

0 引言
高分辨率遥感影像在现代智慧城市中扮演着重要角色,其应用广泛且多样化,其中遥感建筑物提取是其最为重要的应用之一[1]。该技术旨在从城市环境的影像中准确提取出建筑物的轮廓,这一过程可以被视为像素级分类问题,同时也是计算机视觉领域中的语义分割任务。遥感图像的语义分割具有重要意义,广泛应用于海陆分割[2]、土地覆盖分类等遥感领域研究。随着遥感传感器的更新迭代,地面采样距离逐渐增加,人们可获取更多高质量、高分辨率的遥感影像。然而,影像分辨率的提升也带来了更多土地覆盖信息和复杂的环境背景,增加了在城市区域进行建筑物语义分割任务的难度。然而,传统方法在很大程度上依赖于手工设计的特征,难以应对大规模数据集,也无法满足当今实际应用的需求。
近年来,卷积神经网络(convolutional neural network,CNN)在语义分割任务中取得了突破性进展,其在特征提取方面的卓越能力使得模型能够更好地理解图像中的语义信息,从而提高了分割的准确性和效率。Shelhamer等[3]通过将CNN转换为全卷积网络(fully convolutional network,FCN),利用多尺度特征融合方案,显著提高了像素级分类任务的性能。受Ronneberger等[4]的启发,研究者在分割任务中广泛使用编码器-解码器架构,如SegNet[5],DeconNet[6]和U-Net[4]等均因在分割任务中的有效性而被广泛采用。此类模型设计用于捕获图像的语义信息,并将其精确映射回原始图像大小,以实现精确的分割。为了进一步提高分割的准确性和效率,DeepLab系列[7-
鉴于小型建筑物的提取效果不佳和大型建筑物出现空洞等问题,本文提出了一种密集嵌套网络(densely nested network,DN-Net),旨在全方位地捕捉特征信息。DN-Net首先采用改进残差卷积对建筑物进行初步提取,实现了对其轮廓的粗略识别; 接着,通过引入坐标注意力模块(coordinate attention module,CAM),精确定位遥感图像中的建筑物位置; 此外,利用级联卷积模块(cascade convolutional module,CCM)提取丰富的特征信息,使得轮廓更加清晰与准确; 为了进一步降低误检率,DN-Net在4个内部编码器及一个解码器分支的输出中加入了损失函数,以实施深度监督训练,这不仅有助于捕获粗粒度的语义信息和细粒度的空间信息,还可以通过模型修剪来提升遥感建筑物分割的准确度。
1 DN-Net网络
DN-Net的结构如图1所示,图中XEn和XDe分别为编码器和解码器; XIn为融合的特征图。以遥感图像作为输入,选取密集嵌套结构为主干结构。密集嵌套结构内部是由多个注意力块层组成的,每个注意力块层中依次执行粗略特征提取(改进残差卷积)、遥感建筑精准定位(CAM模块)和细化遥感建筑物的边界(CCM模块),最终生成检测结果。模型训练采用监督学习方法,以提高遥感建筑物提取的精确度。
图1
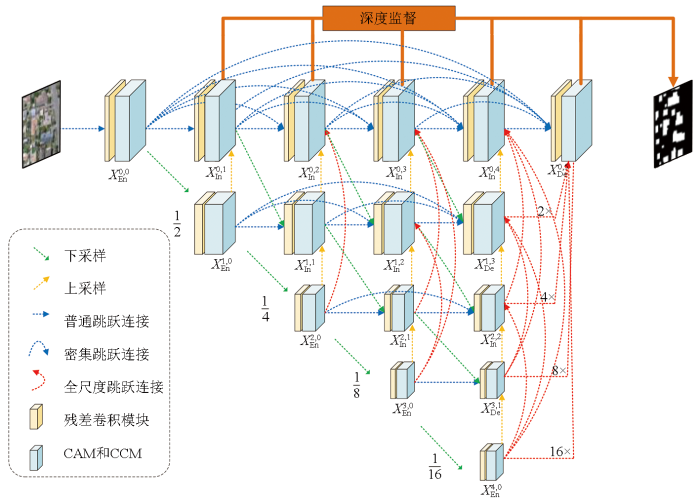
