

0 引言
传统的基于光谱特征的阈值法、分类器法和自动化法提取水体的研究颇为广泛[3]。例如徐涵秋[4]利用中红外波段替换近红外波段构成的改进的归一化差异水体指数(modified normalized difference water index, MNDWI),在不同水体类型的遥感影像进行了实验,对消除阴影具有较好的效果; 此外,还有自动化水体提取指数(automated water extraction index,AWEI)[5]、多波段组合水体指数(multi-band combination water index,MBCWI)[6]等。Rishikeshan等[7]提出了一个基于数学形态学的自动化算法,可从遥感图像中提取水体,该算法只需一个波段进行计算,相比传统方法在提取精度上表现更佳; 李红霞等[8]结合多源遥感数据,利用多尺度分割模型定量确定影像最优分割尺度,使总体分类精度提高。随着人工智能和计算机视觉技术的快速发展,利用深度学习进行高分辨率遥感影像水体提取已成为研究热点之一。如Shelhamer等[9]提出全卷积神经网络(fully convolutional networks,FCN),将全连接层替换为全局平均池化或装置卷积操作,从而适应于图像分割、语义分割等像素级别的任务; 针对细小水体提取目标信息少、易受背景噪声干扰的问题,孟月波等[10]提出一种基于U型网络的多层级特征增强聚合方法,提升了模型语义类别判定能力。然而,高分辨率遥感影像语义分割仍存在挑战和问题; 高质量的分割标注需要对每个像素进行精确分类,这种标注工作非常耗时且昂贵,尤其是在大规模数据集上。对于传统的语义分割模型,在处理多尺度信息、边界细节和计算效率方面都需要不断提升。
因此,针对上述问题,本文以深度学习高分辨率遥感影像中的水体语义分割为出发点,提出了一种改进的DeepLabV3plus模型作为整体语义分割架构,将其原有的Restnet101特征提取网络骨干替换成Efficientnet_B4以提高模型在高分辨率遥感图像中水体提取的效率和精度。Efficientnet_B4通过复合缩放策略(composite scaling strategy, CSS)在深度、宽度和分辨率之间实现更优的平衡,从而在保持高精度的同时显著减少计算资源的消耗[11],从而增强网络对重要特征的提取能力和水体细节部分的区分能力,减少特征损失,提高水体提取精度。
1 研究区概况及数据源
1.1 研究区概况
图1
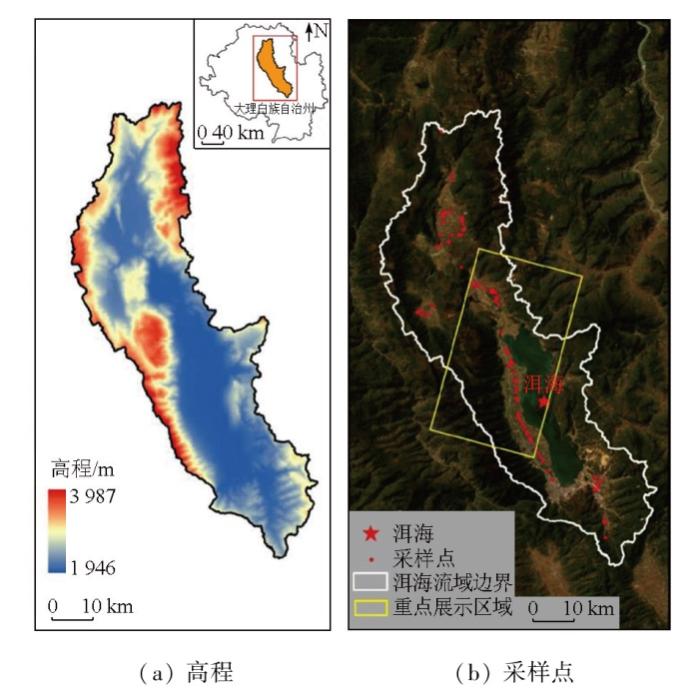
1.2 数据源
为了模型能够在识别与分割水体时捕捉到精细的地物细节,如窄小河流、湖泊边缘及小型水体等,本研究采用由长光卫星技术有限公司自主研发的吉林一号宽幅 01A (JL1KF01A)卫星和高分02系列(JL1GF02A/B/F)与03系列(JL1GF03B)卫星影像。影像的多光谱成像能力和高频次重访能够动态监测水体变化,为水资源管理和环境监测提供可靠的数据支撑。为覆盖整个研究区域,本文共获取了17景影像,影像数据及参数如表1所示。宽幅 01 系列卫星是同时期全球幅宽最大的亚米级光学遥感卫星,而高分 02 系列卫星是新型光学遥感卫星,单颗卫星上装载 2 台0.75 m分辨率相机。宽幅01A和高分02系列卫星全色波段(450~800 nm)空间分辨率为0.75 m,多光谱数据的空间分辨率为3 m,包括蓝B1(450~510 nm)、绿B2(510~580 nm)、红B3(630~690 nm)和近红外B4(770~895 nm)4个波段; 高分03系列卫星采用了高分辨率、超轻量化、低成本相机等创新技术,其中,高分03B单颗卫星上装载1台推扫相机,提供标准单景推扫影像产品; 全色波段(450~700 nm)空间分辨率为1 m,多光谱数据空间分辨率为4 m,包括包括蓝B1(450~510 nm)、绿B2(510~580 nm)、红B3(630~690 nm)和近红外B4(770-890 nm)4个波段。
表1 吉林一号卫星影像参数
Tab.1
| 卫星型号 | 传感器类 型与编号 | 光谱辐照度/(W·m-2·μm-1) | 幅宽/km | 数量/景 | ||||
|---|---|---|---|---|---|---|---|---|
| 全色 | 蓝 | 绿 | 红 | 近红外 | ||||
