

0 引言
煤矸石是煤矿开采过程中产生的灰色或黑色岩石[1],其产出量约占采煤量的10%~15%[2],煤矸石产出后堆积在煤矿区周围形成人造地表景观[3]。目前我国煤矸石积存量已超过80亿t,并仍以1.5亿t/a的速度增长[4]。煤矸石综合利用途径广泛,当前主要用于采空区充填、道路材料应用、发电、熔融烧结等,但调查显示我国煤矸石利用率仅60%~70%[5],仍有大量煤矸石采用露天堆放的方式放置。由于煤矸石孔隙度较大,松散堆积状态下其内部残煤及黄铁矿极易与空气中的氧气和水接触,发生化学反应释放热量,导致煤矸石自燃,释放出大量NOx和SO2等气体,严重污染大气环境[5-6]。除此之外,煤矸石中的锰、铬、硒、镍、砷等多种微量元素会随着大气降水进入土壤和水体,对生态环境造成破坏[7]。因此,实现煤矸石山的有效识别和快速监测对矿区生态环境保护和矿区安全生产十分重要。
遥感技术是在地形条件复杂地区实现煤矸石山识别与监测的有效手段,当前已有利用遥感技术开展煤矸石山及其周边地物识别的实例。荆青青等[8]利用ASTER遥感影像基于主成分分析法(principal component analysis,PCA)及马氏距离(Mahalanobis distance,MD)监督分类方法提取了煤矸石分布范围; Nádudvari[9]利用Landsat ETM+影像获取了地表温度图和归一化差异雪指数(normalized difference snow index,NDSI),探测了煤矸石山火点的分布、强度和演变等信息; 李嘉琪等[2]利用地温反演结果与阈值分析法识别出了自燃煤矸石山的区域分布范围; 周涛等[10]利用无人机遥感影像基于色彩空间变换、纹理滤波特征及支持向量机(support vector machine,SVM)分类方法实现了煤矸石山植被的分类提取。前人利用不同类别的遥感影像在自燃煤矸石山提取、煤矸石堆存区植被提取等方面开展了理论研究和实践,但是在大尺度的煤矸石堆积区识别与提取方面,研究者仅从改进影像空间分辨率(如利用高空间分辨率的无人机遥感影像)或人工改进分类特征等方面提升煤矸石堆存区的识别提取效果,所采用的主要算法仅为地表温度反演算法、阈值提取方法、植被参数反演等遥感参量结合传统监督分类方法,提取结果受建筑物、工厂、道路等地物干扰严重。当前已有的基于高空间分辨率影像与深度学习网络模型提取煤矸石堆存区的先例较少,且该方法存在对小尺度煤矸石山识别精度低、数据计算量大等问题[11]。煤矸石山是空间尺度变化较大的识别目标,基于随机森林算法的地物识别模型能够有效利用高空间分辨率影像的空间信息对其进行提取,且对训练样本的需求小,数据计算量小[12]。
本研究在已有成果的基础上,选取高分二号(GF-2)国产高空间分辨率遥感影像,对煤矸石堆存区及周围地物的光谱特征、纹理特征、地形特征等17种特征类别进行分析,构建特征数据集并进行特征优选,确定适合研究区煤矸石山提取的最优特征组合。在此基础上利用交叉验证方法优化调整随机森林控制参数及训练样本进行分类,并利用混淆矩阵方法对煤矸石山提取结果进行精度评价,为研究区煤矸石山露天堆存区治理工作提供依据。
1 研究区概况及数据源
