

0 引言
高分辨率遥感影像作为当前空天地全方位观测体系中的重要环节,能够针对各类场景进行精确、细致的观测,从而为众多科学研究和工程应用提供基础数据支持和可靠的实景参考[1
高分辨率遥感影像分割是根据一定的规则,将高分辨率遥感影像划分为不同的区域或对象的过程,旨在将影像中的不同地物和特征清晰地区分开来。这不仅能降低遥感影像的解译难度,还能压缩庞大的数据量,简化遥感影像的处理过程,是高分辨率遥感影像数据处理的关键技术[5
这种高效快速的影像信息提取技术,对于土地利用与土地覆盖调查来说,能够迅速估算出土地利用的面积、比例和分布情况。在生态环境保护领域,它可以对一些典型的污染情况进行监测、探查与定位。此外,在城市规划方面,高分辨率遥感影像分割提供了城市中的建筑物、道路、绿化场地等空间信息。同时,它还具有快速提取灾害区域、分析灾害程度的能力。总体上,高分辨率遥感影像分割在遥感领域中具有举足轻重的地位和作用,是目前遥感技术发展的主要方向之一[9
目前常用的高分辨率遥感影像分割方法主要分为非监督分析方法与监督学习方法。其中,非监督分析方法大多需要从影像中提取典型特征,并依赖地物的特征差异实现分割任务,主要方法包括:阈值分割法[13]、区域分割法[14]、边缘检测分割法[15]、基于小波变换的分割方法[16]以及基于聚类的分割方法[17]等。这种分析思路在地物特征明显、不同地物特征差异较大的地面场景中,能够以无需样本、自动化的优势获取较好的分割效果。然而,受制于特征设计、特征提取和特征统计分析的性能,再加上噪声等干扰因素的存在,这类方法在面对高分辨率的复杂地面场景时,可能在地物认知性能、泛化推理程度与抗干扰能力等方法还有所欠缺,在实现高精度的高分辨率遥感影像分割方面仍需面临诸多挑战。
而监督学习方法主要尝试从样本中学习到可泛化的分割规律,对影像进行划分。当下随着卷积神经网络(convolutional neural network,CNN)不断地发展,深度学习神经网络分割成为目前最为流行的监督学习分割方法[18-19]。这种深度学习方法,通过层次化的卷积与后向传播修正,自动化地映射影像数据与地物类别的关系,能够从影像中抽象出非线性的隐含特征,实施高精度的地物划分,主要包括:基于编码器-解码器的分割方法[20
经过多年研究,高分辨率遥感影像分割方法在充足样本条件下已经能够对典型、完整的地物区块进行高精度划分,为各种应用提供准确的地物分布参考。然而,高分辨率遥感影像地物繁复无规律,且地面场景易受多种因素影响而变化较大,不但非监督分析难以解析复杂地物,监督学习也难以建立可靠、通用的样本库。因此,在面对缺乏样本和存在大量干扰信息的复杂地面场景时,单纯依赖非监督分析和监督学习可能难以从影像中抽取出可信、准确的地物语义信息。尽管现有研究通过半监督学习(如伪标签技术)[31]、自监督学习(如对比学习框架)及混合方法(如协同训练)等类自学习分割方法,尝试缓解样本依赖问题,但这些方法仍面临伪标签噪声累积、模型复杂度高或跨场景适应性不足等挑战。为此,迫切需要探索一种具备自学习能力的分割方法,以克服非监督分析在认知性能上的局限性和监督学习对样本的过度依赖。
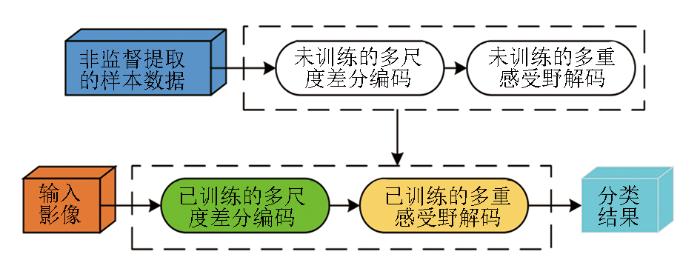
针对当前高分辨率遥感影像分割对自学习能力的需要,本文参考人眼视觉感知的自学习能力,设计了一种基于视觉双驱动认知的自学习分割方法。该方法参考视觉双驱动注意机制,首先利用自底向上数据驱动的非监督光谱聚类对影像进行初步解析,得到超像素边缘并生成影像的同源可靠样本;随后,通过自顶向下任务驱动的轻量级自注意神经网络学习影像同源可靠样本,实现对影像复杂地面场景的准确辨识;最后,参照眼球的微颤动感知机制,根据非监督分析得到的超像素边缘,对神经网络认知结果进行自检校的噪声去除与边缘恢复,得到尽可能准确、可靠的分割结果。
1 视觉感知特性基础
1.1 视觉的双驱动注意机制
人眼的双驱动注意模式能够筛选观测场景的内容,减少待处理信息的复杂度,从而对不同目标实施不同权重的观察,快速、灵活地对场景观察与反馈。这种双驱动注意机制通常以自底向上(bottom-up)的数据驱动方式来快速、模糊地解读低空间频率的场景,并通过自顶向下(top-down)的任务驱动来精细、准确地观察高空间频率或运动的目标[32]。这种机制能有效地利用数据和任务之间的互补性,达成更高效、准确的场景理解。
1.2 视觉的颜色拮抗
1.3 视神经的非经典感受野模型
随着生物神经信息学的研究不断深入,Li等[39]发现视觉神经元感受野外部存在一个能够对经典感受野进行调制、响应的大外周区域,称为非经典感受野(non-classical receptive field,NCRF),可以通过三高斯模型来模拟NCRF对经典感受野的调制特性,其数学表达式为:
E(x,y)=aexp
式中:E(x,y)为感受野上某一点(x,y)感受到的强度;a为敏感区;b为外周区;c为去抑制区;r1,r2,r3分别为感受野不同区域的半径。
在此基础上,Grigorescu等[40]采用二维Gabor函数表征视皮层感知轮廓的方向选择性,配合高斯差分(difference of Gaussian,DoG)函数及高斯拉普拉斯(Laplacian of a Gaussian,LoG)函数模拟外周环绕的侧抑制作用,构建了模拟NCRF各向同性和各向异性的轮廓认知模型,实现了对遥感影像较好的边缘特征认知。其数学表达式为:
式中:DoGr(x,y)和LoGr(x,y)为感受野上某一采样位置(x,y)的强度;k为NCRF与经典感受野的半径比;r为感受野半径。
1.4 视觉的瑞利明暗判据
(1-0.735)/(1+0.735)=15.27% ,
1.5 视觉的等级层次认知特性
1.6 眼球的微颤动感知
2 模拟视觉双驱动认知的自适应分割方法
参考视觉自底向上感知与自顶向下观察的双驱动认知机制,本文提出了一种自适应的分割思路,采用非监督聚类分析模拟基于数据驱动的自底向上感知,通过深度学习网络模拟基于任务驱动的自顶向下注视,从而对高分辨率遥感影像实施智能化自适应的解读,如图1所示。
图1
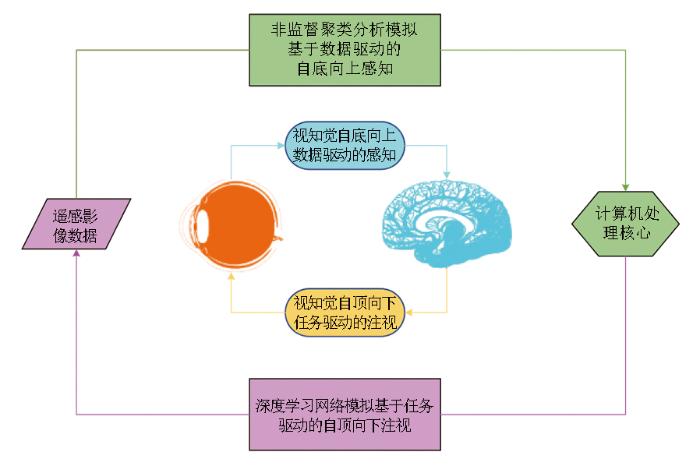
图1
模拟视觉双驱动认知的自适应分割思路
Fig.1
