

0 引言
近岸海域是指20 m等深线至海岸线的海域 [1]。近岸海域监测目标既包括自然环境监测要素(如海、浪、流、潮和水边线等),又包括人类活动监测要素(如船只、车辆、垃圾、人和大坝等),近岸海域监测目标的高精准识别对海洋经济的健康发展、海洋环境的生态保护以及海洋防灾减灾等都具有重要的作用。受自然环境和人类活动的影响,近岸海域监测目标具有多类型、多尺寸和不确定性等特征,如何提高近岸海域监测目标的识别效率是制约海域管理智能化水平的关键问题之一。
深度学习是机器学习算法中的新技术,其动机在于创建一个神经网络并模拟人脑进行分析学习[2]。Hinton于20世纪80年代提出了适用于多层感知机(multi-layer perceptron,MLP)的反向传播算法,使深度学习进入人们的视野[3]。其后,LeCun等[4]于1998年提出了卷积神经网络(convolutional neural networks,CNN); Girshick等[5]于2014年提出了区域卷积神经网络(regions with CNN, R-CNN)目标识别模型; Redmon等 [6]于2015年提出了YOLO(you only look once)目标识别模型。深度学习逐渐被应用于目标识别领域,其目标识别的精度和效率逐渐优化。目前,已有学者将深度学习应用于海洋监测领域,关克平等[7]提出将目标检测算法CenterNet与目标跟踪算法DeepSORT相结合的船舶交通流视觉图像统计方法; 许延雷等[8]提出了基于自适应阈值的改进CenterNet航拍图像目标检测算法; 岳邦铮等[9]设计了适用于(synthetic aperture Radar,SAR)影像的船舶目标检测特征提取模型; 聂鑫等[10]通过改进YOLOv3提出了一种在复杂场景下的船舶检测方法; 齐亮等[11]提出了一种改进的基于区域的快速卷积神经网络(faster region with convolutional neural network,Faster R-CNN)的船舶目标检测方法; 盛明伟等[12]通过在YOLOv3中引入注意力机制,提出了一种改进YOLOv3的船舶目标检测算法。
上述研究将深度学习应用于海域监测,提高了海域监测目标识别的精度和效率。但现有的识别模型多针对某一特定的监测目标,直接将其应用于多类型近岸海域监测目标的同步识别,存在精度和效率欠佳现象,特别是面对小目标的识别其漏检或错检现象严重。本文针对近岸海域监测目标的特点,提出了一种近岸海域监测目标识别模型(Re-YOLOX),提高多类型近岸海域监测目标同步识别的精度和效率,特别是提高小目标的识别精度。
1 近岸海域监测目标识别模型(Re-YOLOX)
图1
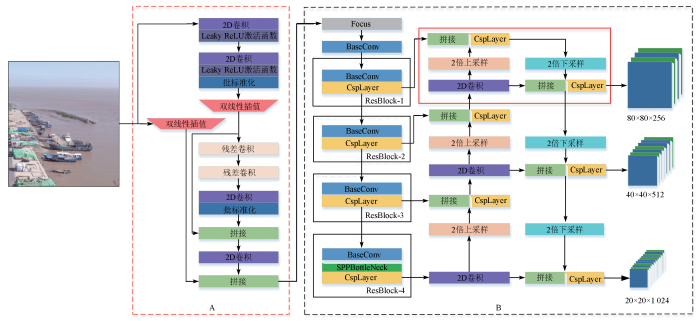
图1
近岸海域监测目标识别模型(Re-YOLOX)结构框架
Fig.1
Structure diagram of target recognition model (Re-YOLOX)
图1中Focus由4种不同的空间压缩方式和一个2D卷积层组成的压缩卷积层; BaseConv是由2D卷积层、批归一化层(batch normalization,BN)以及SiLU激活函数组成的卷积单元; CspLayer由残差卷积模块组成的卷积层; SPPBottleNeck由2个Base-Conv单元和4个大小不同的池化层组成的金字塔池化层。
YOLOX模型由旷视科技于2021年提出,该模型保持了YOLOv5的网络结构,其主干特征提取网络(Backbone)采用交叉阶段部分连接(cross stage partial network,CSPNet)[15]并结合Darknet-53的CSPDarknet结构。YOLOX模型将空间金字塔池化网络(spatial pyramid pooling networks,SPPNet)[16]应用到主干特征提取网络中,代替了原有池化层,提高了目标检测的准确率。同时,在特征层融合部分,将上采样和下采样结合,实现了多尺度特征的融合[17]。YOLOX应用双解耦头结构,对来自主干特征提取网络的特征层分别进行分类操作和定位回归操作,加快了模型的收敛速度,提高了检测精度。与单阶段目标识别模型比较,YOLOX模型无须生成检测目标先验框,可直接对特征点进行回归分析,精简了模型参数并提高了检测精度。与双阶段目标识别模型相比,YOLOX模型无须先生成候选区域,可直接对图像进行特征提取,亦提高了检测速度。因此,面向多类型、多尺寸和不确定性等特征的近岸海域监测目标识别,本文将YOLOX模型作为基础模型。
