植被指数(normalized difference vegetation index,NDVI)能够反映土地植被的分布信息,归一化水指数(normalized difference water index,NDWI)反映了水体的分布信息,而植被和水体是能够影响光谱的两种主要信息。所以,我们利用这两种信息作为先验知识,对遥感影像的融合过程进行约束,可以进一步提高融合效果,改善光谱失真的问题。
基于上述分析,本文提出一种新的图像融合模型——基于知识引导的遥感影像融合模型(remote sensing image FuseNet,RSFuseNet)来改善融合过程中的光谱失真和空间结构失真问题。本文在RSFuseNet模型中引入了SENet网络中的挤压激励(squeeze-and-excitation,SE)结构,通过对图像的特征进行挤压、激励操作学习每个特征通道的权重,将学到的权重赋予图像的每个特征通道,以此来有针对性地抑制无用信息,增强有用信息,减少了冗余信息在网络中的传递和积累,提高了融合精度,缩短了模型的训练时间。根据全色图像与多光谱图像的特点引入先验知识——NDVI和NDWI来对融合过程中的光谱信息进行约束。提高了融合过程中光谱信息的保真度,解决了图像融合过程中容易产生的光谱失真问题。
1 研究数据
1.1 遥感数据及其预处理
本文选择山东省泰安市的两幅高景一号影像,以及其对应的高分六号影像制作数据集。每幅高景一号影像包含了全色波段和多光谱波段,全色波段的分辨率为0.5 m,多光谱波段的分辨率为2 m。每景高分六(GF-6)影像包含多光谱波段(蓝、绿、红、近红外)和全色波段,空间分辨率分别为8 m和2 m,表1 给出了本文所使用的高分六号卫星的主要参数。
图像预处理主要包括几何纠正、辐射校正等步骤。本文利用航天宏图信息技术股份有限公司生产的新一代遥感与地理信息一体化软件(pixel information expert,PIE)对高分六号卫星的图像以批处理的方式进行预处理,包括: 大气校正、几何纠正、正射校正。经过预处理后,得到空间分辨率为8 m的多光谱图像和空间分辨率为2 m的全色图像,其中,多光谱图像包含蓝、绿、红、近红外4个波段,全色图像包含一个波段。在遥感图像处理平台(the environment for visualizing images,ENVI)中对高景一号多光谱影像进行辐射定标、大气校正及正射校正,得到分辨率为2 m的多光谱影像。
1.2 数据集制作
通过1.1节中所述步骤,得到高分六号的全色与多光谱图像及高景一号的多光谱图像,将高分六号全色图像裁剪成512×512大小的TIF格式的图片,图片命名时采用在后缀的前面添加_pan。将对应的高分六号多光谱图像裁剪成128×128大小的TIF格式的图片,图片命名时采用在后缀的前面添加_lrms。将对应的高景一号的多光谱影像裁剪成512像素×512像素大小的TIF格式的图片,图片命名时采用在后缀的前面添加_target。将裁剪得到的数据的80%作为训练样本,20%的数据作为测试样本,分别放在train和test文件夹下,即得到实验所用的数据集。
2 研究方法
2.1 模型结构
RSFuseNet模型的输入数据为训练样本中的高分六号全色、多光谱图像,高景一号的多光谱图像。其中,高分六号的全色图像和多光谱图像用来提取特征并进行特征融合; 高景一号的多光谱图像是参考图像,用来计算模型的损失。模型结构如图1 所示,主要包括特征提取模块、自适应SE模块以及结合自适应SE的卷积模块。
图1
图1
RSFuseNet模型基本结构图
Fig.1
Basic structure of the remote sensing image FuseNet
2.1.1 特征提取模块
在进行图像融合前,全色图像要经过高通滤波器,提取高频细节信息,过滤掉冗余的噪声信息。构建高通滤波器时,首先用均值滤波器获取图像的低频信息,然后用原始图像减去低频信息即得到高频信息。获取全色图像的高频信息可以减少全色图像中的噪声信息对多光谱图像中光谱信息的影响,充分发挥全色图像中高频纹理细节的优势,进而使融合图像的光谱信息和纹理信息达到最优的效果。
多光谱图像输入模型后首先要进行上采样以达到与全色图像相同的分辨率。鉴于双三次插值法可以充分保持多光谱图像的光谱信息,故采用双三次插值进行上采样。考虑到全色图像的分辨率是多光谱图像分辨率的4倍,遂采用分两次上采样来提升多光谱图像的分辨率,每一次在原来的基础上提升两倍。上采样模块由一个双三次插值层和一个1×1卷积的调整层组成。在上采样后引入先验知识,即通过NDVI和NDWI的计算公式分别计算出上采样后多光谱图像的每个像素点的NDVI和NDWI的值,这些值分别组成2个矩阵,与上采样后的多光谱图像一起作为下一层卷积的输入。NDVI和NDWI的计算公式为:
(1) NDVI= N I R - R N I R + R
(2) NDWI= G - N I R G + N I R
式中,NIR ,R 和G 分别为多光谱图像近红外波段、红色波段和绿色波段的反射率。
2.1.2 自适应SE模块
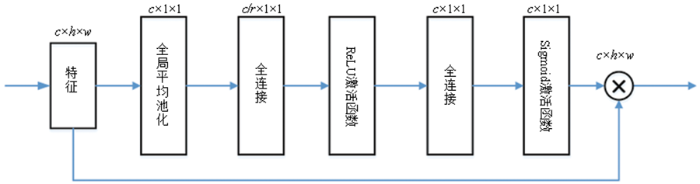
该模块输入的特征图大小为c ×h ×w ,其中c 为通道数,h 为高度,w 为宽度。该模块主要由一个全局平均池化层,两个全连接层,一个ReLU激活函数层和一个Sigmoid激活函数层组成。全局平均池化层将输入的特征图压缩为c ×1×1的大小,也就是每一个通道得到一个值,这个值具有全局的感受野,它表征着在特征通道上响应的全局分布。第一个全连接层将全局平均池化层中得到的结果降维到c /r ×1×1的大小,这里的r 采用上一层卷积的通道数也就是c ,这也是该模块叫作“自适应”SE模块的原因,即降维所用的参数能够随着输入特征通道数的变化而变化,通过这种“自适应”机制可以极大地减少参数量和计算量。ReLU层对第一层全连接层的结果进行激活操作,第二个全连接层将特征升回到原始的维度。通过全连接层的降维和升维以及ReLU的激活操作可以增加模型的非线性,更好地拟合通道间复杂的相关性。Sigmoid激活函数获得每个特征通道的权重。最后将获得的权重乘到每个通道的特征上,也就是图中的×操作。具体见图2 。
图2
图2
自适应SE模块结构图
Fig.2
The structure diagram of adaptive squeeze-and-excitation module
2.1.3 结合自适应SE的卷积模块
RSFuseNet模型的影像融合部分采用结合自适应SE的卷积模块。该模块主要包括3个卷积单元,第一个和第二个卷积单元组成相同,都是由一个卷积层、一个激活函数层和一个自适应SE模块组成; 第三个卷积单元由一个卷积层和一个激活函数层组成。该模块输入为经过高通滤波提取的全色图像的高频纹理信息、上采样后分辨率与全色图像相同的多光谱图像和经过逐像素计算得到的NDVI和NDWI。这样,第一个卷积单元一共输入7个波段,故该单元卷积层的输入通道为7,卷积核大小为9×9,步长大小为1,填充大小为4,输出特征通道大小为48。第二个卷积单元卷积层的输入通道为48,卷积核大小为5×5,步长大小为1,填充大小为2,输出通道的大小为32。第三个卷积单元卷积层的输入通道为32,卷积核大小为5×5,步长大小为1,填充大小为2,输出通道大小为4。由于数据输入模型时首先对其进行归一化操作,故卷积层后面没有使用归一化层。
2.2 训练模型
2.2.1 模型损失
由于图像融合任务属于回归问题,所以模型以均值平方差为基础定义损失函数,均值平方差损失函数定义为:
(3) MSE= 1 m n ∑ i = 0 m - 1 ∑ j = 0 n - 1 2 ,
式中: I (i ,j )为目标图像第(i ,j )个像素的值,即真值; K (i ,j )为训练完成后结果图像第(i ,j )个像素的值; m 为图像的宽度; n 为图像的高度。
根据MSE函数,定义RSFuseNet模型的损失函数为loss ,计算公式为:
(4) loss= 1 m n ∑ i = 0 m - 1 ∑ j = 0 n - 1 spectral (i,j)+Lspatial (i,j))2 ,
(5) Lspectral (i,j)= 1 m n ∑ i = 0 m - 1 ∑ j = 0 n - 1
(6) Lspatial i , j 1 m n ∑ i = 0 m - 1 ∑ j = 0 n - 1 i , j i , j
式中: L spectral (i ,j )为融合图像光谱部分的损失值; L spatial (i ,j )为融合图像结构部分的损失值; R (i ,j )为参考图像的值; upLR (i ,j )为上采样后的多光谱图像的值; HRMS (i ,j )为融合后得到的高分辨多光谱图像的值。
2.2.2 训练方法
模型采用端对端的方式进行训练,使用loss作为损失函数,使用随机梯度下降算法 (stochastic gradient descent,SGD)作为优化算法,具体训练步骤为:
1)确定训练过程中的超参数,并对模型的参数进行初始化。
2)将制作出的训练图像(包括全色,多光谱以及参考图像)作为训练数据输入到模型。
5)使用随机梯度下降算法,对模型的参数进行更新,完成一次训练过程。
