

0 引言
遥感图像地物分类是指把遥感图像中的每个像元划归为某一个语义类别的过程,其主要原理是根据地物电磁波辐射在遥感图像上的特征,判读识别地表物体的类属[1],而在计算机视觉领域中,一般称之为语义分割,其结果可为城市规划和土地使用状况监测等提供基础数据支撑。本文以广州市南沙区和东莞市虎门镇作为研究区域,该区域位于粤港澳大湾区,是中国最具经济活力和发展最快的区域之一,在过去的20 a里,该区域城市建设开发速度不断加快,居民及建设用地的面积占比从2000年的8%增加为2020年的17%,同时林地、耕地和草地等土地面积占比都有一定程度的减少[2]。该区域仍然处于快速的城市开发进程中,对于这个区域进行连续的土地使用状况监测可为土地规划部门提供有价值的参考数据。研究区域位于广东省中南部,属于亚热带气候,气温较高,降水充沛,多云多雾,使用光学遥感卫星技术手段采集地物信息将受到较大的限制。合成孔径雷达(synthetic aperture Radar, SAR)系统[3]具有不受天气、光线以及云层影响的特点,能够实现全天时、全天候的成像,比较适合于该区域的遥感信息采集。
有较多学者已使用基于卷积神经网络的经典语义分割模型在SAR图像上开展了地物分类的研究,并取得了若干成果。Yao等 [4]以德国TerraSAR-X雷达卫星图像和Google Earth光学图像构建数据集,使用全卷积神经网络(fully convolutional networks,FCN)[5]在数据集上实现了地物分类,得到的平均交并比(mean intersection over union,mIoU)值为0.3; Henry等[6]在TerraSAR-X上构建了关于道路的SAR图像数据集,并使用FCN,U-Net和DeepLabv3+ 这3种网络进行地物分类,其中像素精度(pixel accuracy,PA)最高达到了0.71,交并比(intersection over union,IoU)值最高达到了0.45; Wu等 [7]以航空机载雷达得到的SAR图像构建了一个包含建筑物、水体、植被、道路和其他地物共5类目标的数据集,并使用FCN和U-Net对其进行地物分类,得到的PA值都为0.84,得到的mIoU值分别为0.44和0.5。
但是,真实观测场景中存在尺度大小不一的观测目标,通过遥感技术获取的图像中,对应的目标尺度存在一定差异。如果分类模型中卷积核的感受野只能覆盖大尺度目标的一部分,则无法感知目标完整的特征; 反之,如果感受野比目标大得多,背景像素中含有的特征会在训练过程中被模型学习到。因此,根据单一尺度的特征来预测所有像素的类别,会造成地物分类精度的降低。为了解决尺度不一的问题,可采用多个具有不同感受野的卷积核提取多尺度的图像特征,然后将提取到的不同尺度的特征融合,以提高地物分类的鲁棒性和精度。2017年,Zhao等[8]在PSPNet中提出了金字塔池化模块(pyramid pooling module,PPM),这个模块包括多个池化核,分别覆盖图像的整体、一半和小部分,提取多尺度信息并融合,在PASCAL VOC 2012数据集上得到的mIoU值为0.854,比未采用多尺度特征融合的DeepLabV1[9]模型提高了13.8%; Chen等[10]在2017年提出了空洞卷积空间金字塔池化(atrous spatial pyramid pooling,ASPP)模块,该模块采用多个不同膨胀率的卷积核并行提取多尺度特征后融合,结合该模块的DeepLabV2模型在PASCAL VOC 2012数据集上得到的mIoU值为0.797,比DeepLabV1模型提高了8.1%。相比于单一尺度模型,使用了多尺度特征融合策略的语义分割网络模型对应的分类精度都有了一定提高。
基于多卷积核并行提取多尺度特征的策略,本文提出一种应用于SAR图像地物分类的多尺度轻量化卷积神经网络模型ENet-CSPP。模型使用了改进后的ENet网络和卷积空域金字塔池化(convolution spatial pyramid pooling,CSPP)模块作为编码器,使用了深、浅层特征融合的解码器,更加有效地提取了尺度变化较大目标的特征,在一定程度上提高了SAR图像地物分类的精度。
