

0 引言
建筑物是一种重要的基础设施,也是反映社会经济和文化特征的历史遗产。同时,建筑物信息作为地理信息的重要组成部分,广泛应用于城市规划、军事侦察和灾害监测等方面[1-2]。遥感技术的广泛应用推动了卫星图像解译领域的迅猛发展,使得对建筑物的解译结果更加精准[3]。在传统建筑物分割方法中,主要根据影像的颜色、纹理和边缘信息等低维视觉特征进行建筑物的提取,经典的分割方法有基于阈值的大津法[4]、基于区域的分水岭分割法[5]、Prewitt算子边缘检测等[6]。但传统方法一般需要专家知识建立相关的规则分割建筑物,对影像语义信息的提取泛化性大幅减弱,且过度依赖解译人员对场景的认知、效率低下,已不能满足当前实际应用需求[7]。
随着人工智能的兴起,深度学习已在语义分割、目标检测、变化检测等多项技术上取得了突破性进展[8-
因此,为实现更精细的建筑物提取,本文在深度可分离卷积[20](depthwise separable convolution,DSC)的启发下,基于BASNet提出了SD-BASNet网络。该网络在BASNet的基础上设计了一个深度可分离残差模块(depthwise separable residual module,DSRM),降低了模型的参数量、缩短了网络运行时间;其次,为防止网络轻量化带来的精度下降,将空洞卷积[21](dilated convolution,DC)融入BASNet优化模块的编码层,在不增加卷积核大小的情况下,增大特征图的感受野,从而捕捉更广泛的上下文信息,提高建筑物提取的精度。
1 SD-BASNet网络
本文在BASNet网络的基础上进行了改进,提出了一种基于高分辨率遥感影像(high spatial resolution remote sensing images,HSRRSI)的建筑物提取网络SD-BASNet。该网络在BASNet网络的深度监督编解码(Encoder-Decoder)结构中设计了DSRM,将DSC引入其主干网络,避免了卷积核过大,减少模型的参数量;同时在优化模块的编码层中加入DC,目的是增大特征图感受野,解决因为编码层下采样过程中所导致的信息丢失问题,旨在实现建筑物的精细化提取同时使得网络参数量有所下降。
本文提出的SD-BASNet结构如图1所示。原BASNet网络主要由深度监督的Encoder-Decoder模块和残差优化模块组成。深度监督的Encoder-Decoder模块是一个分割目标预测模型,该结构捕获语义信息以提高建筑物提取精度,然后将提取到的特征图传入优化模块,改善影像区域的不确定性和边缘粗糙问题。但由于在网络训练过程中网络模型较为复杂,所产生的参数量不容小觑。因此,本文在BASNet网络的基础上进行改进,提出一种面向HSRRSI建筑物提取的SD-BASNet网络。
图1
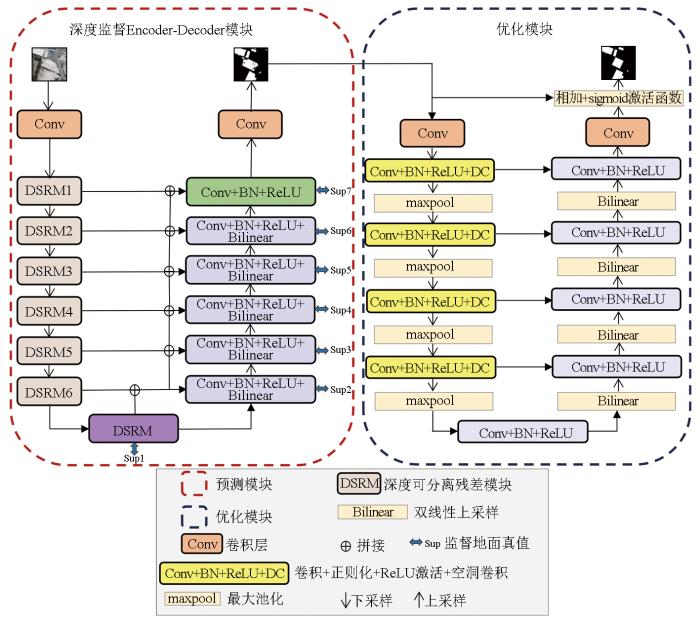
1.1 深度监督Encoder-Decoder模块
