

0 引言
近20 a来,遥感影像处理专家也发展出了许多基于像元的传统提取方法,Work等[3]通过研究MSS影像发现水体在近红外波段上的反射率较低,利用这一特性人为的设定一个较小的阈值来进行水陆分离,被称为单波段方法。多波段方法是Frazier等[4]在研究澳大利亚湖泊时使用TM影像对比分析了TM4,TM5,TM7这3个波段的提取效果,并利用多波段融合的方法通过设置不同阈值提高了分割精确度,但依旧受到噪声的干扰。近期,被广泛认可的水体指数方法,是由McFeeters[5]受到归一化差异植被指数(normalized difference vegetation index,NDVI)的启发,总结并提出了基于绿光波段与近红外波段的归一化差异水体指数(normalized difference water index,NDWI)[6],可有效减少噪声和阴影。其后由Xu[7]在考量建筑物与土壤的波段特性后进行了优化,将近红外波段改为中红外波段,并命名为MNDWI,消除了大部分噪声的影响,但人为观测设定的阈值依旧存在缺陷,因此在地物信息复杂的实际应用中提取精确度并不高。
近些年,随着人工智能算法的发展,深度学习为计算机视觉和图像识别等领域带来了猛烈冲击,其目标分类与识别和追踪技术甚至能与人类识别性能相媲美[8⇓-10]。在Long等[11]提出了全卷积神经网络(fully convolutional networks,FCN)结构后,卷积神经网络分类任务正式进入到像素级别,拓展到语义分割领域。当然就高分辨率遥感影像分割而言,由于其地表目标具有尺度效应,综合高分辨率遥感影像具有丰富的纹理结构信息,需要多尺度图像的分割方法,但从低层次特征到高层次语义鸿沟,实现高分辨率遥感影像语义分割依旧是具有挑战的问题。近期,基于机器学习的遥感影像水体提取任务也开始受到了关注,许玥[12]在传统U-Net深度学习网络上加入条件随机场对水体变迁进行预测。但是目前的方法仅仅使用深度学习进行深层数据的挖掘而无法解释深层特征对于最终结果判断的影响,引入注意力机制可以在结合深层和浅层特征的同时提供更好的可解释性。
因此,本文将研究基于深度学习的高分辨率遥感影像中水体的语义分割。利用深度学习强大的特征表达能力,尝试构造从底层特征到对象语义的映射,同时考虑多尺度特征的监测问题,并适时地引入注意力机制,提升对于中间特征的通道方向以及空间区域上重要区域的关注度,在重要的通道与空间区域块上将会提高响应值,通过激活模块后重要部分对于最终水体分类的影响将提高,弥补纯卷积神经网络无法关注到细节区域分类的缺陷,提高语义分割时关注原始信息中重要部分的可能性。
1 数据集预处理与标注
本实验数据集使用高分六号(GF-6)遥感卫星获取长江三角洲某地区包含水体的4个波段(红光波段、绿光波段、蓝光波段、红外波段)影像,由于目前深度学习卷积网络模型一般只使用三通道图像进行语义分割,因此首先使用eCognition软件对原始遥感影像进行合并,然后根据遥感影像特点,以及后续使用传统指数方法提取水体信息(NDWI)时需要使用红外波段(IR),生成22 953像素×17 605像素大小的IRRG(红外波段、红光波段、绿光波段)PNG三通道图像进行存储。由于遥感影像传感器原因,使用Python对影像进行预处理,减少噪声对语义分割模型识别造成的影响,最终得到完成几何纠正的影像。
本次研究使用eCognition软件对遥感影像进行水陆标注,这是一种基于目标对象的分类方法,因其能够充分利用遥感影像的光谱、纹理、形状、空间信息和相邻关系等特征进行分割分类,所以精度相对较高,能够接近于人工目视解释的精确度(通常情况下语义分割将目视解释图像作为分割的标准影像)。使用eCognition软件选取合适的分割尺度对影像进行分割,使检测的地物能在最合适的分割尺度中突显出来; 选取分割对象的多种典型特征建立地物的分类规则进行检测或分类本文根据不同影像的特征使用不同的尺度参数和形状参数对地物信息进行分割。最终得到如图1所示的标注图像。水体提取语义分割任务作为二分类问题,标注结果(Ground truth)最终转换成灰度图,将背景的颜色通道设置为0,而水体部分设置为1。
图1

2 研究方法
2.1 注意力模块
2.1.1 通道级联空间注意力模型概述
注意力模块目前已经成为了深度学习处理中重要的概念,最初被用于机器翻译,最终在深度学习领域中的自然语言处理、计算机视觉以及图神经网络被广泛使用[15]。
本文尝试将注意力机制引入到遥感影像语义处理中的解码部分,应用于卷积神经网络的注意力模块主要包含通道注意力(channel attention)以及空间注意力(spatial attention)2部分,将这2类注意力处理方法级联形成新的注意力模块,并将其命名为S&CMNet。遥感影像通过主干网络特征提取映射后输入到通道注意力模块,在通道上提升网络对特定通道关注度,对通道特征进行细化。将细化后的通道特征图输入到空间注意模块中,同时空间域上学习关注点,提取重要局部信息。最后通过大量卷积层及池化层后最终连接SoftMax分类器得到语义分割结果。