Adaptive segmentation method for simulating visual dual drive cognition
2.1 模拟视觉颜色拮抗的光谱校正
参考已探明的视杆细胞解析光强、视锥细胞解析波段的视觉颜色拮抗理论,将影像中的地物光谱由成像时常用的RGB颜色空间,转换到目前已广泛使用的CIE-Lab颜色模型[57],以“L”通道描述光强明度,以“a”通道描述从红色到深绿的光谱,以“b”通道描述从蓝色到黄色的光谱[58],从而对光谱范围进行更加全面的表达。并且CIE-Lab颜色模型还能够在不同照明和观察条件下,最大程度地令任意2种颜色刺激的感知差异和数值计算出的色差保持一致[59]。这种与光线及设备无关的颜色表征性能,能够帮助地物光谱的量化数值贴近人眼视觉感受,为地物光谱特征的认知提供基础保障,能够有效提高分割算法的认知性能与分割精度。具体来说,先将RGB过渡至CIE-XYZ空间,再转换到CIE-Lab空间,其转换关系表达式为:
式中:X,Y,Z为 CIE-XYZ 颜色空间的3个分量,其中 Y 用于描述光强明度;R,G,B分别为原始颜色空间的红、绿、蓝3通道数值;L*,a*,b*分别为光强明度、红色至深绿的颜色分量和蓝色至黄色的颜色分量。
2.2 模拟视神经NCRF的边缘识别与超像素划分
参考现有DoG函数及LoG函数对NCRF中外周侧抑制作用的模拟,采用二维离散信号处理中常用且著名的LoG算子(基于 LoG 函数),可以对影像灰度的梯度进行符合人眼视觉感受的度量,从而高效自动化地解析出影像灰度变化剧烈的边缘,表达式为:
式中:L为拉普拉斯运算结果,度量灰度梯度;∇2为拉普拉斯算子,∇为梯度算子;f(x,y)为灰度值。
在解析出灰度变化剧烈的边缘后,在边缘包围的不规则区域内部,由于灰度变化小、空间频率低且光谱特征相似,一般可认为由单一类别地物组成。因此,在完成边缘检测后,可以将由边缘包裹的独立区域作为超像素,以提高地物认知效率。
此外,在不同尺度使用LoG算子,可以模拟视神经NCRF对不同尺度的边缘进行辨识,并获取地物在不同尺度下组成的超像素斑块。在此基础上,将不同尺度的超像素表征图进行叠加,使相同地物的超像素相互覆盖,不同地物的超像素相互区分,最终得以通过多尺度的地物超像素对不同尺度的地物进行完善呈现,如图2所示。具体来说,首先将不同尺度超像素表征图缩放到相同大小;然后对不同尺度的超像素斑块进行腐蚀,腐蚀半径大小与尺度大小成比例,以保障相同地物叠加覆盖时,小尺度边缘可以得到保护;最后从多尺度叠加后的超像素表征图中筛除小面积噪声,并以4连通为依据对不同超像素斑块进行编号,形成独立地物的表征图。
图2
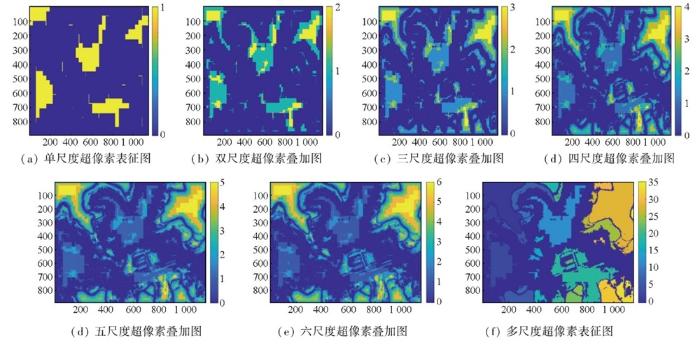
图2
独立地物的多尺度表征示例图
Fig.2
Multi-scale representation example map of independent ground objects
2.3 基于瑞利明暗判据的多尺度超像素聚类
在获取独立地物几何位置的基础上,若能准确辨识独立地物的类别归属,即可建立影像数据与地物类别间的映射,从而为深度学习神经网络构建同源可靠样本。受此启发,针对已标记的独立地物,从多尺度影像中探明独立地物的典型光谱波段,参考瑞利判据下的迈克尔逊对比度阈值15.27%,即可解析独立地物的光谱分布,从而对独立地物的超像素斑块实施无监督、自动化的聚类,获取独立地物的类别归属。具体来说,针对每一个独立地物,首先,需要分析其超像素斑块所在的尺度,当有多个尺度的超像素斑块时,取尺度中值作为可信尺度从而增强稳定性和鲁棒性;然后,根据每个独立地物的可信尺度,从对应尺度的影像中找出超像素斑块区域的光谱分布,由于该区域光谱波动较小,可以取均值作为独立地物的光谱波段;最后,以瑞利判据提供的迈克尔逊对比度阈值15.27%,对所有独立地物的光谱波段进行自适应聚类,自动计算出最佳类别数,从而得到独立地物的类别属性,构建影像数据与地物类别间的映射,生成同源可靠样本,如图3所示。
图3
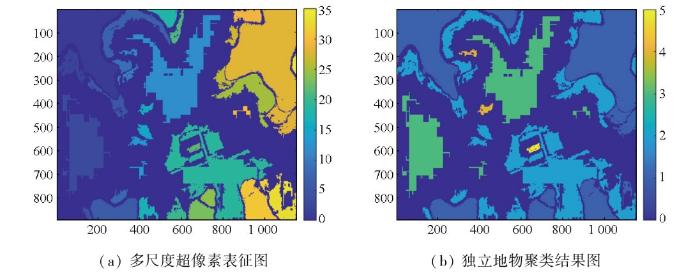
图3
超像素聚类形成同源可靠样本示例图
Fig.3
Superpixel clustering forms an example map of homologous reliable samples
2.4 基于视觉注意的多特征变形轻量神经网络
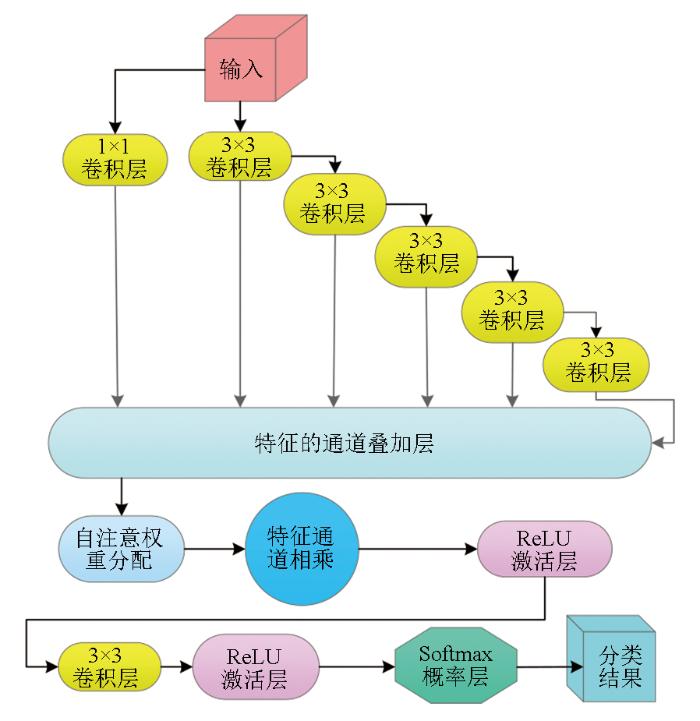
在场景感知过程中,视觉注意机制能够将中央凹视锥细胞对准感兴趣目标,从而形成注视现象,完成对感兴趣目标或区域的精细观察。由于能够提供灵活且强大的空间关系建模思路,这种注意机制目前被广泛应用于计算机视觉 Transformer神经网络当中[60-
图4
图5
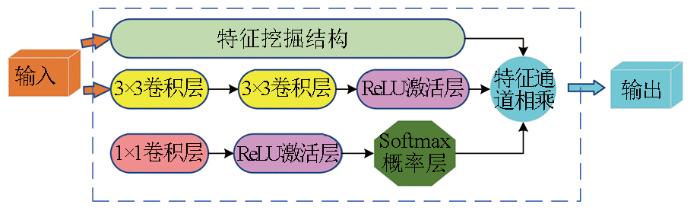
图6
在解码方面,利用2个3×3卷积串联,第一个卷积感受野为 3×3,因第二个卷积的输入是第一个卷积操作后的特征图,所以最终输出的感受野大小相当于5×5,从而实现模拟5×5卷积的感受野,以此类推,通过多个3×3卷积模拟5×5,7×7,9×9的多重感受野,结合1×1卷积构建多卷积模板,结合残差连接和通道叠加,在避免过拟合的基础上解码不同尺度特征,采用一种类似层权重分配的机制,通过图5所示自注意权重分配结构,减少底层过多特征带来的细节噪声与运算负担,提高精度与效率[68],为进一步的通道相乘运算提供权重参数[67],并结合Softmax概率函数分割器,以交叉熵作为损失函数,构建多重感受野解码结构,进行解码分割,如图7所示。
图7
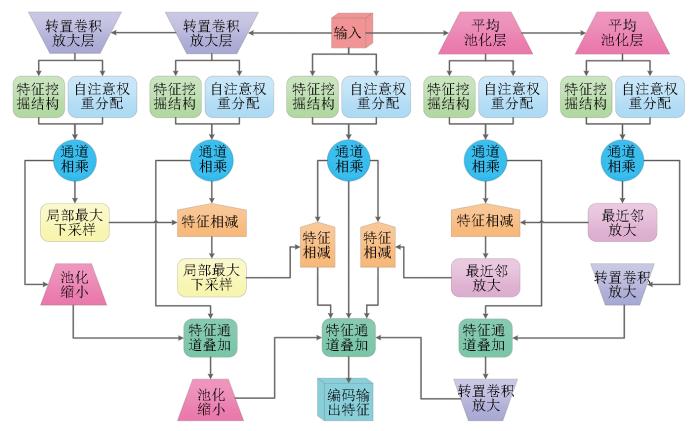
最后,在使用多尺度差分编码结构解析输入影像隐藏特征的基础上,通过多重感受野解码结构映射特征与分割间的关联,形成完整的后向与前向传播链,参考由自底向上非监督分析获取的样本信息,即可构成自顶向下的观察神经网络,完成对地表场景的细致观察,如图8所示。
图8
2.5 基于眼球微颤动感知机制的错误修复