| JL1GF02A | PMS1 | 1 595.47 | 1 980.49 | 1 853.85 | 1 568.66 | 1 083.21 | 21.5×21.5 | 2 |
| PMS2 | 1 584.75 | 1 982.68 | 1 865.88 | 1 594.10 | 1 078.11 | 4 | ||
| JL1GF02B | PMS2 | 1 597.33 | 1 972.83 | 1 852.77 | 1 583.18 | 1 053.48 | 1 | |
| JL1GF02F | PMS2 | 1 532.65 | 1 980.17 | 1 866.51 | 1 590.60 | 1 081.68 | 1 | |
| JL1GF03B02 | PMS | 1 729.96 | 1 973.55 | 1 868.33 | 1 533.91 | 1 073.28 | 17.5×17.5 | 1 |
| JL1GF03B04 | PMS | 1 733.37 | 1 974.94 | 1 866.99 | 1 540.12 | 1 076.20 | 1 | |
| JL1KF01A | PMS03 | 1 553.42 | 1 971.64 | 1 862.81 | 1 558.79 | 1 063.32 | 23×23 | 1 |
| PMS05 | 1 554.59 | 1 980.95 | 1 863.34 | 1 551.80 | 1 059.28 | 2 | ||
| PMS06 | 1 544.92 | 1 977.95 | 1 862.62 | 1 553.75 | 1 072.92 | 4 | ||
1.3 影像预处理
图2

为了确保水体训练样本的高精度,本研究于2023年10月30日在洱海流域进行了实地调研。调研期间,结合影像设备采集区域照片,并通过手持GPS标注记录各个水体区域,通过参考影像与实地数据的对比,基于ArcGIS10.8制作了洱海流域的深度学习语义分割标签(即训练样本的标注)。解译时,将细小的沟渠、湖泊、坑塘、水库均标注为水体,湖岸边缘与芦苇覆盖区域均为非水体,标签类型均为面要素。标注完成的矢量标签需要借助feature to raster工具转为栅格标签,特别需要注意的是,需要将环境设置里的处理范围设置为与标签一致的影像范围。为提高模型的泛化能力,将原始图像和标签进行裁剪,生成尺寸为256像素×256像素的图像,通过对裁剪后的图像进行随机翻转、旋转、缩放、平移、亮度调整等[15],增加数据集的多样性,从而防止模型过拟合。
2 研究方法
图3

2.1 改进的DeepLabV3plus模型
2.1.1 编码优化与损失函数联合
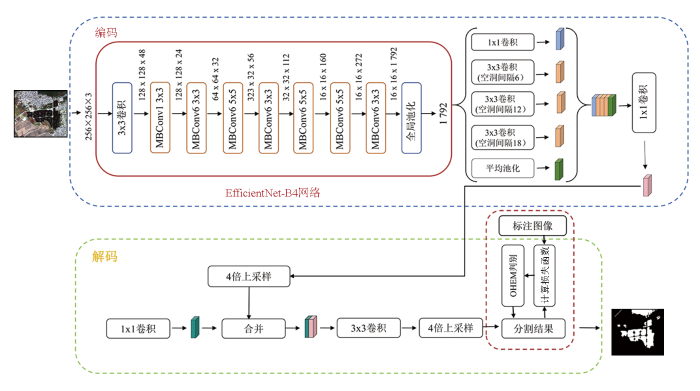
为了让模型能够充分学习到高分辨率图像中多尺度的特征,提高水体提取精度,本文对模型进行了以下改进: ①针对 DeepLabV3plus算法的骨干特征提取网络参数量大、提取特征能力存在局限性的问题,本文将提取特征网络的编译结构ResNet101替换成EfficientNet-B4作为特征提取骨干网络,通过CSS来提高模型的效率和精度,从多个方面减少了梯度爆炸或梯度消失的风险[11]; ②在损失函数部分引入了二元交叉熵损失(binary cross-entropy loss,BCE loss)[20]和 Dice loss[21]的联合损失函数,BCE loss能够对像素级别的分类进行精细优化,而Dice loss能够专注于水体区域的整体重叠情况,弥补了BCE loss在不平衡数据中的不足[22]。
改进的DeepLabV3plus模型结构如图4所示,其中编码部分的红色框为模型改进部分。编码器由骨干网络和空洞空间金字塔池化模块(atrous spatial pyramid pooling,ASPP)组成。在编码器部分,使用预训练的 EfficientNet-B4 作为骨干网络对输入影像进行多层次的特征提取,输入影像为256×256×3,经过初始3×3卷积层和多个移动端逆残差模块(mobile inverted bottleneck convolution,MBConv)逐步进行特征提取与压缩后,其通道数不断增加,最后得到1 792维的特征向量。这些特征向量通过不同尺度的空洞卷积进行多尺度特征提取,生成具有丰富上下文信息的深层次特征图。