DSC是CNN常用的一种卷积操作,广泛应用于轻量级网络设计中[22-
图2
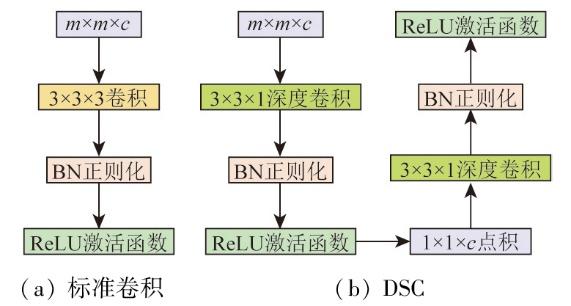
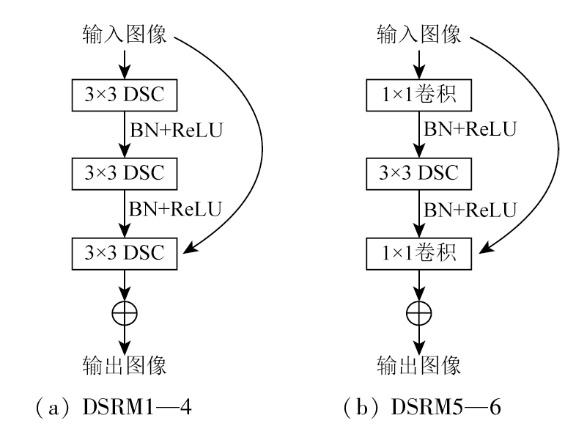
SD-BASNet的深度监督Encoder-Decoder结构由编码层、解码层和桥接层构成。编码部分由1个卷积层和6个DSRM构成。如图3所示,DSRM1—4由64个大小为3×3、步长为1的卷积核组成,用3×3的DSC替换3×3的普通卷积,并进行BN和ReLU操作,该部分使得网络在训练阶段可提取影像特征,捕捉影像中不同像素之间的上下文信息;而DSRM5—6由3个基础残差块和512个卷积核组成,使用DSC代替其中的普通卷积,以减少网络整体参数量。桥接层由3个残差块组成,每个残差块由512个大小为3×3的DSC,BN正则化和ReLU激活函数构成,目的是进一步获取影像特征信息。解码层和编码层几乎对称,不同之处在于卷积核中为普通的3×3卷积。解码层在上采样中通过双线性插值可以有效地增加特征图的分辨率,同时节约内存、减少网络计算资源;最后经过sigmoid函数将7种不同分辨率的特征图(Sup1—7)输出。此外,编解码层之间通过连接操作将高级与低级特征连接起来,利于语义和细节信息的结合,减少信息丢失。
图3
1.2 优化模块
图4
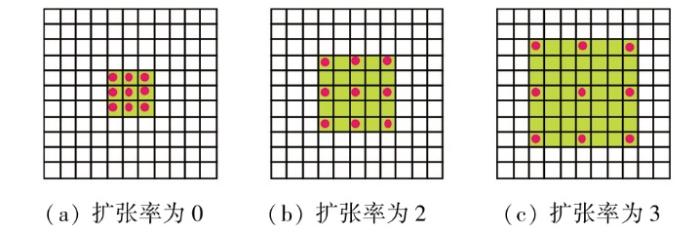
本文的优化模块采用了残差Encoder-Decoder架构。如图1所示,编码层和解码层有4个卷积层,编码层的每个卷积层由64个大小为3×3的卷积核,DC,BN与ReLU激活函数构成。由于网络在下采样过程中丢失了特征图部分细节信息,难以对局部纹理进行精确的分割,所以在优化模块的编码层中引入DC,通过增加卷积核中的空洞融合更多的上下文信息,从而更好地提取特征,增强模型的表征能力,减少参数量的同时防止精度下降。与编码层类似,桥接层、解码层由64个大小为3×3的卷积核、BN与ReLU激活函数组成。值得一提的是,在下采样编码层中使用了非重叠的最大池化层,有助于减少特征维度,提高模型的鲁棒性和计算效率;在上采样解码层中使用了双线性插值,利于影像的平滑输出。
2 实验与分析
2.1 实验数据及设置
为充分验证本文算法的有效性和可行性,使用WHU建筑物数据集[25]进行建筑物提取实验,WHU建筑物数据集由武汉大学季顺平团队提供。该数据集由航空建筑物数据集和卫星建筑物数据集组成,影像地面分辨率为0.075 m,涵盖22万栋形分布各异的建筑物,覆盖面积达450 km2。此数据集将大部分航空影像裁剪为8 188个无重叠的瓦片,大小为512像素×512像素,同时将数据集划分为4 736张训练集、1 036张验证集和2 416张测试集。
实验从WHU数据集随机选取1 850张影像作为训练集、1 000张影像作为测试集。所采用配置为Intel(R) i7-9700k CPU和NVIDIA GeForce GTX1070显卡的计算机,8 GB显存。实验过程迭代次数为100次,初始学习率为0.000 1,权重衰减系数为0,训练过程中批量大小为2,设置训练网络的优化器为Adam,其余超参数设为默认值。