1 多尺度特征融合的SAR图像地物分类模型
1.1 模型构建策略
上述多尺度特征提取和融合的研究都是基于自然图像,ASPP模块采用了多个不同膨胀率的空洞卷积核并行提取图像特征,空洞卷积有利于扩大感受野,充分捕捉图像特征,但由于卷积核中含有空洞,并不是每个输入的像素都参与计算,相邻像素的特征会丢失。SAR图像中相邻像素的类别可能变化巨大,如果丢失邻域特征,将导致地物类型预测性能的降低[11]。另一方面,当图像中物体较小而空洞卷积的膨胀率较大时,3×3空洞卷积就会退化成1×1的卷积[12],感受野减小了。因此,需要将ASPP模块中的空洞卷积改为普通卷积,称为CSPP模块。CSPP模块可以多尺度的方式提取图像的特征,然后进行融合并输出,同时也保留了图像的邻域特征。
较多基于卷积神经网络的经典语义分割模型都采用了编码器-解码器的结构,其用于提取特征的编码器部分大都是基于VGG[13]网络或者ResNet[14]等深层网络,深层网络需要训练大量的网络参数[15],而对于SAR图像而言,目前学术界还没有一种包含数十万或者更多样本的数据集。如果使用大型网络进行训练,容易发生过拟合,导致预测性能大幅度降低。因此,可采用轻量化网络ENet的一部分作为模型的特征提取部分。ENet作为一种实时语义分割的网络,其性能在一些数据集上与SegNet相当,但其推理时间仅为SegNet的1/18,对应的参数减少了79倍[16]。本文提出的模型采用了ENet网络的下采样部分,将其改进后与CSPP模块结合,作为ENet-CSPP的特征提取部分,即编码器。
根据上述分析和讨论,ENet-CSPP模型也采用编码器-解码器结构。为了减少模型深度,将ENet网络的下采样部分轻量化改进后与CSPP结构结合,作为编码器模块; 解码器模块融合深、浅层特征,然后进行上采样,将特征图恢复成原图分辨率。
1.2 ENet-CSPP模型结构
1.2.1 编码器
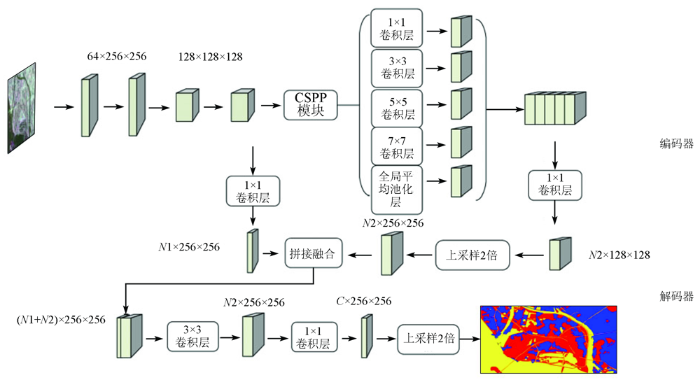
编码器的作用主要是提取图像的深层特征,模型的编码器部分基于改进后的ENet网络的下采样部分和CSPP结构。具体而言,对ENet网络做出了如下改进: ①去除initial层,减少了下采样次数,这将有助于保持特征图分辨率、减少空间信息的损失、提高模型精度; ②移除了section2,减少了网络深度,进一步减少模型的参数量和计算量,较大降低了过拟合风险; ③去除了bottleneck4.0~bottleneck5.1,使用CSPP模块代替,而其中的上采样模块放到了解码器部分。输入图像分辨率为512像素×512像素时ENet和ENet-CSPP的网络结构如表1所示,表1中C为分类的类别数目; N1为浅层特征通道数; N2为深层特征通道数。
表1 ENet和ENet-CSPP的结构对比
Tab.1
| ENet | ENet-CSPP | |||||
|---|---|---|---|---|---|---|
| 层名 | 采样类型 | 输出大小/像素 | 层名 | 采样类型 | 输出大小/像素 | |
| initial | 16×256×256 | |||||
| bottleneck1.0 | downsampling | 64×128×128 | bottleneck1.0 | downsampling | 64×256×256 | |
| 4bottlencek1.x | 64×128×128 | 4bottlencek1.x | 64×256×256 | |||
| bottleneck2.0 | downsampling | 128×64×64 | bottleneck2.0 | downsampling | 128×128×128 | |
| 8bottleneck2.x | 128×64×64 | 8bottleneck2.x | 128×128×128 | |||