其中 MBConv最早由 Sandler等[23]提出,是 EfficientNet 中广泛采用的轻量化卷积模块,其采用“先升维-深度可分离卷积-再降维”的倒残差结构,并结合了残差连接以提升梯度传递能力。 图中所示的 MBConv1 与 MBConv6 的主要差异在于扩展因子不同: MBConv1 表示扩展因子为 1,即输入与中间特征维度相同; MBConv6 表示扩展因子为 6,即中间特征维度为输入的 6 倍,从而增强非线性表达能力。在解码器部分,模型首先对编码器输出的特征图进行 4 倍上采样,然后通过特征融合操作将这些深层次特征图与编码器的低级特征图进行拼接。拼接后的特征图通过 3×3卷积进一步处理,以减少通道数并强化关键信息。在完成卷积操作后,再次进行 4 倍上采样,使特征图恢复至与输入影像相同的分辨率。最后,通过预测结果与真实标签的比较计算损失函数,并引入在线难样本挖掘(online hard example mining,OHEM)机制,对高损失像素进行筛选,仅保留难分类样本参与梯度反传,从而实现模型参数的迭代更新。最终,模型输出与原始影像大小一致的分割结果。
图4
2.1.2 实验环境与训练参数
本文的深度学习模型训练均在图形工作站上运行,主机采用Windows 11家庭中文版23H2,型号为Precision 3660,处理器为Intel Core i9-12900K。本文所使用的软件开发平台为Visual Studio Code,环境配置使用Python 3.9.16和PyTorch 1.13,并配合GCC 7.5.0和CUDA 11.3进行 GPU 加速和编译。本研究使用了Adam优化器,其初始学习率设定为0.001,输入模型样本数量(batch size)设置为8,迭代次数(epoch)为100,输入图像大小为256像素×256像素。为了提高模型的收敛性并避免陷入局部最优解,采用学习率调度策略。具体而言,使用了StepLR调度器,每8个epoch后,将学习率乘以0.1进行衰减。
3 结果与分析
3.1 结果对比
图5
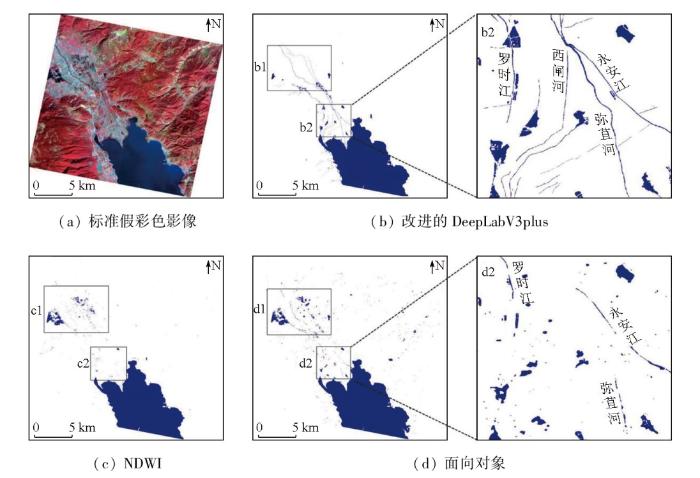
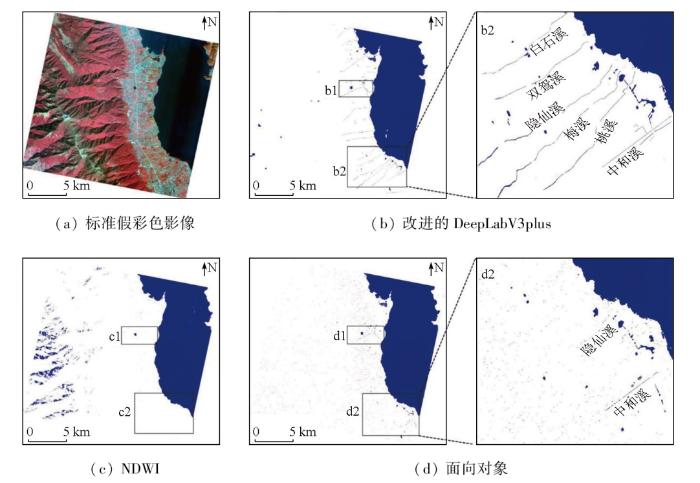
图6
由图5可知,3种方法均能准确提取出洱海北部大面积水体,目视效果较好。各方法的差异主要体现在噪声、细长水体及山体阴影等细节处。在b2的局部放大图中可以看出,改进的DeepLabV3plus模型对细小河流的分割能力较强,且能提取出主要入湖河流(弥苴河、罗时江、西闸河和永安江)的水系形状,提取的水系呈现“爪”型,最大程度地保持了河流的连续性。NDWI方法在细小水系的提取上表现欠佳,湖泊边缘提取不够清晰,在重点对比区域c2中也几乎识别不到细小河流的水体像元,且存在许多噪声,导致漏提率较高。面向对象方法虽然改善了NDWI方法对细小水体提取的不足,但还是出现了水体的“断流”现象,同时伴随着出现了山体阴影像元错分的现象,虽然能很好地区分水体与非水体,但还是存在误提现象,如d2的局部放大图中,面向对象方法只提取到了断续的“三江”水系,且提取的水体中含有山体阴影。
由图6中b2的局部放大图可知,改进的DeepLabV3plus模型提取的水系主干和支流较为清晰,尤其是主要溪流和洱海的水体轮廓得到了较好识别,对于细小水体和支流可能因为分辨率或模型限制存在断裂现象,但总体来说,水系提取的效果较好。NDWI方法明显将洱海西侧苍山的部分山体阴影识别成水体,尤其在洱海西部的重点对比区域(c1与c2)中细小溪流和部分小型水体未能准确提取出来,存在较明显的漏提现象。面向对象法在很大程度上减少了与山体阴影混淆的情况,但在提取主要溪流时效果不理想,如d2的局部放大图中,只识别到隐仙溪与中和溪的零散水体像元,无法保证水体的空间连贯性,也无法反映出水体的整体结构。其次,面向对象方法虽然在抑制部分噪声方面有所改进,但仍然受到湿地、植被阴影的影响,存在许多非水体像元的误识别。
3.2 精度对比
表2 水体提取精度对比
Tab.2
| 指标 | 改进的DeepLabV3plus | NDWI | 面向对象 |
|---|---|---|---|
| 精确率 | 98.87 | 94.32 | 94.80 |
| 召回率 | 99.30 | 93.73 | 98.90 |