2.1.2 特征提取结构
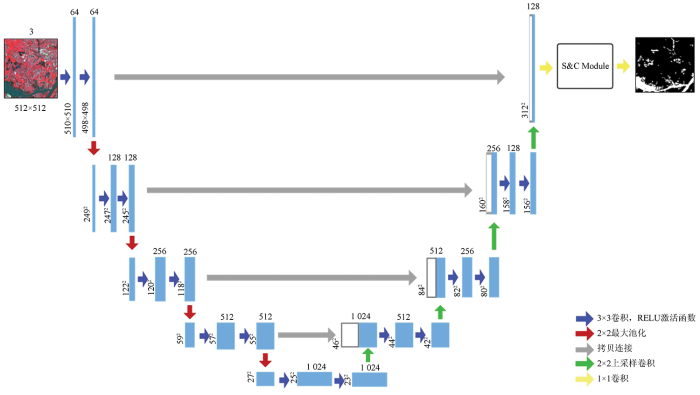
研究过程中对于编码器部分的特征提取骨干网络主要是使用了目前在计算机视觉领域以及语义分割领域取得较好效果的ResNet101和U-Net。本次研究对于ResNet101进行了一定改进,使用了空洞卷积操作,最终得到原图像1/8大小的特征映射图。在特征提取最后一层中并不直接进行语义推理,而是将最后一层特征图输入注意模块进行特征细化,从而更好地学习特征表达。图2为S&CMNet概览图,图中C,H,W分别代表特征图通道数、高度与宽度。
图2
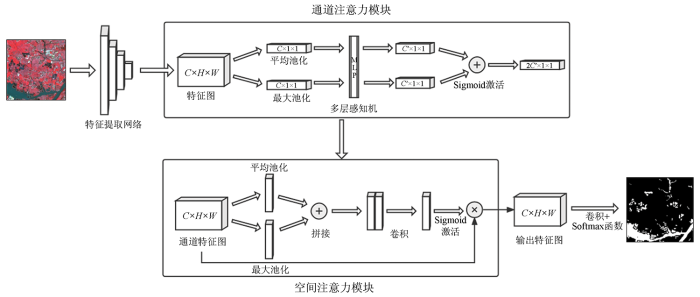
2.2 混合注意力模块
2.2.1 通道注意力模块
高分遥感影像输入特征提取骨干网络通过C核卷积操作之后得到多通道特征图
通道注意力模块的目的是利用每个信道之间的关系特征映射学习一个权值
1)Squeeze模块目的为降低每个通道的信息维度,聚合空间维度信息。池化操作,见式(1)和(2),为每个通道生成2个特征描述符,输入含有隐层的1×1卷积核组成的多层感知器,生成更具有代表性的特征向量,即
式中: Zc1为平均上采样之后生成的更具代表性的通道特征向量; Zc2为最大上采样之后生成的更具代表性的通道特征向量; Fsq为上采样函数; uc为输入通道注意力模块的特征图。
2)Excitation模块主要是通过利用Sigmoid函数,对于Squeeze模块得到的特征进行激活,得到最终的通道注意图。公式为:
式中: Wc为生成的特征权重; Sigmoid为激活函数; MLP为多层感知机组成的线性分类层。
3)Attention模块将最后生成的特征权重与输入的特征图向量相乘,本质上是缩放的过程,从而增强对关键通道的注意力。计算公式为:
式中: Fscale为缩放及特征权重融合函数;
2.2.2 空间注意力模块
空间域注意力模块关注的是对当前任务更具有价值的空间区域,级联在通道注意力模块之后,是对通道注意力的补充。以遥感影像为例,使用空间注意力模块有助于聚合空间信息,特别是对小型地物信息进行处理。
空间注意力模块以通道注意力模块输出的特征图
式中: Zs1为平均上采样之后生成的更具代表性的空间特征向量; Zs2为最大上采样之后生成的更具代表性的空间特征向量。
Excitation模块公式为:
式中: Ms为经过卷积融合后的通道特征;
Attention模块公式为:
式中U为通过所有注意力模块后最终得到的特征图。
S&CMNet模型的混合注意力模块部分参数量非常少,可以忽略,空间注意力模块的参数个数甚至只有98个。除此之外本次实验只在特征提取主干网络的末端层增加了注意模块,因此仅为网络少量增加了计算的复杂度[16]。
2.3 实验流程
为了评估所使用的不同模型方法之间的性能,引入语义分割较为常见的语义分割准确率指标,包括平均交叉合并比(mean intersection over union,mIoU)、F1-Score和像素准确率(pixel accuracy,PA)以及一个图像预测速度指标TIME[17]。
考虑到实验过程中,同时将标记数据集按照7:2:1的比例分为3部分,其中70%的数据用于模型训练,20%的数据用于观察模型效果,10%数据用于最终模型图像预测,验证模型效果。
使用NDWI作为传统方法的对比基线,实验过程使用ENVI 5.3软件在i7-9750H CPU以及NVIDIA 1660 TI GPU设备上进行,阈值设定范围为0.2~1.0之间为水体。基于深度学习模型学习过程,为防止U-Net模型编码器结构以及ResNet101主干网络对于实验的影响,从头开始训练U-Net,SegNet,PSPNet以及DeepLabV3+模型[18⇓-20],用以进行消融对比试验。S&CMNet模块实验部分,通过实验优选,分别选择ResNet101和U-Net编码器为特征提取主干训练,并分别命名为S&CMNet V1和S&CMNet V2,模型架构如图3所示。网络均未单独设置学习率,使用默认的1e-3,采用Adam作为优化器,进行自适应性的学习率更新方法,交叉熵作为损失函数,考虑到二分类语义分割任务训练轮次过多会造成过拟合现象,因此模型训练轮次初始设定均为100轮。同时将U-Net相关网络批次、大小(Batch Size)设置为4,将其他Batch设置为8。所有深度网络模型均在Pytorch平台上实现,用NVIDIA 2080Ti GPU来进行实验[8]。
图3
3 实验结果分析