| repeat section 2,without bottleneck2.0 | CSPP | N2×128×128 | ||||
| bottleneck4.0 | upsampling | 64×128×128 | upsample1.0 | upsampling | N2×256×256 | |
| 2bottleneck4.x | 64×128×128 | concat | (N1+N2)×256×256 | |||
| bottleneck5.0 | upsampling | 16×256×256 | lastconv | C×256×256 | ||
| 2bottleneck5.x | 16×256×256 | upsample2.0 | upsampling | C×512×512 | ||
| fullconv | C×512×512 | |||||
为了进一步提取多尺度的特征信息,编码器后半部分将使用CSPP模块对ENet网络输出的特征进行处理。主要对ASPP模块的改进为: 移除膨胀率分别为6,12,18的空洞卷积层,替换成卷积核尺寸分别为3×3,5×5,7×7的常规卷积层。使用普通卷积将有助于改进空洞卷积造成邻域信息丢失的缺点,提高对小目标的分类效果。另一方面,选择了5×5和7×7等较大尺寸的卷积核,有助于模型维持大的感受野。
改进的ENet网络得到的输出,输入到CSPP模块,该模块包含了多个不同尺寸的卷积层以及一个全图平均池化层,得到了不同分辨率的特征。将多层特征通过concat操作拼接融合,由于全图平均池化层的输出特征图分辨率与其他卷积层特征图分辨率不同,与其他分辨率的特征融合之前,需要对其进行上采样2倍的操作。拼接融合的特征最后通过1×1卷积层,从而减少了通道数量; 最终,输出通道数为N2、分辨率为128像素×128像素的特征图到解码器模块中。
1.2.2 解码器
解码器的作用主要是将特征图还原成与原输入图像具有相同分辨率的图像,从而恢复图像的细节。首先,将编码器的输出上采样2倍后,与来自编码器中提取的相同分辨率的低层特征进行拼接融合; 然后,将得到的融合特征经过2个3×3和1个1×1卷积层处理后,缩减其通道数; 最后,对特征图再进行2倍上采样,得到与原输入图像相同分辨率的特征图。
1.2.3 总体结构
总体结构如图1所示,编码器输出的浅层特征和深层特征经过2个1×1卷积层处理后,得到N1通道数的浅层特征和N2通道数的深层特征,然后再输入到解码器中进行后续处理。
图1
1.3 数据集及分类参考图
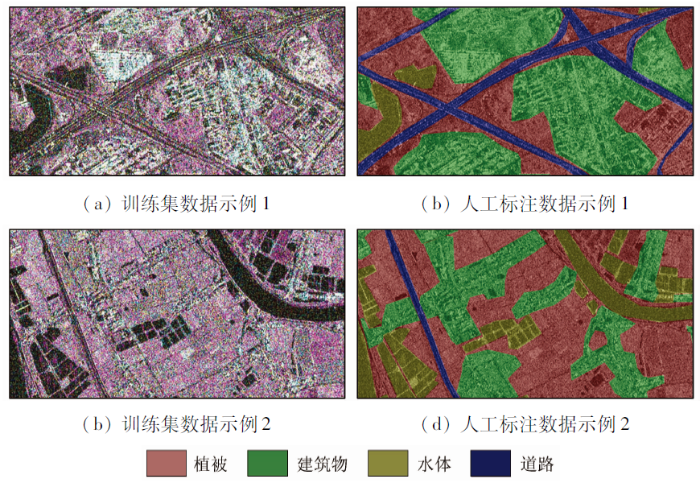
数据集来源于GDUT-Nansha[20]SAR图像数据集,该数据集基于TerraSAR-X[21]双极化数据构建(极化方式为HH/VV),覆盖范围为广州市南沙区整体和东莞市虎门镇一部分。该景TerraSAR-X双极化图像的参数为: 采集于2019年5月14日22: 48: 31(UTC时间),图像大小为23 642像素×8 432像素,近入射角为26.065°,远射角为27.746°,卫星的运动方向为降轨,图像的方位向像元分辨率为6.59 m,距离向像元分辨率为2.70 m。该数据集包含92幅2 048像素×1 024像素的图像,裁剪后得到704幅512像素×512像素的图像。为了扩充样本数量,使用旋转90°,180°,270°以及镜像变换等方法对数据进行增广,同时随机分配15%样本作为验证集,最终得到含有4 788幅图像的训练集,含有844幅图像的验证集,部分训练集数据如图2所示。地物类型设定为4个类型,分别为植被、建筑物、水体和道路。分类参考图对应的区域为东莞市虎门镇,来源于第三方测绘公司航拍采的光学图像,该图像的航测时间为2019年1—2月,与TerraSAR-X卫星数据采集时间基本同步。将图像进行内业数据处理后,结合人工实地调查核对,得到与测试集数据具有相同地理区域的分类参考图。
图2