1.1 利用Resizer model加强模型训练
YOLOX模型采用固定尺度的图像输入,通过对图像进行缩放、镜像和对比度变化等操作提高模型的泛化性。此过程易导致图像细节特征丢失,当图像存在重叠面积的2个或多个目标,或存在较多小面积目标时,细节特征丢失现象会加剧,进而引起漏检测或错检测等问题。为解决该问题,本文引入Resizer model加强模型的训练。
Resizer model是谷歌研究院于2021年提出的图像预处理模型,其借鉴 Resnet[18]的跳跃连接思想,将图像经过原始线性插值方法与学习后线性插值方法融合处理后的特征信息,整合到了CNN中。在进行模型训练时,Resizer model可根据识别模型每轮训练的反向传播结构优化其图像调整参数,使Resizer model成为一种可学习的图像调整模型。在Re-YOLOX模型中,图像直接输入Resizer model,通过卷积运算和双线性插值方法实现图像预处理,将预处理的结果直接输入到图1(B)所示的识别模型中进行特征提取。Resizer model根据其识别模型每次的反向传播结果,优化调整卷积核的参数,进一步调整双线性插值方法对图像的预处理。经过Resizer model处理后的图像尺寸保持一致,且保留了图像的细节特征,加强了模型的特征提取能力。
1.2 改进YOLOX模型的特征金字塔融合结构
YOLOX模型的主干特征提取网络较深,多达上百层。小目标的特征信息会在多次卷积操作后减弱甚至消失。为提升Re-YOLOX模型对小目标物体的识别能力,在YOLOX模型的特征金字塔融合结构中新增一个高分辨率特征层,新增特征层融合结构如图1(B)中红色实线框所示。
YOLOX模型的主干特征提取网络中ResBlock-n表示第n个组合卷积结构,每个组合卷积结构由BaseConv单元和CspLayer层组成。其中BaseConv单元由2D卷积层、BN层以及SiLU激活函数组成; CspLayer层由残差卷积模块组成。如在输入图像宽高为640像素×640像素时,主干网络中的第一个组合卷积结构ResBlock-1的输出特征层的宽高为160像素×160像素,其中拥有大量小目标物体的特征信息。Re-YOLOX模型将160像素×160像素的特征层与来自特征金字塔底层经过上采样得到的特征层,在通道维度上进行拼接,并将拼接得到的特征层用于密集卷积操作,后再一次进行下采样特征提取。在得到经下采样特征提取的特征层后,Re-YOLOX模型将其与特征金字塔上采样过程中具有相同宽高尺寸的特征层再次拼接,实现多尺度特征融合。改进后的特征金字塔融合结构充分利用了主干特征提取网络对图像提取的浅层特征信息,对小目标更加敏感。
1.3 训练Re-YOLOX模型及设置参数
Re-YOLOX模型通过2个阶段进行训练。在第一阶段,使用YOLOX原有的图像预处理方法对模型进行训练,在模型收敛后,保存权重文件,作为第二训练阶段的初始化模型。在第二阶段,用第一训练阶段保存的权重文件对模型参数初始化后,使用Resizer model对模型进行加强训练,使模型在第一训练阶段的基础上,继续学习目标物体的更多细节特征。第一和第二训练阶段的Epoch都为100,为加强对Resizer model和添加高分辨率特征层的特征金字塔融合结构的训练。前50 Epoch冻结模型的主干特征提取网络,第一阶段仅对模型的多尺度特征融合结构进行训练; 第二阶段对多尺度特征融合结构和Resizer model进行训练。2个训练阶段其余参数设置相同,具体包括Momentum=0.9,Decay=0.005,batch size=4,学习率LR设置为0.001。后50 Epoch对全部参数进行训练,为提升模型的稳定性,后50 Epoch的学习率LR设置为0.000 1。优化器为SGD,使用余弦退火学习机制。