2.2 评价指标
为验证本文提出网络的有效性,客观评价提取效果,采用平均交并比(mean intersection over union,mIoU)和平均像素精度(mear pixel accuracy,mPA)对测试集的整体精度进行了评价;以精确率,召回率和F1作为评价指标,定量评价每张场景影像的提取精度。各指标计算公式如下:
式中:P和R分别为精确率和召回率;i为类别序号,i=0,1,…,k,i=0表示背景;k为类别数;TP为建筑物被正确预测为建筑物的像素点个数;TN为背景被正确预测为背景的像素点个数;FP为背景被错误预测为建筑物的像素点个数;FN为建筑物被错误预测为背景的像素点个数。
2.3 结果与分析
2.3.1 模型参数量分析
表1为不同模型参数量与训练时间对比,其中,①为基础网络BASNet,不进行任何改动与添加;②为在BASNet中加入DSC模块;③为在BASNet中加入DC;④为在BASNet中同时加入DSC和DC,即本文所提方法SD-BASNet。表中加粗字体为各项最优。经过实验证明,加入DSC模块的2个网络②和④的参数量和训练时间有所减少。虽然网络②比网络④参数量少,网络训练时间有所提升,但两者之间相差不大。相较于原网络①,所改进网络④在参数上下降了25.10×106,训练时间减少了0.36 h。原网络由于使用了大量卷积核,参数量过大导致网络不易收敛且训练速度较慢。
表1 不同网络的参数量与时间分析
Tab.1
| 序号 | 网络 | 参数量/106 | 训练时间/h |
|---|---|---|---|
| ① | BASNet | 87.06 | 11.27 |
| ② | BASNet+DSC | 61.54 | 10.79 |
| ③ | BASNet+DC | 87.06 | 11.77 |
| ④ | BASNet+DSC+DC(SD-BASNet) | 61.96 | 10.91 |
2.3.2 分割性能分析
为了检验SD-BASNet的建筑物提取效果,本文选取语义分割经典网络PSPNet[26],SegNet[27],Deep-LabV3[28],SE-UNet[29]和UNet++[30]进行实验,并增加了基础网络BASNet与SD-BASNet进行对比,在WHU建筑物数据集上进行性能测试,得出各项精度评价指标如表2所示。从表中可以看出,与其他方法相比,本文所提网络在mIoU,mPA,召回率,精确率和F1方面分别最大提升了25.10%,16.73%,7.13%,32.98%和20.21%,仅一项数据较低,即SD-BASNet网络的召回率方面低于基础网络BASNet,但在其余指标上是最优的。且提出网络侧重于降低网络参数量,从表1可看出参数量的有效下降,证实了本文所提网络SD-BASNet的可行性。