测试集数据裁剪于另一景TerraSAR-X数据,裁剪区域位于东莞市虎门镇的一部分,此区域图像没有包含在训练集中,该区域具体位置如图3所示。该景TerraSAR-X双极化图像的参数为: 采集于2019年5月15日22: 31: 26(UTC时间),图像大小为26 015像素×8 496像素,近入射角为24.899°,远入射角为26.680°; 卫星的运动方向、图像的方位向和距离向像元分辨率与训练集数据相同。
图3

1.4 训练策略
模型的训练使用Adam优化器,初始学习率为0.01; 训练使用的NVIDIA GeForce RTX 3060显卡,其显存容量为12 GB,CUDA核心数量为3 584个,基本核心频率为1 320 MHz; 使用交叉熵函数作为损失函数,损失函数值loss的公式为:
式中: M为BatchSize的大小,即每次迭代送入网络进行训练的样本数目,本文设置为8; N为输入图像的像素数量,本文输入图像分辨率为512像素×512像素,N为262 144; C为类别的数目,本文设置为4类; yic为符号函数,如果样本i的真实类别等于c则取1,否则取0; pic为样本i预测类别为c的概率。
为了防止过拟合,模型采取了早停法和动态调整学习率相结合的训练策略。如果在连续7个轮次之内,验证集的损失函数值没有降低,则自动停止训练; 如果在连续4个轮次之内,验证集的损失函数值没有降低,则自动调整学习率为上一轮学习率的0.1倍。
2 模型预测与实验结果分析
2.1 模型性能评价指标
本文主要采用PA、平均像素精度(mean pixel accuracy,mPA)、IoU和mIoU这4个指标来评估模型。PA为分类正确的像素点数和所有的像素点数的比值; mPA为类别像素精度的平均值; IoU为预测值和真实值的交集与预测值和真实值的并集之间的比值。这个指标用来表达真实值和预测值之间的相关程度,该值越高,相关度越高。mIoU为类别IoU的平均值。其公式分别为:
式中: pii为第i类别正确分类的像素点个数; pij为真实值为i类别的像素预测为j类别的像素点个数;
2.2 交叉熵损失函数权重对模型预测性能的影响
为了减少类别不平衡对模型性能的影响,使用了带权重的交叉熵损失函数。为了验证不同类别权重对模型精度的影响,使用PA,mPA和mIoU作为性能评价指标开展实验。实验结果如表2所示,权重参数一列的数值依次为植被、建筑物、水体、道路的权重数值,该数值Weight的计算公式为:
式中: Pc为样本类别为c的像素数目; P为总样本的像素数目。
表2 交叉熵损失函数类别权重对模型性能的影响
Tab.2
| 权重参数 | PA | mPA | mIoU |
|---|---|---|---|
| 无权重 | 88.8 | 78.8 | 70.1 |
| 0.64,0.73,0.65,0.96 | 88.6 | 81.5 | 71.0 |
训练集中各个类别地物对应的像素数量是不均衡的,其中道路类别对应像素数量远少于其他类别。式(6)根据样本类别的比例来计算权重,减小了植被、建筑物和水体的权重,3种地物目标的语义分割性能指标有轻微下降,PA相对于无权重参数的设置下降了0.2百分点; 因为加大了道路的权重,道路地物目标的语义分割精度得到提高,相对于无权重参数的设置下,其mPA上升了2.7百分点,mIoU也上升了0.9百分点,上述实验验证了带权重的交叉熵损失函数对于解决样本不均衡问题具有较好的效果。
2.3 融合特征通道的数量对模型预测性能的影响
表3 浅层特征和深层特征通道数对模型性能的影响
Tab.3
| N2+N1 | PA | mPA | mIoU |
|---|---|---|---|
| 64+0 | 88.6 | 76.9 | 68.6 |
| 64+8 | 88.4 | 79.2 | 69.9 |
| 64+16 | 88.4 | 78.7 | 69.6 |
| 64+32 | 88.2 | 79.0 | 69.6 |
| 64+64 | 88.3 | 78.9 | 69.6 |
