

0 引言
近年来,高分辨率遥感影像中涉及的地面区域广泛、包含丰富的数据信息,其空间分辨率较高,能够提供更为细致的地物信息,可以清晰地识别城市中的建筑物、道路、绿地等细节,甚至可以区分不同树种的森林类型,因此在检测所需目标的过程中会遇到一些困难。目标检测是在遥感影像中检测所需目标的具体位置以及判断目标的类别。由于遥感影像包含许多背景信息,这使得高分辨率遥感图像中目标检测更加不准确[1]。因此,针对高分辨率遥感图像中目标检测精度、召回率和均值平均精度(mean average precision,mAP)较低问题,本文提出了一种基于YOLO网络模型的目标检测方法。
目标检测算法主要有基于区域的卷积神经网络(region-based convolutional network method,R-CNN)系列[2⇓-4]算法、YOLO系列[5⇓⇓⇓-9]、单次多框检测(single shot multibox detector,SSD)[10]算法等。YOLO系列的目标检测算法在检测速度上相比于其他算法普遍较快,尤其在小目标检测方面具有很好的效果。Lamane等[11]提出了改变参数设置、不同结构和配置以及YOLOv5各个模型的热图图像检测对比实验; Puliti等[12]提出了一种基于YOLO-CNN架构的无人机图像物体检测方法,自动识别树木并根据雪的损伤对其进行分类; Li等[13]实现了YOLOv3,YOLOv4和YOLOv5模型在探地雷达图像隐蔽裂缝检测上的对比实验,得到YOLOv4模型比YOLOv5模型表现出更好的鲁棒性,可以准确地区分隐蔽裂缝和伪裂缝; Wang等[14]提出了一种用于高分辨率光学遥感图像,能够同时利用特征金字塔网络(feature pyramid network,FPN)和路径聚合网络(path aggregation network,PANET)特性的多检测头方法以及一种轻量级混合注意力模块的YOLO-HR网络; Qu等[15]在YOLOv3模型用距离交并比(distance intersection over union,DIoU)作为损失函数加快训练速度,加入卷积块注意力块(convolutional block attention module,CBAM)增强特征信息,特征金字塔改为自适应特征融合(adaptively spatial feature fusion,ASFF)以提高检测速度。Qi等[16]提出了在YOLOv5模型中增加挤压和激励注意力机制(squeeze-and-excitation network,SE)模块,实现了关键特征的提取,其准确率为91.07%,远高于R-CNN,SSD和YOLOv5模型的精度; 由Bao等[17]提出的BC-YOLO模型在无人机遥感影像上的检测精度和召回率分别达到86.2%和86.7%。
尽管目前已经有许多检测方法,但这些原始检测方法的性能已经开始下降,这是导致原始检测方法在高分辨率遥感图像目标检测中检测精度较低的原因之一。因此,目标的检测与识别变得具有挑战性。为了解决上述问题,本文采用了高分辨率遥感影像,利用YOLOv5算法在目标检测方法上进行了研究。本文的目的是结合注意力机制网络设计一种轻量级[18]的网络模型,用于高分辨率遥感影像中目标的检测,提升检测速度和精度。
