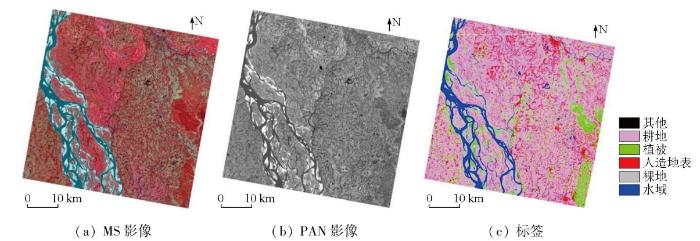
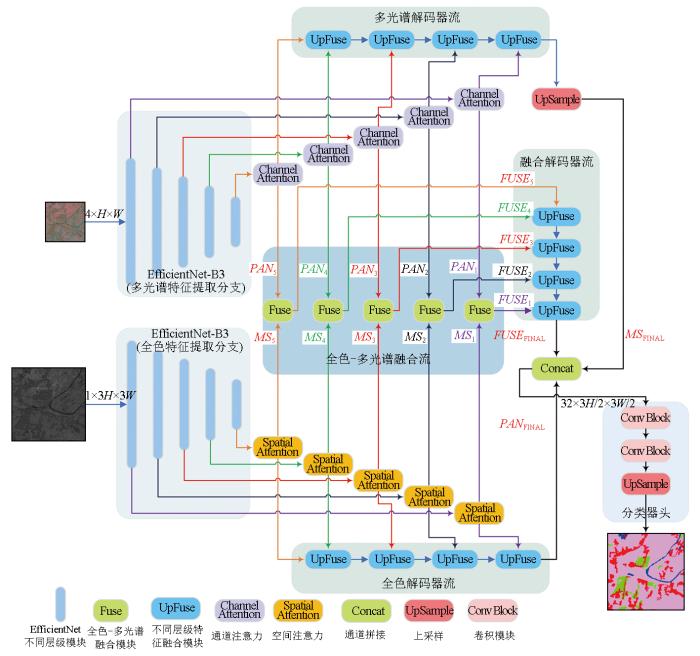
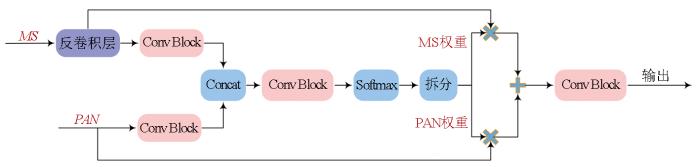
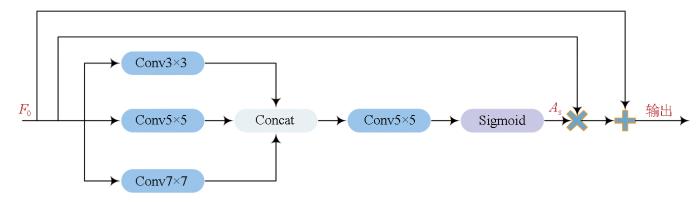
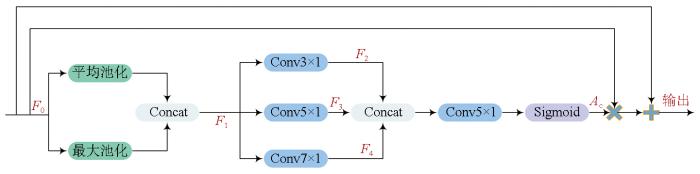
Multispectral (MS) and panchromatic (PAN) images serve as primary data sources for visible-near-infrared optical remote sensing imagery. In a typical land cover classification workflow,the spatial resolution of MS images is generally enhanced using pixel-level fusion methods,followed by image classification. However,the pixel-level fusion process is characterized by considerable time consumption and inconsistency with the optimization objectives of land cover classification,failing to meet the demand for end-to-end remote sensing image classification. To address these challenges,this paper proposed a dual-stream fully convolutional neural network,DSEUNet,which obviates the need for pixel-level fusion. Specifically,two branches were constructed based on the EfficientNet-B3 network to extract features from PAN and MS images,respectively. It was followed by feature-level fusion and decoding,thus outputting the ultimate classification results. Considering that PAN and MS images focus on different features of land cover elements,a spatial attention mechanism was incorporated in the PAN branch to enhance the perception of spatial information,such as details and edges. Moreover,a channel attention mechanism was incorporated in the MS branch to improve the perception of reflectance differences across multiple bands. Experiments on the 10-meter land cover dataset and ablation studies of the network structure demonstrate that the proposed network exhibited higher classification accuracy and faster inference speed. With the same backbone network,DSEUNet outperformed traditional pixel-level fusion-based classification methods,with an increase of 1.62 percentage points in mIoU,1.36 percentage points in mFscore,and 1.49 percentage points in Kappa coefficient,as well as a 17.69% improvement in inference speed.