| 16+8 | 88.6 | 81.5 | 71.0 |
| 32+8 | 88.6 | 77.6 | 69.2 |
| 128+8 | 88.7 | 79.3 | 70.2 |
从表3中前5行数据可看出,模型在保持N2=64不变时,在N1=8时,PA,mPA和mIoU这3项评价精度相对最优; 而当N1=0,即不融合低层特征时,模型的mPA和mIoU相对于N1=8时的模型性能都分别下降了2.3百分点和1.3百分点,这说明了融合低层特征的必要性。后3行数据是在维持N1=8时,不断增大N2得到的实验结果。结果表明,当N2=16时,模型的3项评价精度取得最优,相对于N2=32时所得到的评价精度,前者在mPA和mIoU上高了3.9百分点和1.8百分点。
实验结果表明,对于ENet-CSPP模型,可以通过减少深层、浅层特征通道数来获取较好的预测性能。SAR图像存在尺度不同的地物目标,对于大的地物目标,像素占比较多,样本数量较多,其特征信息在融合特征中占比较多; 小的地物目标,像素占比较少,样本数量较少,其特征信息融合特征中占比较少。特征通道数代表了当前层特征信息数量的大小,特征信息数量越多,其中包含的冗余信息越多。减少特征通道数,一方面可以减少冗余信息,有利于提高ENet-CSPP模型的整体分类精度; 另一方面可以减少融合特征中大地物目标的特征信息占比,更利于下一层网络对小地物目标特征的提取,从而提高模型对小地物目标的分类精度。但随着特征通道数的下降,所包含的特征信息可能不足以让下一层网络提取地物目标类别的特征,导致整体分类精度下降。因此,具体特征通道数的数量还需要根据实验结果决定。综上所述,网络模型在N2=16和N1=8时,特征融合层保持了较小的特征输出,提高了较小地物目标的分类精度,使模型预测达到了相对的最优性能。
2.4 模型性能对比分析
将FCN,SegNet,U-Net,DeepLabV3+,ENet和ENet-CSPP等模型在GDUT-Nansha数据集上训练,在同一测试集上预测,各个模型在测试集图像上的地物分类效果如图4所示。其中,图4(a)测试集图像是TerraSAR-X图像对应的伪彩色图像。以PA,mPA,mIoU以及每个类别的IoU作为性能评价指标进行评测(表4)。其中ENet-CSPP模型是在N2=16和N1=8时得到的实验结果; 除ENet和ENet-CSPP模型外,其余4个模型都使用了基于VGG-16的编码器和预训练权重; 所有模型的损失函数都采用了带权重的交叉熵损失函数,其中权重设置是基于式(6)计算得到,4种地物目标对应的权重分别如表2中所示。
图4
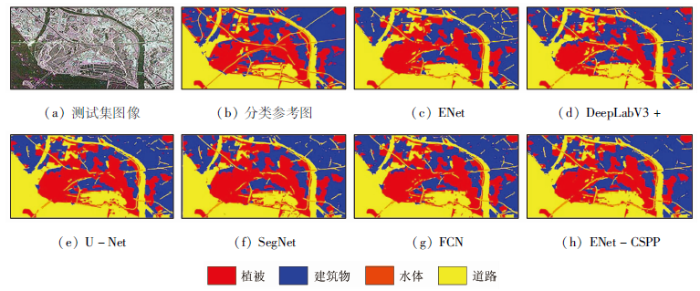
图4
不同模型在测试集遥感图像上的地物分类结果
Fig.4
Classification images of the diffeent models on the test image
表4 不同模型在GDUT-Nansha数据集上的对比
Tab.4
| 模型 | PA | mPA | IoU | mIoU | |||
|---|---|---|---|---|---|---|---|
| 植被 | 建筑物 | 水体 | 道路 | ||||
| FCN | 87.5 | 78.3 | 72.8 | 80.1 | 89.7 | 30.3 | 68.2 |
| SegNet | 87.1 | 79.8 | 72.9 | 79.5 | 88.8 | 32.9 | 68.5 |
| U-Net | 88.0 | 80.0 | 73.3 | 80.5 | 90.5 | 34.1 | 69.6 |
| DeepLabV3+ | 87.1 | 80.2 | 70.5 | 79.7 | 89.1 | 37.0 | 69.1 |
| ENet | 85.7 | 77.7 | 69.3 | 76.7 | 88.8 | 29.4 | 66.1 |