2 实验设计
2.1 数据集
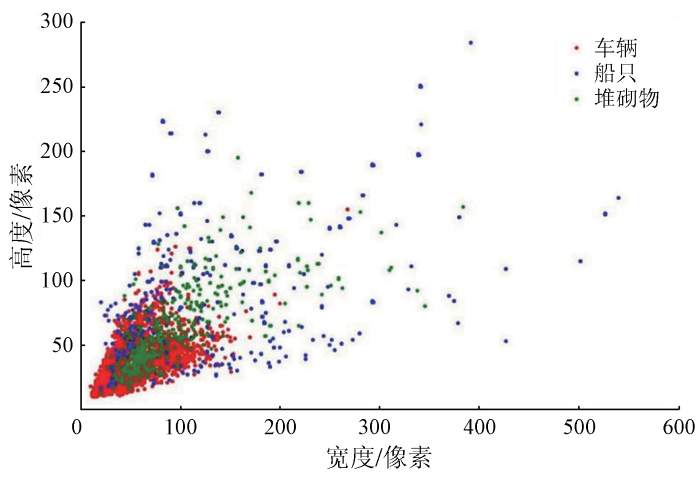
选取无人机航拍的上海市近岸海域视频数据,采用视频抽帧方式构建训练和测试数据集(图2)。实验数据为抽取的1 010张图像,大小为960像素×1 080像素,随机选择80%作为训练集,10%为验证集,10%为测试集。以车辆、船只和堆砌物为近岸海域监测目标,用开源标注工具LabelImg对监测目标进行标注,共标注监测目标15 425个。图3所示为15 425个目标物体的尺寸统计,横、纵坐标分别为目标的宽度和高度,单位为像素,根据COCO数据集标准,将像素面积小于32像素×32像素的目标划分为小目标,像素面积大于96像素×96像素的目标划分为大目标[19]。由图3可知,数据集中的中小型目标占比较大,大多数目标集中分布于0~100像素之间。
图2

图3
2.2 实验环境
实验硬件配置为Inter Core i7-9700 CPU处理器,GeForce GTX 2060显卡的服务器。操作系统为64位Windows 10,深度学习框架为pytorch,可视化工具为Matplotlib。
2.3 评价指标
选用精准率(precision,P)、召回率(recall,R)、平均均值准确率 (mean average precision,mAP)和平均召回率 (mean recall,mR)、平均F1值(mean F1,mF1)和模型的检测速度(frame per second,FPS)对识别模型的性能进行评价[20] 。IOU表示真实标注框与检测框的交并比,本文所有算法模型的IOU均为0.5。P和R的公式分别为:
式中: TP为模型将正样本预测为正样本的个体数量; FP为模型将负样本预测为正样本的个体数量; FN为模型将正样本预测为负样本的数量。
mAP的计算公式为:
式中: C为数据集中的检测类别数; AP(k)和R(k)分别为第k个类别的检测精度和召回率。
F1是对识别模型预测精准率和召回率的综合考量,用来评价识别模型的识别精度、避免精准率和召回率之间的相互影响,mF1的计算公式为:
式中: D为数据集中样本类别个数;
FPS是指识别模型每秒处理的图像数,用于评价模型的检测速度。
3 实验对比与分析
本节分别设计了消融实验和对比实验对提出的Re-YOLOX模型进行可行性和性能验证。
3.1 消融实验
图4
表1所示为Re-YOLOX模型中各改进模型的性能比较,其中,YOLOX+resizer表示将Resizer加入YOLOX模型的图像预处理中; YOLOX+add表示在YOLOX模型的特征金字塔融合结构中添加高分辨率特征层。由表1中可知,YOLOX+resizer模型和YOLOX+add模型均提升了原有YOLOX模型的mAP值、mR值和mF1值,但其检测速度略有下降。YOLOX+resizer模型通过增设Resizer模块,强化了YOLOX模型的特征提取能力,船只的精准率和召回率提升明显,分别增长4.32和4.94百分点; 同时其mAP值提高2.14百分点,mR值提高4.26百分点。YOLOX+add模型通过在特征金字塔融合结构中添加高分辨率特征层,降低了小目标在深度卷积过程中信息损失对模型的影响,车辆和船只的召回率分别提高了7.23和5.97百分点,同时其mR值提高了5.69百分点。而本文提出的Re-YOLOX对小目标更加敏感,特别是对尺寸较小的车辆和船只,相较于YOLOX,召回率分别提高了8.07百分点和8.42百分点。
表1 消融实验测试结果
Tab.1
| 模型 | P/% | R/% | mAP/% | mR/% | mF1/% | FPS/ (张·s-1) | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| 车辆 | 堆砌物 | 船只 | 车辆 | 堆砌物 | 船只 | |||||
| YOLOX | 94.09 | 86.58 | 75.24 | 83.09 | 87.16 | 83.16 | 89.79 | 84.47 | 84.67 | 16.36 |