眼球微颤动自底向上认知背景、自顶向下解析细节,受此启发,本文提出了一种模拟眼球微颤动感知机制的错误修复思路,借助非监督分析提取出的超像素边界,滤除噪声并修复边缘。具体来说,在自底向上解析全局划分出的超像素的基础上,由于超像素内部具有较好的光谱一致性,可将每个超像素视为只包含单类地物的单元;以此为根据,将自顶向下神经网络辨识的地物类别结果,映射到每个超像素中,再以超像素中分布数量最多的地物类别作为该超像素的分割结果,获取所有超像素的分割结果,从而在保护边缘的前提下,滤除和修复由脏样本或过分割带来的细节噪声,有效提高分割精度,增强分割结果的可信度与实用性,如图9所示。
图9
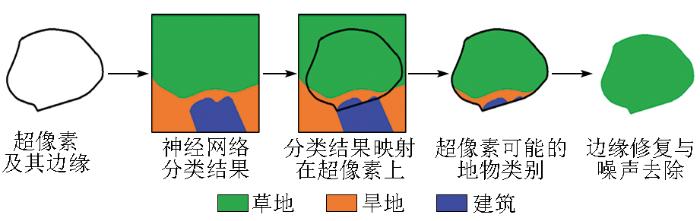
最后,本文参考了一系列视觉感知机理,在自底向上感知与自顶向下观察的双驱动认知框架下,构建了基于视觉双驱动认知的高分辨率遥感影像自学习分割方法,试图以自底向上的非监督聚类获取场景的基本组成,并以此为先验知识,尝试通过神经网络实施自顶向下的详尽观察以实现场景的准确认知,并结合超像素划分带来的参考信息,去除错误并修复边缘,最终实现自动化、智能化、抗干扰的高分辨率遥感影像分割,整体流程如图10所示。
图10
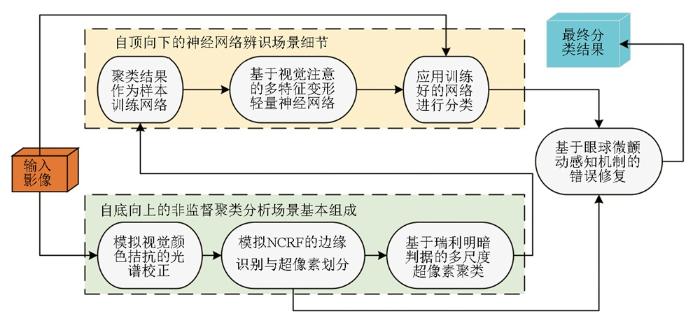
图10
模拟视觉双驱动认知的自适应分割流程
Fig.10
Adaptive segmentation process simulating visual dual drive cognition
3 实验与分析
3.1 实验设计
为了验证本文提出的视觉双驱动自学习分割方法,采用真实高分辨率遥感影像对分割方法进行测试,主要以无人机影像与WorldView-3卫星数据为主,空间分辨率优于1.5 m,能够对地面场景的各种目标进行清晰展示,并且为了更好地贴合实际应用,选取6种不同复杂场景下的小区域位置,这些地方都难以获取样本。
同时,为了客观评价本文方法的地物认知性能与分割精度,选取同样带有注意力结构的神经网络,并嵌入本文提出的双通路分割思路以保持相同的实验条件,从而进行真实、公平的对比。具体来说,使用了已经非常成熟且广受好评的Mask R-CNN(MR)网络及清华大学近期发布的ScalableViT(SViT)网络[61,72]。其中,MR网络在经典Faster R-CNN[73]目标识别网络中加入了基于Mask的注意力机制,能够在识别目标的基础上,通过Mask注意力机制找出目标的轮廓与边界,完成高精度分割,受到广泛好评[72];SViT网络则通过可伸缩自我注意在空间和通道维度进行上下文泛化,并结合一个交互式自注意结构,增强了期望的全局接受域,利用Transformer在单层以最显著的优势取得了高精度的分割性能[61]。此外,所有网络大致都设置在60层左右,卷积通道数不超过64,未知数个数限制为30万左右,学习率统一选在为0.005,即可形成足够的地物认知能力以进行实验比对。
然后,通过自底向上非监督聚类获取场景的基本组成后,在聚类结果的每个类别中,选取一个非背景像素为中心,构造一个32像素×32像素大小的像素框,截取原始图像和聚类结果,形成该类别的一个训练样本。并根据非监督聚类结果,从每个类别中随机选取200个像素作为像素框中心,可获得200个训练样本,以满足神经网络对样本的需要。
最后,除了整体评价外,在每张影像中选取3个小区域,以进行更小尺度的分割精度评定。
3.2 实验结果
根据实验设计,为了验证本文方法在不同场景下特别是在复杂地物识别和精确分割方面的应用潜力,选取了6张影像作为初始数据进行实验,影像中包含建筑、植被、水体、土壤和道路等多种典型地物。使用非监督聚类获取训练样本之后,在使用包括本文方法在内的3种神经网络进行地类分割,并将分割结果与地面真值进行比对,再用4种评价指标对3种方法的分割精度进行客观评价。通过这一系列实验,能够清晰地评估所提方法在复杂地物场景下的表现,并与现有的主流方法进行对比,为方法的进一步优化与实际应用提供有力的支持。
3.2.1 实验一
选择地物类型多样,房屋建筑、道路和多种植被混合的复杂地区为实验一场景,同时该区域影像明亮,光照强度大。在该区域中,选取了3个典型地物作为小区域:独栋小房屋、道路岔口以及顶面结构复杂的较大型房屋。按照上述方法得到实验结果,实验整体和小区域的分割精度见表1,分割结果如图11所示。该实验场景地物细节丰富,光照强度大,在此基础上,参考地面真值,对于自适应得到的地物样本,3种方法都能对地物进行较好的认知。但MR方法容易受到地物细节干扰,导致该方法在辨识地物的过程中带入了大量椒盐噪声。而SViT则展现出更强的认知性能,但由于光照的干扰与样本数量的限制,导致该方法将一些光照过强的房屋误认为地面道路与空地。对比之下,本文方法不但可以充分辨识不同光照条件下的房屋,而且可以对地物细节噪声进行很好的抵抗,得到了最佳的分割效果与分割精度。
图11
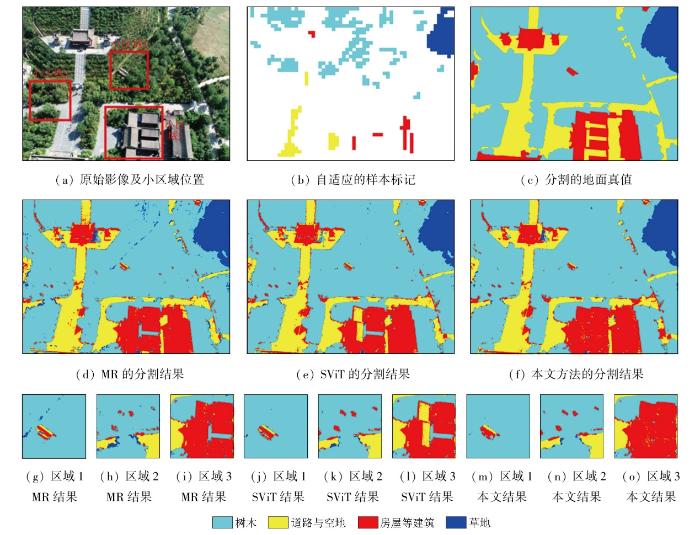
表1 实验一的分割精度
Tab.1
| 精度 指标 | MR | SViT | 本文方法 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 整张影像 | 小区域1 | 小区域2 | 小区域3 | 整张影像 | 小区域1 | 小区域2 | 小区域3 | 整张影像 | 小区域1 | 小区域2 | 小区域3 | |
| OA | 0.861 | 0.858 | 0.867 | 0.950 | 0.961 | 0.966 | 0.882 | 0.883 | 0.890 | 0.715 | 0.648 | 0.728 |
| K | 0.742 | 0.734 | 0.752 | 0.484 | 0.508 | 0.543 | 0.669 | 0.664 | 0.675 | 0.542 | 0.445 | 0.556 |
| QD | 0.052 | 0.048 | 0.053 | 0.026 | 0.017 | 0.016 | 0.064 | 0.058 | 0.051 | 0.172 | 0.098 | 0.172 |
| AD | 0.087 | 0.094 | 0.079 | 0.024 | 0.022 | 0.018 | 0.054 | 0.059 | 0.059 | 0.113 | 0.254 | 0.100 |