| F1分数 | 99.08 | 96.62 | 96.80 |
| 误提率 | 1.13 | 5.68 | 5.20 |
| 漏提率 | 0.70 | 6.27 | 1.10 |
由表2可知,本文提出的改进的DeepLabV3plus模型的精确率、召回率和F1分数分别为98.87%,99.30%和99.08%,与其他2种方法对比,本文的性能均为最优。误提率结果中,本文方法的误提率为1.13%,相比之下,NDWI方法的误提率5.68%,这也造成了较高的漏提率,导致大量真实水体的遗漏。在漏提率方面,改进的DeepLabV3plus模型的漏提率最低,为0.7%,面向对象方法略低,为1.1%,NDWI方法最高,达6.27%; 本文方法的漏提率比其他2种方法分别降低了5.57百分点和0.4百分点。
综上所述,本研究所改进的DeepLabV3plus模型方法相较于其他2种传统方法具有最优的水体提取效果,可以有效抑制建筑物阴影的同时提取相对完整的水体,尤其是对细小水体的识别效果较好,能够实现洱海流域水体信息的快速获取和动态监测。
3.3 细节对比
为了进一步突出本文方法的可行性,选取大面积水体(区域A)、复杂地形水系交汇处(区域B)和包含建筑物阴影的城市区(区域D)的水域进行细节提取分析,由于洱海流域的平原区水田分布较多,因此有必要对水田(区域C)也进行提取分析。水体提取细节如表3所示。




由表3可以看出,对于区域A,本文方法提取的水体结果更光滑,而其他2种方法容易受到路面和建筑物的反射影响,均出现了不同程度的误提,其结果中包含大量错提建筑物和道路,面向对象法稍微改善了这种情况,能准确识别到大部分难以提取的复杂类型水体,但仍然受到少数建筑物的影响导致错提; 在区域B中,对于NDWI和面向对象法,河流交汇处的细小水体周围环境复杂,水体区域光谱信息由于岸边植被和建筑物的遮挡发生变化,导致均出现不同程度的漏提,而改进的DeepLabV3plus模型对细长水体的提取相对完整,没有错提和漏提现象,说明具有较强的小目标分割能力; 在区域C中,水田排列形状规则,呈密集分布状态,但NDWI方法提取的水田边缘缺失; 区域D中,在复杂的城市背景下,虽然改进的DeepLabV3plus模型受少量建筑物影响有一部分误提,但总体提取结果最准确,与其他2种方法相比,能更好地保证河流的连续性。
总体来说,NDWI对大面积水体和城市区水体提取相对完整,但对于复杂地形的细小水体提取效果不佳,容易与其他地物混淆,体现为水体区域零散的“点”; 面向对象法和改进的DeepLabV3plus模型总体来说提取效果优于NDWI,但面向对象法对于建筑物阴影抑制效果较差; 仅有改进DeepLabV3plus将不同区域的水体较为完整地提取出来。
3.4 消融实验
为了验证本文模型中CSS和联合损失函数改进的合理性,使用DeepLabV3plus网络作为基准网络,逐步添加联合损失函数和EfficientNet-B4结构,消融实验结果见表4。
表4 消融实验结果对比
Tab.4
| 网络模型 | F1分数 | mIoU |
|---|---|---|
| 基准网络 | 99.32 | 94.64 |
| DeepLabV3plus+loss | 99.40 | 95.26 |
| DeepLabV3plus+loss+EfficientNet-B4 | 99.71 | 97.71 |
由表4可知,在添加联合损失函数后,F1分数为99.40%,mIoU为95.26%,相较于基准模型,F1分数和mIoU分别提升了0.08和0.62百分点,证明联合损失函数有助于模型之间取得更好的平衡,为模型训练提供更多维度的信息反馈,能够有效增强模型的分割精度。DeepLabV3plus+loss+EfficientNet-B4为本文提出的改进模型结构,F1分数为99.71%,mIoU为97.71%,相较于基准模型,F1分数和mIoU分别提升了0.39和3.07百分点,证明 EfficientNet-B4通过CSS在模型深度、宽度和分辨率之间进行了优化权衡,丰富了模型对多尺度复杂语义分割信息的提取能力。总体而言,本文提出的模型结构通过改进的模块均能相互促进,在图像分割任务中具有更好的性能。
4 讨论
4.1 标签质量对模型性能的影响