6)重复步骤3)—5),直到损失函数小于指定的期望值或者损失值不再减小。
3 实验
3.1 实验设计
本文以pytorch框架为实验平台,以python语言对模型进行编码实现。使用一台服务器开展对比实验,实验使用的操作系统为Ubuntu16.04,为了加速数据的运行,装载GPU TITAN X,并安装CUDA和cuDNN加速。实验使用的数据集在1.2节已经进行了说明,本实验采用1 850组图像作为训练样本、422组图像作为测试样本,训练样本和测试样本互不交叉。每一组图像包括全色图像、多光谱图像、参考图像。由于全色和多光谱图像的空间分辨率之比为1∶4,参考图像与全色图像的空间分辨率相同,所以在这些样本中,全色图像和参考图像的尺寸为512像素×512像素,多光谱图像的尺寸为128像素×128像素。这些数据均由高分六号卫星的PMS传感器获得、经过预处理得到。另外,本文实验得到的结果图像与高分六号全色图像具有相同的空间分辨率,均为2 m,图像尺寸为512像素×512像素。
本文将RSFuseNet模型与5种常见的图像融合方法进行比较,对比方法分别是GS变换、PCA、最邻近插值融合方法(nearest neighbor diffusion,NNDiffuse)、PNN和PanNet。前3种是传统的图像融合算法,PNN和PanNet是深度学习的图像融合算法(表2 )。
3.2 客观评价指标
客观评价指标可以定量地评价融合图像的质量情况,尤其是在图像的一些微小的细节,仅仅依靠人眼很难发现图像的优劣,而采用客观评价指标,则可以通过数值的大小定量地评价图像的好坏。因此,本文选择峰值信噪比(peak signal to noise ratio,PSNR)[26 ] 、结构相似性指数(structural similarity,SSIM)[27 ] 和光谱映射角(spectral angle mapper,SAM)[28 ] 3种评价指标对融合结果进行定量评价,从不同的方面对图像的质量进行评估。
PSNR主要用来评价图像质量的敏感性误差,是衡量两幅图像差别的重要指标,其计算公式为:
(7) PSNR=10 lg 2 n - 1 2 M S E
(8) MSE= 1 H W ∑ i = 1 H ∑ j = 1 W 2 ,
式中: H 和W 分别是图像的高度和宽度; F 和R 分别为融合结果图像和参考图像。PSNR的值越大,表明融合图像从原始图像获得的信息量越多,图像和原始图像相似度越高,融合效果越好。
SSIM从亮度(均值)、对比度(方差)和结构3个层次中比较图像的失真程度,取值范围为[0,1],值越大越好,其计算公式为:
(9) SSIM (F,R)= 2 μ F μ R + C 1 μ F 2 + μ R 2 + C 1 2 σ F R + C 2 σ F 2 + σ R 2 + C 2
式中: μF 为F 的均值; μR 为R 的均值;σ F 2 F 的方差;σ R 2 R 的方差; σRF 为F 和R 的协方差; C 1 =k 1 L 2 C 2 =k 2 L 2 L 为像素值的范围; k 1 =0. 01,k 2 =0. 03为默认值。
SAM是可以计算两幅图像在每个像素处的光谱相似度的一种指标。其值较低则表示较低的光谱失真和较好的图像融合质量。其计算公式为:
(10) SAM F j , R j F j , R j F j R j
式中:F j R j F 和R 的第j 个像素向量,F j , R j L 2范数。
3.3 实验结果
图3 —图6 分别给出了使用NNDiffuse,GS变换、PCA,PanNet,PNN和RSFuseNet方法对测试样本进行融合得到的结果图。其中a列为用 NNDiffuse融合的结果图,b列为用GS变换融合得到的结果图,c列为用PCA融合的结果图,d列为用PanNet模型融合得到的结果图,e列为PNN模型的融合结果图,f列为用RSFuseNet模型得到的融合结果图。这些图像中包含了建筑、农田、大棚、道路、河流等地物,具有一定的代表性。
图3
图3
区域一对比实验结果
Fig.3
Comparison of experimental model results
图4
图4
区域二对比实验结果
Fig.4
Comparison of experimental model results
图5
图5
区域三对比实验结果
Fig.5
Comparison of experimental model results
图6
图6
区域四对比实验结果
Fig.6
Comparison of experimental model results
综合图3 —图6 可以看出,a列融合图像颜色偏深,尤其是在有植被的地方,植被的不同区域展现出的不同颜色在融合图像中无法具体区分。b列和c列图像还是会存在部分光谱失真的现象,d列、e列、f列图像在区分不同区域的植被颜色上都有了改进,可以区分出不同区域不同的颜色。在图像的纹理特征方面,d列和e列要比f列稍逊色一些。在图像的水体特征方面,通过图6 可以看出,与f列图像相比,d列和e列图像在水体的颜色方面存在着明显的光谱失真,a列、b列和c列图像存在着轻微的光谱失真,这也进一步说明了引入NDWI信息可以改善水体的光谱失真现象。仔细观察上述图像可以发现,f列图像的结果在图像的边缘部分更清晰,比如在房子的边缘、大棚的边缘以及不同作物的边缘,f列图像得到的结果纹理更明显,d列和e列则有一些模糊。这说明了利用卷积神经网络进行图像融合的方法是优于传统的图像融合方法的,而且不同的卷积神经网络算法对融合结果的影响不同。通道注意力层在图像的融合过程中发挥了作用,能够通过学习每个通道的特征信息并根据其重要程度赋予其权重,这样,权重低的噪声信息在图像融合的过程中就会被相应的抑制,从而使融合结果更精确。
各个模型的定量评价结果如表3 所示,表中向上的箭头表示该指标的值越高,融合效果越好,向下的箭头表示该指标的值越低,融合效果越好。可以看到RSFuseNet模型的3个评价指标的值均优于对比模型。
通过图3 —图6 和表3 的分析,可以发现不论是主观视觉感受还是在客观评价指标,本文构建的RSFuseNet模型都比其他方法表现出更好的效果。
4 讨论
4.1 自适应SE对结果精度的影响
使用自适应SE模块的目的,是为了对特征重标定,从而达到根据特征的重要程度进行特征融合的目的。在本研究开展的对比实验中,RSFuseNet,PanNet和PNN都是通过对输入的特征进行卷积操作达到特征融合的效果。不同的是,RSFuseNet在融合的过程中采用了自适应SE模块对特征进行重标定,而PanNet和PNN在融合的过程中没有进行特征的重标定操作。
对比RSFuseNet模型和PanNet模型、PNN模型的融合结果,可以发现PanNet模型生成的图像还普遍存在着棋盘化的现象; PNN模型的结果图像在光谱上还是存在着一定的失真。RSFuseNet模型融合的结果图像光谱信息较好,细节较丰富。尤其是在图像中建筑的边缘、道路、农田中不同作物的边缘以及大棚的边缘,RSFuseNet的融合结果比PanNet,PNN的融合结果具有更加清晰的纹理。
造成这种现象的原因,主要是因为在RSFuseNet模型中使用了自适应SE模块。该模块通过特征重标定增强有用的特征,抑制无用的特征,从而能够有针对性地进行图像融合,减少了冗余信息对融合结果的影响。
4.2 先验知识对结果精度的影响
目前,在图像分类,图像分割任务中需要根据先验知识对训练图像做一个真值图,以此来告诉深度学习模型哪些类型的地物是农田,哪些地物类型是建筑、小麦、玉米、水体、道路等等。在图像融合中无法细致地对每一类地物做出标记,但是可以利用遥感影像便于计算的NDVI和NDWI属性充当先验信息来进行图像融合。因此,使用NDVI和NDWI这两种先验知识的目的,是为了在模型中添加一些限制条件,达到对图像融合约束的作用。在本研究开展的对比实验中,只有RSFuseNet模型使用了先验知识NDVI和NDWI。
对比RSFuseNet模型和GS,PCA,PanNet,PNN及NNDiffuse,可以发现NNDiffuse得到的结果图像光谱失真比较严重,图像颜色发暗,难以区分不同地物。GS和PCA得到的结果图像存在着少许的光谱失真。PanNet和PNN模型的结果图也存在着轻微的光谱失真。而RSFuseNet模型的结果图像则几乎没有出现光谱失真现象,光谱信息更丰富,图像质量更高。
5 结论
针对遥感影像融合过程中容易出现的光谱失真和空间结构失真问题,本文利用注意力机制在特征提取方面的优势和先验知识的特性,建立了一种适用于高分六号遥感影像的融合模型。该模型利用注意力机制对图像的特征通道赋予重要性,并根据重要程度对特征进行后续的处理; 同时在融合过程中利用先验知识对特征进行逐像素约束,使得融合结果的光谱特征和纹理特征都取得了较高的保真度。
本文的不足之处在于本文构建的模型是有监督模型,但是当前图像融合的参考图像难以获得,融合结果相比理想结果可能还是存在一些差距。针对这个问题考虑在下一步的工作中根据遥感影像的特点设计一个无监督的网络,解决参考图像难以获得的问题。
参考文献
View Option
[1]
王建宇 , 王跃明 , 李春来 . 高光谱成像系统的噪声模型和对辐射灵敏度的影响
[J]. 遥感学报 , 2010 , 14 (4 ):607 -620 .