3.2.2 实验二
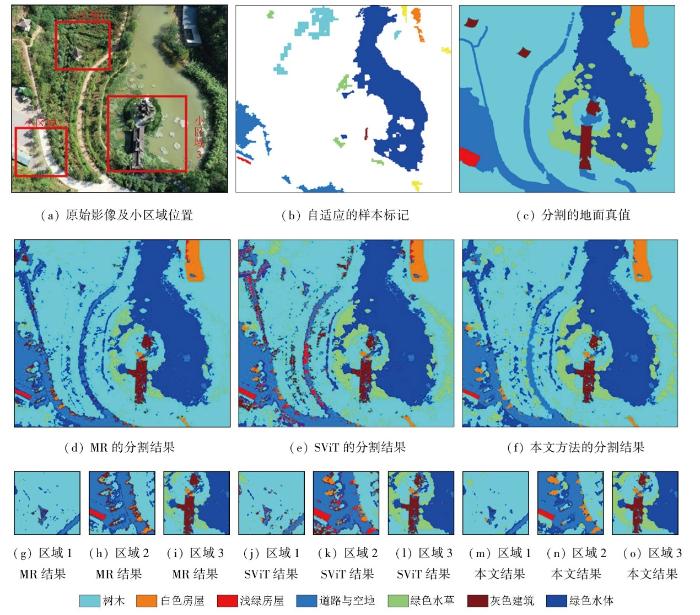
同样选择具有复杂地物组合的区域为实验二场景,该区域中包含绿色水体,并且影像中存在大量阴影。在该区域中选择3个典型的地物小区域进行分析:独立的亭台、弯道与浅绿房屋以及水中的灰色建筑。实验整体和小区域的分割精度见表2,分割结果如图12所示。面对多种房屋、道路、植被与水体混杂等多地物混合的复杂地面场景,MR方法凭借其强大的细节认知能力,在详细辨识地物的同时,将许多阴影误认为是灰色建筑,降低了整体的认知精度。而SViT在分析复杂多样的地物时,由于样本数量的限制,各类地物可能并未进行足够均衡的训练,导致很多植物被误认为房屋。另外,本文方法虽然将一些树木误认为是光谱相似的水草,但能够避免阴影的干扰,正确认知房屋、道路与水体,取得了最高的分割精度。
表2 实验二的分割精度
Tab.2
| 精度 指标 | MR | SViT | 本文方法 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 整张影像 | 小区域1 | 小区域2 | 小区域3 | 整张影像 | 小区域1 | 小区域2 | 小区域3 | 整张影像 | 小区域1 | 小区域2 | 小区域3 | |
| OA | 0.799 | 0.918 | 0.642 | 0.741 | 0.767 | 0.896 | 0.616 | 0.652 | 0.815 | 0.922 | 0.645 | 0.761 |
| K | 0.690 | 0.574 | 0.513 | 0.649 | 0.639 | 0.522 | 0.485 | 0.535 | 0.678 | 0.587 | 0.523 | 0.675 |
| QD | 0.086 | 0.040 | 0.252 | 0.156 | 0.084 | 0.060 | 0.271 | 0.191 | 0.07 | 0.059 | 0.250 | 0.090 |
| AD | 0.119 | 0.032 | 0.106 | 0.102 | 0.149 | 0.043 | 0.113 | 0.157 | 0.111 | 0.029 | 0.105 | 0.149 |
图12
3.2.3 实验三
图13
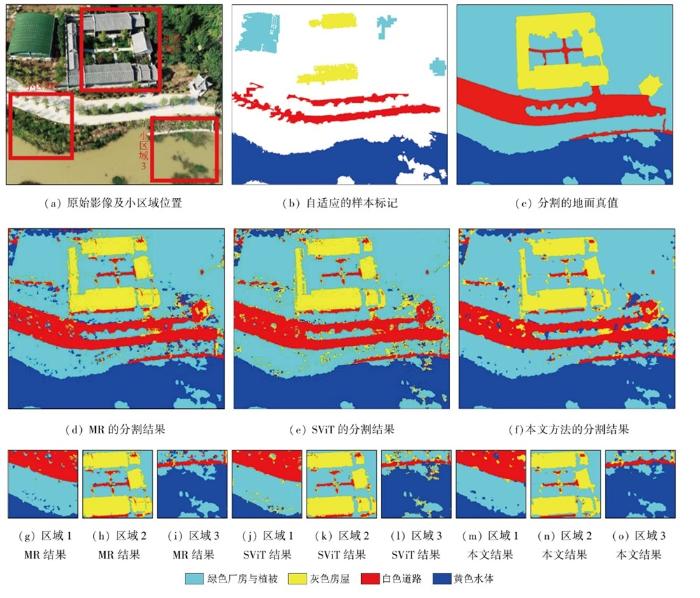
表3 实验三的分割精度
Tab.3
| 精度 指标 | MR | SViT | 本文方法 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 整张影像 | 小区域1 | 小区域2 | 小区域3 | 整张影像 | 小区域1 | 小区域2 | 小区域3 | 整张影像 | 小区域1 | 小区域2 | 小区域3 | |
| OA | 0.861 | 0.939 | 0.819 | 0.852 | 0.856 | 0.934 | 0.829 | 0.824 | 0.876 | 0.951 | 0.850 | 0.893 |
| K | 0.787 | 0.902 | 0.669 | 0.716 | 0.782 | 0.896 | 0.691 | 0.685 | 0.810 | 0.920 | 0.727 | 0.799 |
| QD | 0.053 | 0.054 | 0.109 | 0.133 | 0.058 | 0.054 | 0.117 | 0.161 | 0.056 | 0.027 | 0.088 | 0.088 |
| AD | 0.086 | 0.007 | 0.072 | 0.015 | 0.086 | 0.012 | 0.054 | 0.015 | 0.068 | 0.022 | 0.062 | 0.019 |
3.2.4 实验四
表4 实验四的分割精度
Tab.4
| 精度 指标 | MR | SViT | 本文方法 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 整张影像 | 小区域1 | 小区域2 | 小区域3 | 整张影像 | 小区域1 | 小区域2 | 小区域3 | 整张影像 | 小区域1 | 小区域2 | 小区域3 | |
| OA | 0.774 | 0.709 | 0.863 | 0.779 | 0.774 | 0.738 | 0.787 | 0.781 | 0.803 | 0.765 | 0.851 | 0.775 |
| K | 0.705 | 0.522 | 0.796 | 0.617 | 0.697 | 0.538 | 0.686 | 0.607 | 0.735 | 0.568 | 0.779 | 0.599 |
| QD | 0.135 | 0.241 | 0.05 | 0.133 | 0.159 | 0.216 | 0.160 | 0.156 | 0.110 | 0.157 | 0.082 | 0.149 |
| AD | 0.091 | 0.050 | 0.087 | 0.088 | 0.067 | 0.046 | 0.053 | 0.063 | 0.087 | 0.078 | 0.067 | 0.076 |
图14
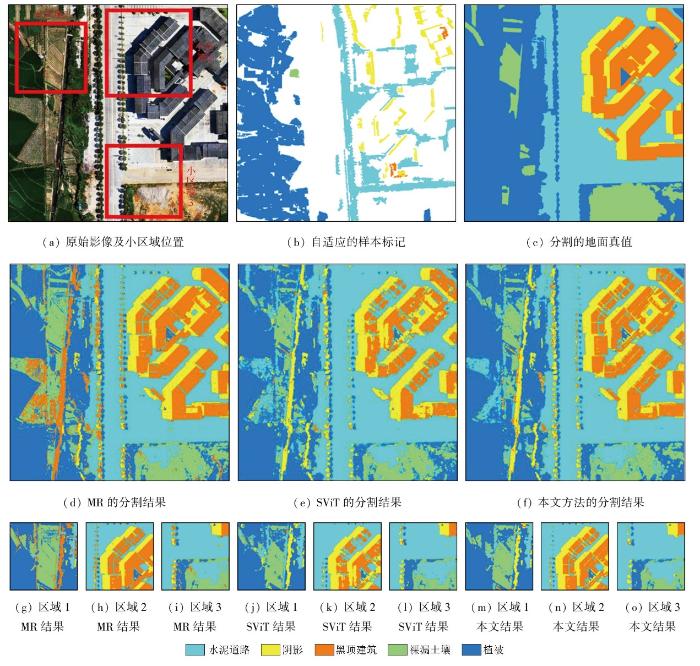
3.2.5 实验五
表5 实验五的分割精度
Tab.5
| 精度 指标 | MR | SViT | 本文方法 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 整张影像 | 小区域1 | 小区域2 | 小区域3 | 整张影像 | 小区域1 | 小区域2 | 小区域3 | 整张影像 | 小区域1 | 小区域2 | 小区域3 | |
| OA | 0.800 | 0.670 | 0.686 | 0.521 | 0.792 | 0.644 | 0.750 | 0.515 | 0.816 | 0.677 | 0.758 | 0.533 |
| K | 0.713 | 0.528 | 0.548 | 0.299 | 0.703 | 0.502 | 0.629 | 0.309 | 0.719 | 0.530 | 0.631 | 0.301 |