LI Yinglong, DENG Yupeng, KONG Yunlong, CHEN Jingbo, MENG Yu, LIU Diyou. End-to-end land cover classification based on panchromatic-multispectral dual-stream convolutional network[J]. Remote Sensing for Land & Resources, 2025, 37(5): 152-161 doi:10.6046/zrzyyg.2024208
为了验证所提出的方法的有效性,本文将提出的DSEUNet与单流分类方法进行了对比。这里的单流分类方法指的是先对PAN影像和MS影像进行像素级融合,然后对融合影像进行分类的方法。对比方法包括经典的语义分割网络:基于ResNet50[23]骨干网络的Deeplabv3[24]和PspNet[25],SegNet[26],HRNet[27]和基于EfficientNet-B3网络的UNet[16];专门针对遥感领域设计的语义分割网络:UNetFormer[28],MACUNet[29],ABCNet[30],MANet[31]和MAResNet[32]等。精度评价指标包括平均交并比(mean intersection over union,mIoU)、总体精度(overall accuracy,OA)、平均F1分数(mFscore)和Kappa系数共4项指标。表1展示了不同模型的各项指标。其中,表格第3—7列展示的是相应方法的分类结果针对不同类别的交并比(intersection over union,IoU)值,表格第8—11列展示的是整体指标,每一列中加粗的数字表示最优指标(下同)。
Tab.1
表1
表1在10 m地表覆盖数据集上不同方法的分类指标
Tab.1 Classification index of different methods on 10 m land cover dataset (%)
本文进一步从参数量、计算量和推理速度3个维度对比了DSEUNet与传统单流网络的效率表现,其中计算量用浮点运算次数(giga floating point operations per second,GFLOPS)衡量;推理速度通过计算采用batch_size为8 h推理2 888个样本的平均耗时得到,用每秒帧数(frames per second,FPS)衡量,结果如表3所示。
Tab.3
表3
表3不同模型的网络效率指标
Tab.3 Network efficiency indicators of different models
GaetanoR, IencoD, OseK, et al.MRFusion:A Deep Learning architecture to fuse PAN and MS imagery for land cover mapping[J/OL]. arXiv, 2018(2018-06-29) [2024-11-03]. https://arxiv.org/abs/1806.11452v1.
Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixels-to-pixels, improve on the previous best result in semantic segmentation. Our key insight is to build "fully convolutional" networks that take input of arbitrary size and produce correspondingly-sized output with efficient inference and learning. We define and detail the space of fully convolutional networks, explain their application to spatially dense prediction tasks, and draw connections to prior models. We adapt contemporary classification networks (AlexNet, the VGG net, and GoogLeNet) into fully convolutional networks and transfer their learned representations by fine-tuning to the segmentation task. We then define a skip architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations. Our fully convolutional networks achieve improved segmentation of PASCAL VOC (30% relative improvement to 67.2% mean IU on 2012), NYUDv2, SIFT Flow, and PASCAL-Context, while inference takes one tenth of a second for a typical image.
RonnebergerO, FischerP, BroxT.U-net:Convolutional networks for biomedical image segmentation[C]// Proceedings of the Medical Image Computing and Computer-Assisted Intervention-MICCAI 2015: 18th International Conference.Springer,2015:234-241.
WooS, ParkJ, LeeJ Y, et al.CBAM:Convolutional block attention module[C]// Proceedings of the Proceedings of the European Conference on Computer Vision. Springer,2018:7132-7141.
FuJ, LiuJ, TianH, et al.Dual attention network for scene segmentation[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2019:3141-3149.
National Geomatics Center of China.CH/T 9032—2022 Global geographic information resource data product specification[S]. Beijing: China Cartographic Publishing House, 2022.
ZhaoH, ShiJ, QiX, et al.Pyramid scene parsing network[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2017:6230-6239.