YOLOv5是一种基于单阶段(one-stage)目标检测算法,具有较快的检测速度和较好的检测精度。YOLOv5采用了FPN和跨尺度预测技术,被广泛应用于各个领域的目标检测任务[19],因此可以有效处理高分辨率遥感影像中的目标多尺度问题。此外,YOLOv5还具有较强的实时性,适合在资源受限的遥感应用场景中使用。为了提高高分辨率遥感图像目标检测的精度和速度,本文提出了一种基于YOLOv5的轻量级检测模型GC-YOLOv5,在已有的YOLOv5算法中引入了轻量GhostConv模块[20]和提取关键特征的坐标注意力机制(coordinate attention, CA)模块[21]。本文借助于NWPU-VHR-10数据集[22-23]和RSOD数据集[24],将该模型应用于高分辨率遥感影像的目标检测。
1 研究方法
1.1 设计思路
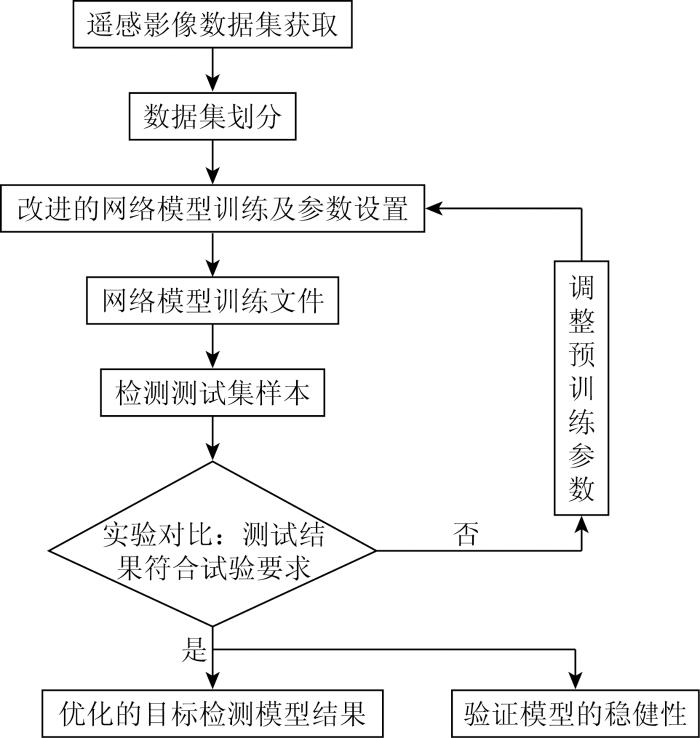
本文以YOLOv5算法为基础对模型进行设计,该算法引入坐标注意力机制和轻量级网络,能够提高目标的检测精度,降低训练模型的大小,并提高模型的训练效率,提高计算资源的利用率。本文方法的流程如图1所示。主要分为模型训练和模型测试2个阶段。首先从数据集公开平台获取遥感影像数据集并划分数据集; 其次,利用本文方法进行网络训练,利用训练好的模型对测试集样本进行检测; 最后,判断测试结果是否符合试验要求,如果不符合实验要求,则调整预训练参数重新训练,得到优化的物体检测模型。
图1
1.2 改进的GC-YOLOv5网络架构
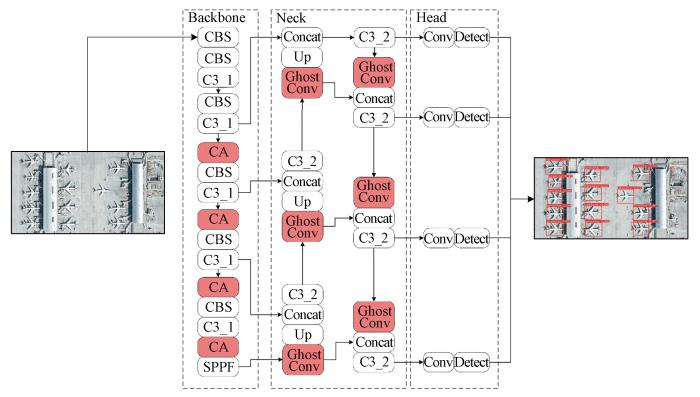
YOLOv5是由Jocher[25]提出的一种单阶段目标检测方法,通过直接回归候选框的相对位置来定位和分类目标。它现在已经是一个成熟的检测网络,在数据预处理、特征提取和特征融合方面进行了各种改进,大大提高了网络的检测精度。本文中,输入的图像尺寸为1 280像元×1 280像元,选取了YOLOv5s6模型作为基准并在此基础上进行了改进,利用YOLOv5在目标检测中的优势,对其改进使模型更适应遥感影像中目标的检测,提出一种GC-YOLOv5方法。
YOLOv5网络的核心模块主要包含普通卷积模块(convolutional-batchnormal-SiLu,CBS)、New CSP-Darknet53(C3)模块(包括C3_1、C3_2模块)、Spatial Pyramid Pooling-Fast(SPPF)模块和CSP-PAN模块。该算法在骨干网络(backbone network)阶段对输入的图像像素和目标的位置实现匹配,完成特征提取; 在颈部网络(neck network)阶段将提取出的特征进行自下而上的上采样(Up),并将其相同尺寸大小的网络层特征进行拼接融合(Concat); 最后在头部网络(head network)根据特征记忆将特征进行标准卷积(Conv)并检测(Detect)图像中的目标。
随着网络层数的增多,应增强特征提取从而提升目标检测的精度和速度; 但是这样会造成网络的计算负担,继而降低检测速度。针对这一问题对网络模型做出了改进,图2为改进后的网络模型结构(GC-YOLOv5),红色部分为修改的模块。针对网络模型的计算量和检测速度问题,在网络模型的颈部网络使用GhostConv模块代替原本的CBS模块,通过降低卷积的维度减少模型的参数数量,从而减少计算量; 之后为保证模型的精度,在骨干网络层引入了CA模块以增强骨干网络层的图像特征,使网络更加专注于感兴趣的目标,加强目标的识别能力,两者相互结合后既提升了模型的精度,又减少了模型参数的计算量。
图2
1.3 Backbone改进
图3
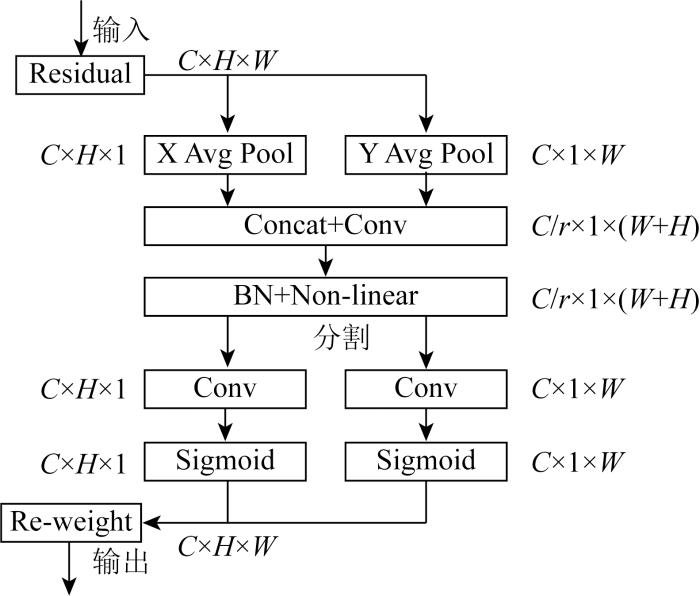
在给定输入X的情况下,
用2个空间范围的合并内核(H, 1)或(1, W)分别沿着水平坐标和垂直坐标对每个通道进行编码,因此,第c通道在高度h和宽度w的输出分别表示为:
式中zc为与第c通道相关联的输出; xc为与第c通道相关联的水平输入。输入的X直接来自具有固定核大小的卷积层,被视为局部描述符的集合。
以上2个转换分别沿2个空间方向聚合特征并生成一对方向感知的特征图。在此基础上,将式(2)和式(3)产生的聚集特征图连接起来,发送到共享的1 × 1卷积变换函数
式中:
式中σ为Sigmoid函数。扩展输出
1.4 Neck改进
如图4所示,GhostConv模块通过将传统的卷积运算与廉价的线性运算相结合,充分利用特征提取与特征映射冗余特性之间的关系,减少了模型的参数量和浮点计算,同时确保了检测性能。GhostConv模块采用普通卷积层生成少量的特征图,利用廉价的线性运算增强特征,增加通道数。且其线性运算具有很大的多样性,特征映射与线性运算一起执行,保持固有的特征映射,避免有用的特征地图信息丢失。假设输入图像
图4
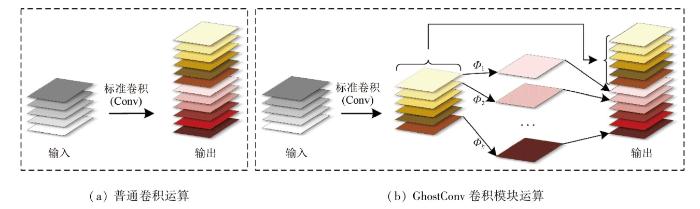
图4
普通卷积运算和GhostConv卷积模块运算
Fig.4
Normal convolution operations and GhostConv convolution module operations
式中: *为卷积运算;
在该卷积过程中,所需触发器的数量为
式中: y'i为Y'中的第i个本征特征映射,上述函数中的Φi, j是用于生成第j个重影特征映射yij的第j(除了最后一个)个线性运算。也就是说,y'i可以具有一个或多个重影特征映射
式中: d×d为线性运算核的大小(与k×k的大小相似); s为廉价的变换运算的数量,通常满足c>> s。结果表明普通卷积与GhostConv模块的加速比相等,且普通卷积的翻转大约是GhostConv模块的s倍,表明了GhostConv模块的计算量的优势。
2 实验
2.1 数据集
本文使用公开的数据集NWPU-VHR-10和RSOD,如图5所示。NWPU-VHR-10数据集中的所有图像来自于高分辨率卫星影像,提取自Google Earth和Vaihingen,总共有800张图像,包含飞机、油罐、船、操场、篮球场、网球场、码头、棒球场、汽车和桥梁等主要类别。由于数据集中150张图像没有目标,因此选取有目标的650张图像在模型中进行测试。RSOD数据集提取自Google Earth和Baidu Map,总共976张图像,包含了飞机、油罐、操场和立交桥等主要类别。本文中使用MakeSense在线工具对数据集进行了重新标注,生成以txt为后缀的标签文件。之后,分别将2个数据集以7∶1.5∶1.5的比例划分为训练集、验证集和测试集。
图5
图5
NWPU-VHR-10数据集和RSOD数据集样例图
Fig.5
Sample diagram of NWPU-VHR-10 dataset and RSOD dataset
2.2 实验环境
本文的实验在Windows11系统上进行工作,实验平台为Google Colaboratory,使用的是谷歌云端硬盘,含有GPU。实验环境的配置如表1所示。
表1 实验环境配置
Tab.1
| 平台 | 配置 |
|---|---|
| 脚本语言 | Python3.7.15 |
| 深度学习框架 | Torch1.12.1+cu113 |
| GPU类型 | Tesla T4 |
| NVIDIA | NVIDIA-SMI 460.32.03 |
| CUDA版本 | CUDA Version:11.2 |