| QD | 0.108 | 0.273 | 0.162 | 0.385 | 0.131 | 0.304 | 0.082 | 0.405 | 0.113 | 0.264 | 0.082 | 0.319 |
| AD | 0.092 | 0.057 | 0.152 | 0.094 | 0.077 | 0.052 | 0.168 | 0.080 | 0.070 | 0.039 | 0.151 | 0.078 |
图15
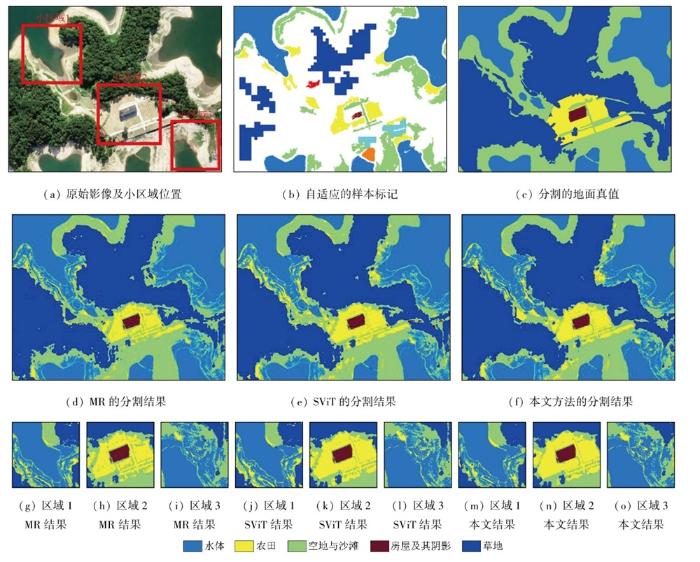
3.2.6 实验六
实验六涵盖了不同类型的房屋建筑,这些建筑分布不均且与大量高耸植被交织在一起,选择散布的红色房屋、深蓝房屋与空地以及植被与土壤交错的地方作为小区域进行分析。实验整体和小区域的分割精度见表6,分割结果如图16所示。面对多种类型、非均匀分布的房屋混合高耸植被的复杂场景,3种方法都可以对复杂地面场景进行较为良好的自适应解读。但面对数量稀少的深蓝房屋,由于特征与样本的稀缺及光照条件的差异,辨识效果均不理想。其中,MR方法通过过拟合达到了对深蓝房屋最优认知,也将大量其他地物误认为深蓝房屋,带来了大量噪声,干扰正确解读。而SViT则过拟合了红色房屋,导致其他地物被错误标记为红色房屋降低了分割精度。另外,本文方法通过对各类地物的合适拟合,形成了最佳的泛化能力,能有效抵抗噪声干扰,达到了最佳分割结果与最高分割精度。
表6 实验六的分割精度
Tab.6
| 精度 指标 | MR | SViT | 本文方法 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 整张影像 | 小区域1 | 小区域2 | 小区域3 | 整张影像 | 小区域1 | 小区域2 | 小区域3 | 整张影像 | 小区域1 | 小区域2 | 小区域3 | |
| OA | 0.822 | 0.788 | 0.825 | 0.904 | 0.854 | 0.820 | 0.861 | 0.909 | 0.855 | 0.821 | 0.863 | 0.919 |
| K | 0.623 | 0.649 | 0.682 | 0.655 | 0.665 | 0.686 | 0.736 | 0.617 | 0.673 | 0.694 | 0.736 | 0.647 |
| QD | 0.065 | 0.103 | 0.065 | 0.045 | 0.074 | 0.077 | 0.040 | 0.050 | 0.072 | 0.075 | 0.052 | 0.034 |
| AD | 0.113 | 0.109 | 0.110 | 0.051 | 0.072 | 0.103 | 0.097 | 0.041 | 0.071 | 0.104 | 0.087 | 0.047 |
图16
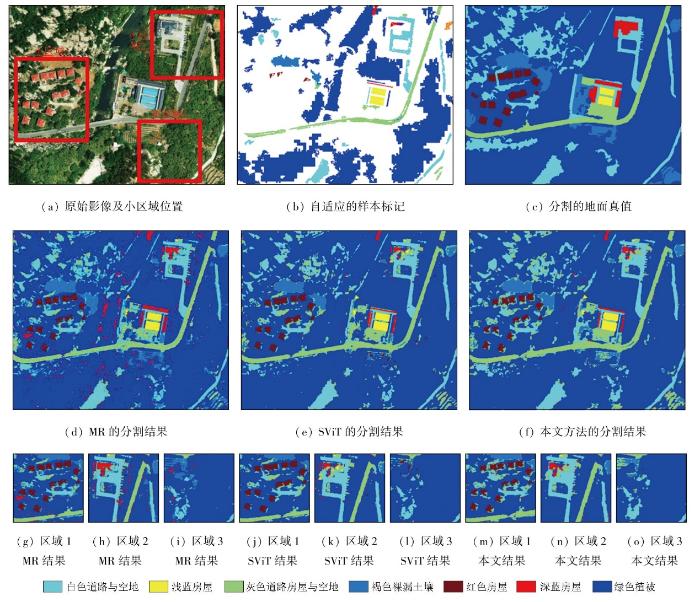
3.3 分析与讨论
为了更加直观地对比各种方法的分割性能,统计比较各方法在整张影像的OA,Kappa系数及OD,如图17所示。
图17
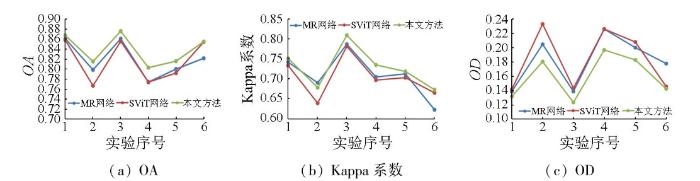
综上所述,MR方法作为经典的注意力结构网络,具有较好的地物辨识能力,能够对地面场景中各类地物进行较为准确的解读,但容易过拟合,导致杂乱地物细节突破泛化极限,产生噪声,严重影响分割精度。总体而言,这种方法可以对简单地面场景与去除影像进行较好的解读与分析。SViT方法是一种较为新颖流行的Transformer结构网络,其地物认知能力非常优秀,能够在多种复杂场景中正确辨识不同地物,但其复杂结构通常需要充足的训练样本,且自学习分析可能难以保证样本数量和质量,导致一些欠拟合的分割结果。在确保样本充足的前提下,该方法能较准确地解析各类地物。本文方法在实验中展现良好的地物认知能力,始终保持适度拟合以追求全局最优的分割结果。它具有较好的泛化性能,能够准确识别地物,并有效抑制干扰信息,实现最高精度和最低错误率的分割结果。
4 结论
本文提出的视觉双驱动自学习分割方法,通过参考视觉自底向上感知与自顶向下观察的双驱动认知机制,以视觉的颜色拮抗、NCRF、瑞利明暗判据及等级层次认知理论为指导,建立了自底向上的非监督聚类方法,自适应地划分超像素并完成聚类;并以聚类结果为样本参考,模拟视觉的注意机制,架构了自顶向下的神经网络,对地面场景实施智能、详尽的解读;最后,借助眼球微颤动的感知机制,参照超像素的单一类别组成与清晰边缘,对神经网络分割结果进行噪声滤除与边缘修复,最终得到准确、可靠的地面分割结果。
相比于成熟的Mask R-CNN网络和较新的ScalableViT网络,在真实高空间分辨率遥感影像的分割实验中,本文方法能够保持稳健、可靠的分割精度,表现出优秀的区域一致性与细节认知能力。并且经过实验对比可以发现,本文提出的双驱动自适应认知策略可以避开样本数据收集、样本可靠性探讨等繁复流程,结合噪声剔除、边缘恢复的功能,能够自动化、智能化地获取高精度的地面场景分割结果。
总体而言,面对高分辨率遥感影像的复杂地表场景,本文在参考视觉感知原理上提出的先粗后细、粗细互补的分割方法,采用非监督聚类和神经网络理论,面向复杂地面场景中大量信息混杂的实际分割难题,针对自学习过程中难以保障的样本数量与样本质量,借助特征发掘结构以保障其认知性能,配合轻量的自注意结构调整特征权重以满足少量含干扰信息样本的训练要求,能够突破样本数量与样本质量对实际地物分割工作的制约,自动智能地解析高分辨率遥感影像复杂地面场景,为多种实际工程提供地面类别参考,具有较强的应用潜力。
然而,值得注意的是,本文使用非监督聚类得到的样本效果虽然已经很好,但还有较大的提升空间,在后续的研究中将考虑结合光谱角制图(spectral angle mapping,SAM)方法和图割算法等提高分割精度,以得到更好的样本用于深度学习。
参考文献
Simplified object-based deep neural network for very high resolution remote sensing image classification
[J].
