

0 引言
近年来,深度卷积神经网络(deep convolutional neural network, DCNN)以其卓越的特征表示能力逐渐受到广泛认可,同时也使得基于DCNN的语义分割算法成为研究热点,如FCN[11],UNet[12],SegNet[13],PSPNet[14],Deeplabv2[15]等多个算法相继被提出,并不断刷新着语义分割算法精度的里程碑。然而,这些方法在训练集和测试集之间的数据域高度一致时,才能表现出优异的性能,并且对数据域的变化十分敏感。当训练数据和测试数据存在域偏差时,例如影像地理位置、传感器成像方法和获取时天气条件等因素的影响会导致影像数据之间出现颜色、纹理、空间分辨率和背景的差异,这使得在一个数据集(源域)上训练的模型一旦应用于另一个数据集(目标域)进行预测时,模型的准确性可能会显著下降。
为解决上述问题,最常见的方法是在目标域上进行大量像素级标注并重新训练模型,然而,这种方法成本高且耗时费力,限制了其在实践中的可行性。另外,利用已经训练好的模型在目标域上进行微调,或者在源域数据集上进行样本扩增也是一种选择,但这些方法并未取得理想的效果。相应地,无监督域自适应(unsupervised domain adaptation, UDA)方法应运而生,旨在解决源域和目标域之间的域偏差问题,并在目标域没有任何标注的情况下实现高质量的分割结果。
目前的UDA方法可以大致分为3类[16-17]: 生成方法、自训练方法和对抗学习方法。生成方法利用生成对抗网络作为生成模型,通过在源域和目标域之间进行图像转换来减小域偏差[18⇓⇓-21],但生成的影像准确性有限,而分割模型性能又过度依赖于生成影像的质量。自训练方法通过使用模型预测的伪标签进行迭代训练,以提升模型在目标域上的性能[22-23],但其对初始伪标签质量要求较高,并且容易出现错误累积的问题。对抗学习方法则通过生成器和鉴别器之间的极小极大博弈机制,来解决源域和目标域之间的域偏差问题[24⇓⇓-27],同时还克服了生成方法和自训练方法所面临的限制。因此,本文研究工作主要围绕基于对抗学习的UDA方法展开。
基于对抗学习的UDA方法因其卓越的性能表现而受到广泛研究。为此,Tsai等[24]提出了AdaptSeg,利用对抗学习思想将源域和目标域的结构化输出空间进行对齐; Luo等[25]提出了CLAN,通过引入类别级别的对抗学习使得源域和目标域在语义上更一致; Vu等[26]提出了Advent方法,通过最小化域间的熵差异来进行域自适应; Guo等[27]提出了MetaCorrection,结合元学习和对抗学习的思想来缩小源域和目标域的特征分布差异。上述方法大多采用整体性的域对齐方式来解决域偏差问题,但是由于空间分辨率、外观分布、对象大小和场景上下文信息的影响,即使是同一影像的不同区域,在进行域对齐时也存在不同的困难程度。从整体角度来看,以相同的权重对齐影像中的每个区域特征,可能导致已对齐区域出现不对齐的负迁移现象。从类别角度来看,一张影像通常包含多种不同的类别,由于不同类别的域对齐困难程度不同,这种整体性的域对齐方式,也可能会导致类别的负迁移现象出现。
基于上述分析, 本文提出了一个UDA语义分割框架,并将其命名为OA-GAL。该框架通过不同的域对齐策略,以及特征的多尺度感知和目标对象间的信息关联,以实现对负迁移现象的缓解,同时提升分割网络的准确性和鲁棒性。随后使用HRSI对本文所提出的OA-GAL进行实验分析与评估。
1 研究方法
1.1 OA-GAL框架
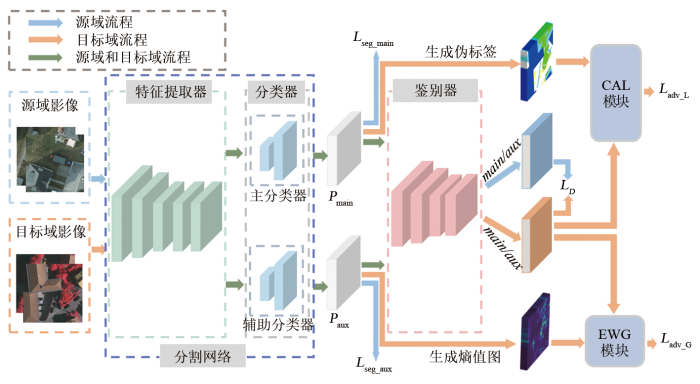
本文提出的UDA语义分割框架(OA-GAL)如图1所示。图中main为与主分类器相关的值,aux为与辅助分类器相关的值,
图1
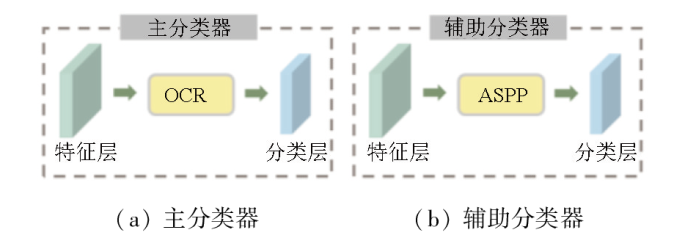
1.2 OCR/ASPP双分类器组合