表1列出了本文模型在所设计数据集上的分割结果,其中100-1表示预测每一百张512×512大小的图需要花费的时间。从表1中实验结果可以看出,与传统遥感图像水体检测方法NDWI相比,使用神经网络的方法在3个评价指标上都取得了更高的检测精度,在3个评价指标上平均增加了23.98,46.06和41.73百分点,证明了深度学习算法在遥感影像的语义分割方面具有可靠性和有效性; 另外,对于S&CMNet V2,在mIoU和F1-Score上比同时将VGG网络作为主干网络的U-Net和SegNet分别增加了1.49,0.93和1.97,1.21百分点,这说明混合注意力模块能够捕获有意义的通道特征信息以及聚合更多的位置信息; 最后,对于S&CMNet V1,预测时间为190.66 s,是所有语义分割模型中耗时最少的,这在需要应用于实时语义分割场景任务有显著优势。
表1 S&CMNet模型语义精度
Tab.1
| 模型名称 | PA/% | mIoU/% | F1- Score/% | TIME/ (s·100-1) |
|---|---|---|---|---|
| NDWI | 67.52 | 41.48 | 51.30 | — |
| U-Net | 90.43 | 88.33 | 93.50 | 252.25 |
| SegNet | 93.04 | 87.85 | 93.22 | 419.03 |
| S&CMNet V2 | 92.66 | 89.82 | 94.43 | 291.31 |
| PSPNet | 88.64 | 86.07 | 92.16 | 223.62 |
| DeeplabV3+ | 92.83 | 88.09 | 93.38 | 239.88 |
| S&CMNet V1 | 91.37 | 85.09 | 91.51 | 190.66 |
为了进一步展示分割结果,分别进行了3次消融实验,同时选取了3张不同区域的图像进行可视化处理,表2展示了与传统方法NDWI相比,深度学习分割模型如U-Net等能够得到具有更为连贯和准确的分割图,同时可以看出对于红外波段反射不敏感的区域NDWI并不能做出良好判断,而通过深度神经网络进行特征提取后则对不同空间域大小的水体都有较好的表现。
表2 NDWI分割方法与U-Net语义分割方法的分割结果
Tab.2
 |
为了从现有深度语义分割模型中寻找能够更好适应水体提取任务的基线网络,本文进行了大量实验,表3展示了现有深度分割模型之间的对比结果,从网络模型的角度出发,SegNet模型中使用的解码器结构使最终的分割影像中出现了大量噪声,而U-Net更好地避免了这种情况; 另外DeeplabV3+和PSPNet的结果是对相当于原图1/8的特征图进行下采样从而使结果会存在少许边缘模糊的情况,但是由于是以ResNet101为主干网络,其在多层语义特征表述上有着更好的效果。结合表3得出的结论,将ResNet101与U-Net的特征提取网络作为主干网络,在此基础上引入混合注意力模块得到模型S&CMNet V1以及S&CMNet V2,表4展示了2个模型的可视化结果,可以看出S&CMNet模型均有较好的表现,同时在细小河流区域展现出了更为准确的分割结果。
表3 基于ResNet101的语义分割网络的分割结果与先前实验结果之间对比
Tab.3
| 数据序号 | 原始图像 | 真值 | U-Net | SegNet | PSPNet | DeeplabV3+ | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 |  |  |  |  |  |  | |||||
| 2 |  |  |  |  |  |  | |||||
| 3 |  |  | 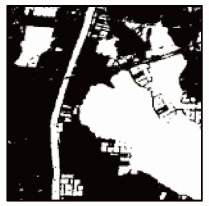 |  |  | 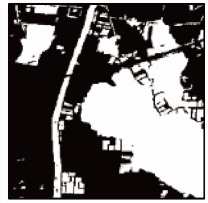 | |||||

4 结论
本文提出了一种新的深度分割模型S&CMNet用于高分辨率遥感图像水体提取任务。通过实验评估,证明了本文模型能够显著提高水体检测性能,并具有高效的推理速度,且在GPU上实时运行速度快。
本文方法依旧存在一些需要解决的问题,本文只引入了2个较为简单的通道注意力和空间注意力,性能提升有限,但同时也证明了注意力机制在遥感影像语义分割中的可行性。目前兴起于自然语言处理技术的Transformer注意力模块快速发展,为语义分割领域提供更多可行性。高分辨率遥感影像包含了丰富地物信息以及影像普遍连续性等特点,似乎更加适合将传统的端到端训练过程用序列到序列的预测任务来提供替代视角。如何针对高分遥感影像设计更好的深度学习网络结构,从而更好地解决遥感应用领域中的诸多问题,需要计算机视觉、遥感科学等众多领域研究者的共同努力。
参考文献
Utilization of satellite data for inventorying prairie ponds and lakes