高空间分辨率遥感影像最优分割结果自动确定方法
[J].
DOI:10.11947/j.AGCS.2022.20210423

针对现有方法普遍存在不能充分顾及遥感影像多波段光谱信息,以及忽视遥感影像中地理要素的多尺度特性等问题,提出一种自动确定高空间分辨率遥感影像最优分割结果的非监督评价方法。该方法基于信息熵生成光谱信息离散度,利用光谱信息离散度构建能表达分割对象内部光谱均质性指标和分割对象与其相邻分割对象间光谱异质性指标。基于构建的光谱均质性和光谱异质性指标,采用“粗估计+精确定”的策略,逐步得到一个多级优化后的影像最优分割结果。本文在3个不同下垫面影像区域进行试验。结果表明,该方法能有效地实现自动确定高空间分辨率遥感影像最优分割结果,与现有方法相比,本文方法确定出的影像最优分割结果质量更高,与参考分割结果更加贴近。
The automatic determination method of the optimal segmentation result of high-spatial resolution remote sensing image
[J].
DOI:10.11947/j.AGCS.2022.20210423
The existing methods cannot fully take into account the multi-band spectral information of remote sensing images, and ignore the multi-scale characteristics of geographical elements in remote sensing images. This study proposed an unsupervised evaluation method for automatically determining the optimal segmentation result of high-spatial resolution remote sensing image. This method generates the spectral information divergence based on information entropy, and uses the spectral information divergence to construct the indexes that can express the intra-segment homogeneity and inter-segment heterogeneity. Based on the constructed homogeneity and heterogeneity indexes, the strategy of "rough estimation + fine determination" is adopted to gradually obtain an optimal image segmentation result after multi-level optimization. The proposed method was carried out in three different underlying surface image areas. Experimental results demonstrate that the method can effectively automatically determine the optimal segmentation results of high-spatial resolution remote sensing images. Compared with existing methods, the optimal image segmentation results determined by the method have higher quality and are closer to the reference segmentation results.
空间信息感知语义分割模型的高分辨率遥感影像道路提取
[J].
Road extraction method of high-resolution remote sensing image on the basis of the spatial information perception semantic segmentation model
[J].
Superpixel segmentation of high-resolution remote sensing image based on feature reconstruction method by salient edges
[J].
智能优化学习的高空间分辨率遥感影像语义分割
[J].
Intelligent optimization learning for semantic segmentation of high spatial resolution remote sensing images
[J].
基于层次化混合模型的高分辨率遥感影像分割方法研究
[J].DOI:10.11947/j.AGCS.2023.20210147
Hierarchical mixture model based high-resolution remote sensing image segmentation method
[J].DOI:10.11947/j.AGCS.2023.20210147
A coarse-to-fine weakly supervised learning method for green plastic cover segmentation using high-resolution remote sensing images
[J].
Semantic segmentation of very-high-resolution remote sensing images via deep multi-feature learning
[J].
Non-local feature search network for building and road segmentation of remote sensing image
[J].
Multiscale feature fusion network for automatic port segmentation from remote sensing images
[J].
基于语义分割的遥感影像建筑物自动提取方法
[J].
Automatic building extraction from remote sensing images based on semantic segmentation
[J].
结合分类和语义分割的遥感影像洪涝灾害检测方法
[J].
Remote sensing image flood disaster detection method based on classification and semantic segmentation
[J].
遥感地物分割的改进格子玻尔兹曼并行模型
[J].
Improved lattice Boltzmann parallel model for remote sensing object segmentation
[J].
基于直方图区域生长的遥感图像阈值分割算法
[J].
DOI:10.13474/j.cnki.11-2246.2021.0037
[本文引用: 1]
传统阈值分割算法从单阈值扩展到多阈值的过程中,时间复杂度会大幅度增加,并且由于遥感图像信息复杂,会导致分割效果降低。为了解决这些问题,本文提出了基于直方图区域生长的遥感图像阈值分割算法。在本文算法中,每一个灰度级均作为1个初始阈值,用256个阈值将直方图分割成256个原始小区域。为了减少阈值数目,本文将小区域合并成大区域,每一次合并都可视为一次区域的生长。在每次生长过程中,选取熵值H最小的区域作为直方图各区域中的主区域,并通过本文提出的预匹配策略将其与相邻区域合并。每一次区域生长后,阈值数目均减少1个。在整个过程中,最多只需要生长255次。算法的时间复杂度稳定在O(L)级别。最后通过单阈值和多阈值试验证明本文算法在运行时间和分割精度上均具有优势。
Threshold segmentation algorithm based on histogram region growing for remote sensing images
[J].
DOI:10.13474/j.cnki.11-2246.2021.0037
[本文引用: 1]
In the process of traditional thresholding algorithm from single-threshold to multi-threshold, the time complexity will increase greatly, and because of the complexity of remote sensing image information, the segmentation effect will be reduced. This paper creatively proposes the idea based on histogram region growing for remote sensing images. Each gray level is regarded as a threshold, so that the histogram is divided into 256 original small regions by the 256 thresholds. For reducing the number of thresholds, small regions are merged into large regions. Each merging can be regarded as the growth of a region. In each growth, the region with the smallest entropy <i>H</i> is selected as the main one in all regions of the histogram, and then it is merged with the adjacent region by the way of pre-judgment. After growing, the number of thresholds decreases. In the whole process, the growth times are only 255 at most, and the time complexity is stable at <i>O</i>(<i>L</i>). In this paper, single-threshold and multi-threshold experiments show that the algorithm has high accuracy in segmentation results, and has advantages in run time.
使用超像素编码的交互式影像语义分割方法
[J].
A method for interactive image semantic segmentation using superpixel encoding
[J].
基于小波域三重MRF分割算法的遥感图像分割分析
[J].
Analysis of remote sensing image segmentation based on wavelet domain triple MRF segmentation algorithm
[J].
Real-time segmentation of remote sensing images with a combination of clustering and Bayesian approaches
[J].
深度卷积语义分割网络在农田遥感影像分类中的对比研究——以河套灌区为例
[J].
A comparative study on semantic segmentation-orientated deep convolutional networks for remote sensing image-based farmland classification:A case study of the Hetao irrigation district
[J].
深度语义分割网络无人机遥感松材线虫病变色木识别
[J].
Identifying discolored trees inflected with pine wilt disease using DSSN-based UAV remote sensing
[J].
结合空洞卷积的FuseNet变体网络高分辨率遥感影像语义分割
[J].
Semantic segmentation of high-resolution remote sensing images based on improved FuseNet combined with atrous convolution
[J].
Wide and deep Fourier neural network for hyperspectral remote sensing image classification
[J].
基于注意力密集连接金字塔网络的新增建设用地变化检测
[J].
DOI:10.13474/j.cnki.11-2246.2022.0075
[本文引用: 1]
城市新增建设用地变化迅速频繁、场景复杂等因素导致变化检测结果出现欠分割或过分割等问题,基于此本文提出了一种融合注意力机制的密集连接金字塔网络用于城市新增建设用地变化检测。在编码阶段运用卷积注意力模型提升对变化信息的关注度,突出重要特征;采用密集连接空洞卷积空间金字塔池化模块实现多尺度特征的提取与融合,提高特征的利用率与传播效率;在解码阶段通过对提取的特征图进行上采样还原图像的空间尺度特征。试验结果表明,该方法有效改善了欠分割与过分割问题,变化检测效果更好。
Detection of new construction land change based on attention intensive connection pyramid network
[J].
DOI:10.13474/j.cnki.11-2246.2022.0075
[本文引用: 1]
To settle the problems of frequent and rapid changes of new urban construction sites and complex scenarios which lead to under-segmentation or over-segmentation of change detection results,this paper proposes a densely connected pyramid network with a fused attention mechanism for urban new construction site change detection.In the coding stage,a convolutional attention model is applied to enhance the attention to change information and highlight important features;then a densely connected null convolutional spatial pyramid pooling module is used to realize the extraction and fusion of multi-scale features and improves the feature utilization and propagation efficiency;in the decoding stage,the spatial scale features of the image are restored by upsampling the extracted feature maps.The experimental results show that the method in this paper effectively improves the under-segmentation and oversegmentation problems,and the change detection effect is better.