HRSI具有出色的空间分辨率和广泛的覆盖范围,这使得目标对象的细节和全局上下文信息变得至关重要。对象上下文表征(object context representation, OCR)模块[28]通过引入注意力机制和上下文感知,利用对象之间的关联信息来提供更丰富的对象表示,从而提升分割模型对图像中对象间关系的理解能力。同时,空洞空间金字塔池化(atrous spatial pyramid pooling, ASPP)模块[15]通过并行空洞卷积和全局平均池化操作,捕获多尺度的上下文信息,扩展感受野并实现全局特征融合,从而增强分割模型对不同尺度对象的识别能力。以往一些研究者的工作也证明了OCR模块对目标对象上下文特征关系优秀的学习能力[29-30],以及ASPP模块对于全局多尺度上下文信息的获取能力[15]。这2个模块对于提升高分遥感影像中复杂场景目标对象的准确识别和分割能力有着重要的意义。
为了实现高质量的分割结果,采用Deeplabv2 [15]作为基础分割网络。在分割网络G的具体实现中,如图2所示,在经过特征提取器处理得到的特征层之后插入一个OCR模块,随后进行分类,并将其作为主分类器。辅助分类器使用Deeplabv2中带有ASPP模块的分类器。带有OCR模块的主分类器通过对象间关系建模,捕捉目标之间的空间布局和语义相互作用,从而增强目标的上下文表示能力; 而带有ASPP模块的辅助分类器,通过多尺度感受野,能够捕捉不同尺度上的语义信息,从而适应遥感影像中的目标变化和尺度差异。将2个分类器相结合,实现了特征的多尺度感知和目标对象之间关系的建模。这样的组合能够充分利用HRSI的丰富信息,提高分割的准确性和鲁棒性,以获得更好的域适应性能。
图2
1.3 EWG模块
从整体的角度上来看,大多数UDA框架都是以相同的强度对齐目标域和源域的不同区域,但不同区域中的内容不同,导致其对齐难度也是不同的。并且,目标域中大部分预测不准确的区域通常是由于这些区域未能得到良好的对齐。
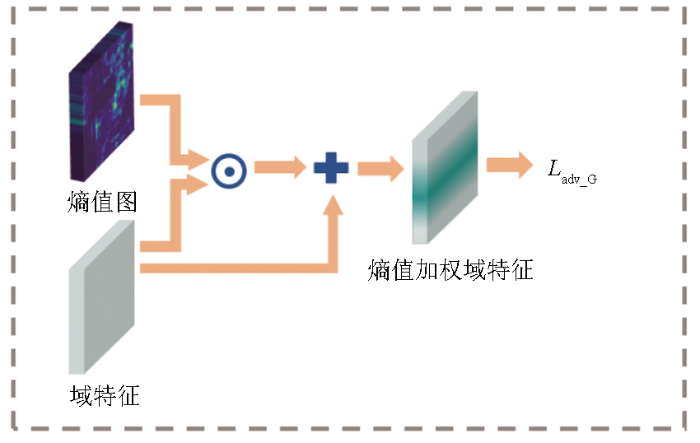
鉴于对齐难度与空间位置相关,并且辅助分类器可以更好地利用目标域多尺度特征和全局上下文信息,可以利用辅助分类器的预测结果进行熵值处理。通过观察预测结果的熵值判断其偏差大小,高熵值表示预测结果的偏差较大,低熵值表示预测结果的偏差较小。因此,如图3所示,EWG模块将高熵值区域作为对域对齐的重点关注对象,并给予这些区域更大的损失权重,迫使鉴别器在对抗训练中对齐目标域中高熵值区域的域特征分布,同时降低对低熵值区域的关注程度。
图3
具体可表示为,用辅助分类器的预测结果
式中: C为类别数;
式中:
基于熵值加权注意力机制的全局对齐损失
通过对域特征和熵值图进行加权运算,给予难以对齐的区域更大的损失权重,以便鉴别器更加专注地对齐这些区域。这种整体性的区域加权策略使得容易对齐和困难对齐的区域具有不同的权重,避免了使用相同权重对所有区域进行对齐的原始方法可能引发的负迁移问题的出现。
1.4 CAL模块
从类别的角度来看,目标域域特征的不同空间位置对应的类别属性可能不同,因此整体域对齐方式可能会导致类别的负迁移现象。在本文中,CAL先将不同空间位置的域特征与相应的类别属性进行匹配,再利用主分类器对类别对象间上下文语义特征敏感的特点,通过伪标签生成策略结合目标域的主分类器预测结果
式中:
图4为CAL模块示意图。
图4

如图4所示,一旦获得了此处的伪标签,便可以通过伪标签为目标域的域特征
式中:
在进行了不同类别的域特征区域选取后,利用平均池化对该类别的域特征进行聚合,域特征逐类聚合策略可表示为:
式中:
最后,基于逐类别域特征聚合的局部对齐损失
与直接整体对齐域特征的方法相比,本文提出的逐类别域特征聚合策略能够使域鉴别器知道每个类别的域特征区域,并对每个类别的域特征进行分别聚合和对齐,互不干扰。此外,对于那些不确定类别的区域,由于缺乏类别标签,不进行域特征聚合,即域特征分布不会调整,这2点都有效防止类别负迁移现象的出现。
1.5 模型训练