表2 不同网络的检测结果
Tab.2
| 网络 | mIoU | mPA | 召回率 | 精确率 | F1 |
|---|---|---|---|---|---|
| PSPNet | 73.74 | 80.43 | 89.62 | 62.86 | 73.89 |
| SegNet | 77.67 | 83.26 | 93.27 | 67.87 | 78.57 |
| DeepLabV3 | 82.30 | 87.07 | 94.34 | 75.39 | 83.80 |
| SE-UNet | 82.95 | 87.37 | 95.43 | 75.74 | 84.46 |
| UNet++ | 83.77 | 87.92 | 96.09 | 76.69 | 85.30 |
| BASNet | 90.10 | 93.88 | 98.40 | 87.44 | 89.92 |
| SD-BASNet | 92.25 | 96.59 | 96.50 | 93.79 | 92.61 |
2.3.3 定性定量分析
为分析SD-BASNet在WHU建筑物数据集中不同场景下的性能差异,在测试集中选取小尺度、多尺度、大尺度建筑物用于定性定量分析。选取的预测场景影像及标签示例如图5所示。以下分为小尺度、多尺度、大尺度3个场景分析各个网络测试性能差异的原因。
图5
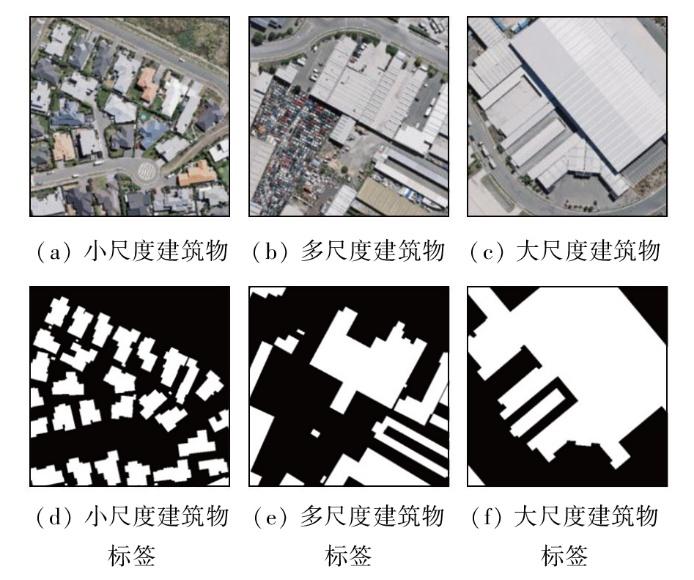
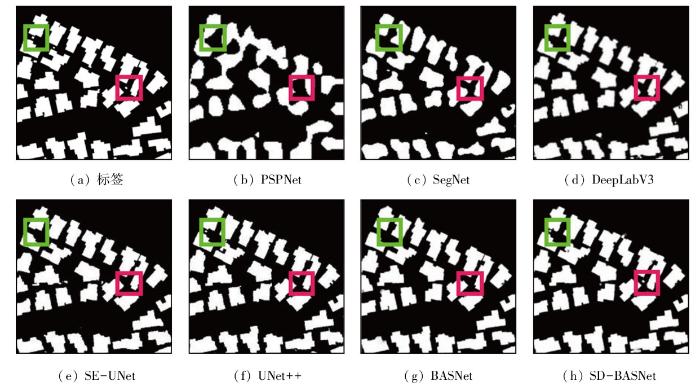
1)小尺度建筑物提取。表3和图6分别展示了小尺度建筑物场景下的检测结果和提取情况。从表3来看,在小尺度建筑物的监测下,SD-BASNet除了召回率性能比其他网络较低外,其余性能最为优越。从图6可视化场景可以看出,每当小型建筑物密度较高时,常用的语义分割模型PSPNet和SegNet结果均有不同程度的粘连,提取效果较差。DeepLabV3,SE-UNet,UNet++和BASNet对建筑物提取较为完整,建筑物轮廓能很好地被识别,然而从图中绿色和红色标注框显示得知,对于更细小的目标物体,这几种对比网络均不能识别出来,而SD-BASNet不仅在提取建筑物完整度方面表现良好,也能识别更细小的目标建筑物,证实其在小尺度建筑物场景下具有一定的优越性。
表3 小尺度建筑物的检测结果
Tab.3
| 网络 | mIoU | mPA | 召回率 | 精确率 | F1 |
|---|---|---|---|---|---|
| PSPNet | 74.30 | 79.84 | 89.84 | 61.46 | 75.26 |
| SegNet | 74.64 | 82.24 | 96.84 | 65.48 | 78.13 |
| DeepLabV3 | 82.17 | 87.93 | 96.80 | 77.06 | 85.81 |
| SE-UNet | 83.59 | 88.81 | 97.87 | 78.43 | 87.08 |