[本文引用: 1]
Wang J Y Wang Y M Li C L Noise model of hyperspectral imaging system and influence on radiation sensitivity
[J]. Journal of Remote Sensing , 2010 , 14 (4 ):607 -620 .
[本文引用: 1]
[2]
Vivone G Alparone L Chanussot J et al. A critical comparison among pansharpening algorithms
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2015 , 53 (5 ):2565 -2586 .
DOI:10.1109/TGRS.2014.2361734
URL
[本文引用: 1]
[3]
Xie B Zhang H Huang B Revealing implicit assumptions of the component substitution pansharpening methods
[J]. Remote Sensing , 2017 , 9 (5 ):443 -458 .
DOI:10.3390/rs9050443
URL
[本文引用: 1]
[4]
Yong Y Wan W Huang S et al. A novel pan-sharpening framework based on matting model and multiscale transform
[J]. Remote Sensing , 2017 , 9 (4 ):391 .
DOI:10.3390/rs9040391
URL
[本文引用: 1]
[5]
王晓艳 , 刘勇 , 蒋志勇 . 一种基于结构相似度的IHS变换融合算法
[J]. 遥感技术与应用 , 2011 , 26 (5 ):670 -676 .
[本文引用: 1]
Wang X Y Liu Y Jiang Z Y An IHS fusion method based on structural similarity
[J]. Remote Sensing Technology and Application , 2011 , 26 (5 ):670 -676 .
[本文引用: 1]
[6]
Yang Y Wan W Huang S et al. Remote sensing image fusion based on adaptive IHS and multiscale guided filter
[J]. IEEE Access , 2017 (4 ):4573 -4582 .
[本文引用: 1]
[7]
W Dong S Xiao X Xue et al. An improved hyperspectral pansharpening algorithm based on optimized injection model
[J]. IEEE Access , 2019 (7 ):16718 -16729 .
[本文引用: 1]
[8]
Xu L Zhang Y Gao Y et al. Using guided filtering to improve gram-schmidt based pansharpening method for GeoEye-1 satellite images
[J]. Proceedings of the 4th International Conference on Information Systems and Computing Technology , 2016 (64 ):33 -37 .
[本文引用: 1]
[9]
Aiazzi B Alparone L Baronti S et al. MTF-tailored multiscale fusion of high-resolution MS and Pan imagery
[J]. Photogrammetric Engineering & Remote Sensing , 2015 , 72 (5 ):591 -596 .
[本文引用: 1]
[10]
Vivone G Restaino R Mura M D et al. Contrast and error-based fusion schemes for multispectral image pansharpening
[J]. IEEE Geoscience and Remote Sensing Letters , 2013 , 11 (5 ):930 -934 .
DOI:10.1109/LGRS.2013.2281996
URL
[本文引用: 1]
[11]
Alparone , Luciano , Baronti , et al. Spatial methods for multispectral pansharpening:Multiresolution analysis demystified
[J]. IEEE Transactions on Geoscience & Remote Sensing , 2016 (54 ):2563 -2576 .
[本文引用: 1]
[13]
Lu X Zhang J Zhang Y An improved non-subsampled contourlet transform-based hybrid pan-sharpening algorithm
[C]// 2017 IEEE International Geoscience and Remote Sensing Symposium . Fort Worth : IEEE , 2017 :3393 -3396 .
[本文引用: 1]
[14]
James R Vadivel M Improvement of spectral and spatial information using modified WAMM and modified bi-cubic interpolation method in non-subsampled contourlet transform domain
[C]// 2015 International Conference on Robotics,Automation,Control and Embedded Systems (RACE) . Chennai India : IEEE , 2015 :1 -5 .
[本文引用: 1]
[15]
Zhang Z Luo X Wu X A new pansharpening method using statistical model and shearlet transform
[J]. IEEE Technical Review , 2014 , 31 (5 ):308 -316 .
[本文引用: 1]
[16]
Wang X Bai S Li Z et al. The PAN and MS Image pansharpening algorithm based on adaptive neural network and sparse representation in the NSST domain
[J]. IEEE Access , 2019 (7 ):52508 -52521 .
[本文引用: 1]
[17]
Yin H T Sparse representation based pan-sharpening with details injection model
[J]. Signal Processing , 2015 (113 ):218 -227 .
[本文引用: 1]
[18]
Giuseppe M Davide C Luisa V et al. Pansharpening by convolutional neural networks
[J]. Remote Sensing , 2016 , 8 (7 ):594 .
DOI:10.3390/rs8070594
URL
[本文引用: 1]
[19]
Scarpa G Vitale S Cozzolino D Target-adaptive CNN-based pansharpening
[J]. IEEE Transactions on Geoscience & Remote Sensing , 2018 , 56 (9 ):5443 -5457 .
[本文引用: 1]
[20]
Yuan Q Wei Y Meng X et al. A multiscale and multidepth convolutional neural network for remote sensing imagery pan-sharpening
[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , 2018 , 11 (3 ),978 -989 .
DOI:10.1109/JSTARS.2018.2794888
URL
[本文引用: 1]
[21]
Yang J Fu X Hu Y et al. PanNet:A deep network architecture for pan-sharpening
[C]// 2017 IEEE International Conference on Computer Vision(ICCV) . Venice Italy : IEEE , 2017 :5449 -5457 .
[本文引用: 1]
[22]
Shao Z Cai J Remote sensing image fusion with deep convolutional neural network
[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , 2018 , 11 (5 ):1656 -1669 .
DOI:10.1109/JSTARS.2018.2805923
URL
[本文引用: 1]
[23]
Azarang A Manoochehri H E Kehtarnavaz N Convolutional autoencoder-based multispectral image fusion
[J]. IEEE Access , 2019 , 7 :35673 -35683 .
DOI:10.1109/ACCESS.2019.2905511
[本文引用: 1]
This paper presents a deep learning-based pansharpening method for fusion of panchromatic and multispectral images in remote sensing applications. This method can be categorized as a component substitution method in which a convolutional autoencoder network is trained to generate original panchromatic images from their spatially degraded versions. Low resolution multispectral images are then fed into the trained convolutional autoencoder network to generate estimated high resolution multispectral images. The fusion is achieved by injecting the detail map of each spectral band into the corresponding estimated high resolution multispectral bands. Full reference and no-reference metrics are computed for the images of three satellite datasets. These measures are compared with the existing fusion methods whose codes are publicly available. The results obtained indicate the effectiveness of the developed deep learning-based method for multispectral image fusion.
[24]
Jie H Li S Gang S et al. Squeeze-and-excitation networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2020 , 42 (8 ):2011 -2023 .
DOI:10.1109/TPAMI.2019.2913372
PMID:31034408
[本文引用: 1]
The central building block of convolutional neural networks (CNNs) is the convolution operator, which enables networks to construct informative features by fusing both spatial and channel-wise information within local receptive fields at each layer. A broad range of prior research has investigated the spatial component of this relationship, seeking to strengthen the representational power of a CNN by enhancing the quality of spatial encodings throughout its feature hierarchy. In this work, we focus instead on the channel relationship and propose a novel architectural unit, which we term the "Squeeze-and-Excitation" (SE) block, that adaptively recalibrates channel-wise feature responses by explicitly modelling interdependencies between channels. We show that these blocks can be stacked together to form SENet architectures that generalise extremely effectively across different datasets. We further demonstrate that SE blocks bring significant improvements in performance for existing state-of-the-art CNNs at slight additional computational cost. Squeeze-and-Excitation Networks formed the foundation of our ILSVRC 2017 classification submission which won first place and reduced the top-5 error to 2.251 percent, surpassing the winning entry of 2016 by a relative improvement of ∼ 25 percent. Models and code are available at https://github.com/hujie-frank/SENet.