本文提出的UDA语义分割框架主要使用4个损失函数进行训练,包括分割损失、自适应对抗损失、全局对齐损失和局部对齐损失。其中,本文使用多类交叉熵损失函数计算分割损失
式中:
对于模型中的鉴别器,本文使用对抗训练和二类交叉熵损失来对其进行训练,其损失函数
式中:
为了更好地对齐源域特征与目标域特征的分布,本文使用EWG模块和CAL模块来进行域对齐,对抗性损失
式中
2 实验设计
2.1 实验数据
本实验采用ISPRS在遥感图像分割和对象识别领域中常用的2个HRSI数据集Vaihingen和Potsdam。其中Vaihingen数据集包含33幅不同大小的遥感影像,正射影像和和数字地表模型(digital surface model,DSM)的空间分辨率为0.09 m,Potsdam 数据集包含38幅相同尺寸的遥感影像,正射影像和DSM的空间分辨率为0.05 m。
如图5所示,Potsdam数据集和Vaihingen数据集都具有较高的分辨率和丰富的地物细节。并且Potsdam数据集中的对象类别与Vaihingen类似,包括建筑物、道路、树木、汽车等。在本实验中将这2个数据集裁剪成512像素×512像素大小, 横向和纵向重叠度均为50%, 并将裁剪后的Potsdam数据集作为源域,Vaihingen数据集作为目标域。最后,2个数据集都随机划分20%的图像作为测试集,剩下的80%作为训练集。
图5

2.2 网络结构设置
对于域鉴别器D,采用了深度卷积生成对抗网络(deep convolutional generation adversarial network, DCGAN)[31]。在得到概率预测图后,将其输入到DCGAN的4个带有泄露修正线性单元(leaky ReLU)的卷积层中,并通过1×1卷积层输出输入值的域类别(源域或目标域)。
2.3 实验参数设置
2.4 精度评价指标
为了公正评估分割网络G在每个类别上的性能,计算各类别的交并比(intersection over union,IOU)和平均交并比(mean intersection over union,mIOU)[11]来综合考虑模型对于各类别的性能并评估模型的整体性能。公式分别为:
式中: TP为真阳性; FP为假阳性; FN为假阴性; i为类别序号; C为类别总数。
2.5 对比方法及实验结果分析
表1 Potsdam→Vaihingen的UDA分割结果示例
Tab.1
 |
对分割效果进行定量评价,实验结果见表2,第一行是Deeplabv2(仅使用源域数据进行训练的分割模型,用于预测目标域图像)。从第2—5行是与UDA相关的语义分割模型的对比方法,第6行是本文提出的OA-GAL,加粗字体表示每列的最高值。从表2可以看出,相较于未进行域自适应的Deeplabv2,OA-GAL在各类别的IOU上都有显著提升,mIOU从0.264 7提升到0.474 8。此外,相对于其他模型,OA-GAL在树木、低矮植被、建筑、道路等类别的IOU明显优于其他模型,但在其他类别和汽车这2个小类别的IOU略低于个别模型。总体而言,本文提出的OA-GAL优于其他模型,并获得了更高的mIOU分数。
表2 Potsdam→Vaihingen对比实验的结果评价
Tab.2
| 模型 | mIOU | IOU | |||||
|---|---|---|---|---|---|---|---|
| 其他类 | 汽车 | 树木 | 低矮植被 | 建筑 | 道路 | ||
| Deeplabv2 | 0.264 7 | 0.066 3 | 0.074 5 | 0.186 5 | 0.244 3 | 0.488 6 | 0.527 9 |
| AdaptSegNet | 0.423 1 | 0.075 2 | 0.263 4 | 0.457 8 | 0.401 1 | 0.720 1 | 0.620 9 |
| CLAN | 0.410 1 | 0.084 7 | 0.164 0 | 0.544 1 | 0.274 1 | 0.773 0 | 0.619 9 |