研究区位于福建省龙岩市新罗区,地理坐标范围为N25°17'24″~25°19'19″,E117°09'40″~117°11'46″(图1),面积约12.3 km2。地处闽西南拗陷带西南段,地貌类型以山地丘陵为主,地势西北高东南低,地形复杂,相对高差约331 m。气候类型属亚热带季风气候,常年温湿多雨,气温变化不大,年平均气温为20.5°,年平均降雨量为1 733.1 mm。龙岩市煤炭资源储量约8.70亿t,占福建省全省资源储量的57.92%[13],新罗区是福建省龙岩市的下辖城区,该区矿产资源丰富,开发历史悠久,就煤炭资源来看,新罗区位于龙永煤田东北隅,境内二叠纪煤系分布于区域东北角,煤炭资源以高变质无烟煤及贫煤为主[14]。据统计,截至2021年,龙岩市煤矸石累计堆积量约945万t,并以42万t/a的速度增长,随着煤炭开采不断堆积形成矸石山,且绝大多数矸石山当前并未采取绿化措施[15]。
图1

本文利用GF-2高空间分辨率遥感影像开展煤矸石山信息提取研究,所用遥感影像由GF-2卫星的PMS2传感器于2021年1月14日拍摄所得,图像质量良好,无云覆盖。GF-2卫星是我国于2014年8月19日发射的首颗自主研制的空间分辨率优于1 m的民用光学遥感卫星,卫星轨道高度631 km,重访周期为5 d。GF-2影像数据包含4个4 m空间分辨率的多光谱波段和1个1 m空间分辨率的全色波段。为获取实验影像,对原始GF-2影像进行图像裁剪、辐射定标、大气校正、正射纠正、图像融合和图像配准等预处理操作,最终获取空间分辨率为1 m的研究区正射影像。
2 研究方法
2.1 样本制作与特征预提取
图2

其他地物; 从研究区地物纹理特点来看,煤矸石堆存区表面纹理粗糙,内部纹理相对简单,边界较为明显。除以上特征外,由于研究区内不同区域的煤矸石堆存量存在差异,且矸石堆与其他地物存在“异物同谱”等现象,为进一步提高煤矸石堆分类检测精度,将煤矸石山分为重度堆积和轻度堆积2类进行信息提取,并选取193个不同类型的地物影像样本组成样本集,各类地物的典型样本如图2所示。
基于研究区内不同类别煤矸石堆存区与周边地物的差异特点,提取地物光谱特征、纹理特征、地形特征构建随机森林分类的特征变量集。光谱特征反映不同地物色调差异,由于煤矸石堆存区的影像色调与其他地物类别存在差异,且煤矸石堆积区周边植被覆盖范围较大,因此除GF-2遥感影像原始的4个多光谱波段(B1,B2,B3,B4)的灰度特征外,还计算了影像灰度平均值,并反演了归一化植被指数(normalized difference vegetation index,NDVI)对研究区地物进行增强提取,如图3所示,其中NDVI的计算公式为:
式中R和NIR分别为红光和近红外波段反射率值。
图3

图4

图5

2.2 随机森林模型参数优化
本文将选取的样本集按照2∶8的比例随机划分为测试集和训练集,利用sklearn库进行随机森林模型训练。采用交叉验证方法对随机森林模型的框架参数及决策树参数进行优化,交叉验证方法综合随机搜索交叉验证与网格搜索交叉验证2种方法进行。先利用随机搜索交叉验证方法对超参数组合进行随机排列,并输出最优的随机排列组合,确定最优组合的大致范围,随后利用网格搜索交叉验证缩小参数范围,遍历小范围内的每一种超参数组合,从而选出最终的参数组合[21]。
由于研究区训练样本量及特征数较少,因此不限制最大深度,通过交叉验证方法设置本文模型最优参数组合: 随机森林树数设为150,最大特征数设为auto,分割所需的最小样本数设为2,叶节点处所需的最小样本数设为1。
2.3 分类特征优化
3 结果与分析
3.1 煤矸石堆存区分类特征优选
图6
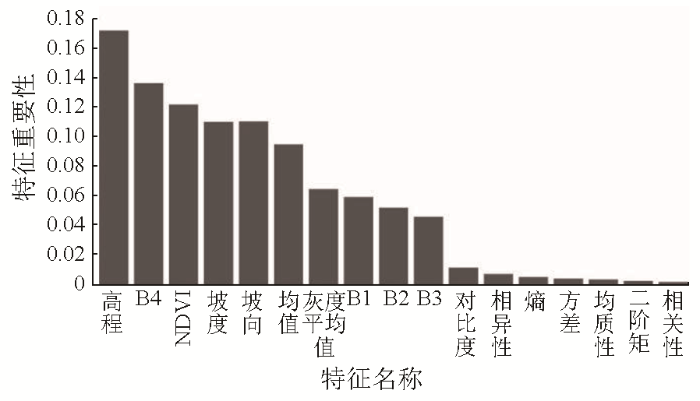
图7
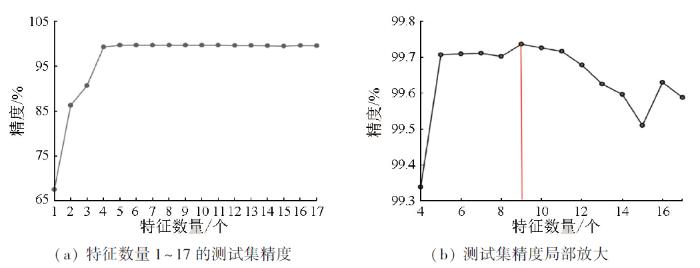
图7
测试集精度与特征数量关系
Fig.7