本文在进行水体提取前,通过参照实地调研数据和高分辨率遥感影像制作水体语义分割训练样本,由人工目视解译后对图像像素逐一标记,人工和时间成本较高[26],且人工标注的水体样本具有主观性,从而使得标签数据存在偏差。在深度学习语义分割模型中,标签数据的质量直接影响模型的性能,洱海流域内存在细小水系、狭窄溪流和植被覆盖的水体区域,人工标注水体边界具有较大的难度。尤其是当水体较窄或被部分遮挡时,人眼难以分辨水体与非水体,容易造成漏标或错标,进而降低提取的精度。在今后的研究中考虑改进标注流程或引入自动化标注辅助工具,可以在一定程度上提高标注数据的质量。
4.2 水体提取过程出现水流断续现象
尽管改进的DeepLabV3plus模型在大多数区域内表现优异,但在极细小水系(苍山十八溪)的提取中仍存在部分水流断续现象。这一现象可能与河流地形、太阳高度角、光谱混合效应等因素密切相关。Li等[27]提出的几何-光学模型显示,树冠形状和相互阴影效应会显著改变地物的反射特性,使得河道边缘的光谱特征发生变化,增加模型识别的难度。李文涛等[28]的研究表明,太阳高度角变化会显著影响影像中阴影的长度和分布,较低的太阳高度角会导致长阴影覆盖建筑物和地表特征,降低水体提取的精度。此外,Small[29]提出光谱混合像元问题在高分辨率影像中尤为明显,特别是在狭窄的溪流区域,像元可能同时包含水体和周围地物的混合光谱特征,增加了模型的分类难度。再加上苍山十八溪的溪流宽度极窄,在高分辨率影像中仅占少数像元,这进一步限制了模型对这些细小水体的精细提取能力,导致部分断续现象的出现。
4.3 光谱信息融合
吉林一号遥感影像在空间分辨率上存在一定的优势,但由于影像波段数量较少,缺乏对水体识别敏感的短波红外波段,存在光谱分辨率不足的现象[30],限制了模型在复杂环境中对水体的识别能力。特别是在洱海流域等季节性水体明显的区域,雨季水体浑浊度增加,易与湿地或植被混淆,而旱季水体缩减导致边界模糊和光谱混合现象,增加了提取难度。未来研究可以引入多源遥感数据,如合成孔径雷达(synthetic aperture Radar,SAR)影像或其他多光谱数据,利用SAR对水体的穿透能力减少光谱混淆,并结合光谱重建和数据增强技术,丰富影像的光谱信息。此外,多时相分析与时间序列模型能有效捕捉水体动态变化特征,提升季节性水体提取的精度和稳定性,从而增强吉林一号影像在复杂水体环境中的应用效果。
5 结论
针对目前高分辨率遥感影像提取水体信息存在的细节特征提取能力较弱、学习不充分问题,本文提出了一种改进的DeepLabV3plus水体提取模型用于对洱海流域水体进行精细提取,并与传统的NDWI方法和面向对象方法进行对比,主要结论如下:
1)从洱海流域北部和西部的提取结果可以看出,改进的DeepLabV3plus模型在洱海主体水体和主要河流的识别上表现优异,能够较为完整地提取出永安江、弥苴河等主要河流,并显示出较好的连贯性。相比之下,NDWI方法虽然能够识别出明显的洱海水体,但在细小河流和复杂地形区域表现不佳,漏提现象较为明显; 面向对象法则在细小水系的提取上存在较大的断续性,仅能识别出零散的水体像元,整体提取效果不如改进的DeepLabV3plus模型。
2)改进的DeepLabV3plus模型、NDWI和面向对象法精确度和召回率分别为98.87%,94.32%,94.80%及99.30%,93.73%,98.90%,其中,本文方法的精确率和召回率都高于其他2种方法,且漏提率仅为0.7%,相较于其他2种方法分别降低了5.57百分点和0.4百分点,说明改进的DeepLabV3plus模型可以保证水体的相对完整。
3)综合4个不同类型区域的提取结果可知,改进的DeepLabV3plus模型在各类复杂环境中提取水体出色,尤其在抑制建筑物阴影、捕捉细小水体和区分周围复杂地物的能力上,相较于传统的NDWI和面向对象法有显著提升,展现了模型较好的鲁棒性。
综上所述,高分辨率遥感影像与深度学习的应用大大地提高了水体学习提取的精度与效率。尤其是在处理复杂地形和多样化地物形态时,也为洱海流域水体信息监测提供了新的思路。未来的研究可以进一步探索与其他深度学习模型相结合,提升遥感影像信息提取的精度和稳定性。
参考文献
A cross-domain object-semantic matching framework for imbalanced high spatial resolution imagery water-body extraction
[J].