| ADVENT | 0.434 8 | 0.168 6 | 0.221 8 | 0.510 7 | 0.316 9 | 0.768 2 | 0.622 4 |
| Metacorrection | 0.440 4 | 0.102 8 | 0.249 5 | 0.517 1 | 0.400 1 | 0.744 8 | 0.628 1 |
| OA-GAL | 0.474 8 | 0.114 8 | 0.219 5 | 0.573 2 | 0.435 5 | 0.818 2 | 0.687 4 |
此外,如图6所示,本文还选取2个示例,可视化了框架中CAL模块的伪标签生成结果和EWG模块的熵值图生成结果。本文将预测概率图的阈值
图6

图6
伪标签和熵值图可视化示例
Fig.6
Example of visualization of pseudo labels and entropy regions
2.6 消融实验
为了验证所提出方法的有效性,本文在不同设置下评估了从Potsdam到Vaihingen的模型测试结果。基线模型表示AdaptSegNet模型(不采用OCR/ASPP双分类器组合、CAL模块、EWG模块),具体结果如表3所示。第2—5行展示了在基线基础上逐渐添加OCR/ASPP双分类器组合、CAL模块和EWG模块后的结果。
表3 消融实验
Tab.3
| 模型 | OCR/ASPP | CAL | EWG | mIOU |
|---|---|---|---|---|
| 基线模型 | 0.423 1 | |||
| OCR/ASPP | √ | 0.438 2 | ||
| OCR/ASPP+CAL | √ | √ | 0.451 9 | |
| OCR/ASPP+EWG | √ | √ | 0.453 7 | |
| OA-GAL | √ | √ | √ | 0.474 8 |
当引入OCR/ASPP双分类器组合到模型后,mIOU提高到0.438 2。这表明OCR/ASPP双分类器组合可以分别从类别上下文感知和多尺度上下文信息的角度出发,去增强分类模型的理解能力和泛化能力,有助于更好地进行域对齐。
在分别将CAL和EWG插入到域鉴别器之后,mIOU进一步提高到0.451 9和0.453 7。这证明了针对每个类别单独对齐域特征且互不干扰的方法以及根据不同区域给予不同关注度的域对齐方法的有效性。最后,与仅插入CAL或EWG相比,当同时添加CAL和EWG时,mIOU提升到0.474 8,均有所提升。这验证了CAL和EWG模块在域对齐过程中的互补性,也验证了对不同区域进行不同强度的域对齐策略的可行性。
3 结论
本文提出了一个基于对抗学习的无监督自适应框架OA-GAL,用于HRSI的分割,并与其他同类型方法进行了对比实验,最后对实验结果和精度进行了对比分析,验证了OA-GAL性能的有效性与优越性,结论如下:
1) 本文在OA-GAL的分割网络G中提出了OCR/ ASPP双分类器组合,实现了特征的多尺度感知和目标对象间的信息关联,提高了对HRSI分割的准确性和鲁棒性。
2) 在OA-GAL的鉴别器D中提出了 EWG模块和CAL模块,其中EWG专注于解决目标域中难以实现对齐的区域,而CAL则负责实现各类别间相互独立的域对齐效果。两者的结合产生了更精细、全面的对齐结果,提高了鉴别器D的域自适应效果。
3) 与大多数同类型方法采用的整体性域对齐方式不同,OA-GAL采用针对不同特征区域的差异性关注度进行域对齐。实验证明,OA-GAL能够更有效地缓解不同域之间的域偏差问题,并在无标签的目标域上获得良好的分割结果。
通过分析,认识到OA-GAL对于类似于汽车、其他类等小类别地物的分割能力方面存在一些不足,因此在后续工作中会着重去优化小类别地物的分割。值得注意的是,OA-GAL在建筑和道路的分割结果方面表现较为出色,后续会将该框架应用于建筑物或道路等单类域自适应分割问题进行进一步验证。
参考文献
面向高分辨率遥感影像大范围道路提取的深度学习方法研究
[J].