网络模型的实验训练参数如表2所示。神经网络优化器(neural network optimizer)、批次大小(batch size)、学习率(learning rate)、动量参数(momentum parameter)、权重衰减(weight decay)为算法中默认值。训练轮数(training epochs)根据实验结果的拟合度设定,初始值为400,经过训练后,数据训练到200轮次时便达到拟合状态,便设定训练轮数为200进行训练。
表2 实验训练参数
Tab.2
| 参数 | 配置 |
|---|---|
| 神经网络优化器 | SGD |
| 批次大小 | 16 |
| 学习率 | 0.01 |
| 动量参数 | 0.937 |
| 权重衰减 | 0.000 5 |
| 训练轮数 | 200 |
2.3 评估指标
为了验证GC-YOLOv5模型的性能,本文用精度、召回率、均值平均精度(mean average precision,mAP)和模型的检测速度(frames per second,FPS)作为评估指标。精度表示正样本中被预测为正值的数量与正样本的比。召回率表示检测到的真实的正样本与正样本的比。精度和召回率的计算公式为:
式中: P为精度; R为召回率; TP为检测为正确的正样本; FP为检测为错误的正样本; FN为检测为错误的负样本; TN为检测为正确的负样本。
mAP用来评估网络的整体检测效果。mAP是对所有类别的AP相加并求平均值,mAP@0.5表示在计算过程中,将标签框与预测框的交并比(intersection over union,IoU)阈值设置为0.5。AP表示精度-召回率(P-R)曲线与坐标轴所包围的区域。IoU表示预测框与标签框重叠部分的面积与它们并集面积之比。AP和mAP的计算公式为:
式中 N为类别数量。
3 结果和分析
3.1 各个网络模块对模型性能的影响
为了验证每个方法对模型的影响,本文通过在网络模型逐个加入2种网络模块用于分析其对网络模型性能的影响,各个网络模块对模型的精度和mAP@0.5值所产生的影响如图6所示。表3为方法性能测试实验结果,表格记录了每个方法加入到网络中的精度、速度等数值,性能最优数值加粗表示。图中可以直观地看出本文提出的模型在训练期间产生的波动幅度较小,具有良好的拟合度。训练前期,模型的收敛速度快,训练100轮后,模型的精度和mAP值在后面超越了YOLOv5算法模型,曲线逐渐趋于平缓。根据表3可知,在网络结构中添加了基于坐标的注意力机制CA后,模型的召回率值提高3.1个百分点,mAP@0.5值提高0.6个百分点; 模型的参数数量增加了0.02×106个,权重文件大小增加1.3 MB,FPS提高了10.11 幅/s。使用轻量化GhostConv网络模块后,对网络结构的参数数量和检测速度的影响较大,模型的精度值提高0.3个百分点,参数数量减少了2.67×106个,权重文件大小减小了5.1 MB,FPS提高了6.97 幅/s。2种方法结合后,经过训练,模型的性能比原始模型更为稳定,结果表明GC-YOLOv5模型的精度、召回率、mAP值均优于YOLOv5模型,精度提高3.65%,召回率增长4.21%,mAP@0.5值增加2.84%,并且模型的参数数量也有所减少,减少了0.97×106个,生成的权重文件也减少了4.1 MB,FPS提高了5.86 幅/s。
图6
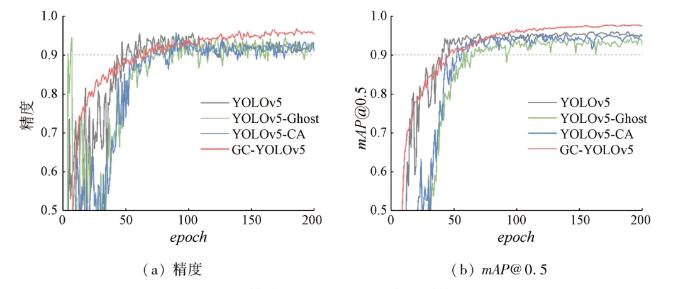
表3 方法性能测试实验结果
Tab.3
| 模型 | 精度/% | 召回率/% | mAP@0.5/% | 参数数量/106个 | 权重文件数量/MB | FPS/(幅·s-1) |