Relationship between test set accuracy and number of features
因此结合特征重要性评价及测试集精度评价结果优选出9个特征变量参与煤矸石信息提取: 预提取的地形特征中的3个地形特征变量均被选中,其中高程特征重要性排名第1,坡度排名第4,坡向特征排名第5; 光谱特征重要性也较高,5个光谱特征被选中,其中B4波段、NDVI、影像灰度平均值特征、B1波段、B2波段分别排在第2,3,7,8和9位,光谱特征中,B4波段和NDVI相对更为重要。在特征优化过程中,删除最多的特征为纹理特征,8个纹理特征中仅有纹理均值被选中,排名第6。
3.2 煤矸石堆存区提取结果与精度评价
基于随机森林算法对研究区GF-2影像进行分类,结果如图8所示,从定性的角度可知,研究区内植被分布广泛,区内房屋建筑物、道路主要分布于西北边缘、西南角及东南角,山地阴影与实际空间分布相关性强。本文分类方法提取的煤矸石堆积区呈群落状分布,轮廓较为明显,有5处集中分布区及多处零散分布区,提取结果与野外煤矸石堆调查点吻合度较高,部分煤矸石堆存于居民地附近。在研究区内随机生成350个地面验证点,为增加煤矸石堆积区验证的准确性,结合野外煤矸石堆调研成果,在煤矸石堆集中区增加50个验证样本点,共利用400个地面验证点对随机森林提取分类结果进行验证,其中煤矸石重度堆积区验证点78个,煤矸石轻度堆积区验证点57个,煤矸石验证点共计135个。分类精度评价结果如表1所示。在定性分析的基础上利用混淆矩阵法对地面验证点与真实地物类型进行统计分析,其中煤矸石重度堆积区正确分类像元数71个,错分为轻度堆积区的像元数3个,煤矸石轻度堆积区正确分类像元数52个,错分为重度堆积区的像元数1个,因此在不区分堆积程度的情况下,煤矸石堆积区正确分类像元数共计127个,煤矸石总体分类精度达到94.07%,Kappa系数为0.819。
图8
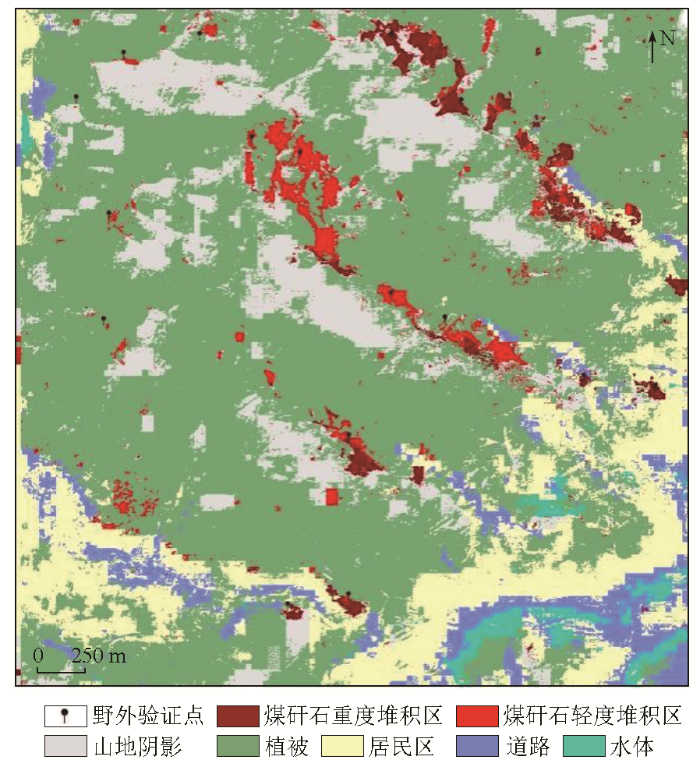
表1 分类精度评价
Tab.1
| 地物类别 | 正确分类点 总和/像元 | 重度与轻度 煤矸石错分 点/像元 | 验证点总 和/像元 | 生产者精 度/% | 用户精度/% | 错分误差/% | 漏分误差/% | 煤矸石总体 分类精度/% | Kappa系数 |
|---|---|---|---|---|---|---|---|---|---|
| 煤矸石重度堆积区 | 71 | 3 | 78 | 91.03 | 97.26 | 2.74 | 6.41 | 94.07 | 0.819 |
| 煤矸石轻度堆积区 | 52 | 1 | 57 | 91.23 | 77.61 | 22.39 | 8.77 | ||
| 煤矸石堆积区 | 127 | 4 | 135 | 94.07 | 90.71 | 9.29 | 5.93 |
煤矸石堆积区由于自身的色调、纹理和地形等特征,分类效果较好,其中煤矸石重度堆积区生产者精度达91.03%,用户精度达97.26%,煤矸石轻度堆积区生产者精度达91.23%,用户精度仅为77.61%,以上结果说明基于特征优选的随机森林算法在提取煤矸石堆存区信息中有较好的适用性,但当煤矸石堆积区表层煤矸石堆积程度有所区分时,轻度煤矸石堆积区的用户精度明显降低,错分误差较高,达22.39%,这是由于部分山地阴影或植被被错误识别为煤矸石轻度堆存区所造成的,因此在后续的实验中将重点增加轻度煤矸石堆积区与山地阴影、植被的区分程度,提高煤矸石轻度堆积区的提取精度。
4 结论