Deep learning method for large-scale road extraction from high resolution remote sensing imagery
[J].
基于多源国产高分辨率遥感影像的山区河流信息自动提取
[J].
Automatic extraction of mountain river information from multiple Chinese high-resolution remote sensing satellite images
[J].
基于高分辨率卫星遥感影像滑坡提取方法研究现状
[J].
DOI:10.11873/j.issn.1004-0323.2023.1.0108
[本文引用: 1]

滑坡具有强大的爆发力和破坏性,是世界上发生频率较高的自然灾害之一,给人们的生命财产造成了严重的损害。灾后准确快速的提取滑坡,获取滑坡的分布范围,对滑坡灾害调查及危险性评估极为重要。围绕基于高分辨率卫星遥感影像监测滑坡的方法进行了调研,首先介绍了滑坡在高分辨率卫星遥感影像上的解译特征,而后论述了滑坡提取方法和精度评价分析方法的研究进展,最后总结了当前方法的优势与不足,以及未来研究的发展方向。结果表明:深度学习方法具有较大的潜力,未来应加强深度学习与其他自动化解译方法的结合在滑坡监测中的应用,解决样本规模对模型结果的影响,实现模型的可迁移性,提高其自动化程度。
Research status of landslide extraction methods based on high-resolution satellite remote sensing images
[J].
基于高分辨率遥感影像的建筑物提取
[J].
DOI:10.13474/j.cnki.11-2246.2023.0191
[本文引用: 1]
高分辨率遥感影像不仅具有丰富的光谱、空间分布、形状和纹理特征,也包含清晰的场景语义信息。本文以安徽省枞阳县枞阳镇为研究区域,以高分辨率影像为基础数据源,利用eCognition软件中深度学习与面向对象相结合的方法进行建筑物自动提取。结果表明,该方法具有更好的建筑物提取效果,总体分类精度达96.8%,可用于通过高分辨率影像进行建筑物提取的生产。
Buildings extraction based on high-resolution remote sensing imagery
[J].
DOI:10.13474/j.cnki.11-2246.2023.0191
[本文引用: 1]
High-resolution remote sensing images not only have rich spectrum, spatial distribution, shape and texture features, but also contain clear scene semantic information. Taking Zongyang town, Zongyang county, Anhui province as the research area, and using high-resolution images as the basic data source, the deep learning and object-oriented method in eCognition software is used to automatically extract buildings in this paper. The results show that the method of combining deep learning with object-oriented has a better effect of building extraction, and the overall classification accuracy reaches 96.8%, which can be used for building extraction production based on high-resolution images.
高分辨率遥感影像耕地提取研究进展与展望
[J].
Progress and prospect of cultivated land extraction from high-resolution remote sensing images
[J].
基于WorldView-2影像和语义分割模型的小麦分类提取
[J].
DOI:10.11873/j.issn.1004-0323.2022.3.0564
[本文引用: 2]
为使用高分辨率遥感影像和深度学习语义分割模型实现快速准确的小麦种植空间信息提取,以WorldView-2遥感影像为数据源,制作尺度分别为128×128、256×256、512×512的样本数据集,对U-net和DeepLab3+语义分割模型的参数进行训练,建立小麦遥感分类模型;通过与极大似然和随机森林方法比较,检验深度学习分类效果。结果显示:①不同尺度样本训练得到的模型总体精度、Kappa系数分别在94%和0.82以上,模型精度稳定,样本尺度大小对小麦分类提取模型影响较小;②深度学习方法的小麦分类总精度和Kappa系数分别在94%和0.89以上,极大似然和随机森林则在92%和0.85以下,表明该研究建立的小麦遥感分类模型优于传统分类方法。研究结果可为高分辨率遥感影像作物种植信息的深度学习方法提取提供参考。
Winter wheat extraction of WorldView-2 image based on semantic segmentation method
[J].