We present a novel and practical deep fully convolutional neural network architecture for semantic pixel-wise segmentation termed SegNet. This core trainable segmentation engine consists of an encoder network, a corresponding decoder network followed by a pixel-wise classification layer. The architecture of the encoder network is topologically identical to the 13 convolutional layers in the VGG16 network [1]. The role of the decoder network is to map the low resolution encoder feature maps to full input resolution feature maps for pixel-wise classification. The novelty of SegNet lies is in the manner in which the decoder upsamples its lower resolution input feature map(s). Specifically, the decoder uses pooling indices computed in the max-pooling step of the corresponding encoder to perform non-linear upsampling. This eliminates the need for learning to upsample. The upsampled maps are sparse and are then convolved with trainable filters to produce dense feature maps. We compare our proposed architecture with the widely adopted FCN [2] and also with the well known DeepLab-LargeFOV [3], DeconvNet [4] architectures. This comparison reveals the memory versus accuracy trade-off involved in achieving good segmentation performance. SegNet was primarily motivated by scene understanding applications. Hence, it is designed to be efficient both in terms of memory and computational time during inference. It is also significantly smaller in the number of trainable parameters than other competing architectures and can be trained end-to-end using stochastic gradient descent. We also performed a controlled benchmark of SegNet and other architectures on both road scenes and SUN RGB-D indoor scene segmentation tasks. These quantitative assessments show that SegNet provides good performance with competitive inference time and most efficient inference memory-wise as compared to other architectures. We also provide a Caffe implementation of SegNet and a web demo at http://mi.eng.cam.ac.uk/projects/segnet.
WangJ, SunK, ChengT, et al.
Deep high-resolution representation learning for visual recognition
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(10):3349-3364.
SelvarajuR R, CogswellM, DasA, et al.Grad-CAM:Visual explanations from deep networks via gradient-based localization[C]//2017 IEEE International Conference on Computer Vision (ICCV). IEEE,2017:618-626.
... 为了验证所提出的方法的有效性,本文将提出的DSEUNet与单流分类方法进行了对比.这里的单流分类方法指的是先对PAN影像和MS影像进行像素级融合,然后对融合影像进行分类的方法.对比方法包括经典的语义分割网络:基于ResNet50[23]骨干网络的Deeplabv3[24]和PspNet[25],SegNet[26],HRNet[27]和基于EfficientNet-B3网络的UNet[16];专门针对遥感领域设计的语义分割网络:UNetFormer[28],MACUNet[29],ABCNet[30],MANet[31]和MAResNet[32]等.精度评价指标包括平均交并比(mean intersection over union,mIoU)、总体精度(overall accuracy,OA)、平均F1分数(mFscore)和Kappa系数共4项指标.表1展示了不同模型的各项指标.其中,表格第3—7列展示的是相应方法的分类结果针对不同类别的交并比(intersection over union,IoU)值,表格第8—11列展示的是整体指标,每一列中加粗的数字表示最优指标(下同). ...
... 为了验证所提出的方法的有效性,本文将提出的DSEUNet与单流分类方法进行了对比.这里的单流分类方法指的是先对PAN影像和MS影像进行像素级融合,然后对融合影像进行分类的方法.对比方法包括经典的语义分割网络:基于ResNet50[23]骨干网络的Deeplabv3[24]和PspNet[25],SegNet[26],HRNet[27]和基于EfficientNet-B3网络的UNet[16];专门针对遥感领域设计的语义分割网络:UNetFormer[28],MACUNet[29],ABCNet[30],MANet[31]和MAResNet[32]等.精度评价指标包括平均交并比(mean intersection over union,mIoU)、总体精度(overall accuracy,OA)、平均F1分数(mFscore)和Kappa系数共4项指标.表1展示了不同模型的各项指标.其中,表格第3—7列展示的是相应方法的分类结果针对不同类别的交并比(intersection over union,IoU)值,表格第8—11列展示的是整体指标,每一列中加粗的数字表示最优指标(下同). ...
DeepLab:Semantic image segmentation with deep convolutional nets,atrous convolution,and fully connected CRFs
1
2018
... 为了验证所提出的方法的有效性,本文将提出的DSEUNet与单流分类方法进行了对比.这里的单流分类方法指的是先对PAN影像和MS影像进行像素级融合,然后对融合影像进行分类的方法.对比方法包括经典的语义分割网络:基于ResNet50[23]骨干网络的Deeplabv3[24]和PspNet[25],SegNet[26],HRNet[27]和基于EfficientNet-B3网络的UNet[16];专门针对遥感领域设计的语义分割网络:UNetFormer[28],MACUNet[29],ABCNet[30],MANet[31]和MAResNet[32]等.精度评价指标包括平均交并比(mean intersection over union,mIoU)、总体精度(overall accuracy,OA)、平均F1分数(mFscore)和Kappa系数共4项指标.表1展示了不同模型的各项指标.其中,表格第3—7列展示的是相应方法的分类结果针对不同类别的交并比(intersection over union,IoU)值,表格第8—11列展示的是整体指标,每一列中加粗的数字表示最优指标(下同). ...