|---|---|---|---|---|---|---|
| YOLOv5 | 93.1 | 92.5 | 95 | 12.34 | 24.6 | 40.65 |
| YOLOv5-CA | 92.5 | 95.6 | 95.6 | 12.36 | 25.9 | 50.76 |
| YOLOv5-Ghost | 93.4 | 91.7 | 93.7 | 9.67 | 19.5 | 47.62 |
| GC-YOLOv5 | 96.5 | 96.4 | 97.7 | 11.37 | 20.5 | 46.51 |
3.2 NWPU-VHR-10数据集在不同算法下的对比实验
为了进一步验证所提方法的优势,将所提方法与Faster-RCNN算法进行了比较,模型的性能如表4所示。从表中可以看出,本文方法识别目标的精度比Faster-RCNN算法模型高出5.12%,比YOLOv5算法模型高出3.65%。mAP值比YOLOv5算法模型高出2.84%。在速度上,本文方法的FPS值比YOLOv5算法模型高出14.42%,是一个很好的突破。
表4 不同方法在NWPU-VHR-10数据集上的性能
Tab.4
| 模型 | 精度/ % | 召回 率/% | mAP@0.5/% | FPS/(幅·s-1) |
|---|---|---|---|---|
| Faster-RCNN | 91.8 | 93.8 | — | — |
| YOLOv5 | 93.1 | 92.5 | 95 | 40.65 |
| GC-YOLOv5 | 96.5 | 96.4 | 97.7 | 46.51 |
同时整理了在NWPU-VHR-10数据集上的部分可视化检测结果如图7所示,并对图像中每个算法模型的标签、类别进行了统计,如表5所示。典型的Two-Stage算法Faster-RCNN检测时,飞机的精度仅仅达到了91%,操场的精度仅为94%,网球场的精度为92%,其检测精度低于One-Stage算法YOLOv5。YOLOv5算法下飞机的精度为96%,操场的精度为97%,网球场的精度为96%。而改进过后的GC-YOLOv5算法比YOLOv5原始算法的检测精度高,飞机的精度达到了98%,操场的精度达到了99%,网球场的精度达到了97%。表5记录了把不同算法的检测结果和真实标签的对比,3种算法均全部检测出了飞机、网球场、操场,没有出现漏检情况。但Faster-RCNN算法多检测出一个棒球场,且识别错误。YOLOv5算法没有出现漏检和误检的情况。GC-YOLOv5模型同样没有出现漏检和误检的情况,但识别出了汽车并且识别正确,识别的精度为52%。结果表明本文提出的方法更具有优势。
图7

图7
NWPU-VHR-10数据集检测结果样例
Fig.7
Example of detection results of NWPU-VHR-10 dataset
表5 NWPU-VHR-10数据集中不同算法的检测结果与真实标签对比
Tab.5
| 图像类别 | 真实标签 | Faster-RCNN | YOLOv5 | GC-YOLOv5 |
|---|---|---|---|---|
| 飞机 | 13 | 13 | 13 | 13 |
| 网球场 | 4 | 4 | 4 | 4 |
| 操场 | 1 | 1 | 1 | 1 |
| 汽车 | 0 | 0 | 0 | 1 |
| 棒球场 | 0 | 1 | 0 | 0 |
3.3 RSOD数据集在不同算法下的对比实验