[25]
聂文昌 . 融合先验知识的深度学习目标识别与定位研究 [D]. 哈尔滨 : 哈尔滨工程大学 , 2019 .
[本文引用: 1]
Nie Wenchang Research on target recognition and locationbased on prior knowledge using deep learning [D]. Harbin : Harbin Engineering University , 2019 .
[本文引用: 1]
[27]
[本文引用: 1]
Yang L P Ma M Xie W et al. Fusion algorithm evaluation of Landsat 8 panchromatic and multispectral images in arid regions
[J]. Remote Sensing for Land and Resources , 2019 , 31 (4 ):11 -19 .doi: 10.6046/gtzyyg.2019.04.02 .
[本文引用: 1]
[28]
Vivone G Alparone L Chanussot J et al. A critical comparison among pansharpening algorithms
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2015 , 53 (5 ):2565 -2586 .
DOI:10.1109/TGRS.2014.2361734
URL
[本文引用: 1]
高光谱成像系统的噪声模型和对辐射灵敏度的影响
1
2010
... 目前,由于传感器技术的限制,单一传感器还不能直接获取到同时具有高光谱分辨率、高空间分辨率的图像,卫星遥感平台上一般同时安装有两台传感器,分别用于获取高空间分辨率的全色图像和多光谱图像[1 ] .在应用时,通常需要先利用图像融合技术对全色图像和多光谱图像进行融合,以获取同时具有高光谱分辨率和高空间分辨率的图像[2 ] . ...
高光谱成像系统的噪声模型和对辐射灵敏度的影响
1
2010
... 目前,由于传感器技术的限制,单一传感器还不能直接获取到同时具有高光谱分辨率、高空间分辨率的图像,卫星遥感平台上一般同时安装有两台传感器,分别用于获取高空间分辨率的全色图像和多光谱图像[1 ] .在应用时,通常需要先利用图像融合技术对全色图像和多光谱图像进行融合,以获取同时具有高光谱分辨率和高空间分辨率的图像[2 ] . ...
A critical comparison among pansharpening algorithms
1
2015
... 目前,由于传感器技术的限制,单一传感器还不能直接获取到同时具有高光谱分辨率、高空间分辨率的图像,卫星遥感平台上一般同时安装有两台传感器,分别用于获取高空间分辨率的全色图像和多光谱图像[1 ] .在应用时,通常需要先利用图像融合技术对全色图像和多光谱图像进行融合,以获取同时具有高光谱分辨率和高空间分辨率的图像[2 ] . ...
Revealing implicit assumptions of the component substitution pansharpening methods
1
2017
... 传统的图像融合方法主要有成分替代(component substitution,CS)[3 ] 、多分辨率分析(multiresolution analysis,MRA)[4 ] 和稀疏表示(spare representation,SR)[5 ] .CS融合方法首先将多光谱图像(multispectral,MS)转化到另一个空间,将空间结构和光谱信息分离为不同的成分; 然后,将转化后的MS图像中具有空间结构的分量替换为全色图像(panchromatic,PAN).经典的基于CS的融合方法包括强度-色调-饱和度(intensity-hue-saturation,IHS)融合方法[6 ] 、主成分分析(principal component analysis,PCA)融合方法[7 ] 和施密特正交化方法(gram-schmidt,GS)[8 ] .基于CS的方法可以获得丰富的细节,但光谱失真往往比较严重.MRA融合方法的核心是多尺度细节提取和注入.通常采用MRA方法从PAN图像中提取空间细节,然后将其注入上采样的多光谱图像中.广泛使用的MRA方法包括拉普拉斯金字塔[9 ] 、小波变换[10 ,11 ] 、curvelet变换[12 ] 、非下采样contourlet变换[13 ,14 ] 、sheartlet变换[15 ] 、非下采样sheartlet变换[16 ] .与基于CS的方法相比,基于MRA的方法将提取到的全色图像的细节信息注入到多光谱图像中能够更好地保持光谱特性.稀疏表示的核心思想是将图像表示为一个过完整字典中最少原子的线性组合,但是该方法比较复杂和费时[17 ] . ...
A novel pan-sharpening framework based on matting model and multiscale transform
1
2017
... 传统的图像融合方法主要有成分替代(component substitution,CS)[3 ] 、多分辨率分析(multiresolution analysis,MRA)[4 ] 和稀疏表示(spare representation,SR)[5 ] .CS融合方法首先将多光谱图像(multispectral,MS)转化到另一个空间,将空间结构和光谱信息分离为不同的成分; 然后,将转化后的MS图像中具有空间结构的分量替换为全色图像(panchromatic,PAN).经典的基于CS的融合方法包括强度-色调-饱和度(intensity-hue-saturation,IHS)融合方法[6 ] 、主成分分析(principal component analysis,PCA)融合方法[7 ] 和施密特正交化方法(gram-schmidt,GS)[8 ] .基于CS的方法可以获得丰富的细节,但光谱失真往往比较严重.MRA融合方法的核心是多尺度细节提取和注入.通常采用MRA方法从PAN图像中提取空间细节,然后将其注入上采样的多光谱图像中.广泛使用的MRA方法包括拉普拉斯金字塔[9 ] 、小波变换[10 ,11 ] 、curvelet变换[12 ] 、非下采样contourlet变换[13 ,14 ] 、sheartlet变换[15 ] 、非下采样sheartlet变换[16 ] .与基于CS的方法相比,基于MRA的方法将提取到的全色图像的细节信息注入到多光谱图像中能够更好地保持光谱特性.稀疏表示的核心思想是将图像表示为一个过完整字典中最少原子的线性组合,但是该方法比较复杂和费时[17 ] . ...
一种基于结构相似度的IHS变换融合算法
1
2011
... 传统的图像融合方法主要有成分替代(component substitution,CS)[3 ] 、多分辨率分析(multiresolution analysis,MRA)[4 ] 和稀疏表示(spare representation,SR)[5 ] .CS融合方法首先将多光谱图像(multispectral,MS)转化到另一个空间,将空间结构和光谱信息分离为不同的成分; 然后,将转化后的MS图像中具有空间结构的分量替换为全色图像(panchromatic,PAN).经典的基于CS的融合方法包括强度-色调-饱和度(intensity-hue-saturation,IHS)融合方法[6 ] 、主成分分析(principal component analysis,PCA)融合方法[7 ] 和施密特正交化方法(gram-schmidt,GS)[8 ] .基于CS的方法可以获得丰富的细节,但光谱失真往往比较严重.MRA融合方法的核心是多尺度细节提取和注入.通常采用MRA方法从PAN图像中提取空间细节,然后将其注入上采样的多光谱图像中.广泛使用的MRA方法包括拉普拉斯金字塔[9 ] 、小波变换[10 ,11 ] 、curvelet变换[12 ] 、非下采样contourlet变换[13 ,14 ] 、sheartlet变换[15 ] 、非下采样sheartlet变换[16 ] .与基于CS的方法相比,基于MRA的方法将提取到的全色图像的细节信息注入到多光谱图像中能够更好地保持光谱特性.稀疏表示的核心思想是将图像表示为一个过完整字典中最少原子的线性组合,但是该方法比较复杂和费时[17 ] . ...
一种基于结构相似度的IHS变换融合算法
1
2011
... 传统的图像融合方法主要有成分替代(component substitution,CS)[3 ] 、多分辨率分析(multiresolution analysis,MRA)[4 ] 和稀疏表示(spare representation,SR)[5 ] .CS融合方法首先将多光谱图像(multispectral,MS)转化到另一个空间,将空间结构和光谱信息分离为不同的成分; 然后,将转化后的MS图像中具有空间结构的分量替换为全色图像(panchromatic,PAN).经典的基于CS的融合方法包括强度-色调-饱和度(intensity-hue-saturation,IHS)融合方法[6 ] 、主成分分析(principal component analysis,PCA)融合方法[7 ] 和施密特正交化方法(gram-schmidt,GS)[8 ] .基于CS的方法可以获得丰富的细节,但光谱失真往往比较严重.MRA融合方法的核心是多尺度细节提取和注入.通常采用MRA方法从PAN图像中提取空间细节,然后将其注入上采样的多光谱图像中.广泛使用的MRA方法包括拉普拉斯金字塔[9 ] 、小波变换[10 ,11 ] 、curvelet变换[12 ] 、非下采样contourlet变换[13 ,14 ] 、sheartlet变换[15 ] 、非下采样sheartlet变换[16 ] .与基于CS的方法相比,基于MRA的方法将提取到的全色图像的细节信息注入到多光谱图像中能够更好地保持光谱特性.稀疏表示的核心思想是将图像表示为一个过完整字典中最少原子的线性组合,但是该方法比较复杂和费时[17 ] . ...