| ENet-CSPP | 88.6 | 81.5 | 74.4 | 81.8 | 90.3 | 37.3 | 71.0 |
如表4所示,为各个模型在GDUT-Nansha数据集上的对比结果。纵向对比,ENet-CSPP模型比ENet模型,在PA,mPA和mIoU上分别高出了2.9百分点、3.8百分点和4.9百分点; 关于4种地物的IoU上,ENet-CSPP模型都有较大程度地提高,特别对于道路的分类,其IoU比ENet高出了7.9百分点,这表明CSPP模块融合多尺度特征的模式,有效提高了小尺度地物目标的分类精度。横向对比,ENet-CSPP模型比其余4个经典模型中性能最优的U-Net模型,在PA,mPA和mIoU上分别高出了0.6百分点、1.5百分点和1.4百分点; 在4个类别的IoU上,ENet-CSPP模型对水体的分类精度有所降低,但对于其他3个地物目标,尤其是在道路地物的分类上,比U-Net模型高出3.2百分点,表明了ENet-CSPP模型的有效性。值得注意的是,DeepLabV3+模型对于道路地物的分类,其IoU也达到了37.0%,相比于ENet-CSPP模型仅降低0.3百分点,但对植被地物目标,其IoU相比于ENet-CSPP模型降低了3.9百分点; 这是因为该模型使用的ASPP模块也为多尺度特征融合模块,有效提高了模型对道路地物目标的分类精度; 但另一方面,ASPP中使用空洞卷积作为特征提取手段,会丢失相邻像素的特征,DeepLabV3+模型丢失了植被地物目标的重要特征,降低了植被地物目标的分类精度。CSPP模块将ASPP模块中的空洞卷积改为了普通卷积,保留了图像的邻域特征,通过ENet-CSPP与DeepLabV3+预测性能的对比,可以看出CSPP模块的有效性。
3 结论
针对华南地区亚热带气候多云多雾的特点,采用TerraSAR-X雷达遥感图像来完成目标区域遥感信息的获取。针对SAR图像中地物目标尺度变化较大的问题,基于多卷积核并行提取多尺度特征的策略,提出了ENet-CSPP模型。模型的编码器使用了轻量化ENet网络作为特征提取网络,同时结合了基于ASPP模块改进的CSPP模块; 解码器部分融合了来自模型浅层网络输出的特征以及深层网络输出的特征,最终输出地物分类图。模型训练中使用了具有合理权重的交叉熵函数作为损失函数,完成了深层、浅层特征通道数对模型性能影响的实验,并利用多个卷积神经网络模型在GDUT-NanSha数据集上进行了对比。实验结果表明ENet-CSPP模型可以得到更高的分类精度,更有利于监测土地的覆盖情况。通过理论分析和实验验证,初步得到如下结论:
1)在卷积神经网络中结合多尺度特征融合模块的方法,有利于SAR图像地物分类任务,模型的分类精度有明显提高。
2)训练中使用具有合理权重的交叉熵函数作为损失函数,能有效减少样本不平衡问题对模型分类性能的影响,提高模型的分类性能。
3)对于ENet-CSPP模型,可以通过减少深层、浅层特征通道数来提高模型对小地物目标类别的分类精度,以获取较好的总体预测性能,但具体特征通道数的数量需要通过实验决定。
后续将考虑研究弱标注样本的生成方法,以扩充数据集的样本,在提高模型性能的同时减少人力标注的投入。
参考文献
基于DBN模型的遥感图像分类
[J].
Remote sensing image classification based on DBN model
[J].
粤港澳大湾区土地覆盖及景观格局时空变化分析
[J].
Analysis of spatio-temporal changes of land cover and landscape pattern in Guangdong-Hong Kong-Macao Greater Bay Area
[J].
Semantic segmentation using deep neural networks for SAR and optical image pairs
[C]//
Fully convolutional networks for semantic segmentation
[J].