| UNet++ | 84.77 | 89.92 | 97.09 | 79.69 | 87.30 |
| BASNet | 92.89 | 96.56 | 93.99 | 96.01 | 94.99 |
| SD-BASNet | 93.07 | 96.81 | 94.71 | 96.17 | 95.41 |
图6
2)多尺度建筑物提取。表4和图7分别展示了多尺度建筑物场景下的检测结果和提取情况。从表4可以看出,SD-BASNet总体领先于其他的对比网络,尤其在mPA精度指标方面达到了94.50%。从图7多尺度建筑物中可以明显看出建筑物的边缘提取方面,SD-BASNet具有明显优势。PSPNet与SegNet可视化结果最差,边界信息出现严重的不连续性缺陷现象;而DeepLabV3,SE-UNet和UNet++在一定程度上弥补了边缘提取缺陷问题。从标注的红绿框可知,相较于前几种网络,BASNet更注重边缘信息和语义特征的获取,从而提取结果较为精确。SD-BASNet相较于BASNet而言,不仅在参数量上有所下降,且更聚焦于特征信息之间的提取。从绿框看,比之BASNet提取建筑物出现语义信息表征弱的情况,SD-BASNet提取建筑物更为优越。
表4 多尺度建筑物的检测结果
Tab.4
| 网络 | mIoU | mPA | 召回率 | 精确率 | F1 |
|---|---|---|---|---|---|
| PSPNet | 46.14 | 76.51 | 78.49 | 53.75 | 63.14 |
| SegNet | 81.04 | 87.69 | 95.42 | 77.37 | 85.45 |
| DeepLabV3 | 81.58 | 87.97 | 96.23 | 77.56 | 85.89 |
| SE-UNet | 83.09 | 88.80 | 97.99 | 78.46 | 87.15 |
| UNet++ | 86.86 | 84.79 | 97.14 | 77.14 | 85.02 |
| BASNet | 89.36 | 93.58 | 94.40 | 90.61 | 92.51 |
| SD-BASNet | 90.18 | 94.50 | 94.57 | 91.81 | 93.17 |
图7
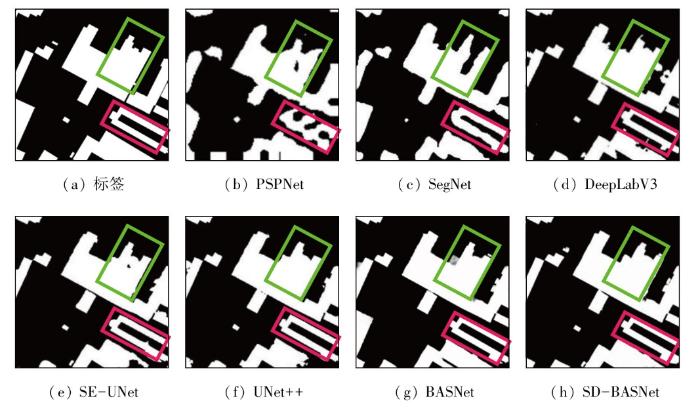
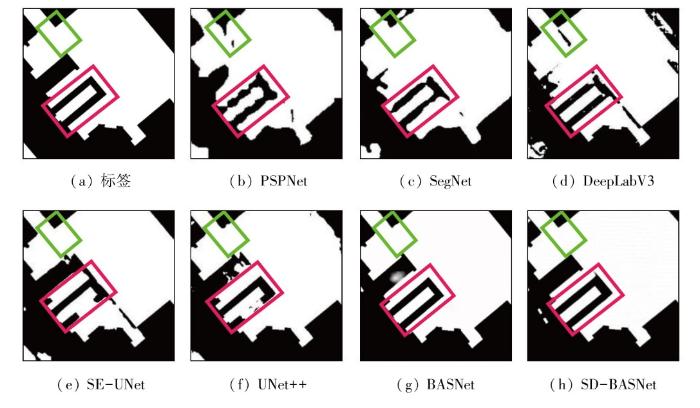
表5 大尺度建筑物的检测结果
Tab.5
| 网络 | mIoU | mPA | 召回率 | 精确率 | F1 |
|---|---|---|---|---|---|
| PSPNet | 39.58 | 40.72 | 40.72 | 58.62 | 56.71 |
| SegNet | 82.62 | 90.25 | 87.19 | 90.14 | 88.64 |