[J].
Water body detection and delineation with Landsat TM data
[J].
The use of the normalized difference water index (NDWI) in the delineation of open water features
[J].DOI:10.1080/01431169608948714 URL [本文引用: 1]
Atmospherically resistant vegetation index (ARVI) for EOS-MODIS
[J].DOI:10.1109/36.134076 URL [本文引用: 1]
A study on information extraction of water body with the modified normalized difference water index (MNDWI)
[J].
Gradient-based learning applied to document recognition
[J].DOI:10.1109/5.726791 URL [本文引用: 2]
ImageNet classification with deep convolutional neural networks
[J].
Mask R-CNN
[C]//
Fully convolutional networks for semantic segmentation
[C]//
Multi-attention object detection model in remote sensing images based on multi-scale
[J].DOI:10.1109/ACCESS.2019.2928522 URL [本文引用: 1]
Hybrid first and second order attention U-net for building segmentation in remote sensing images
[J].
Reducing the dimensionality of data with neural networks
[J].
DOI:10.1126/science.1127647
PMID:16873662
[本文引用: 1]

High-dimensional data can be converted to low-dimensional codes by training a multilayer neural network with a small central layer to reconstruct high-dimensional input vectors. Gradient descent can be used for fine-tuning the weights in such "autoencoder" networks, but this works well only if the initial weights are close to a good solution. We describe an effective way of initializing the weights that allows deep autoencoder networks to learn low-dimensional codes that work much better than principal components analysis as a tool to reduce the dimensionality of data.
Toward evaluating multiscale segmentations of high spatial resolution remote sensing images
[J].DOI:10.1109/TGRS.2014.2381632 URL [本文引用: 1]
Deeplab:Semantic image segmentation with deep convolutional nets,atrous convolution,and fully connected CRFs
[J].DOI:10.1109/TPAMI.2017.2699184 URL [本文引用: 1]
Pyramid scene parsing network
[C]//
U-net:Convolutional networks for biomedical image segmentation
[C]//

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}