融合边缘特征与语义信息的人工坑塘精准提取方法
[J].
DOI:10.12082/dqxxkx.2022.210489
[本文引用: 1]

针对高空间分辨率遥感影像目标提取中定位精度低、边缘粗糙等问题,提出一种融合目标边缘特征与语义信息的人工坑塘提取网络模型。方法首先利用改进的U-Net语义分割网络模块来提取遥感影像中丰富的目标语义信息,然后拓展上述语义分割网络构建边缘提取子网络来获取遥感影像的多尺度边缘特征,最后借助于编码-解码子网络融合边缘特征与语义信息,实现遥感影像目标的精准提取。将该方法运用到雷州半岛复杂背景条件下人工坑塘提取实验中,实验结果中本文提出的方法在F分数以及边界F分数等评价指标上表现最优,达到97.61%与83.01%,验证了融合高层语义信息结合低层的边缘特征在提升遥感目标提取精确度上的有效性。
Accurate extraction of artificial pit-pond integrating edge features and semantic information
[J].
基于多源国产高分辨率遥感影像的山区河流信息自动提取
[J].
DOI:10.16511/j.cnki.qhdxxb.2022.22.043
[本文引用: 1]
高分辨率遥感影像地理信息是研究山区河流的重要数据源。针对山区地物类型复杂、河道狭窄等原因导致的河流表面信息提取完整性差、河宽难以自动提取且精度低等问题,结合随机森林(RF)和神经网络(ANN)算法,建立了河流表面信息提取方法RF-ANN。该方法支持并行运算且能降低热红外数据尺度辅助去噪,实现了对河流表面信息的像素级提取。利用Laplace算子及边缘算法改进了RivWidthCloud河宽提取算法,使其不需要人工设定判别阈值,提升了算法的普适性。以国产GF-1、ZY-3卫星影像为主要数据源,选取黄河一级支流皇甫川为研究区域。利用所建立的方法提取了皇甫川流域2级及以上河流的河流表面信息和平滩河宽。结果表明: RF-ANN的河流表面信息提取精度达到94.7%。提取河宽的平均误差为1.07 m (约0.5个像素),提取的最小有效河宽为6.1 m (约3个像素),提取河宽与检验河宽的R2和RMSE分别为0.93和1.52,宽度小于10 m极细河流、10~30 m细小河流、30~90 m较细河流及90 m以上较宽河流的河宽提取误差分别为18.5%、8.8%、2.0%和0.7%。该研究结果为山区河流几何形态特征提取及河流地貌空间分布研究提供了方法和数据支持。
Automatic extraction of mountain river information from multiple Chinese high-resolution remote sensing satellite images
[J].
利用改进的归一化差异水体指数(MNDWI)提取水体信息的研究
[J].
A study on information extraction of water body with the modified normalized difference water index (MNDWI)
[J].
Automated water extraction index:A new technique for surface water mapping using Landsat imagery
[J].
一种基于Landsat8的多波段组合水体指数模型
[J].
DOI:10.13474/j.cnki.11-2246.2022.0135
[本文引用: 1]
本文通过分析水体在Landsat 8数据中可见光波段和近红外波段的波谱差异,将Landsat 8数据中可见光波段作为一组,近红外波段和中红外波段作为另一组,构建了多波段组合水体指数(MBCWI)模型。基于Landsat 8数据在合肥、安康和康定地区共3景数据5种不同场景进行水体提取试验。结果表明,该模型不仅能够抑制云层、阴影、裸土、亮色地物和建筑物等对水体提取的影响,还能较好地提取出含有大量蓝藻的水体,且阈值稳定,Kappa系数优于0.968 5,总体精度高达99.69%,总体误差小于8.92%。相较于其他水体指数而言,提取精度显著提高。
A multi-band combination water index model based on Landsat8
[J].
An automated mathematical morphology driven algorithm for water body extraction from remotely sensed images
[J].
结合多源遥感数据和面向对象的旱区湿地信息提取
[J].