为了印证模型的性能,本文将所设计的网络模型运用在RSOD数据集上进行了实验,如表6所示,性能最优数值加粗表示。与YOLOv5模型相比,GC-YOLOv5模型的召回率提高了5.23%,mAP@0.5提高了4.06%。与Faster-RCNN相比,精度提高了1.74%,召回率提高了0.78%。
表6 不同算法在RSOD数据集上的性能
Tab.6
| 模型 | 精度/% | 召回率/% | mAP@0.5/% | FPS/(幅· |
|---|---|---|---|---|
| Faster-RCNN | 91.8 | 89.8 | -- | -- |
| YOLOv5 | 94.0 | 86.0 | 88.7 | 64.93 |
| GC-YOLOv5 | 93.4 | 90.5 | 92.3 | 64.93 |
在RSOD数据集上的可视化检测结果如图8所示。使用Faster-RCNN算法检测时,飞机的精度达到了91%,立交桥的精度为88%。YOLOv5算法下飞机的精度为94%,立交桥的精度为81%。而改进过后的GC-YOLOv5算法下飞机的精度达到了94%,立交桥的精度达到了92%。表7记录了把不同算法的检测结果和真实标签的对比,3种算法均全部检测出了飞机、立交桥,同样没有出现漏检情况。而Faster-RCNN算法多检测出一个立交桥,且识别错误,YOLOv5算法没有出现漏检和误检的情况,GC-YOLOv5模型同样没有出现漏检和误检的情况,但只有GC-YOLOv5模型对每个目标的检测精度全部达到了90%以上。
图8-1
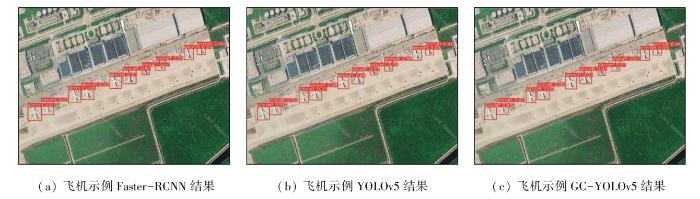
图8-2
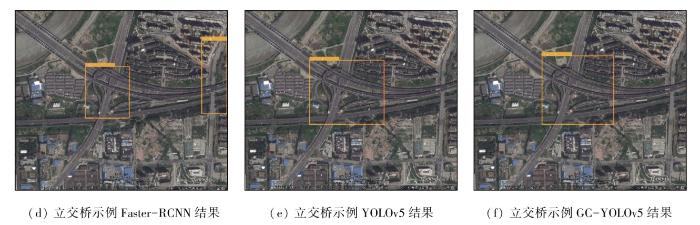
表7 RSOD数据集中不同算法的检测结果与真实标签对比
Tab.7
| 图像类别 | 真实标签 | Faster-RCNN | YOLOv5 | GC-YOLOv5 |
|---|---|---|---|---|
| 飞机 | 10 | 10 | 10 | 10 |
| 立交桥 | 1 | 2 | 1 | 1 |
3.4 方法适应性分析
YOLOv5算法结合GhostConv模块和CA注意力机制可以是一种有效的解决方案。高分辨率遥感影像通常具有较大的空间范围和丰富的细节信息,包括目标的形状、纹理和光谱特征。同时,高分辨率遥感影像中可能存在大量的小目标和密集的目标分布,如建筑物、车辆和船只等。因此,高分辨率遥感影像目标检测需要具备较高的检测精度和较快的检测速度。
GhostConv模块是一种轻量级的卷积神经网络模型,具有较小的模型体积和较低的计算复杂度,通过减少网络中的计算量,并使用更少的参数来实现更好的特征表示,适合在资源受限的遥感设备上部署。因此,将GhostConv模块引入YOLOv5算法中,可以进一步提高目标检测算法在高分辨率遥感影像中的性能。CA注意力机制是一种通道级别的注意力机制,用于在网络中学习通道间的关联信息。在高分辨率遥感影像目标检测中,通过引入CA注意力机制,可以自适应地调整不同通道的权重,使网络更关注对目标有贡献的通道,从而提升目标检测的精度。将GhostConv模块和CA注意力机制与YOLOv5算法结合,可以在高分辨率遥感影像目标检测中获得以下优势:
1) 较小的模型体积和低的计算复杂度。GhostNet模型可以减小网络的模型体积和计算复杂度,使得算法在资源受限的遥感设备上更加适用,同时CA注意力机制可以通过自适应地调整通道权重,进一步提高网络的性能。