| DeepLabV3 | 84.50 | 91.90 | 92.57 | 88.09 | 90.28 |
| SE-UNet | 88.21 | 93.85 | 93.56 | 91.80 | 92.67 |
| UNet++ | 87.59 | 92.16 | 93.31 | 90.34 | 91.31 |
| BASNet | 91.76 | 95.39 | 92.70 | 97.12 | 94.86 |
| SD-BASNet | 92.34 | 95.95 | 92.49 | 97.59 | 95.50 |
图8
2.3.4 消融实验
表6 消融实验检测结果
Tab.6
| 网络 | mIoU | mPA | 召回率 | 精确率 | F1 |
|---|---|---|---|---|---|
| BASNet | 90.10 | 93.88 | 98.40 | 87.44 | 89.92 |
| BASNet+DSC | 86.39 | 94.80 | 91.39 | 93.05 | 92.70 |
| BASNet+DC | 92.56 | 95.01 | 96.16 | 93.24 | 92.12 |
| SD-BASNet | 92.25 | 96.59 | 96.50 | 93.79 | 92.61 |
图9

3 讨论与结论
3.1 讨论
从上述实验结果与分析中可得出,SD-BASNet与其他几种网络相比,精度和可视化结果均有较大的提升,验证了其对HSRRSI建筑物提取的有效性和可行性。而对比基础网络BASNet,本文网络的DSRM模块能简化网络结构,降低模型的参数量;在优化模块加入DC后,能更好地提取目标特征、增强模型的表征能力,说明设计DSRM与加入DC对网络模型训练有一定的积极影响。同时,在建筑物小尺度、多尺度、大尺度的背景下,SD-BASNet与其他网络相比依旧能取得较好结果,证明了所提网络的实用性与优越性。
3.2 结论
本文利用所提出的网络SD-BASNet,降低了基础网络BASNet的参数量,同时实现了建筑物提取精度的提升。该网络为避免卷积核过大,在预测网络中设计了DSRM模块,有效减少了模型的参数量;又在优化模块的编码层中加入DC以增大特征图感受野,解决编码层下采样过程中所导致的信息丢失问题。在WHU建筑物数据集上对网络进行了实验测试。结果表明:与基础网络BASNet相比,SD-BASNet中DSRM模块的设计与DC的集成使得参数量和运行时间分别减少了25.10×106和0.36 h,且在不修改网络结构的情况下提高了其精度;相较于其他6种对比网络,其精度指标及可视化效果为总体最佳。
然而本文网络在召回率指标的提取上,依旧低于基础网络BASNet。在后续研究中,针对此问题需综合考虑样本类别的平衡问题。同时进一步优化网络结构,可尝试将语义分割算法与目标检测任务进行融合,提升网络在训练过程的精度,使其在复杂场景中达到更好的提取效果。
参考文献
基于双路细节关注网络的遥感影像建筑物提取
[J].