结合空洞卷积的FuseNet变体网络高分辨率遥感影像语义分割
[J].
Semantic segmentation of high-resolution remote sensing images based on improved FuseNet combined with atrous convolution
[J].
MANet:A multi-level aggregation network for semantic segmentation of high-resolution remote sensing images
[J].
B-FGC-net:A building extraction network from high resolution remote sensing imagery
[J].
A review of semantic segmentation using deep neural networks
[J].
Fully convolutional networks for semantic segmentation
[C]//
SegNet:A deep convolutional encoder-decoder architecture for image segmentation
[J].
DOI:10.1109/TPAMI.2016.2644615
PMID:28060704
[本文引用: 1]
We present a novel and practical deep fully convolutional neural network architecture for semantic pixel-wise segmentation termed SegNet. This core trainable segmentation engine consists of an encoder network, a corresponding decoder network followed by a pixel-wise classification layer. The architecture of the encoder network is topologically identical to the 13 convolutional layers in the VGG16 network [1]. The role of the decoder network is to map the low resolution encoder feature maps to full input resolution feature maps for pixel-wise classification. The novelty of SegNet lies is in the manner in which the decoder upsamples its lower resolution input feature map(s). Specifically, the decoder uses pooling indices computed in the max-pooling step of the corresponding encoder to perform non-linear upsampling. This eliminates the need for learning to upsample. The upsampled maps are sparse and are then convolved with trainable filters to produce dense feature maps. We compare our proposed architecture with the widely adopted FCN [2] and also with the well known DeepLab-LargeFOV [3], DeconvNet [4] architectures. This comparison reveals the memory versus accuracy trade-off involved in achieving good segmentation performance. SegNet was primarily motivated by scene understanding applications. Hence, it is designed to be efficient both in terms of memory and computational time during inference. It is also significantly smaller in the number of trainable parameters than other competing architectures and can be trained end-to-end using stochastic gradient descent. We also performed a controlled benchmark of SegNet and other architectures on both road scenes and SUN RGB-D indoor scene segmentation tasks. These quantitative assessments show that SegNet provides good performance with competitive inference time and most efficient inference memory-wise as compared to other architectures. We also provide a Caffe implementation of SegNet and a web demo at http://mi.eng.cam.ac.uk/projects/segnet.
Pyramid scene parsing network
[C]//
DeepLab:Semantic image segmentation with deep convolutional nets,atrous convolution,and fully connected CRFs
[J].
A review of single-source deep unsupervised visual domain adaptation
[J].
The eyes of the gods:A survey of unsupervised domain adaptation methods based on remote sensing data
[J].
Unpaired image-to-image translation using cycle-consistent adversarial networks
[C]//
FDA:Fourier domain adaptation for semantic segmentation
[C]//
CyCADA:Cycle-consistent adversarial domain adaptation
[J/OL].
Coarse-to-fine domain adaptive semantic segmentation with photometric alignment and category-center regularization
[C]//
Unsupervised domain ada-ptation for semantic segmentation via class-balanced self-training
[C]//
Rectifying pseudo label learning via uncertainty estimation for domain adaptive semantic segmentation
[J].
Learning to adapt structure output space for semantic segmentation
[C]//
Taking a closer look at domain shift:Category-level adversaries for semantics consistent domain adaptation
[C]//
ADVENT:Adversarial entropy minimization for domain adaptation in semantic segmentation
[C]//
MetaCorrection:Domain-aware meta loss correction for unsupervised domain adaptation in semantic segmentation
[C]//
Object-contextual representations for semantic segmentation
[J/OL].
Segmentation transformer:Object-contextual representations for semantic segmentation
[J/OL].
Recognizing zucchinis intercropped with sunflowers in UAV visible images using an improved method based on OCRNet
[J].
Unsupervised representation learning with deep convolutional generative adversarial networks
[J/OL].
Large-scale machine learning with stochastic gradient descent
[C]//
Adam:A method for stochastic optimization
[J/OL].
Deep residual learning for image recognition
[C]//

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}