Combining multi-source remote sensing data and object-oriented wetland information extraction in arid areas
[J].DOI:10.1021/es204272v URL [本文引用: 1]
Fully convolutional networks for semantic segmentation
[J].
DOI:10.1109/TPAMI.2016.2572683
PMID:27244717
[本文引用: 1]
Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixels-to-pixels, improve on the previous best result in semantic segmentation. Our key insight is to build "fully convolutional" networks that take input of arbitrary size and produce correspondingly-sized output with efficient inference and learning. We define and detail the space of fully convolutional networks, explain their application to spatially dense prediction tasks, and draw connections to prior models. We adapt contemporary classification networks (AlexNet, the VGG net, and GoogLeNet) into fully convolutional networks and transfer their learned representations by fine-tuning to the segmentation task. We then define a skip architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations. Our fully convolutional networks achieve improved segmentation of PASCAL VOC (30% relative improvement to 67.2% mean IU on 2012), NYUDv2, SIFT Flow, and PASCAL-Context, while inference takes one tenth of a second for a typical image.
多层级特征增强聚合的遥感图像细小水体提取
[J].
Multi-level feature enhancement aggregation for fine water extraction in remote sensing images
[J].
EfficientNet:Rethinking model scaling for convolutional neural networks
[C]//
洱海流域环境保护和综合管理浅析
[J].
Analysis on environmental protection and comprehensive management in Erhai Lake Basin
[J].
基于FSO算法的洱海流域土地利用分类适用性研究
[J].
Applicability of land use classification in Erhai Basin based on FSO algorithm
[J].
基于高分一号卫星影像的水体信息提取方法初探
[J].
Preliminary exploration on water body information extraction method based on Gaofen No.1 satellite image
[J].
A survey on image data augmentation for deep learning
[J].DOI:10.1186/s40537-019-0197-0 [本文引用: 1]
基于NEWI模型的典型岩溶区普者黑流域水体信息提取
[J].针对岩溶区水体破碎植被与水体重叠的特点提出一种新型混合水体指数对该地区水资源管理与评估有着重要作用。以2017年普者黑的Landsat8 OLI影像数据为基础数据,选择不同流域水系类型,构建新型混合水体指数NEWI,与归一化水体指数(Normalized Difference Water Index,NDWI)和改进的归一化水体指数(Modified Normalized Difference Water Index,MNDWI)进行对比,分析各指数的水体信息提取的准确性和完整性。结果表明:新型水体指数NEWI的提取效果优于NDWI和MNDWI,特别是含有坑塘和水体植被的破碎湖泊区域,NEWI计算水体与阴影的区分度25.3%,大于NDWI(17.9%)和MNDWI(15.6%);水体与非水体的总体识别精度为88.83%,Kappa系数0.76,也大于NDWI(87.10%,Kappa系数0.74)和MNDWI(81.93%,Kappa系数0.64)。利用NEWI对遥感影像进行水体增强的方法,不仅能够很好地提取出开阔水域的水体信息,边缘清晰可靠;对于破碎水域,NEWI水体提取精度最高,并且相比基于复杂数学理论的分类提取过程,操作相对简单,易于推广,能够较好地提高岩溶破碎区的水系提取和水域实时监测的精度。
Puzhehei River Basin water body information extraction based on the typical karst area of NEWI model
[J].
一种多水体类型地区的坑塘水面精准提取方法
[J].
A method for accurately extracting the water surface of pits and ponds in areas with multiple water body types
[J].
基于Sentinel-2A影像的复合轮作种植结构提取
[J].
Extraction of compound rotation planting structure based on Sentinel-2A image
[J].
光谱模型结合面向对象法的山区水体提取
[J].
Water extraction in mountainous area based on spectral model and object-oriented method
[J].
知识图谱嵌入模型中的损失函数研究综述
[J].
DOI:10.11896/jsjkx.211200175
[本文引用: 1]
表达方式丰富直观的知识图谱得到了大量学者的关注。在知识图谱嵌入方面已积累了大量研究,其成果在电商、金融、医药、交通、智能问答等领域发挥了重要的作用。其中,损失函数在知识图谱嵌入模型的训练阶段起到了非常关键的作用。在现有知识图谱嵌入研究的基础上,根据基础损失函数把模型中使用的损失函数梳理为合页损失、逻辑回归损失、交叉熵损失、对数似然损失、负采样损失和均方误差损失六大类,并逐类详细分析了损失函数的原型公式、物理含义和其在知识图谱嵌入模型中的扩展、演变及应用。在此基础上,对静态和动态两大知识图谱场景中各种损失函数的使用情况、效率和收敛性进行了综合分析评价;根据分析结果,结合知识图谱的发展应用趋势和损失函数现状,对损失函数的未来研究方向进行了探讨。
Comprehensive survey of loss functions in knowledge graph embedding models
[J].