本文以GF-2融合后的1 m空间分辨率遥感影像及区域30 m空间分辨率的ASTER GDEM数字高程模型数据为基础,提取了17种影像光谱特征、纹理特征及地形特征值,构建了初始特征集,通过测试集精度评价及特征重要性评估优选出9种特征变量并构建了分类特征集,利用随机森林算法进行煤矸石堆积区地物分类,并基于混淆矩阵方法对提取结果进行精度评价,验证了国产GF-2高空间分辨率数据在煤矸石堆积区土地覆被类型分类的可行性。主要结论如下:
1)参与分类的特征变量数量及类别会影响最终的地物提取效果,本文优选出9个特征变量(高程、坡度、坡向、B4波段、NDVI、影像灰度平均值、B1波段、B2波段、纹理均值)参与地物分类,特征优选结果表明地形特征对于区分煤矸石堆积区的土地覆被类型最为敏感,光谱特征次之,纹理特征在该类地区信息提取方面的重要性最低。
2)不区分地表煤矸石堆存程度时,煤矸石堆存区识别的总体精度为94.07%,Kappa系数为0.819,证实了该方法的有效性; 区分煤矸石堆存程度的情况下,煤矸石重度堆积区及煤矸石轻度堆积区提取的生产者精度分别为91.03%和91.23%,但是由于部分山地阴影与植被被错误识别为煤矸石轻度堆存区,因此煤矸石轻度堆积区的用户精度偏低,仅为77.61%,这将导致煤矸石轻度堆存区的提取面积与实际相比偏大,因此从提取精度来看煤矸石重度堆积区的提取效果优于轻度堆积区。
3)由于采煤形成的煤矸石大多堆存于山顶或自然堆积于地表,且中国南方山地地区植被覆盖面积较为广阔,因此煤矸石堆存区普遍存在海拔、坡度、坡向明显高于周围其他地物以及植被特征区分地物差异明显的特点,因此体现地形、植被特征的高程、坡度、坡向、多光谱波段B4和NDVI对中国南方地区其他山地煤矿开采区的煤矸石山信息提取也具有普适性。
4)本文提取的地形特征对于煤矸石山信息提取效果显著,但由于开放性数据源类别的限制,所用地形数据空间分辨率仅为30 m,受空间分辨率的限制,提取结果中存在部分地类边缘准确性较低的问题,在后续的研究中将利用无人机等设备获取更高空间分辨率的地形数据,结合高空间分辨率遥感影像的其他地类特征,进一步提升地物分类精度。
参考文献
高光谱成像的煤与矸石分类
[J].
Classification method of coal and gangue based on hyperspectral imaging technology
[J].
自燃煤矸石山的遥感识别——基于Landsat8热红外波段地表温度反演数据
[J].
Remote sensing recognition of spontaneous combustion gangue dump:Based on Landsat8 thermal infrared band land surface temperature inversion data
[J].
基于多尺度分割的煤矿区典型地物遥感信息提取
[J].
Remote sensing information extraction of typical surface objects in a coal mining area based on multiple-scale segmentation
[J].
煤矸石充填复垦地理化特性与重金属分布特征
[J].
Physical and chemical properties and distribution characteristics of heavy metals in reclaimed land filled with coal gangue
[J].
煤矸石研究综述: 分类、危害及综合利用
[J].