多模态特征融合的遥感图像语义分割网络
[J].
DOI:10.3778/j.issn.1002-8331.2207-0010
[本文引用: 2]
遥感图像语义分割是指通过对遥感图像上每个像素分配语义标签并标注,从而形成分割图的过程,在国土资源规划、智慧城市等领域有着广泛的应用。高分辨率遥感图像存在目标大小尺度不一与阴影遮挡等问题,单一模态下对相似地物和阴影遮挡地物分割较为困难。针对上述问题,提出了将IRRG(infrared、red、green)图像与DSM(digital surface model)图像融合的遥感图像语义分割网络MMFNet。网络采用编码器-解码器的结构,编码层采用双输入流的方式同时提取IRRG图像的光谱特征和DSM图像的高度特征。解码器使用残差解码块(residual decoding block,RDB)提取融合后的特征,并使用密集连接的方式加强特征的传播和复用。提出复合空洞空间金字塔(complex atrous spatial pyramid pooling,CASPP)模块提取跳跃连接的多尺度特征。在国际摄影测量与遥感学会(international society for photogrammetry and remote sensing,ISPRS)提供的Vaihingen和Potsdam数据集上进行了实验,MMFNet分别取得了90.44%和90.70%的全局精确度,相比较与DeepLabV3+、OCRNet等通用分割网络和CEVO、UFMG_4等同数据集专用分割网络具有更高的分割精确度。
Remote sensing image semantic segmentation network based on multimodal feature fusion
[J].
DOI:10.3778/j.issn.1002-8331.2207-0010
[本文引用: 2]
Semantic segmentation of remote sensing images refers to the process of forming a segmentation map by semantically labeling each pixel on a remote sensing image, and it has a wide range of applications in land and resource planning, smart city and other fields. High-resolution remote sensing images have problems such as different target size and scale and shadow occlusion, and it is difficult to segment similar objects and shadow occluded objects in a single mode. Aiming at the above problems, a remote sensing image semantic segmentation network MMFNet is proposed, which fuses IRRG(infrared, red, green) images with DSM(digital surface model) images. The network adopts an encoder-decoder structure, and the encoding layer uses a dual-input stream to extract the spectral features of IRRG images and the height features of DSM images simultaneously. The decoder uses the residual decoding block(RDB) to extract the fused features, and uses dense connections to enhance feature propagation and multiplexing. A complex atrous spatial pyramid pooling(CASPP) module is proposed to extract skip-connected multi-scale features. Experiments are conducted on the Vaihingen and Potsdam datasets provided by the international society for photogrammetry and remote sensing(ISPRS), and MMFNet achieves global accuracy of 90.44% and 90.70%, respectively, compared with DeepLabV3+, OCRNet Equal general segmentation network and CEVO, UFMG_4 equivalent dataset dedicates segmentation network have higher segmentation accuracy.
SPANet:Successive pooling attention network for semantic segmentation of remote sensing images
[J].
Multi-resolution classification network for high-resolution UAV remote sensing images
[J].
基于混合注意力机制和Deeplabv3+的遥感影像建筑物提取方法
[J].
A method for information extraction of buildings from remote sensing images based on hybrid attention mechanism and Deeplabv3+
[J].
融合混合注意力机制与多尺度特征增强的高分影像建筑物提取
[J].
Building extraction from high-resolution images using a hybrid attention mechanism combined with multi-scale feature enhancement
[J].
融合Transformer结构的高分辨率遥感影像变化检测网络
[J].
DOI:10.13474/j.cnki.11-2246.2022.0229
[本文引用: 1]
为解决遥感影像变化检测全局上下文信息捕获的问题,本文提出了基于孪生结构、跳跃连接结构及Transformer结构的TSU-Net。该模型编码器采用混合CNN-Transformers结构,借助自注意力机制捕获遥感影像的全局上下文信息,增强了模型对于像素级遥感影像变化检测任务的长距离上下文建模能力。该模型在LEVIR-CD数据集和CDD数据集进行测试,F1得分分别为90.73和93.14,优于各对比模型。
High-resolution remote sens-ing image change detection network with Transformer structure
[J].
Multimodal remote sensing image segmentation with intuition-inspired hypergraph modeling
[J].
图像语义分割方法在高分辨率遥感影像解译中的研究综述
[J].
DOI:10.3778/j.issn.1673-9418.2211015
[本文引用: 1]
快速获取遥感信息对图像语义分割方法在遥感影像解译应用发展具有重要的研究意义。随着卫星遥感影像记录的数据种类越来越多,特征信息越来越复杂,精确有效地提取遥感影像中的信息,成为图像语义分割方法解译遥感图像的关键。为了探索快速高效解译遥感影像的图像语义分割方法,对大量关于遥感影像的图像语义分割方法进行了总结。首先,综述了传统的图像语义分割方法,并将其划分为基于边缘检测的分割方法、基于区域的分割方法、基于阈值的分割方法和结合特定理论的分割方法,同时分析了传统图像语义分割方法的局限性。其次,详细阐述了基于深度学习的语义分割方法,并以每种方法的基本思想和技术特点作为划分标准,将其分为基于FCN的方法、基于编解码器的方法、基于空洞卷积的方法和基于注意力机制的方法四类,概述了每类方法中包含的子方法,并对比分析了这些方法的优缺点。然后,简单介绍了遥感图像语义分割常用数据集和性能评价指标,给出了经典网络模型在不同数据集上的实验结果,同时对不同模型的性能进行了评估。最后,分析了图像语义分割方法在高分辨率遥感图像解译上面临的挑战,并对未来的发展趋势进行了展望。
Research review of image semantic segmentation method in high-resolution remote sensing image interpretation
[J].
一种基于对抗学习的高分辨率遥感影像语义分割无监督域自适应方法
[J].
An adversarial learning-based unsupervised domain adaptation method for semantic segmentation of high-resolution remote sensing images
[J].
Bottom-up and top-down attention:Different processes and overlapping neural systems
[J].
Anterior dorsal attention network tau drives visual attention deficits in posterior cortical atrophy
[J].
Context-aware saliency detection
[J].We propose a new type of saliency—context-aware saliency—which aims at detecting the image regions that represent the scene. This definition differs from previous definitions whose goal is to either identify fixation points or detect the dominant object. In accordance with our saliency definition, we present a detection algorithm which is based on four principles observed in the psychological literature. The benefits of the proposed approach are evaluated in two applications where the context of the dominant objects is just as essential as the objects themselves. In image retargeting, we demonstrate that using our saliency prevents distortions in the important regions. In summarization, we show that our saliency helps to produce compact, appealing, and informative summaries.
傅里叶变换通道注意力网络的胆管癌高光谱图像分割
[J].
Fourier transform channel attention network for cholangiocarcinoma hyperspectral image segmentation
[J].
Self-attention feature fusion network for semantic segmentation
[J].
Visual pigments of single primate cones
[J].Single parafoveal cones from human and monkey retinas were examined in a recording microspectrophotometer. Three types of receptors with maximum absorption in the yellow, green, and violet regions of the spectruin were found. Thus the commonly held belief, for which there has previously been no direct and unequivocal evidence, that color vision is mediated by several kinds of receptors (possibly three), each containing photopigments absorbing in diflerent regions of the spectrum, is confirmed.
Role of the extensive area outside the x-cell receptive field in brightness information transmission
[J].Stimulus area-response functions of retinal ganglion cells show an extensive disinhibitory region (DIR) outside the classical receptive field (RF). The DIR has a wide summation area but low sensitivity. Spatial responses of the retinal ganglion cells have been simulated in a model which takes into account also the properties of the DIR. By scanning the RF and its DIR with a visual image and reconstructing the transferred image for single cells, it is shown that these properties of the DIR are beneficial in the transmission of area brightness and image grey scales.
Contour detection based on nonclassical receptive field inhibition
[J].
DOI:10.1109/TIP.2003.814250
PMID:18237948
[本文引用: 1]
We propose a biologically motivated method, called nonclassical receptive field (non-CRF) inhibition (more generally, surround inhibition or suppression), to improve contour detection in machine vision. Non-CRF inhibition is exhibited by 80% of the orientation-selective neurons in the primary visual cortex of monkeys and has been shown to influence human visual perception as well. Essentially, the response of an edge detector at a certain point is suppressed by the responses of the operator in the region outside the supported area. We combine classical edge detection with isotropic and anisotropic inhibition, both of which have counterparts in biology. We also use a biologically motivated method (the Gabor energy operator) for edge detection. The resulting operator responds strongly to isolated lines, edges, and contours, but exhibits weak or no response to edges that are part of texture. We use natural images with associated ground truth contour maps to assess the performance of the proposed operator for detecting contours while suppressing texture edges. Our method enhances contour detection in cluttered visual scenes more effectively than classical edge detectors used in machine vision (Canny edge detector). Therefore, the proposed operator is more useful for contour-based object recognition tasks, such as shape comparison, than traditional edge detectors, which do not distinguish between contour and texture edges. Traditional edge detection algorithms can, however, also be extended with surround suppression. This study contributes also to the understanding of inhibitory mechanisms in biology.