Building extraction based on dual-stream detail-concerned network
[J].
基于形态学序列和多源先验信息的城市建筑物高分遥感提取
[J].
High-resolution remote sensing extraction of urban buildings based on morphological sequences and multi-source a priori information
[J].
融合CNN和Transformer的遥感图像建筑物快速提取
[J].
Fast extraction of buildings from remote sensing images by fusion of CNN and Transformer
[J].
A threshold selection method from gray-level histograms
[J].
A neutrosophic approach to image segmentation based on watershed method
[J].
Object enhancement and extraction
[J].
Deep learning-based building extraction from remote sensing images:A comprehensive review
[J].
面向高分影像建筑物提取的多层次特征融合网络
[J].
High-resolution image building extraction based on multi-level feature fusion network
[J].
Object detection using YOLO:Challenges,architectural successors,datasets and applications
[J].
Building extraction from VHR remote sensing imagery by combining an improved deep convolutional encoder-decoder architecture and historical land use vector map
[J].
Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set
[J].
一种轻量级的DeepLabv3+遥感影像建筑物提取方法
[J].
Lightweight DeepLabv3+ building extraction method from remote sensing images
[J].
Boundary-aware segmentation network for mobile and web applications
[J/OL].
Multi-scale context aggregation by dilated convolutions
[J/OL].
MobileNets: Efficient convolutional neural networks for mobile vision applications
[J/OL].
ImageNet classification with deep convolutional neural networks
[J].
EfficientNet:Rethinking model scaling for convolutional neural networks
[J/OL].2019:
遥感影像建筑物提取的卷积神经元网络与开源数据集方法
[J].
DOI:10.11947/j.AGCS.2019.20180206
[本文引用: 1]

从遥感图像中自动化地检测和提取建筑物在城市规划、人口估计、地形图制作和更新等应用中具有极为重要的意义。本文提出和展示了建筑物提取的数个研究进展。由于遥感成像机理、建筑物自身、背景环境的复杂性,传统的经验设计特征的方法一直未能实现自动化,建筑物提取成为30余年尚未解决的挑战。先进的深度学习方法带来新的机遇,但目前存在两个困境:①尚缺少高精度的建筑物数据库,而数据是深度学习必不可少的“燃料”;②目前国际上的方法都采用像素级的语义分割,目标级、矢量级的提取工作亟待开展。针对于此,本文进行以下工作:①与目前同类数据集相比,建立了一套目前国际上范围最大、精度最高、涵盖多种样本形式(栅格、矢量)、多类数据源(航空、卫星)的建筑物数据库(WHU building dataset),并实现开源;②提出一种基于全卷积网络的建筑物语义分割方法,与当前国际上的最新算法相比达到了领先水平;③将建筑物提取的范围从像素级的语义分割推广至目标实例分割,实现以目标(建筑物)为对象的识别和提取。通过试验,验证了WHU数据库在国际上的领先性和本文方法的先进性。
Building extraction via convolutional neural networks from an open remote sensing building dataset
[J].