Remote sensing image fusion based on adaptive IHS and multiscale guided filter
1
2017
... 传统的图像融合方法主要有成分替代(component substitution,CS)[3 ] 、多分辨率分析(multiresolution analysis,MRA)[4 ] 和稀疏表示(spare representation,SR)[5 ] .CS融合方法首先将多光谱图像(multispectral,MS)转化到另一个空间,将空间结构和光谱信息分离为不同的成分; 然后,将转化后的MS图像中具有空间结构的分量替换为全色图像(panchromatic,PAN).经典的基于CS的融合方法包括强度-色调-饱和度(intensity-hue-saturation,IHS)融合方法[6 ] 、主成分分析(principal component analysis,PCA)融合方法[7 ] 和施密特正交化方法(gram-schmidt,GS)[8 ] .基于CS的方法可以获得丰富的细节,但光谱失真往往比较严重.MRA融合方法的核心是多尺度细节提取和注入.通常采用MRA方法从PAN图像中提取空间细节,然后将其注入上采样的多光谱图像中.广泛使用的MRA方法包括拉普拉斯金字塔[9 ] 、小波变换[10 ,11 ] 、curvelet变换[12 ] 、非下采样contourlet变换[13 ,14 ] 、sheartlet变换[15 ] 、非下采样sheartlet变换[16 ] .与基于CS的方法相比,基于MRA的方法将提取到的全色图像的细节信息注入到多光谱图像中能够更好地保持光谱特性.稀疏表示的核心思想是将图像表示为一个过完整字典中最少原子的线性组合,但是该方法比较复杂和费时[17 ] . ...
An improved hyperspectral pansharpening algorithm based on optimized injection model
1
2019
... 传统的图像融合方法主要有成分替代(component substitution,CS)[3 ] 、多分辨率分析(multiresolution analysis,MRA)[4 ] 和稀疏表示(spare representation,SR)[5 ] .CS融合方法首先将多光谱图像(multispectral,MS)转化到另一个空间,将空间结构和光谱信息分离为不同的成分; 然后,将转化后的MS图像中具有空间结构的分量替换为全色图像(panchromatic,PAN).经典的基于CS的融合方法包括强度-色调-饱和度(intensity-hue-saturation,IHS)融合方法[6 ] 、主成分分析(principal component analysis,PCA)融合方法[7 ] 和施密特正交化方法(gram-schmidt,GS)[8 ] .基于CS的方法可以获得丰富的细节,但光谱失真往往比较严重.MRA融合方法的核心是多尺度细节提取和注入.通常采用MRA方法从PAN图像中提取空间细节,然后将其注入上采样的多光谱图像中.广泛使用的MRA方法包括拉普拉斯金字塔[9 ] 、小波变换[10 ,11 ] 、curvelet变换[12 ] 、非下采样contourlet变换[13 ,14 ] 、sheartlet变换[15 ] 、非下采样sheartlet变换[16 ] .与基于CS的方法相比,基于MRA的方法将提取到的全色图像的细节信息注入到多光谱图像中能够更好地保持光谱特性.稀疏表示的核心思想是将图像表示为一个过完整字典中最少原子的线性组合,但是该方法比较复杂和费时[17 ] . ...
Using guided filtering to improve gram-schmidt based pansharpening method for GeoEye-1 satellite images
1
2016
... 传统的图像融合方法主要有成分替代(component substitution,CS)[3 ] 、多分辨率分析(multiresolution analysis,MRA)[4 ] 和稀疏表示(spare representation,SR)[5 ] .CS融合方法首先将多光谱图像(multispectral,MS)转化到另一个空间,将空间结构和光谱信息分离为不同的成分; 然后,将转化后的MS图像中具有空间结构的分量替换为全色图像(panchromatic,PAN).经典的基于CS的融合方法包括强度-色调-饱和度(intensity-hue-saturation,IHS)融合方法[6 ] 、主成分分析(principal component analysis,PCA)融合方法[7 ] 和施密特正交化方法(gram-schmidt,GS)[8 ] .基于CS的方法可以获得丰富的细节,但光谱失真往往比较严重.MRA融合方法的核心是多尺度细节提取和注入.通常采用MRA方法从PAN图像中提取空间细节,然后将其注入上采样的多光谱图像中.广泛使用的MRA方法包括拉普拉斯金字塔[9 ] 、小波变换[10 ,11 ] 、curvelet变换[12 ] 、非下采样contourlet变换[13 ,14 ] 、sheartlet变换[15 ] 、非下采样sheartlet变换[16 ] .与基于CS的方法相比,基于MRA的方法将提取到的全色图像的细节信息注入到多光谱图像中能够更好地保持光谱特性.稀疏表示的核心思想是将图像表示为一个过完整字典中最少原子的线性组合,但是该方法比较复杂和费时[17 ] . ...
MTF-tailored multiscale fusion of high-resolution MS and Pan imagery
1
2015
... 传统的图像融合方法主要有成分替代(component substitution,CS)[3 ] 、多分辨率分析(multiresolution analysis,MRA)[4 ] 和稀疏表示(spare representation,SR)[5 ] .CS融合方法首先将多光谱图像(multispectral,MS)转化到另一个空间,将空间结构和光谱信息分离为不同的成分; 然后,将转化后的MS图像中具有空间结构的分量替换为全色图像(panchromatic,PAN).经典的基于CS的融合方法包括强度-色调-饱和度(intensity-hue-saturation,IHS)融合方法[6 ] 、主成分分析(principal component analysis,PCA)融合方法[7 ] 和施密特正交化方法(gram-schmidt,GS)[8 ] .基于CS的方法可以获得丰富的细节,但光谱失真往往比较严重.MRA融合方法的核心是多尺度细节提取和注入.通常采用MRA方法从PAN图像中提取空间细节,然后将其注入上采样的多光谱图像中.广泛使用的MRA方法包括拉普拉斯金字塔[9 ] 、小波变换[10 ,11 ] 、curvelet变换[12 ] 、非下采样contourlet变换[13 ,14 ] 、sheartlet变换[15 ] 、非下采样sheartlet变换[16 ] .与基于CS的方法相比,基于MRA的方法将提取到的全色图像的细节信息注入到多光谱图像中能够更好地保持光谱特性.稀疏表示的核心思想是将图像表示为一个过完整字典中最少原子的线性组合,但是该方法比较复杂和费时[17 ] . ...
Contrast and error-based fusion schemes for multispectral image pansharpening
1
2013
... 传统的图像融合方法主要有成分替代(component substitution,CS)[3 ] 、多分辨率分析(multiresolution analysis,MRA)[4 ] 和稀疏表示(spare representation,SR)[5 ] .CS融合方法首先将多光谱图像(multispectral,MS)转化到另一个空间,将空间结构和光谱信息分离为不同的成分; 然后,将转化后的MS图像中具有空间结构的分量替换为全色图像(panchromatic,PAN).经典的基于CS的融合方法包括强度-色调-饱和度(intensity-hue-saturation,IHS)融合方法[6 ] 、主成分分析(principal component analysis,PCA)融合方法[7 ] 和施密特正交化方法(gram-schmidt,GS)[8 ] .基于CS的方法可以获得丰富的细节,但光谱失真往往比较严重.MRA融合方法的核心是多尺度细节提取和注入.通常采用MRA方法从PAN图像中提取空间细节,然后将其注入上采样的多光谱图像中.广泛使用的MRA方法包括拉普拉斯金字塔[9 ] 、小波变换[10 ,11 ] 、curvelet变换[12 ] 、非下采样contourlet变换[13 ,14 ] 、sheartlet变换[15 ] 、非下采样sheartlet变换[16 ] .与基于CS的方法相比,基于MRA的方法将提取到的全色图像的细节信息注入到多光谱图像中能够更好地保持光谱特性.稀疏表示的核心思想是将图像表示为一个过完整字典中最少原子的线性组合,但是该方法比较复杂和费时[17 ] . ...