Review of research on coal gangue with its classification,hazards and comprehensive utilization
[J].
我国煤矸石综合利用的现状、问题与建议
[J].
Current situation of the comprehensive utilization of coal gangue in China and the related problems and recommendations
[J].
煤矸石综合利用现存问题分析与解决对策研究
[J].
Analysis on existing problems and countermeasures of comprehensive utilization of coal gangue
[J].
基于ASTER遥感影像的煤矸石分布信息提取方法
[J].
Collecting method of coal refuse distribution information based on ASTER remote sensing images
[J].
Thermal mapping of self-heating zones on coal waste dumps in Upper Silesia (Poland): A case study
[J].
基于无人机遥感的煤矸石山植被分类
[J].
Classification of coal gangue pile vegetation based on UAV remote sensing
[J].
Representation learning:A review and new perspectives
[J].
基于随机森林的洪河湿地遥感影像分类研究
[J].
Classification of Honghe wetland remote sensing image based on random forests
[J].
自然地理
[EB/OL].(
Physical geography
[EB/OL].(
龙岩市现已探明煤炭资源状况及远景资源区预测
[C]//
The situation of coal resources and the prediction of prospective resource areas have been proved in Longyan City
[C]//
龙岩新罗区: 煤矸石变废为宝煤台披上“新绿装”
[EB/OL].(
Longyan Xinluo District:Coal gangue waste into trea-sure coal platform covered with "new green"
[EB/OL].(
结合ZY-1 02D光谱与纹理特征的干旱区植被类型遥感分类
[J].
Method for classifying vegetation types in arid areas combining spectral and textural features of ZY-1 02D
[J].
Textural features for image classification
[J].
基于随机森林与特征选择的藏东南土地覆被分类方法及精度评价
[J].
DOI:10.13249/j.cnki.sgs.2023.03.002
[本文引用: 1]

由于云污染、实地验证点的匮乏,以及地形地貌的复杂、破碎化,多云山区土地覆被的准确分类较难实现。以藏东南这一典型的多云山区及生态过渡区为研究区,基于Google Earth Engine(GEE)平台和野外实测数据,结合多光谱数据、雷达数据、高程数据、辅助数据,提取光谱特征、纹理特征、地形特征等信息,利用递归特征消除法对特征进行优化,并采用随机森林算法构建分类模型,以期有效利用多源遥感数据提高土地覆被分类精度。结果表明:① 并非特征越多分类精度越高,特征选择后数量由58个减至38个,分类精度(总体精度93.96%,Kappa系数0.92)较未优化前(总体精度93.11%,Kappa系数0.92)略有提升。② 地形特征及雷达特征对藏东南土地覆被分类具有重要作用,地形特征对多数土地覆被类型的分类精度具有影响,而雷达数据对裸地、建设用地、灌丛影响较大,分类过程中如不考虑地形及雷达特征,总体精度分别降至88.98%,92.48%。纹理特征以及时序特征仅对提高具有明显纹理以及时序变化的土地覆被类型的精度有帮助。结合随机森林和特征优化算法,能够在保证土地覆被分类精度的同时,高效整合多源数据信息,加快模型运算速度,为多云山区土地覆被分类提供切实可行的方法。
Land cover classification based on random forest and feature optimism in the Southeast Qinghai-Tibet Plateau
[J].
DOI:10.13249/j.cnki.sgs.2023.03.002
[本文引用: 1]
Obtaining accurate land cover information in cloudy mountain areas are severely impacted by cloud contaminations, the scarcity of field validation points, and the complexity and fragmentation of landforms. Taken the Southeast Qinghai-Tibet Plateau, a typical cloudy mountainous area and ecological transition zone, as study area, this research first extract the spectral features, radar features, textual features, topographic features through the spectral data, radar data, DEM data and auxiliary data based on the Google Earth Engine and filed observed data. Then we built the random forest model and made feature reduction using recursive feature elimination, in order to improve the accuracy of land cover classification by using multi-source remote sensing data effectively. Results showed that: 1) The feature numbers reduced from 58 to 38 after feature optimization, classification accuracy (overall accuracy 93.96%, Kappa coefficient 0.92) slightly improved compared to unoptimized (overall accuracy 93.11%, Kappa coefficient 0.92); 2) Topographic and radar features played an essential role in the land cover classification of mountainous cloudy areas. If the topographic features and radar feature were excluded, accuracies would decrease to 88.98% and 92.48%, respectively. Topographic features would influence the classification accuracy of most land cover types, while radar features had more impacts on bare lands, construction lands, and shrublands. Textual features and sequential features could only help to increase the accuracy of land cover type with significant textual features and temporal variations. More accurate land cover information can be detected by combing the random forest and feature optimization algorithm, while also provide a more efficient and faster way of integrating multisource data, thus making contribution to land cover classification of the cloudy and mountainous area.