DOI:10.11896/jsjkx.211200175
[本文引用: 1]
Due to its rich and intuitive expressivity,knowledge graph has received much attention of many scholars. A lot of works have been accumulated in knowledge graph embedding. The results of the works have played an important role in some fields, such as e-commerce, finance,medicine, transportation and intelligent Q & A. In the knowledge graph embedding model, the loss function plays a key role in its training stage. Based on the existing research of knowledge graph embeddings, this paper classifies the loss functions used in the model into six categories: hinge loss, logistic loss, cross entropy loss, log likelihood loss, negative sampling loss and mean square error loss. The prototype formula and physical meaning of loss functions and their expansion, evolution and application in knowledge graph embedding models are analyzed in detail one by one.Based on the above,the usage, efficiency and convergence of various loss functions in the static and dynamic knowledge graph scenarios are comprehensively analyzed and evaluated. According to the analysis results, combined with the development and application trend of knowledge graph and the current situation of loss functions,the future works of loss functions are discussed.
基于改进Deeplabv3+模型的遥感影像地物语义分割方法研究
[J].
The research on semantic segmentation of remote sensing image about ground objects based on improved Deeplabv3+ model
[J].
UNet++:A nest-ed U-Net architecture for medical image segmentation
[J/OL].
MobileNetV2:Inverted residuals and linear bottlenecks
[C]//
基于Sentinel-1A SAR的洞庭湖汛期水体面积动态变化监测研究
[J].
DOI:10.11873/j.issn.1004-0323.2024.3.0741
[本文引用: 1]
洞庭湖水体面积动态变化监测对防洪、维系生态系统的稳定及生物多样性具有重要意义。以经典Unet网络模型和创新性HRNet网络模型为代表的深度学习技术已成为遥感图像信息获取的高效途径,实验以Sentinel-1A SAR影像为主要数据源,定性、定量地分析了Sentinel-1双极化水体指数法(Sentinel-1 Dual-Polarized Water Index,SDWI)、面向对象分类法、UNet网络模型和HRNet网络模型4种方法的水体提取效果,并基于最佳水体提取方法对洞庭湖2016~2021年汛期(4~10月)水体面积进行时空变化特征分析。结果表明:①HRNet和Unet网络模型较传统方法具有更优的水体提取效果,其中,HRNet网络模型在抑噪、抗阴影等方面表现更佳,F1分数、误判率和平均交并比分别为0.961 6、0.007 8和0.958 6;②汛期洞庭湖水体面积在月际变化上呈现出“涨—丰—退”的变化特征,湖面从4~5月份开始扩张,6~8月份水域面积维持在较高水平,此后由于来水减少,9~10月的水体面积逐步减小。研究期间所监测到的最大水体面积为2020年7月30日的2 263.90 km2;③洞庭湖汛期的水体淹没频率从湖体中心和干流向外逐渐降低,不同湖区的淹没频率分布格局不同,东洞庭湖 “湖心高四周低”,南洞庭湖和西洞庭湖“南高北低”。综上所述,Sentinel-1A SAR影像与深度学习技术的结合应用可以实现洞庭湖水体信息高效获取与水面面积高频监测,为高动态湖泊水域监测提供了一种新思路。
Dynamic monitoring of water area in Dongting Lake during flood season based on sentinel-1A SAR data
[J].
面向不同环境背景的Landsat影像水体提取方法适用性研究
[J].
DOI:10.12082/dqxxkx.2021.200312
[本文引用: 1]
快速、准确地从卫星影像中提取水体信息一直是遥感应用的热点问题,在水资源管理、水环境监测和灾害应急管理等领域极具应用价值。虽然目前已有多种针对Landsat系列影像的水体提取方法,但由于地理位置、地形和水体形态等环境背景因素的影响,导致同种方法在不同的环境背景中呈现出不同的提取效果。本文针对人为影响严重、影像明暗对比强烈的城区(北京怀柔县城周边)以及地形起伏明显、水体细小的非城区(北京密云水库周边) 2种典型背景环境,选择波段设置略有差异的Landsat 5(2009年)和Landsat 8(2019年)卫星影像,对比了常用的指数法(NDWI和MNDWI)和分类法(最大似然法和支持向量机)在水体信息提取方面的优势和不足。结果表明:在城区背景中,SVM的准确性最高(总体精度>97%);在非城区背景中,MNDWI与SVM的精度相当(总体精度>95%),前者更适用于水体的快速提取,而后者提取的山间细碎河流更完整,且在Landsat 8中应用的效果更好。该研究为不同环境背景下水体提取方法的选择提供了参考。
Application of water extraction methods from Landsat imagery for different environmental background
[J].
基于深度学习的遥感图像水体提取综述
[J].
A review of water body extraction from remote sensing images based on deep learning
[J].
Geometric-optical bidirectional reflectance modeling of the discrete crown vegetation canopy:Effect of crown shape and mutual shadowing
[J].DOI:10.1109/36.134078 URL [本文引用: 1]
亚米级宽幅卫星边缘视场影像的DSM生成研究
[J].
Production of DSM based on image located at edge of view of sub meter WFV satellite
[J].
The Landsat ETM+ spectral mixing space
[J].DOI:10.1016/j.rse.2004.06.007 URL [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}