Spatial methods for multispectral pansharpening:Multiresolution analysis demystified
1
2016
... 传统的图像融合方法主要有成分替代(component substitution,CS)[3 ] 、多分辨率分析(multiresolution analysis,MRA)[4 ] 和稀疏表示(spare representation,SR)[5 ] .CS融合方法首先将多光谱图像(multispectral,MS)转化到另一个空间,将空间结构和光谱信息分离为不同的成分; 然后,将转化后的MS图像中具有空间结构的分量替换为全色图像(panchromatic,PAN).经典的基于CS的融合方法包括强度-色调-饱和度(intensity-hue-saturation,IHS)融合方法[6 ] 、主成分分析(principal component analysis,PCA)融合方法[7 ] 和施密特正交化方法(gram-schmidt,GS)[8 ] .基于CS的方法可以获得丰富的细节,但光谱失真往往比较严重.MRA融合方法的核心是多尺度细节提取和注入.通常采用MRA方法从PAN图像中提取空间细节,然后将其注入上采样的多光谱图像中.广泛使用的MRA方法包括拉普拉斯金字塔[9 ] 、小波变换[10 ,11 ] 、curvelet变换[12 ] 、非下采样contourlet变换[13 ,14 ] 、sheartlet变换[15 ] 、非下采样sheartlet变换[16 ] .与基于CS的方法相比,基于MRA的方法将提取到的全色图像的细节信息注入到多光谱图像中能够更好地保持光谱特性.稀疏表示的核心思想是将图像表示为一个过完整字典中最少原子的线性组合,但是该方法比较复杂和费时[17 ] . ...
Remote sensing image fusion using the curvelet transform
1
2007
... 传统的图像融合方法主要有成分替代(component substitution,CS)[3 ] 、多分辨率分析(multiresolution analysis,MRA)[4 ] 和稀疏表示(spare representation,SR)[5 ] .CS融合方法首先将多光谱图像(multispectral,MS)转化到另一个空间,将空间结构和光谱信息分离为不同的成分; 然后,将转化后的MS图像中具有空间结构的分量替换为全色图像(panchromatic,PAN).经典的基于CS的融合方法包括强度-色调-饱和度(intensity-hue-saturation,IHS)融合方法[6 ] 、主成分分析(principal component analysis,PCA)融合方法[7 ] 和施密特正交化方法(gram-schmidt,GS)[8 ] .基于CS的方法可以获得丰富的细节,但光谱失真往往比较严重.MRA融合方法的核心是多尺度细节提取和注入.通常采用MRA方法从PAN图像中提取空间细节,然后将其注入上采样的多光谱图像中.广泛使用的MRA方法包括拉普拉斯金字塔[9 ] 、小波变换[10 ,11 ] 、curvelet变换[12 ] 、非下采样contourlet变换[13 ,14 ] 、sheartlet变换[15 ] 、非下采样sheartlet变换[16 ] .与基于CS的方法相比,基于MRA的方法将提取到的全色图像的细节信息注入到多光谱图像中能够更好地保持光谱特性.稀疏表示的核心思想是将图像表示为一个过完整字典中最少原子的线性组合,但是该方法比较复杂和费时[17 ] . ...
An improved non-subsampled contourlet transform-based hybrid pan-sharpening algorithm
1
2017
... 传统的图像融合方法主要有成分替代(component substitution,CS)[3 ] 、多分辨率分析(multiresolution analysis,MRA)[4 ] 和稀疏表示(spare representation,SR)[5 ] .CS融合方法首先将多光谱图像(multispectral,MS)转化到另一个空间,将空间结构和光谱信息分离为不同的成分; 然后,将转化后的MS图像中具有空间结构的分量替换为全色图像(panchromatic,PAN).经典的基于CS的融合方法包括强度-色调-饱和度(intensity-hue-saturation,IHS)融合方法[6 ] 、主成分分析(principal component analysis,PCA)融合方法[7 ] 和施密特正交化方法(gram-schmidt,GS)[8 ] .基于CS的方法可以获得丰富的细节,但光谱失真往往比较严重.MRA融合方法的核心是多尺度细节提取和注入.通常采用MRA方法从PAN图像中提取空间细节,然后将其注入上采样的多光谱图像中.广泛使用的MRA方法包括拉普拉斯金字塔[9 ] 、小波变换[10 ,11 ] 、curvelet变换[12 ] 、非下采样contourlet变换[13 ,14 ] 、sheartlet变换[15 ] 、非下采样sheartlet变换[16 ] .与基于CS的方法相比,基于MRA的方法将提取到的全色图像的细节信息注入到多光谱图像中能够更好地保持光谱特性.稀疏表示的核心思想是将图像表示为一个过完整字典中最少原子的线性组合,但是该方法比较复杂和费时[17 ] . ...
Improvement of spectral and spatial information using modified WAMM and modified bi-cubic interpolation method in non-subsampled contourlet transform domain
1
2015
... 传统的图像融合方法主要有成分替代(component substitution,CS)[3 ] 、多分辨率分析(multiresolution analysis,MRA)[4 ] 和稀疏表示(spare representation,SR)[5 ] .CS融合方法首先将多光谱图像(multispectral,MS)转化到另一个空间,将空间结构和光谱信息分离为不同的成分; 然后,将转化后的MS图像中具有空间结构的分量替换为全色图像(panchromatic,PAN).经典的基于CS的融合方法包括强度-色调-饱和度(intensity-hue-saturation,IHS)融合方法[6 ] 、主成分分析(principal component analysis,PCA)融合方法[7 ] 和施密特正交化方法(gram-schmidt,GS)[8 ] .基于CS的方法可以获得丰富的细节,但光谱失真往往比较严重.MRA融合方法的核心是多尺度细节提取和注入.通常采用MRA方法从PAN图像中提取空间细节,然后将其注入上采样的多光谱图像中.广泛使用的MRA方法包括拉普拉斯金字塔[9 ] 、小波变换[10 ,11 ] 、curvelet变换[12 ] 、非下采样contourlet变换[13 ,14 ] 、sheartlet变换[15 ] 、非下采样sheartlet变换[16 ] .与基于CS的方法相比,基于MRA的方法将提取到的全色图像的细节信息注入到多光谱图像中能够更好地保持光谱特性.稀疏表示的核心思想是将图像表示为一个过完整字典中最少原子的线性组合,但是该方法比较复杂和费时[17 ] . ...
A new pansharpening method using statistical model and shearlet transform
1
2014
... 传统的图像融合方法主要有成分替代(component substitution,CS)[3 ] 、多分辨率分析(multiresolution analysis,MRA)[4 ] 和稀疏表示(spare representation,SR)[5 ] .CS融合方法首先将多光谱图像(multispectral,MS)转化到另一个空间,将空间结构和光谱信息分离为不同的成分; 然后,将转化后的MS图像中具有空间结构的分量替换为全色图像(panchromatic,PAN).经典的基于CS的融合方法包括强度-色调-饱和度(intensity-hue-saturation,IHS)融合方法[6 ] 、主成分分析(principal component analysis,PCA)融合方法[7 ] 和施密特正交化方法(gram-schmidt,GS)[8 ] .基于CS的方法可以获得丰富的细节,但光谱失真往往比较严重.MRA融合方法的核心是多尺度细节提取和注入.通常采用MRA方法从PAN图像中提取空间细节,然后将其注入上采样的多光谱图像中.广泛使用的MRA方法包括拉普拉斯金字塔[9 ] 、小波变换[10 ,11 ] 、curvelet变换[12 ] 、非下采样contourlet变换[13 ,14 ] 、sheartlet变换[15 ] 、非下采样sheartlet变换[16 ] .与基于CS的方法相比,基于MRA的方法将提取到的全色图像的细节信息注入到多光谱图像中能够更好地保持光谱特性.稀疏表示的核心思想是将图像表示为一个过完整字典中最少原子的线性组合,但是该方法比较复杂和费时[17 ] . ...
The PAN and MS Image pansharpening algorithm based on adaptive neural network and sparse representation in the NSST domain
1
2019
... 传统的图像融合方法主要有成分替代(component substitution,CS)[3 ] 、多分辨率分析(multiresolution analysis,MRA)[4 ] 和稀疏表示(spare representation,SR)[5 ] .CS融合方法首先将多光谱图像(multispectral,MS)转化到另一个空间,将空间结构和光谱信息分离为不同的成分; 然后,将转化后的MS图像中具有空间结构的分量替换为全色图像(panchromatic,PAN).经典的基于CS的融合方法包括强度-色调-饱和度(intensity-hue-saturation,IHS)融合方法[6 ] 、主成分分析(principal component analysis,PCA)融合方法[7 ] 和施密特正交化方法(gram-schmidt,GS)[8 ] .基于CS的方法可以获得丰富的细节,但光谱失真往往比较严重.MRA融合方法的核心是多尺度细节提取和注入.通常采用MRA方法从PAN图像中提取空间细节,然后将其注入上采样的多光谱图像中.广泛使用的MRA方法包括拉普拉斯金字塔[9 ] 、小波变换[10 ,11 ] 、curvelet变换[12 ] 、非下采样contourlet变换[13 ,14 ] 、sheartlet变换[15 ] 、非下采样sheartlet变换[16 ] .与基于CS的方法相比,基于MRA的方法将提取到的全色图像的细节信息注入到多光谱图像中能够更好地保持光谱特性.稀疏表示的核心思想是将图像表示为一个过完整字典中最少原子的线性组合,但是该方法比较复杂和费时[17 ] . ...