2) 较好的目标检测精度。GhostConv模块通过引入Ghost module来提取更好的特征表示,结合YOLOv5的特征金字塔网络和跨尺度预测技术,可以更好地处理高分辨率遥感影像中的目标多尺度问题,从而提高目标检测的精度。同时,CA注意力机制可以在网络中学习通道间的关联信息,帮助网络更加关注对目标有贡献的通道,进一步提升目标检测的准确性。
3) 较快的检测速度。YOLOv5作为一种单阶段目标检测算法,具有较快的检测速度,适合在实时或近实时的遥感应用场景中使用。GhostConv模块的轻量化设计也有助于加速整个算法的推理过程,从而在高分辨率遥感影像目标检测中保持较快的检测速度。
总的来说,YOLOv5算法结合GhostConv网络和CA注意力机制在高分辨率遥感影像目标检测上具有较好的适应性。它可以在保持较小的模型体积和较快的检测速度的同时,提高目标检测的精度,适用于资源受限的遥感设备和实时或近实时的遥感应用场景。
4 结论
检测高分辨率遥感图像中的目标时,方便、快速、高精度的检测模型是非常重要的。针对现有目标检测算法在高分辨率遥感图像检测精度不够理想的问题,本文提出的一种GC-YOLOv5轻量级的高分辨率遥感图像目标检测网络模型。该算法是在YOLOv5模型的基础上,结合轻量级GhostConv模块解决了传统算法在高分辨率遥感图像检测中的难题。
1) 模型检测精度为96.5%、召回率为96.4%,mAP@0.5值为97.7%,分别提高了3.65%,4.21%和2.84%。
2) 针对高分辨率遥感图像中尺寸差别较大和不同角度的目标同样能实现精准的检测。
3) 在NWPU-VHR-10数据集和RSOD 数据集上验证了该模型,并证明了该模型的稳健性。该模型一定程度上解决了目标检测精度低下的问题。
GC-YOLOv5模型能够实现对不同类别的目标进行检测,各方面性能得到提升,但仍存在一些不足之处需要改进。与YOLOv5相比,虽然GC-YOLOv5在检测物体方面具有更好的性能,但仍有一些小目标被遗漏或者识别错误,导致目标被遗漏或者识别错误的主要原因是目标与背景的色差较小,与部分物体形状相似。虽然多尺度目标检测算法工作更有效,但它需要大量的计算,并且对硬件配置有很高的要求。同时,还应考虑其他干扰因素的影响,例如云雾遮挡和太阳照射出现的阴影。在未来的工作中,我们将收集更多的目标与背景颜色接近的图像作为研究数据,在保证精度的前提下增强网络模型的适应性。
参考文献
Small object detection in remote sensing images based on super-resolution
[J].
Rich feature hierarchies for accurate object detection and semantic segmentation
[C]//
Fast R-CNN
[C]//
Faster R-CNN:Towards real-time object detection with region proposal networks
[J].
You only look once:Unified,real-time object detection
[C]//
YOLO9000:Better,faster,stronger
[C]//
YOLOv3:An incremental improvement
[J/OL].
YOLOv7:Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
[J/OL].
A review of YOLO algorithm developments
[J].
SSD:single shot MultiBox detector
[C]//