| YOLOX+resizer | 88.69 | 88.27 | 79.56 | 89.87 | 88.23 | 88.10 | 91.93 | 88.73 | 87.04 | 15.44 |
| YOLOX+add | 89.65 | 89.49 | 80.34 | 90.32 | 91.03 | 89.13 | 93.28 | 90.16 | 88.24 | 14.32 |
| Re-YOLOX | 88.91 | 92.00 | 81.31 | 91.16 | 93.24 | 91.58 | 94.23 | 91.99 | 89.67 | 13.91 |
3.2 对比实验
表2 不同模型的目标识别结果
Tab.2
| 图像序号 | 标签 | CenterNet | Faster R-CNN | YOLOv3 | Re-YOLOX |
|---|---|---|---|---|---|
| a |  | ||||
| b |  | ||||
| c |  | ||||
| d |  | ||||
表3 不同模型的评价指标
Tab.3
| 模型 | P/% | R/% | mAP/% | mR/% | mF1/% | FPS/ (张·s-1) | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| 车辆 | 堆砌物 | 船只 | 车辆 | 堆砌物 | 船只 | |||||
| CenterNet | 95.38 | 97.56 | 96.72 | 51.07 | 54.05 | 62.11 | 80.48 | 55.74 | 71.00 | 14.38 |
| Faster R-CNN | 46.42 | 74.84 | 77.00 | 36.35 | 78.38 | 81.05 | 59.02 | 65.26 | 65.67 | 7.41 |
| YOLOv3 | 77.38 | 73.87 | 73.63 | 72.71 | 61.19 | 52.34 | 68.28 | 58.04 | 67.67 | 21.44 |
| Re-YOLOX | 88.91 | 92.00 | 81.31 | 91.16 | 93.24 | 91.58 | 94.23 | 91.99 | 89.67 | 13.91 |
由表2和表3可看出,Re-YOLOX模型对于位置邻近且有重叠遮挡的目标和小尺寸目标具有更好的识别效果,如面向图像a的目标识别,只有Faster R-CNN和Re-YOLOX模型将右下方的2只船只识别开来,但Re-YOLOX预测框的回归效果明显优于Faster R-CNN预测框; 面向图像c的目标识别,其他模型均存在明显漏检现象,尤其是CenterNet模型漏检现象最严重,Re-YOLOX模型识别出了所有船只和车辆。同时,Re-YOLOX模型具有最高的mAP, mR和mF1值,分别为94.23%,91.99%和89.67%。但Re-YOLOX模型的FPS略低于CenterNet和YOLOv3,高于Faster R-CNN模型。总体而言,Re-YOLOX模型在保证目标识别效率的前提下提高了目标识别精度。
4 结论
本文针对近岸海域监测目标识别精度要求高和实时性要求强等现实需求,兼顾近岸海域监测目标的多尺度及小目标多等特性,提出了一种近岸海域监测目标识别模型(Re-YOLOX模型),包括: 利用可学习的图像调整模型加强Re-YOLOX模型训练,提高模型的特征学习能力和表达能力; 改进Re-YOLOX模型的特征金字塔融合结构,缓解小目标识别的漏检问题。
用无人机监测的近岸海域视频数据作数据集,以车辆、船只和堆砌物为监测目标,通过消融实验和对比实验对提出的Re-YOLOX模型进行可行性和性能验证。消融实验结果表明,在Re-YOLOX模型中Resizer模块的增设,强化了YOLOX模型的特征提取能力; 在特征金字塔融合结构中添加高分辨率特征层,提高了小目标的识别能力。通过与CenterNet,Faster R-CNN,YOLOv3和YOLOX模型的对比实验结果表明,Re-YOLOX模型可满足近岸海域监测目标的识别需求,其mAP,mR和mF1值均优于其他识别模型。
参考文献
海洋工程对天津近岸海域环境的影响研究
[J].
