

0 引言
目前对于高空间分辨率遥感影像桥梁检测的方法主要分为两类。一类是基于图像处理的传统方法。Lomenie N等[8]结合空间关系准则检测高分影像中的桥梁,该方法错检率低,但漏检率较高; 杨浩等[9]结合遥感图像的成像特点识别桥梁目标,但是此算法只针对水域上的桥梁,对于陆地上桥梁的检测不能达到很好的效果; 陈爱军[10]提出了一种基于极化圆周SAR图像的路上桥梁检测方法,解决了传统桥梁检测方法需要基于河流提取结果才能实现桥梁检测的问题。第二类是基于深度学习的目标检测方法。Chen L等[7]提出了基于平衡和注意力机制的SAR图像桥梁自动检测网络,极大提高了检测精度。但是利用深度学习对光学遥感影像的桥梁进行检测的相关报道较少。针对传统方法泛化能力差、鲁棒性低的问题,基于深度学习[11]的目标检测算法逐渐兴起,其主要分为两类: 一类是将目标检测过程分为特征提取和目标定位两部分的两阶段目标检测算法,如R-CNN[12],Fast R-CNN[13],Faster R-CNN[14]等; 第二类是将特征提取和定位一体化处理的单阶段目标检测算法,如SSD[15],YOLO系列[16⇓-18]等。YOLOv4[19]将分类和回归在同一深度卷积网络中实现,训练过程简单、占用物理空间小,与其他算法相比具有更高的检测精度。
上述算法仍存在一些未能解决的问题: ①传统桥梁检测方法大多针对河流水体设计特征,对于陆地上桥梁或干涸水域上的桥梁检测效果差; ②YOLOv4方法预设的锚框尺寸根据自然图像公开数据集中的目标聚类得到,由于遥感影像与自然图像存在较大差异,其尺寸较大,背景复杂,且待测目标尺度分布范围广,因此预设锚框的尺寸并不完全适用于遥感影像目标检测任务; ③利用深度学习的桥梁检测方法需要大量的训练样本,对于小样本数据集的训练和检测具有一定难度。④遥感影像成像条件各异,存在目标被云雾遮挡的现象,以往的目标检测方法没有充分考虑到这种情况,导致检测结果不理想。
针对以上问题,本文提出结合随机擦除和YOLOv4的高空间分辨率遥感影像桥梁自动检测方法: 首先,采用YOLOv4目标检测方法对桥梁数据集进行训练并检测,以解决传统方法的人工设计特征难以适用于多场景下桥梁检测任务的问题; 然后采用k-means聚类方法,统计高空间分辨率遥感影像梁数据集中所有目标的尺寸,并进行聚类分析,得到适合于遥感影像桥梁目标检测的锚框; 再引入随机擦除(random erase, RE)数据增强方法,在遥感影像上随机选择矩形区域并擦除; 最后,对擦除后的影像进行训练,这样既能扩充数据集,又能解决云雾遮挡桥梁检测精度低的问题,以此提高检测精度。
1 研究方法
为了解决训练数据较少,且传统方法对于被云雾遮挡目标检测精度低的问题,本文首先统计数据集中目标的尺度分布范围,利用k-means聚类方法匹配合适的锚框尺寸; 然后用RE与Mosaic数据增强方法相结合对训练数据集进行预处理; 再利用YOLOv4网络训练处理后的数据集; 最后对检测结果进行精度评价。具体技术路线如图1所示。
图1
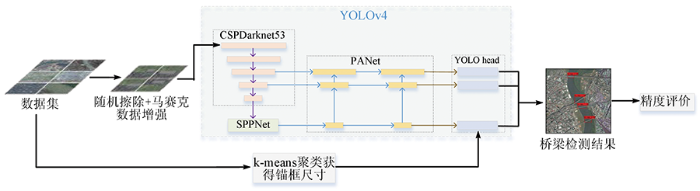
1.1 数据集及尺度统计
1.1.1 数据集介绍
图2

1.1.2 尺度统计
高空间分辨率遥感卫星成像过程因受环境条件的影响,生成的影像内容复杂,不同时段的影像辐射差异大,且目标尺度分布不均匀。因此同一尺寸的预定义锚框难以满足不同尺度桥梁检测的需求。YOLOv4预设了9个锚框,大小为Anchor box=(12,16; 19,36; 40,28; 36,75; 76,55; 72,146; 142,110; 192,243; 459,401)分别针对76×76,38×38以及19×19这3个不同的尺度进行检测。以上锚框尺寸是根据VOC数据集目标框聚类得到的,但是并不适用于所有类型的目标检测任务。