DOI:10.1109/TPAMI.2016.2572683
PMID:27244717
[本文引用: 1]

Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixels-to-pixels, improve on the previous best result in semantic segmentation. Our key insight is to build "fully convolutional" networks that take input of arbitrary size and produce correspondingly-sized output with efficient inference and learning. We define and detail the space of fully convolutional networks, explain their application to spatially dense prediction tasks, and draw connections to prior models. We adapt contemporary classification networks (AlexNet, the VGG net, and GoogLeNet) into fully convolutional networks and transfer their learned representations by fine-tuning to the segmentation task. We then define a skip architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations. Our fully convolutional networks achieve improved segmentation of PASCAL VOC (30% relative improvement to 67.2% mean IU on 2012), NYUDv2, SIFT Flow, and PASCAL-Context, while inference takes one tenth of a second for a typical image.
Road segmentation in SAR satellite images with deep fully convolutional neural networks
[J].DOI:10.1109/LGRS.2018.2864342 URL [本文引用: 1]
PolSAR image semantic segmentation based on deep transfer learning-realizing smooth classification with small training sets
[J].DOI:10.1109/LGRS.8859 URL [本文引用: 1]
Pyramid scene parsing network
[C]//
Semantic image segmentation with deep convolutional nets and fully connected CRFs
[J].
DeepLab:Semantic image segmentation with deep convolutional nets,atrous convolution,and fully connected CRFs
[J].DOI:10.1109/TPAMI.2017.2699184 URL [本文引用: 1]
多尺度信息融合的遥感图像语义分割模型
[J].
Semantic segmentation on remote sensing images with multi-scale feature fusion
[J].
Rethinking atrous convolution for semantic image segmentation
[EB/OL].(
Very deep convolutional networks for large-scale image recognition
[C]//
Deep residual learning for image recognition
[C]//
基于语义分割网络的高分遥感影像城市建成区提取方法研究与对比分析
[J].
Research and comparative analysis of urban built-up area extraction methods from high-resolution remote sensing images based on semantic segmentation network
[J].
ENet:A deep neural network ar- chitecture for real-time semantic segmentation
[EB/OL].(
SegNet:A deep convolutional encoder-decoder architecture for image segmentation
[J].
DOI:10.1109/TPAMI.2016.2644615
PMID:28060704
[本文引用: 1]
We present a novel and practical deep fully convolutional neural network architecture for semantic pixel-wise segmentation termed SegNet. This core trainable segmentation engine consists of an encoder network, a corresponding decoder network followed by a pixel-wise classification layer. The architecture of the encoder network is topologically identical to the 13 convolutional layers in the VGG16 network [1]. The role of the decoder network is to map the low resolution encoder feature maps to full input resolution feature maps for pixel-wise classification. The novelty of SegNet lies is in the manner in which the decoder upsamples its lower resolution input feature map(s). Specifically, the decoder uses pooling indices computed in the max-pooling step of the corresponding encoder to perform non-linear upsampling. This eliminates the need for learning to upsample. The upsampled maps are sparse and are then convolved with trainable filters to produce dense feature maps. We compare our proposed architecture with the widely adopted FCN [2] and also with the well known DeepLab-LargeFOV [3], DeconvNet [4] architectures. This comparison reveals the memory versus accuracy trade-off involved in achieving good segmentation performance. SegNet was primarily motivated by scene understanding applications. Hence, it is designed to be efficient both in terms of memory and computational time during inference. It is also significantly smaller in the number of trainable parameters than other competing architectures and can be trained end-to-end using stochastic gradient descent. We also performed a controlled benchmark of SegNet and other architectures on both road scenes and SUN RGB-D indoor scene segmentation tasks. These quantitative assessments show that SegNet provides good performance with competitive inference time and most efficient inference memory-wise as compared to other architectures. We also provide a Caffe implementation of SegNet and a web demo at http://mi.eng.cam.ac.uk/projects/segnet.
U-Net:Convolutional networks for biomedical image segmentation
[C]//
Encoder-decoder with atrous separable convolution for semantic image segmentation
[C]//
轻量化卷积神经网络在SAR图像语义分割中的应用
[J].
Application of lightweight convolutional neural network in SAR image semantic segmentation
[J].
The TerraSAR-X mission and system design
[J].DOI:10.1109/TGRS.2009.2031062 URL [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}