DOI:10.11947/j.AGCS.2019.20180206
[本文引用: 1]
Automatic extraction of buildings from remote sensing images is significant to city planning, popular estimation, map making and updating.We report several important developments in building extraction. Automatic building recognition from remote sensing data has been a scientific challenge of more than 30 years. Traditional methods based on empirical feature design can hardly realize automation. Advanced deep learning based methods show prospects but have two limitations now. Firstly, large and accurate building datasets are lacking while such dataset is the necessary fuel for deep learning. Secondly, the current researches only concern building's pixel wise semantic segmentation and the further extractions on instance-level and vector-level are urgently required. This paper proposes several solutions. First, we create a large, high-resolution, accurate and open-source building dataset, which consists of aerial and satellite images with both raster and vector labels. Second,we propose a novel structure based on fully neural network which achieved the best accuracy of semantic segmentation compared to most recent studies. Third, we propose a building instance segmentation method which expands the current studies of pixel-level segmentation to building-level segmentation. Experiments proved our dataset's superiority in accuracy and multi-usage and our methods' advancement. It is expected that our researches might push forward the challenging building extraction study.
SegNet:A deep convolutional encoder-decoder architecture for image segmentation
[J].
DOI:10.1109/TPAMI.2016.2644615
PMID:28060704
[本文引用: 1]
We present a novel and practical deep fully convolutional neural network architecture for semantic pixel-wise segmentation termed SegNet. This core trainable segmentation engine consists of an encoder network, a corresponding decoder network followed by a pixel-wise classification layer. The architecture of the encoder network is topologically identical to the 13 convolutional layers in the VGG16 network [1]. The role of the decoder network is to map the low resolution encoder feature maps to full input resolution feature maps for pixel-wise classification. The novelty of SegNet lies is in the manner in which the decoder upsamples its lower resolution input feature map(s). Specifically, the decoder uses pooling indices computed in the max-pooling step of the corresponding encoder to perform non-linear upsampling. This eliminates the need for learning to upsample. The upsampled maps are sparse and are then convolved with trainable filters to produce dense feature maps. We compare our proposed architecture with the widely adopted FCN [2] and also with the well known DeepLab-LargeFOV [3], DeconvNet [4] architectures. This comparison reveals the memory versus accuracy trade-off involved in achieving good segmentation performance. SegNet was primarily motivated by scene understanding applications. Hence, it is designed to be efficient both in terms of memory and computational time during inference. It is also significantly smaller in the number of trainable parameters than other competing architectures and can be trained end-to-end using stochastic gradient descent. We also performed a controlled benchmark of SegNet and other architectures on both road scenes and SUN RGB-D indoor scene segmentation tasks. These quantitative assessments show that SegNet provides good performance with competitive inference time and most efficient inference memory-wise as compared to other architectures. We also provide a Caffe implementation of SegNet and a web demo at http://mi.eng.cam.ac.uk/projects/segnet.
Rethinking atrous convolution for semantic image segmentation
[J/OL].
基于特征压缩激活Unet网络的建筑物提取
[J].
DOI:10.12082/dqxxkx.2019.190285
[本文引用: 1]
自动提取城市建筑物对城市规划、防灾避险等行业应用具有重要意义,当前利用高空间分辨率遥感影像进行建筑物提取的卷积神经网络在网络结构和损失函数上都存在提升的空间。本研究提出一种卷积神经网络SE-Unet,以U-Net网络结构为基础,在编码器内使用特征压缩激活模块增加网络特征学习能力,在解码器中复用编码器中相应尺度的特征实现空间信息的恢复;并使用dice和交叉熵函数复合的损失函数进行训练,减轻了建筑物提取任务中的样本不平衡问题。实验采用了Massachusetts建筑物数据集,和SegNet、LinkNet、U-Net等模型进行对比,实验中SE-Unet在准确度、召回率、F1分数和总体精度 4项精度指标中表现最优,分别达到0.8704、0.8496、0.8599、0.9472,在测试影像中对大小各异和形状不规则的建筑物具有更好的识别效果。
Building extraction based on SE-unet
[J].
UNet:Redesigning skip connections to exploit multiscale features in image segmentation
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}