为了充分统计桥梁数据集中目标的尺度范围,本文使用k-means聚类方法,对数据集中的2 000张高空间分辨率遥感影像进行统计。将所有桥梁的尺度分为9个类,首先随机选择数据中心的9个点作为质心; 然后将与之靠近的点进行分类; 不断迭代更新这9个点的值,直到这9个点的值不再变化为止; 最后分别设置为预定义锚框的大小。表1为k-means聚类所得的预测框尺度。
表1 k-means聚类结果
Tab.1
| 序号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| x | 19 | 24 | 28 | 36 | 55 | 64 | 108 | 116 | 200 |
| y | 16 | 76 | 34 | 173 | 25 | 56 | 382 | 37 | 129 |
1.2 数据增强
当模型中参数相对于训练样本过多时,就会发生过拟合现象,从而降低模型的泛化能力。遮挡是影响模型泛化能力的关键因素。现用于桥梁检测模型的训练数据集较小,且部分影像中含有被云雾遮挡的桥梁。因此实现不同层次的遮挡不变性是解决这一问题的有效方法。为了使桥梁的某些部分被云雾遮挡时,模型仍然能够从整体结构中将其正确检测出来,本文引入了RE数据增强,与YOLOv4本身的Mosaic数据增强相结合以扩充原有数据集并模拟桥梁被云雾遮挡的情况。RE数据增强[21]随机选取影像上的一个矩形区域,只遮挡部分对象,能够维护对象的整体结构,且将被擦除区域的像素值重新赋值为随机值,亦可看作给图像添加了块噪声。该方法能够有效加大训练难度,防止过拟合,在一定程度上提高泛化能力。利用RE数据增强方式主要是模拟遮挡场景,应用在桥梁检测中即可模拟桥梁被云雾遮挡的情况,与YOLOv4本身的Mosaic数据增强相结合,使网络具有更好的鲁棒性。
图3为RE数据增强流程图。影像中随机选择一个矩形区域
图3
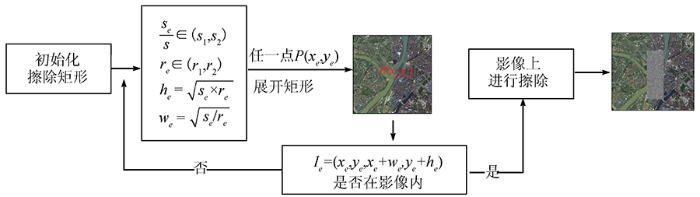
随机擦除的优势可以概括为以下几点:
1)随机擦除过程是在一个连续的矩形区域上操作、没有舍弃任何像素值,不会引起信息丢失,目的是使模型对噪声和遮挡具有更好的鲁棒性。
2)随机擦除可以在不改变原有学习策略的情况下应用于基于卷积神经网络的目标检测任务。
3)可以作为现有数据增强方法的补充,与其他数据增强方法相结合,能进一步提高目标检测性能。
1.3 YOlOv4网络结构
YOLOv4[19]是由Bochkovskiy等于2020年提出的单阶段目标检测网络,该网络的主干为CSPDarknet53,由5个CSPnet[22]模块组成,每个CSPnet模块前面都是大小为3×3,步长为2的卷积核,可以起到下采样的作用,因此大小为608像素×608像素的输入图像被逐步下采样为19×19的特征图。CSPDarknet53解决了因梯度信息重复导致的推理计算过高的问题,增强了CNN的学习能力,使得网络在轻量化的同时保持准确性,且能有效的降低内存成本及计算瓶颈。SPP模块使用不同尺寸的滑动窗口对上一个卷积层获得的特征图进行采样,分别合并得到的结果,就会得到固定长度的输出; FPN层自顶向下传达强语义特征,而包含2个PAN结构的特征金字塔则自底向上传达强定位特征,两者结合,从不同的主干层对不同的检测层进行特征聚合,进一步提高特征提取的能力。
1.4 CIoU_Loss模型