Sparse representation based pan-sharpening with details injection model
1
2015
... 传统的图像融合方法主要有成分替代(component substitution,CS)[3 ] 、多分辨率分析(multiresolution analysis,MRA)[4 ] 和稀疏表示(spare representation,SR)[5 ] .CS融合方法首先将多光谱图像(multispectral,MS)转化到另一个空间,将空间结构和光谱信息分离为不同的成分; 然后,将转化后的MS图像中具有空间结构的分量替换为全色图像(panchromatic,PAN).经典的基于CS的融合方法包括强度-色调-饱和度(intensity-hue-saturation,IHS)融合方法[6 ] 、主成分分析(principal component analysis,PCA)融合方法[7 ] 和施密特正交化方法(gram-schmidt,GS)[8 ] .基于CS的方法可以获得丰富的细节,但光谱失真往往比较严重.MRA融合方法的核心是多尺度细节提取和注入.通常采用MRA方法从PAN图像中提取空间细节,然后将其注入上采样的多光谱图像中.广泛使用的MRA方法包括拉普拉斯金字塔[9 ] 、小波变换[10 ,11 ] 、curvelet变换[12 ] 、非下采样contourlet变换[13 ,14 ] 、sheartlet变换[15 ] 、非下采样sheartlet变换[16 ] .与基于CS的方法相比,基于MRA的方法将提取到的全色图像的细节信息注入到多光谱图像中能够更好地保持光谱特性.稀疏表示的核心思想是将图像表示为一个过完整字典中最少原子的线性组合,但是该方法比较复杂和费时[17 ] . ...
Pansharpening by convolutional neural networks
1
2016
... 近年来,基于深度学习的遥感图像融合方法受到了广泛的关注,如以卷积神经网络为基础的融合网络 (pansharpening by convolutional neural networks,PNN)[18 ] ,基于卷积神经网络的目标自适应融合网络(target-adaptive CNN-based pansharpening,Target-PNN)[19 ] ,多尺度多深度卷积神经网络(multi-scale and multi-depth convolutional neural network,MSDCNN)[20 ] ,采用深度网络结构的图像融合(a deep network architecture for pan-sharpening,PanNet)[21 ] ,遥感图像融合深度卷积神经网络(remote sensing image fusion with deep convolutional neural network,RSIFNN)[22 ] ,基于卷积自编码器的MS融合(convolutional autoencoder-based multispectral image fusion,CAE)[23 ] .其中,PNN网络首次在图像融合任务中使用卷积神经网络,其将插值后的多光谱图像和全色图像拼接起来输入网络中进行端对端的训练,网络直接学习输入和高分辨率图像之间的关系; PanNet网络将全色图像和多光谱图像的高频细节信息拼接起来输入到残差网络中进行特征提取与融合,然后将提取到的高频细节信息注入上采样后的低分辨率多光谱图像中.与传统的基于CS和基于MRA的算法相比,基于CNN的方法显著提高了图像融合的性能,但这些方法还存在一些问题,主要有: Target-PNN和RSIFNN都缺乏具体的纹理细节处理,导致融合后的图像纹理细节不够清晰.PNN只是单纯地将全色图像和上采样的多光谱图像输入卷积神经网络进行训练,没有根据全色图像和多光谱图像各自的特点有针对的进行特征提取和融合,可能会导致一些光谱和空间结构的失真.PanNet虽然增强了纹理细节,但没有考虑MS图像光谱通道之间的关系,可能会导致一些光谱失真. ...
Target-adaptive CNN-based pansharpening
1
2018
... 近年来,基于深度学习的遥感图像融合方法受到了广泛的关注,如以卷积神经网络为基础的融合网络 (pansharpening by convolutional neural networks,PNN)[18 ] ,基于卷积神经网络的目标自适应融合网络(target-adaptive CNN-based pansharpening,Target-PNN)[19 ] ,多尺度多深度卷积神经网络(multi-scale and multi-depth convolutional neural network,MSDCNN)[20 ] ,采用深度网络结构的图像融合(a deep network architecture for pan-sharpening,PanNet)[21 ] ,遥感图像融合深度卷积神经网络(remote sensing image fusion with deep convolutional neural network,RSIFNN)[22 ] ,基于卷积自编码器的MS融合(convolutional autoencoder-based multispectral image fusion,CAE)[23 ] .其中,PNN网络首次在图像融合任务中使用卷积神经网络,其将插值后的多光谱图像和全色图像拼接起来输入网络中进行端对端的训练,网络直接学习输入和高分辨率图像之间的关系; PanNet网络将全色图像和多光谱图像的高频细节信息拼接起来输入到残差网络中进行特征提取与融合,然后将提取到的高频细节信息注入上采样后的低分辨率多光谱图像中.与传统的基于CS和基于MRA的算法相比,基于CNN的方法显著提高了图像融合的性能,但这些方法还存在一些问题,主要有: Target-PNN和RSIFNN都缺乏具体的纹理细节处理,导致融合后的图像纹理细节不够清晰.PNN只是单纯地将全色图像和上采样的多光谱图像输入卷积神经网络进行训练,没有根据全色图像和多光谱图像各自的特点有针对的进行特征提取和融合,可能会导致一些光谱和空间结构的失真.PanNet虽然增强了纹理细节,但没有考虑MS图像光谱通道之间的关系,可能会导致一些光谱失真. ...
A multiscale and multidepth convolutional neural network for remote sensing imagery pan-sharpening
1
2018
... 近年来,基于深度学习的遥感图像融合方法受到了广泛的关注,如以卷积神经网络为基础的融合网络 (pansharpening by convolutional neural networks,PNN)[18 ] ,基于卷积神经网络的目标自适应融合网络(target-adaptive CNN-based pansharpening,Target-PNN)[19 ] ,多尺度多深度卷积神经网络(multi-scale and multi-depth convolutional neural network,MSDCNN)[20 ] ,采用深度网络结构的图像融合(a deep network architecture for pan-sharpening,PanNet)[21 ] ,遥感图像融合深度卷积神经网络(remote sensing image fusion with deep convolutional neural network,RSIFNN)[22 ] ,基于卷积自编码器的MS融合(convolutional autoencoder-based multispectral image fusion,CAE)[23 ] .其中,PNN网络首次在图像融合任务中使用卷积神经网络,其将插值后的多光谱图像和全色图像拼接起来输入网络中进行端对端的训练,网络直接学习输入和高分辨率图像之间的关系; PanNet网络将全色图像和多光谱图像的高频细节信息拼接起来输入到残差网络中进行特征提取与融合,然后将提取到的高频细节信息注入上采样后的低分辨率多光谱图像中.与传统的基于CS和基于MRA的算法相比,基于CNN的方法显著提高了图像融合的性能,但这些方法还存在一些问题,主要有: Target-PNN和RSIFNN都缺乏具体的纹理细节处理,导致融合后的图像纹理细节不够清晰.PNN只是单纯地将全色图像和上采样的多光谱图像输入卷积神经网络进行训练,没有根据全色图像和多光谱图像各自的特点有针对的进行特征提取和融合,可能会导致一些光谱和空间结构的失真.PanNet虽然增强了纹理细节,但没有考虑MS图像光谱通道之间的关系,可能会导致一些光谱失真. ...
PanNet:A deep network architecture for pan-sharpening
1
2017
... 近年来,基于深度学习的遥感图像融合方法受到了广泛的关注,如以卷积神经网络为基础的融合网络 (pansharpening by convolutional neural networks,PNN)[18 ] ,基于卷积神经网络的目标自适应融合网络(target-adaptive CNN-based pansharpening,Target-PNN)[19 ] ,多尺度多深度卷积神经网络(multi-scale and multi-depth convolutional neural network,MSDCNN)[20 ] ,采用深度网络结构的图像融合(a deep network architecture for pan-sharpening,PanNet)[21 ] ,遥感图像融合深度卷积神经网络(remote sensing image fusion with deep convolutional neural network,RSIFNN)[22 ] ,基于卷积自编码器的MS融合(convolutional autoencoder-based multispectral image fusion,CAE)[23 ] .其中,PNN网络首次在图像融合任务中使用卷积神经网络,其将插值后的多光谱图像和全色图像拼接起来输入网络中进行端对端的训练,网络直接学习输入和高分辨率图像之间的关系; PanNet网络将全色图像和多光谱图像的高频细节信息拼接起来输入到残差网络中进行特征提取与融合,然后将提取到的高频细节信息注入上采样后的低分辨率多光谱图像中.与传统的基于CS和基于MRA的算法相比,基于CNN的方法显著提高了图像融合的性能,但这些方法还存在一些问题,主要有: Target-PNN和RSIFNN都缺乏具体的纹理细节处理,导致融合后的图像纹理细节不够清晰.PNN只是单纯地将全色图像和上采样的多光谱图像输入卷积神经网络进行训练,没有根据全色图像和多光谱图像各自的特点有针对的进行特征提取和融合,可能会导致一些光谱和空间结构的失真.PanNet虽然增强了纹理细节,但没有考虑MS图像光谱通道之间的关系,可能会导致一些光谱失真. ...