Classification of targets detected by mmWave radar using YOLOv5
[J].
Automatic detection of snow breakage at single tree level using YOLOv5 applied to UAV imagery
[J].
Detection of concealed cracks from ground penetrating radar images based on deep learning algorithm
[J].
Remote sensing image super-resolution and object detection:Benchmark and state of the art
[J].
Remote sensing image target detection:Improvement of the YOLOv3 model with auxiliary networks
[J].
An improved YOLOv5 model based on visual attention mechanism:Application to recognition of tomato virus disease
[J].
A defect detection method based on BC-YOLO for transmission line components in UAV remote sensing images
[J].
Lightweight convolutional neural network with knowledge distillation for cervical cells classification
[J].
A real-time detection algorithm for kiwifruit defects based on YOLOv5
[J].
GhostNet:More features from cheap operations
[C]//
Coordinate attention for efficient mobile network design
[C]//
Multi-class geospatial object detection and geographic image classification based on collection of part detectors
[J].
A survey on object detection in optical remote sensing images
[J].
Accurate object localization in remote sensing images based on convolutional neural networks
[J].
Ultralytics/YOLOv5:V6.2-YOLOv5 classification models,apple M1,reproducibility,clearML and deci.ai integrations
[Z].
Squeeze-and-excitation networks
[C]//
CBAM:Convolutional block attention module
[C]//

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}