1
2017
... 为了验证所提出的方法的有效性,本文将提出的DSEUNet与单流分类方法进行了对比.这里的单流分类方法指的是先对PAN影像和MS影像进行像素级融合,然后对融合影像进行分类的方法.对比方法包括经典的语义分割网络:基于ResNet50[23]骨干网络的Deeplabv3[24]和PspNet[25],SegNet[26],HRNet[27]和基于EfficientNet-B3网络的UNet[16];专门针对遥感领域设计的语义分割网络:UNetFormer[28],MACUNet[29],ABCNet[30],MANet[31]和MAResNet[32]等.精度评价指标包括平均交并比(mean intersection over union,mIoU)、总体精度(overall accuracy,OA)、平均F1分数(mFscore)和Kappa系数共4项指标.表1展示了不同模型的各项指标.其中,表格第3—7列展示的是相应方法的分类结果针对不同类别的交并比(intersection over union,IoU)值,表格第8—11列展示的是整体指标,每一列中加粗的数字表示最优指标(下同). ...
SegNet:A deep convolutional encoder-decoder architecture for image segmentation
1
2017
... 为了验证所提出的方法的有效性,本文将提出的DSEUNet与单流分类方法进行了对比.这里的单流分类方法指的是先对PAN影像和MS影像进行像素级融合,然后对融合影像进行分类的方法.对比方法包括经典的语义分割网络:基于ResNet50[23]骨干网络的Deeplabv3[24]和PspNet[25],SegNet[26],HRNet[27]和基于EfficientNet-B3网络的UNet[16];专门针对遥感领域设计的语义分割网络:UNetFormer[28],MACUNet[29],ABCNet[30],MANet[31]和MAResNet[32]等.精度评价指标包括平均交并比(mean intersection over union,mIoU)、总体精度(overall accuracy,OA)、平均F1分数(mFscore)和Kappa系数共4项指标.表1展示了不同模型的各项指标.其中,表格第3—7列展示的是相应方法的分类结果针对不同类别的交并比(intersection over union,IoU)值,表格第8—11列展示的是整体指标,每一列中加粗的数字表示最优指标(下同). ...
Deep high-resolution representation learning for visual recognition
1
2021
... 为了验证所提出的方法的有效性,本文将提出的DSEUNet与单流分类方法进行了对比.这里的单流分类方法指的是先对PAN影像和MS影像进行像素级融合,然后对融合影像进行分类的方法.对比方法包括经典的语义分割网络:基于ResNet50[23]骨干网络的Deeplabv3[24]和PspNet[25],SegNet[26],HRNet[27]和基于EfficientNet-B3网络的UNet[16];专门针对遥感领域设计的语义分割网络:UNetFormer[28],MACUNet[29],ABCNet[30],MANet[31]和MAResNet[32]等.精度评价指标包括平均交并比(mean intersection over union,mIoU)、总体精度(overall accuracy,OA)、平均F1分数(mFscore)和Kappa系数共4项指标.表1展示了不同模型的各项指标.其中,表格第3—7列展示的是相应方法的分类结果针对不同类别的交并比(intersection over union,IoU)值,表格第8—11列展示的是整体指标,每一列中加粗的数字表示最优指标(下同). ...
UNetFormer:A UNet-like transfor-mer for efficient semantic segmentation of remote sensing urban scene imagery
1
2022
... 为了验证所提出的方法的有效性,本文将提出的DSEUNet与单流分类方法进行了对比.这里的单流分类方法指的是先对PAN影像和MS影像进行像素级融合,然后对融合影像进行分类的方法.对比方法包括经典的语义分割网络:基于ResNet50[23]骨干网络的Deeplabv3[24]和PspNet[25],SegNet[26],HRNet[27]和基于EfficientNet-B3网络的UNet[16];专门针对遥感领域设计的语义分割网络:UNetFormer[28],MACUNet[29],ABCNet[30],MANet[31]和MAResNet[32]等.精度评价指标包括平均交并比(mean intersection over union,mIoU)、总体精度(overall accuracy,OA)、平均F1分数(mFscore)和Kappa系数共4项指标.表1展示了不同模型的各项指标.其中,表格第3—7列展示的是相应方法的分类结果针对不同类别的交并比(intersection over union,IoU)值,表格第8—11列展示的是整体指标,每一列中加粗的数字表示最优指标(下同). ...