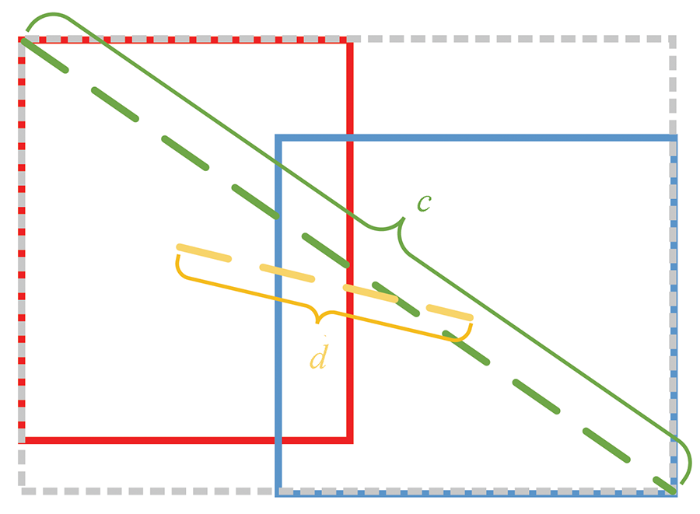
遥感影像中的桥梁存在着多桥密集并行的现象,并行桥梁之间的锚框会有所重叠,非极大抑制过程会剔除部分锚框导致漏检,采用CIoU能够有效解决这一问题。寻常的IoU_Loss无法直接优化预测框和真实框没有重叠的部分,CIoU将目标与锚框之间的重叠区域、中心距离、宽高比都考虑进去,使得目标回归更加稳定,不会出现训练过程中发散等问题。如图4所示,c为预测框b与真实框bgt的最小外接矩形的对角线距离; d为预测框与真实框中心点之间的距离。IoU为预测框和真实框面积交集与面积并集的比值。
图4
CIoU公式如下:
式中,
所以CIoU_Loss为:
式中: b为预测框; bgt为真实框; ρ2(b,bgt)为预测框和真实框之间的欧氏距离; c为能够同时包含预测框和真实框的最小闭包区域对角线长度; w和h分别为预测框的宽和高; wgt和hgt分别为真实框的宽和高。
2 实验结果与分析
本文方法使用GPU进行训练,计算机配置为Windows10,Intel(R)i7-9700k CPU,NVIDIA GeForce GTX1070 Ti显卡,8 GB显存,平台为pytorch。训练的初始学习率设置为0.001,权重衰减系数设置为0.000 5,训练动量为0.9,置信度设置为0.5,IoU阈值设置为0.5,训练300个Epoch,迭代次数4 000次。用随机数法将数据集按照8∶2的比例分配为训练集、验证集,抽取典型桥梁影像作为测试集。
为了验证本文方法的有效性,利用目标的平均检测精度(mAP)以及平均检测准确度(average detection accuracy,Ada)作为模型定量的评估指标,来衡量模型的准确性,其定义为:
式中: Precision为精确率,指实际正样本占被预测为正样本的比例; TP为被正确分类的正样本,即被正确检测的桥梁数量; FP为被错误分类的负样本,即被检测为桥梁的其他目标的数量; PrecisionC为C类目标的精确率; NC为含有C类目标的图片的数量; N为数据集中图片的总数。
平均检测准确度(Ada)为检测样本的总准确度(detection accuracy,DA)与正确检测样本数之商,总准确度为单幅图像中所有被正确检测目标的准确度之和,计算公式如下:
表2 不同模型的检测结果
Tab.2
| 模型 | 网络 | +RE | 涨点 | 本文涨点 |
|---|---|---|---|---|
| SSD | 61.09 | 66.82 | 5.73 | 35.97 |
| Mobilenet-SSD | 66.56 | 70.23 | 3.67 | 30.50 |
| Centernet | 82.07 | 84.28 | 2.21 | 14.99 |
| Efficientdet | 76.67 | 76.44 | 1.77 | 20.39 |
| Retinanet | 78.23 | 80.12 | 1.89 | 18.83 |
| YOLOv3 | 93.82 | 95.66 | 1.84 | 3.24 |
| YOLOv4 | 94.07 | 97.06 | 2.99 | 2.99 |
由表2可知,①在引入了RE方法之后,各网络mAP涨点从1.77%到5.73%不等,说明RE数据增强可以与不同目标检测方法相结合,并有效提升检测精度; ②本文方法与其他6种方法相比,mAP都有较大程度的提高,验证了本文选取YOLOv4作为原始网络的可行性; ③其中RE数据增强(本文所提算法)能够选择影像上的随机区域进行擦除,有效模拟了桥梁目标被云雾遮挡的情况,提升了整体的检测精度。由此可知,对场景较单一、且数据量小的数据集进行数据增强对提高模型检测的精度有一定积极作用。