The influence of ocean engineering in the coastal area of Tianjin
[J].
Gradient-based learning applied to document recognition
[J].DOI:10.1109/5.726791 URL [本文引用: 1]
Rich feature hierarchies for accurate object detection and semantic segmentation
[C]//
You only look once:Unified,real-time object detection
[C]//
基于tbd策略的船舶交通流视觉图像统计方法
[J].
Visual image statistics method of ship traffic flow based on tbd strategy
[J].
基于改进CenterNet的航拍图像目标检测算法
[J].
Target detection algorithm for aerial images based on improved CenterNet
[J].
基于改进 Faster R-CNN 的 SAR 船舶目标检测方法
[J].
A SAR ship detection method based on improved Faster R-CNN
[J].
复杂场景下基于增强YOLOv3的船舶目标检测
[J].
DOI:10.11772/j.issn.1001-9081.2020010097
[本文引用: 1]

为提升水上交通安全监管的智能化水平,进一步提高基于深度学习的船舶目标检测算法的定位精度和检测准确率,在传统YOLOv3算法基础上,提出用于船舶目标检测的增强YOLOv3算法。首先,在网络预测层引入预测框不确定性回归,以预测边界框的不确定性信息;然后,使用负对数似然函数和改进的二值交叉熵函数重新设计损失函数;其次,针对船舶形状使用K均值聚类算法重新设计先验锚框尺寸并平均分配到对应预测尺度;在网络训练阶段,使用数据增强策略扩充训练样本数量;最后,使用加入高斯软阈值函数的非极大值抑制(NMS)算法对预测框进行后处理。对各种改进方法和不同目标检测算法在真实海事视频监控数据集上进行对比实验。实验结果显示,与传统YOLOv3算法相比,带有预测框不确定性信息的YOLOv3算法的假正样本(FP)数量降低了35.42%,真正样本(TP)数量提高了1.83%,所以提高了准确率;增强YOLOv3算法在船舶图像上的平均准确率均值(mAP)达到87.74%,与传统YOLOv3算法和Faster R-CNN算法相比分别提高了24.12%和23.53%;所提算法的每秒钟检测图像数量达到30.70张,满足实时检测的要求。实验结果表明,所提算法在雾天和低照度等不良天气条件与复杂通航背景下,均能实现船舶目标的高精度稳定实时检测。
Ship target detection based on enhanced YOLOv3 in complex scenes
[J].
基于改进的Faster R-CNN船舶目标检测算法
[J].
Ship target detection algorithm based on improved Fast R-CNN
[J].
基于改进YOLOv3的船舶目标检测算法
[J].
Ship target detection algorithm based on improved YOLOv3
[J].
Learning to resize images for computer vision tasks
[C]//
CSPNet:A new backbone that can enhance learning capability of CNN
[C]//
Spatial pyramid pooling in deep convo-lutional networks for visual recognition
[J].DOI:10.1109/TPAMI.2015.2389824 URL [本文引用: 1]
基于深度学习的深层次多尺度特征融合目标检测算法
[J].
Deep multi-scale feature fusion target detection algorithm based on deep learning
[J].
Inception-v4,inception-resnet and the impact of residual connections on learning
[C]//
Microsoft COCO:Common objects in context
[C]//
基于Mask R-CNN的无人机影像路面交通标志检测与识别
[J].
Detection and recognition of road traffic signs in UAV images based on Mask R-CNN
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}