MACU-net for semantic segmentation of fine-resolution remotely sensed images
1
2022
... 为了验证所提出的方法的有效性,本文将提出的DSEUNet与单流分类方法进行了对比.这里的单流分类方法指的是先对PAN影像和MS影像进行像素级融合,然后对融合影像进行分类的方法.对比方法包括经典的语义分割网络:基于ResNet50[23]骨干网络的Deeplabv3[24]和PspNet[25],SegNet[26],HRNet[27]和基于EfficientNet-B3网络的UNet[16];专门针对遥感领域设计的语义分割网络:UNetFormer[28],MACUNet[29],ABCNet[30],MANet[31]和MAResNet[32]等.精度评价指标包括平均交并比(mean intersection over union,mIoU)、总体精度(overall accuracy,OA)、平均F1分数(mFscore)和Kappa系数共4项指标.表1展示了不同模型的各项指标.其中,表格第3—7列展示的是相应方法的分类结果针对不同类别的交并比(intersection over union,IoU)值,表格第8—11列展示的是整体指标,每一列中加粗的数字表示最优指标(下同). ...
ABCNet:Attentive bilateral contextual network for efficient semantic segmentation of fine-resolution remotely sensed imagery
1
2021
... 为了验证所提出的方法的有效性,本文将提出的DSEUNet与单流分类方法进行了对比.这里的单流分类方法指的是先对PAN影像和MS影像进行像素级融合,然后对融合影像进行分类的方法.对比方法包括经典的语义分割网络:基于ResNet50[23]骨干网络的Deeplabv3[24]和PspNet[25],SegNet[26],HRNet[27]和基于EfficientNet-B3网络的UNet[16];专门针对遥感领域设计的语义分割网络:UNetFormer[28],MACUNet[29],ABCNet[30],MANet[31]和MAResNet[32]等.精度评价指标包括平均交并比(mean intersection over union,mIoU)、总体精度(overall accuracy,OA)、平均F1分数(mFscore)和Kappa系数共4项指标.表1展示了不同模型的各项指标.其中,表格第3—7列展示的是相应方法的分类结果针对不同类别的交并比(intersection over union,IoU)值,表格第8—11列展示的是整体指标,每一列中加粗的数字表示最优指标(下同). ...
Multiattention network for semantic segmentation of fine-resolution remote sensing images
1
2021
... 为了验证所提出的方法的有效性,本文将提出的DSEUNet与单流分类方法进行了对比.这里的单流分类方法指的是先对PAN影像和MS影像进行像素级融合,然后对融合影像进行分类的方法.对比方法包括经典的语义分割网络:基于ResNet50[23]骨干网络的Deeplabv3[24]和PspNet[25],SegNet[26],HRNet[27]和基于EfficientNet-B3网络的UNet[16];专门针对遥感领域设计的语义分割网络:UNetFormer[28],MACUNet[29],ABCNet[30],MANet[31]和MAResNet[32]等.精度评价指标包括平均交并比(mean intersection over union,mIoU)、总体精度(overall accuracy,OA)、平均F1分数(mFscore)和Kappa系数共4项指标.表1展示了不同模型的各项指标.其中,表格第3—7列展示的是相应方法的分类结果针对不同类别的交并比(intersection over union,IoU)值,表格第8—11列展示的是整体指标,每一列中加粗的数字表示最优指标(下同). ...
Multistage attention ResU-net for semantic segmentation of fine-resolution remote sensing images
1
2022
... 为了验证所提出的方法的有效性,本文将提出的DSEUNet与单流分类方法进行了对比.这里的单流分类方法指的是先对PAN影像和MS影像进行像素级融合,然后对融合影像进行分类的方法.对比方法包括经典的语义分割网络:基于ResNet50[23]骨干网络的Deeplabv3[24]和PspNet[25],SegNet[26],HRNet[27]和基于EfficientNet-B3网络的UNet[16];专门针对遥感领域设计的语义分割网络:UNetFormer[28],MACUNet[29],ABCNet[30],MANet[31]和MAResNet[32]等.精度评价指标包括平均交并比(mean intersection over union,mIoU)、总体精度(overall accuracy,OA)、平均F1分数(mFscore)和Kappa系数共4项指标.表1展示了不同模型的各项指标.其中,表格第3—7列展示的是相应方法的分类结果针对不同类别的交并比(intersection over union,IoU)值,表格第8—11列展示的是整体指标,每一列中加粗的数字表示最优指标(下同). ...












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}