图5
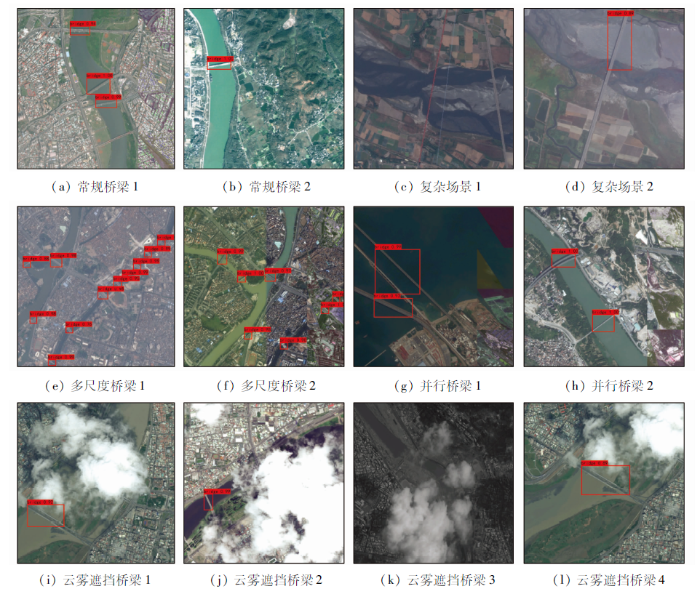
图6
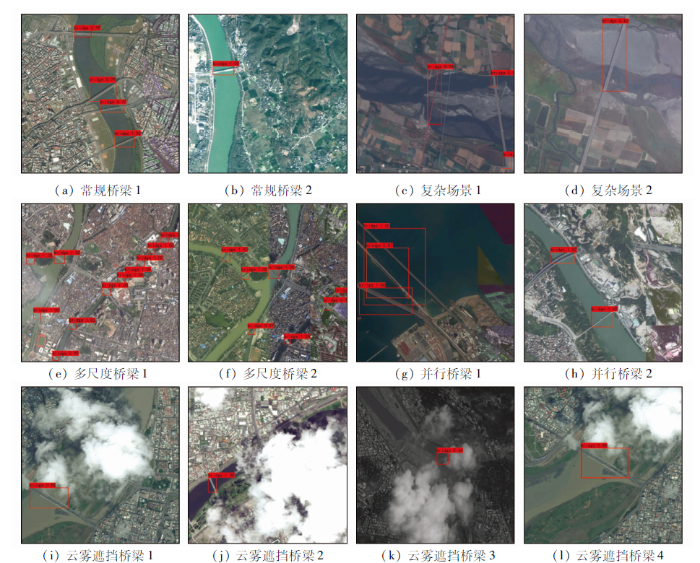
图7
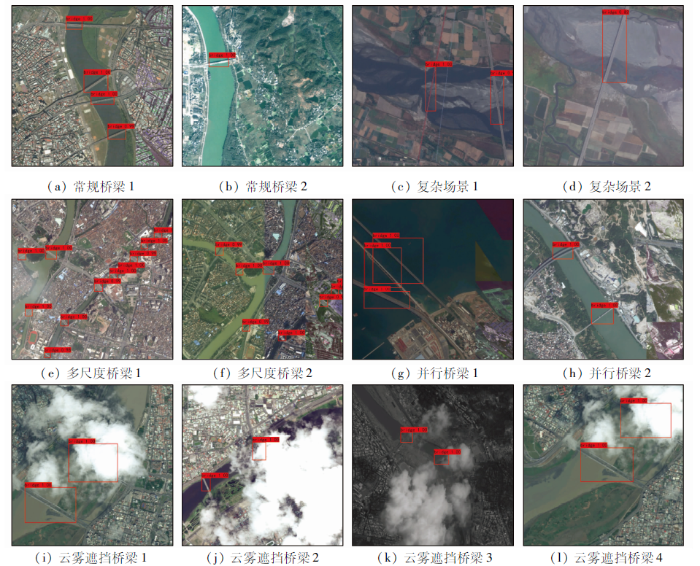
表3 样例检测结果
Tab.3
| 模型 | 常规 | 复杂 背景 | 多尺度 | 并行 | 云雾 遮挡 | |
|---|---|---|---|---|---|---|
| 共含桥梁/个 | 5 | 3 | 19 | 6 | 8 | |
| 正确检出/个 | YOLOv3 | 4 | 1 | 18 | 4 | 3 |
| YOLOv4 | 5 | 2 | 18 | 5 | 4 | |
| 本文方法 | 5 | 3 | 19 | 5 | 8 | |
| 平均检测准确度/% | YOLOv3 | 98.25 | 89.00 | 95.81 | 98.00 | 93.33 |
| YOLOv4 | 94.20 | 88.00 | 99.70 | 97.40 | 88.00 | |
| 本文方法 | 99.80 | 99.50 | 99.59 | 100.00 | 100.00 | |
由表3可知,相比于YOLOv3和YOLOv4,本文方法对于不同场景下桥梁的正确检测个数均有提高,说明本文方法具有较好的桥梁检测能力; 其次,本文方法对于云雾遮挡桥梁的检测效果明显优于其他2种方法,YOLOv3和YOLOv4仅能检测出薄云覆盖和部分遮挡桥梁,对于完全遮挡和厚云覆盖等桥梁检测效果较差,而本文方法能能够以较高准确度检测出部分遮挡、完全遮挡、厚云覆盖及薄云覆盖等多种条件下的桥梁,有效提高了对于云雾遮挡桥梁检测的鲁棒性; 最后,本文方法在绝大多数场景下的平均检测准确度高于YOLOv3和YOLOv4,说明本文方法在保证检测效果的前提下适用于多种场景的桥梁检测。
3 结论与展望
针对传统目标检测网络识别被云雾遮挡桥梁能力差的问题,提出结合RE和YOLOv4桥梁自动检测方法。本文方法的mAP达到了97.06%,较YOLOv4网络提高了2.99百分点。对于被云雾遮挡桥梁的平均检测准确度提高了12百分点。试验结果验证了本文方法对于识别复杂场景下的桥梁、多尺度的桥梁、并行桥梁尤其是被云雾遮挡的桥梁有很大的优势。但本文方法也存在不足之处,RE产生的像素值与真实云雾有一定差异,使得检测效果提升有一定局限性,后期将对遮挡桥梁设计更有针对性的方法,进一步提高检测性能。
参考文献
Detection and segmentation of man-made objects in outdoor scenes:Concrete bridges
[J].
一种基于极化圆周SAR图像的陆上桥梁提取方法
[J].
A method of land bridge extraction based on polarized circumferential SAR image
[J].
深度学习的遥感影像舰船目标检测
[J].
Deep learning for ship target detection in remote sensing images
[J].
基于深度学习的国产高分遥感影像飞机目标自动检测
[J].
Automatic detection of aircraft targets in domestic high-resolution remote sensing images based on deep learning