数字脉冲压缩技术在雷达中的应用
[J].
Application of digital pulse compression technique in Radar
[J].
Image quality assessment based on a degradation model
[J].
DOI:10.1109/83.841940
PMID:18255436
[本文引用: 1]
We model a degraded image as an original image that has been subject to linear frequency distortion and additive noise injection. Since the psychovisual effects of frequency distortion and noise injection are independent, we decouple these two sources of degradation and measure their effect on the human visual system. We develop a distortion measure (DM) of the effect of frequency distortion, and a noise quality measure (NQM) of the effect of additive noise. The NQM, which is based on Peli's (1990) contrast pyramid, takes into account the following: 1) variation in contrast sensitivity with distance, image dimensions, and spatial frequency; 2) variation in the local luminance mean; 3) contrast interaction between spatial frequencies; 4) contrast masking effects. For additive noise, we demonstrate that the nonlinear NQM is a better measure of visual quality than peak signal-to noise ratio (PSNR) and linear quality measures. We compute the DM in three steps. First, we find the frequency distortion in the degraded image. Second, we compute the deviation of this frequency distortion from an allpass response of unity gain (no distortion). Finally, we weight the deviation by a model of the frequency response of the human visual system and integrate over the visible frequencies. We demonstrate how to decouple distortion and additive noise degradation in a practical image restoration system.
Preliminary analytical method for unsupervised remote sensing image classification based on visual perception and a force field
[J].
Receptive fields of single neurones in the cat’s striate cortex
[J].
Receptive fields and functional architecture of monkey striate cortex
[J].
The period of susceptibility to the physiological effects of unilateral eye closure in kittens
[J].
Functional architecture of macaque monkey visual cortex
[J].
结合层次化搜索与视觉残差网络的光学舰船目标检测方法
[J].
Optical ship target detection method combining hierarchical search and visual residual network
[J].
视觉感受与Markov随机场相结合的高分辨率遥感影像分割法
[J].
DOI:10.11947/j.AGCS.2015.20130453
鉴于视觉感受对外界强大的感知与识别能力, 模拟视觉神经感知的工作机制, 并结合Markov随机场模型, 提出一种新的影像分割方法。首先, 分析视觉感知系统的工作机制, 将其特性归纳为等级层次性、学习能力、特征检测能力和稀疏编码特性, 继而利用小波变换、非监督聚类、特征分析和Laplace分布模拟视觉工作机制, 然后结合Markov随机场模型实现高分辨率遥感影像的分割。通过不同卫星的真实遥感影像进行相关试验。试验结果表明本文提出的方法在高分辨率遥感影像分割任务中有非常良好的表现。
A methodology of image segmentation for high resolution remote sensing image based on visual system and Markov random field
[J].
DOI:10.11947/j.AGCS.2015.20130453
In consideration of the visual system's tremendous ability to perceive and identify the information, a new image segmentation method is presented which simulates the mechanism of visual system for the high resolution remote sensing image segmentation with Markov random field model. Firstly, the characteristics of the visual system have been summarized as: hierarchy, learning ability, feature detection capability and sparse coding property. Secondly, the working mechanism of visual system is simulated by wavelet transform, unsupervised clustering algorithm, feature analysis and Laplace distribution. Then, the segmentation is achieved by the visual mechanism and the Markov random field. Different satellites remote sensing images are adopted as the experimental data, and the segmentation results demonstrate the proposed method have good performance in high resolution remote sensing images.
MsVRL:Self-supervised multiscale visual representation learning via cross-level consistency for medical image segmentation
[J].
Visual perception and saccadic eye movements
[J].
DOI:10.1016/j.conb.2011.05.012
PMID:21646014
[本文引用: 1]
We use saccades several times per second to move the fovea between points of interest and build an understanding of our visual environment. Recent behavioral experiments show evidence for the integration of pre- and postsaccadic information (even subliminally), the modulation of visual sensitivity, and the rapid reallocation of attention. The recent physiological literature has identified a characteristic modulation of neural responsiveness-perisaccadic reduction followed by a postsaccadic increase-that is found in many visual areas, but whose source is as yet unknown. This modulation seems optimal for reducing sensitivity during and boosting sensitivity between saccades, but no study has yet established a direct causal link between neural and behavioral changes.Copyright © 2011 Elsevier Ltd. All rights reserved.
A review of interactions between peripheral and foveal vision
[J].
DOI:10.1167/jov.20.12.2
PMID:33141171
[本文引用: 3]
Visual processing varies dramatically across the visual field. These differences start in the retina and continue all the way to the visual cortex. Despite these differences in processing, the perceptual experience of humans is remarkably stable and continuous across the visual field. Research in the last decade has shown that processing in peripheral and foveal vision is not independent, but is more directly connected than previously thought. We address three core questions on how peripheral and foveal vision interact, and review recent findings on potentially related phenomena that could provide answers to these questions. First, how is the processing of peripheral and foveal signals related during fixation? Peripheral signals seem to be processed in foveal retinotopic areas to facilitate peripheral object recognition, and foveal information seems to be extrapolated toward the periphery to generate a homogeneous representation of the environment. Second, how are peripheral and foveal signals re-calibrated? Transsaccadic changes in object features lead to a reduction in the discrepancy between peripheral and foveal appearance. Third, how is peripheral and foveal information stitched together across saccades? Peripheral and foveal signals are integrated across saccadic eye movements to average percepts and to reduce uncertainty. Together, these findings illustrate that peripheral and foveal processing are closely connected, mastering the compromise between a large peripheral visual field and high resolution at the fovea.
Miniature eye movements enhance fine spatial detail
[J].
Microsaccadic efficacy and contribution to foveal and peripheral vision
[J].
The impact of microsaccades on vision:Towards a unified theory of saccadic function
[J].
DOI:10.1038/nrn3405
PMID:23329159
[本文引用: 1]
When we attempt to fix our gaze, our eyes nevertheless produce so-called 'fixational eye movements', which include microsaccades, drift and tremor. Fixational eye movements thwart neural adaptation to unchanging stimuli and thus prevent and reverse perceptual fading during fixation. Over the past 10 years, microsaccade research has become one of the most active fields in visual, oculomotor and even cognitive neuroscience. The similarities and differences between microsaccades and saccades have been a most intriguing area of study, and the results of this research are leading us towards a unified theory of saccadic and microsaccadic function.
改进的CIELAB均匀颜色空间
[J].
Modified CIELAB uniform color space
[J].
微胶囊叶黄素吸收光谱及色调的影响因素研究
[J].
Studies on factors influence UV-absorbance and color value of microencapsulated lutein
[J].
基于CNN与SETR的特征融合滑坡体检测
[J].
A landslide detection method using CNN- and SETR-based feature fusion
[J].
基于改进U-Net网络的花岗伟晶岩信息提取方法
[J].
A granitic pegmatite information extraction method based on improved U-Net
[J].
一种边界引导与跨尺度信息交互网络用于遥感影像水体提取
[J].
A boundary guidance and cross-scale information interaction network for water body extraction from remote sensing images
[J].
基于多尺度卷积神经网络的遥感目标检测研究
[J].
Object detection in remote sensing images using multiscale convolutional neural networks
[J].
联合多流融合和多尺度学习的卷积神经网络遥感图像融合方法
[J].
Multi-stream architecture and multi-scale convolutional neural network for remote sensing image fusion
[J].
Enhanced shuffle attention network based on visual working mechanism for high-resolution remote sensing image classification
[J].
SegNeXt:Rethinking convolutional attention design for semantic segmentation
[J/OL].
Two-pathway anti-interference neural network based on the retinal perception mechanism for classification of remote sensing images from unmanned aerial vehicles
[J].
Enhanced watershed segmentation algorithm-based modified ResNet50 model for brain tumor detection
[J].
M2SNet:Multi-scale in multi-scale subtraction network for medical image segmentation
[J/OL].
Object detection using adaptive mask RCNN in optical remote sensing images
[J].
Globally convergent algorithms for estimating generalized gamma distributions in fast signal and image processing
[J].
基于高分辨率遥感影像和改进U-Net模型的滑坡提取——以汶川地区为例
[J].
Information extraction of landslides based on high-resolution remote sensing images and an improved U-Net model:A case study of Wenchuan,Sichuan
[J].
Death to Kappa:Birth of quantity disagreement and allocation disagreement for accuracy assessment
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}