随机森林方法研究综述
[J].
A review of technologies on random forests
[J].
基于GF-2 PMS影像和随机森林的甘肃临夏花椒树种植监测
[J].
Monitoring of Zanthoxylum bungeanum Maxim planting using GF-2 PMS images and the random forest algorithm:A case study of Linxia,Gansu Province
[J].
基于GF-2影像和随机森林算法的花岗伟晶岩提取
[J].
Extracting granite pegmatite information based on GF-2 images and the random forest algorithm
[J].
基于地理加权随机森林的青藏地区放牧强度时空格局模拟
[J].
DOI:10.13249/j.cnki.sgs.2023.03.003
[本文引用: 1]
精确刻画放牧强度时空格局是深刻理解青藏地区高寒草地服务功能动态及其驱动机制的重要基础,对辅助制定区域生态安全和可持续发展战略具有意义。基于牲畜年末存栏量、牧区人口密度、生长季NDVI、年降水量、年平均气温和居民点分布等数据,采用地理加权随机森林模型,模拟了2000年、2010年和2020年3期青藏地区放牧强度的空间格局,并定量评价了环境因子对放牧强度空间分布解释性的区域差异。结果表明:① 地理加权随机森林模拟结果可精细地刻画青藏地区放牧强度的空间特征,与经典随机森林模型相比,判定系数更高,平均绝对值误差和均方根误差更低。② 青藏地区放牧强度呈现东南高、西北低的基本特征,其中,西北部地区放牧强度低于25羊单位/km<sup>2</sup>的区域约占青藏地区面积的1/2。③ 与2000年和2010年相比,2020年青藏地区放牧强度呈现总体下降、局部抬升的态势;其中,较2010年,2020年放牧强度下降超过1羊单位/km<sup>2</sup>的区域占牧区面积的61.69%。④ 牧区人口密度是解释放牧强度空间异质性最主要的因素,其相对重要性呈现西高东低的特征,而降水量和生长季NDVI的相对重要性则呈现西北高、东南低的特征。研究结论可为青藏地区草地可持续管理和生态安全屏障建设提供科学参考。
Mapping the multi-temporal grazing intensity on the Qinghai-Tibet Plateau using geographically weighted random forest
[J].
DOI:10.13249/j.cnki.sgs.2023.03.003
[本文引用: 1]
Accurately quantifying the spatiotemporal pattern of grazing intensity on the Qinghai-Tibet Plateau (QTP) is crucial to improving our understanding of the driving mechanism of alpine grassland change, and is of great significance for maintaining regional ecological security and promoting sustainable development policies. Based on the data of livestock inventory at the end of the year and environmental covariates (e.g. population density in pastoral areas, growing season NDVI, annual precipitation, annual mean temperature, and settlements), the gridded grazing intensities on the QTP in 2000, 2010, and 2020 were simulated by geographically weighted random forest (GRF), and the regional differences in the interpretability of environmental variables were then analyzed. The results showed that grazing intensity maps predicted by the GRF could mirror the spatial distribution of grazing intensity on the QTP, compared with the classic random forest model, the R2 was higher, and both the mean absolute value error (MAE) and root mean square error (RMSE) were lower. The grazing intensity was generally higher in the southeast and lower in the northwest of the QTP. The areas with grazing intensity of less than 25 sheep units/km2 in the northwest part accounted for about half of the QTP. Compared with 2000 and 2010, the grazing intensity of the QTP in 2020 showed a trend of overall decrease but local increase. For example, compared with 2010, the areas of grazing intensity decreased by higher than 1 sheep unit/km2 in 2020 accounting for 61.69% of the pastoral area. The population density in pastoral areas was the most important factor explaining the spatial heterogeneity of grazing intensity, and its relative importance was higher in the western QTP and lower in the eastern QTP. On the contrary, the relative importance of both precipitation and growing season NDVI was higher in the northwest part and lower in the southeast part of QTP. Our results provide scientific references for sustainable grassland management and ecological safety barrier construction on the QTP.
基于顺序向前选择算法的制冷系统故障诊断分析
[J].
Refrigeration system fault diagnosis based on sequential forward order feature selection algorithm
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}