[J].
基于Mask R-CNN的无人机影像路面交通标志检测与识别
[J].
Detection and recognition of traffic signing based on Mask R-CNN image using UAV
[J].
A new deep learning network for automatic bridge detection from SAR images based on balanced and attention mechanism
[J].DOI:10.3390/rs12030441 URL [本文引用: 2]
Integrating textural and geometric information for an automatic bridge detection system
[C]//
高分辨率遥感图像中桥梁自动识别方法研究
[J].
Research on automatic bridge identification method in high resolution remote sensing images
[J].
大幅面卫星遥感图像中桥梁识别算法
[J].
Bridge recognition algorithm in large-scale satellite remote sensing images
[J].
Deep learning
[J].DOI:10.1142/S1793351X16500045 URL [本文引用: 1]
Rich feature hierarchies for accurate object detection and semantic segmentation
[C]//
Fast R-CNN
[C]//
Faster R-CNN:Towards real-time object detection with region proposal networks
[J].DOI:10.1109/TPAMI.2016.2577031 URL [本文引用: 1]
Ssd:Single shot multibox detector
[J].
You only look once:Unified,real-time object detection
[C]//
YOLO9000:Better,faster,stronger
[C]//
YOLOv3:An incremental improvement
[EB/OL].(
Yolov4:Optimal speed and accuracy of object detection
[J].
2020 Gaofen challenge on automated high-resolution earth observation image interpretation
[EB/OL]. Online: http://en.sw.chreos.org.
Random erasing data augmentation
[J].DOI:10.1609/aaai.v34i07.7000 URL [本文引用: 1]
CSPNet:A new backbone that can enhance learning capability of CNN
[C]//

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}