Remote sensing image fusion with deep convolutional neural network
1
2018
... 近年来,基于深度学习的遥感图像融合方法受到了广泛的关注,如以卷积神经网络为基础的融合网络 (pansharpening by convolutional neural networks,PNN)[18 ] ,基于卷积神经网络的目标自适应融合网络(target-adaptive CNN-based pansharpening,Target-PNN)[19 ] ,多尺度多深度卷积神经网络(multi-scale and multi-depth convolutional neural network,MSDCNN)[20 ] ,采用深度网络结构的图像融合(a deep network architecture for pan-sharpening,PanNet)[21 ] ,遥感图像融合深度卷积神经网络(remote sensing image fusion with deep convolutional neural network,RSIFNN)[22 ] ,基于卷积自编码器的MS融合(convolutional autoencoder-based multispectral image fusion,CAE)[23 ] .其中,PNN网络首次在图像融合任务中使用卷积神经网络,其将插值后的多光谱图像和全色图像拼接起来输入网络中进行端对端的训练,网络直接学习输入和高分辨率图像之间的关系; PanNet网络将全色图像和多光谱图像的高频细节信息拼接起来输入到残差网络中进行特征提取与融合,然后将提取到的高频细节信息注入上采样后的低分辨率多光谱图像中.与传统的基于CS和基于MRA的算法相比,基于CNN的方法显著提高了图像融合的性能,但这些方法还存在一些问题,主要有: Target-PNN和RSIFNN都缺乏具体的纹理细节处理,导致融合后的图像纹理细节不够清晰.PNN只是单纯地将全色图像和上采样的多光谱图像输入卷积神经网络进行训练,没有根据全色图像和多光谱图像各自的特点有针对的进行特征提取和融合,可能会导致一些光谱和空间结构的失真.PanNet虽然增强了纹理细节,但没有考虑MS图像光谱通道之间的关系,可能会导致一些光谱失真. ...
Convolutional autoencoder-based multispectral image fusion
1
2019
... 近年来,基于深度学习的遥感图像融合方法受到了广泛的关注,如以卷积神经网络为基础的融合网络 (pansharpening by convolutional neural networks,PNN)[18 ] ,基于卷积神经网络的目标自适应融合网络(target-adaptive CNN-based pansharpening,Target-PNN)[19 ] ,多尺度多深度卷积神经网络(multi-scale and multi-depth convolutional neural network,MSDCNN)[20 ] ,采用深度网络结构的图像融合(a deep network architecture for pan-sharpening,PanNet)[21 ] ,遥感图像融合深度卷积神经网络(remote sensing image fusion with deep convolutional neural network,RSIFNN)[22 ] ,基于卷积自编码器的MS融合(convolutional autoencoder-based multispectral image fusion,CAE)[23 ] .其中,PNN网络首次在图像融合任务中使用卷积神经网络,其将插值后的多光谱图像和全色图像拼接起来输入网络中进行端对端的训练,网络直接学习输入和高分辨率图像之间的关系; PanNet网络将全色图像和多光谱图像的高频细节信息拼接起来输入到残差网络中进行特征提取与融合,然后将提取到的高频细节信息注入上采样后的低分辨率多光谱图像中.与传统的基于CS和基于MRA的算法相比,基于CNN的方法显著提高了图像融合的性能,但这些方法还存在一些问题,主要有: Target-PNN和RSIFNN都缺乏具体的纹理细节处理,导致融合后的图像纹理细节不够清晰.PNN只是单纯地将全色图像和上采样的多光谱图像输入卷积神经网络进行训练,没有根据全色图像和多光谱图像各自的特点有针对的进行特征提取和融合,可能会导致一些光谱和空间结构的失真.PanNet虽然增强了纹理细节,但没有考虑MS图像光谱通道之间的关系,可能会导致一些光谱失真. ...
Squeeze-and-excitation networks
1
2020
... 注意力机制源于对人类视觉的研究,在认知学中,人类会有选择地关注所有信息的一部分,同时忽略其他可见信息.该思想最早应用在自然语言的处理中.后来,研究者提出了注意力机制模型(squeeze-and-excitation networks,SENet),该模型通过对输入的信息进行挤压、激励和特征重标定,对每个特征通道赋予不同的权重[24 ] .该网络结构被广泛应用于目标检测、图像分类等任务中,取得了很好的效果.在图像融合任务中,需要通过神经网络对全色和多光谱图像的所有特征进行融合操作,但是这样会产生大量的冗余信息,如何更准确高效地融合特征信息成为了一个亟待解决的问题.注意力机制则可以通过对特征赋予权重来解决这个问题. ...
1
2019
... 先验知识是人们通过经验或者数理统计等方法得到的对于事物特性的描述,被广泛应用于自然图像去模糊、自然图像去噪中[25 ] .常用的自然图像先验知识有自然图像的局部平滑性、非局部自相似性、稀疏性等特征.受自然图像先验知识的启发,考虑到归一化植被指数(normalized difference vegetation index,NDVI)能够反映土地植被的分布信息,归一化水指数(normalized difference water index,NDWI)反映了水体的分布信息,而植被和水体是能够影响光谱的两种主要信息.所以,我们利用这两种信息作为先验知识,对遥感影像的融合过程进行约束,可以进一步提高融合效果,改善光谱失真的问题. ...
1
2019
... 先验知识是人们通过经验或者数理统计等方法得到的对于事物特性的描述,被广泛应用于自然图像去模糊、自然图像去噪中[25 ] .常用的自然图像先验知识有自然图像的局部平滑性、非局部自相似性、稀疏性等特征.受自然图像先验知识的启发,考虑到归一化植被指数(normalized difference vegetation index,NDVI)能够反映土地植被的分布信息,归一化水指数(normalized difference water index,NDWI)反映了水体的分布信息,而植被和水体是能够影响光谱的两种主要信息.所以,我们利用这两种信息作为先验知识,对遥感影像的融合过程进行约束,可以进一步提高融合效果,改善光谱失真的问题. ...
Evaluation of pan-sharpening methods for spatial and spectral quality
1
2016
... 客观评价指标可以定量地评价融合图像的质量情况,尤其是在图像的一些微小的细节,仅仅依靠人眼很难发现图像的优劣,而采用客观评价指标,则可以通过数值的大小定量地评价图像的好坏.因此,本文选择峰值信噪比(peak signal to noise ratio,PSNR)[26 ] 、结构相似性指数(structural similarity,SSIM)[27 ] 和光谱映射角(spectral angle mapper,SAM)[28 ] 3种评价指标对融合结果进行定量评价,从不同的方面对图像的质量进行评估. ...
干旱区Landsat8全色与多光谱数据融合算法评价
1
2019
... 客观评价指标可以定量地评价融合图像的质量情况,尤其是在图像的一些微小的细节,仅仅依靠人眼很难发现图像的优劣,而采用客观评价指标,则可以通过数值的大小定量地评价图像的好坏.因此,本文选择峰值信噪比(peak signal to noise ratio,PSNR)[26 ] 、结构相似性指数(structural similarity,SSIM)[27 ] 和光谱映射角(spectral angle mapper,SAM)[28 ] 3种评价指标对融合结果进行定量评价,从不同的方面对图像的质量进行评估. ...
干旱区Landsat8全色与多光谱数据融合算法评价
1
2019
... 客观评价指标可以定量地评价融合图像的质量情况,尤其是在图像的一些微小的细节,仅仅依靠人眼很难发现图像的优劣,而采用客观评价指标,则可以通过数值的大小定量地评价图像的好坏.因此,本文选择峰值信噪比(peak signal to noise ratio,PSNR)[26 ] 、结构相似性指数(structural similarity,SSIM)[27 ] 和光谱映射角(spectral angle mapper,SAM)[28 ] 3种评价指标对融合结果进行定量评价,从不同的方面对图像的质量进行评估. ...
A critical comparison among pansharpening algorithms
1
2015
... 客观评价指标可以定量地评价融合图像的质量情况,尤其是在图像的一些微小的细节,仅仅依靠人眼很难发现图像的优劣,而采用客观评价指标,则可以通过数值的大小定量地评价图像的好坏.因此,本文选择峰值信噪比(peak signal to noise ratio,PSNR)[26 ] 、结构相似性指数(structural similarity,SSIM)[27 ] 和光谱映射角(spectral angle mapper,SAM)[28 ] 3种评价指标对融合结果进行定量评价,从不同的方面对图像的质量进行评估. ...









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}