DN-Net融合了密集跳跃连接和全尺度跳跃连接,旨在充分捕获不同尺度的语义信息,以生成更精确的分割结果。跳跃连接在提升深度神经网络性能方面起至关重要作用。密集跳跃连接使得同一层级的特征能够相互融合,而全尺度跳跃连接则通过连接浅层特征与深层特征,不仅保留了底层特征,还避免了随着网络深度增加导致的性能衰减。遥感建筑物背景比较复杂,凭借层级式模块堆叠策略实现多尺度特征提取,增强对遥感建筑物信息的捕捉能力。该网络架构包含堆叠的注意力块层,每个块层级致力于实现更为精细的特征提取。堆叠的注意力块层包含了改进残差卷积模块、CAM模块以及CCM模块等关键组件。改进残差卷积自适应地细化特征,提高模型的表征能力; CAM则精确捕捉遥感建筑物的位置特征,增强模型对位置信息的敏感性; CCM通过其结构设计,增强了模型捕捉多尺度特征的能力。
模型的编码器节点位于第一列,标记为
堆叠的注意力块层形成独立特征提取子网络。以注意力块层
式中:
图2
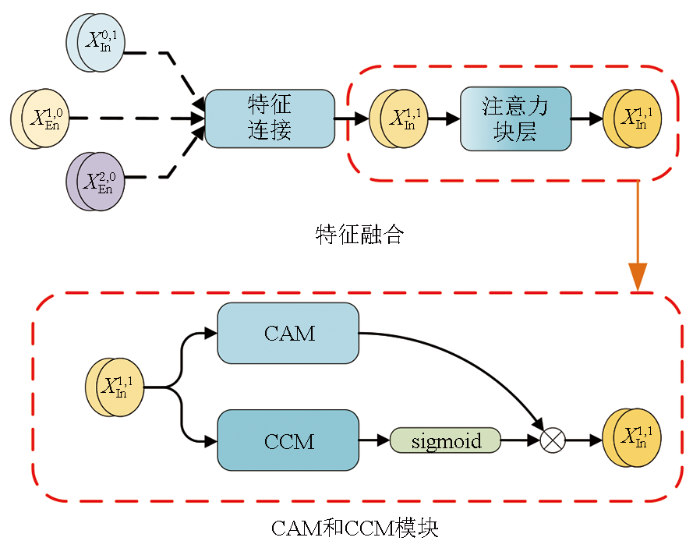
注意力块层的交互如图2所示。在多层特征融合后通过CAM和CCM进行特征增强,来自注意力块层X的特征映射由CAM和CCM处理,处理过程可以总结为:
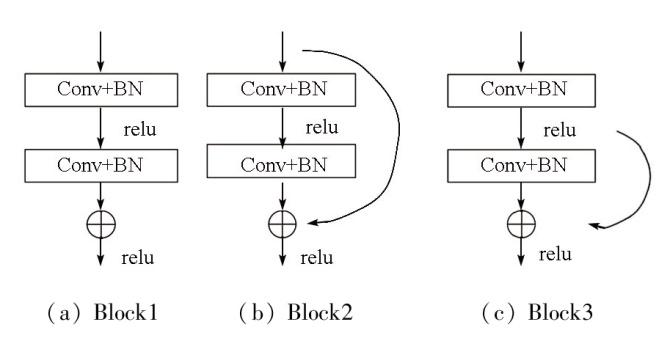
1.1 改进残差卷积块
本文提出了一种改进的残差卷积块。该模块首先将输入特征映射x(H×W×Cin)通过3×3卷积(Conv)、归一化(BN)和激活函数(relu)转换为中间特征映射U1(x),并将其通道数转换为Cout,从而实现局部特征提取。这一过程由3×3卷积层完成。随后,中间特征映射U1(x)作为输入,以学习和提取到上下文信息U2(U1(x))。
图3
1.2 CAM模块
在遥感图像处理领域,准确地捕捉建筑物的位置、形状和大小至关重要。为了更有效地整合这些空间信息,引入了CAM,模块结构如图4所示。
图4
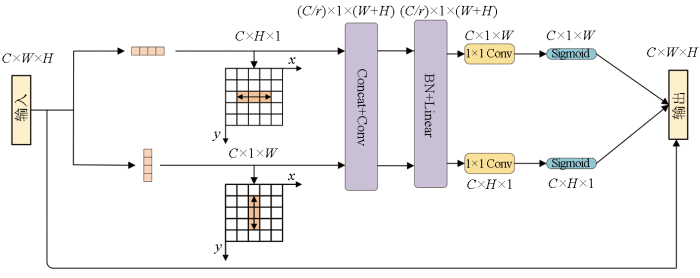
该模块可有效学习到建筑物位置信息,从而提高遥感建筑物位置准确性。具体而言,传统的全局池化操作在处理位置信息时往往会损失大量空间细节,摒弃全局平均池化。基于此将全局池化分解为2个一维池化操作,公式为:
这种分解不仅有助于更好地捕获通道间的信息,而且显著提高了模型对位置和方向的感知能力。CAM能够保留更多的空间信息,从而支持更精准的远程空间交互。CAM显著增强了模型对遥感图像中建筑物特定位置的识别能力,有效地支持了复杂地理环境中建筑物的精确定位。
完成特征图的变换后进行特征拼接操作。在实施特征融合过程中,采用了拼接(Concat)操作将不同卷积层产生的特征图进行组合。将特征图通过1×1卷积(1×1Conv)进行降维,得到降维后的特征图Z∈R(C/r)×(H+W)×1,接下来,特征图被送入分割操作中,分割为Zh∈R(C/r)×H×1和Zw∈R(C/r)×W×1,每组均通过1×1卷积进一步进行特征转换。转换后的特征图再通过sigmoid函数激活,以得到在特定维度上重要性的调制特征Sh∈RC×H×1和Sw∈RC×1×W。通过精细的特征重构与整合方法,有效地捕获并强化对关键信息的表征,从而提高特征的表达能力,增强对建筑物等关键信息的提取。最后,CAM模块的输出公式可写为:
1.3 CCM模块
CCM模块如图5所示,旨在提升对于复杂遥感图像特征提取的能力。CCM由多个卷积层堆叠而成,其中每个卷积层都配有ReLU激活函数,以增强非线性表达能力。卷积核的大小设定为1×1,3×3,5×5和7×7,模型能够有效捕获到不同尺度的特征信息,并且在进行特征融合时能够保持较高适应性。CCM的核心是利用不同大小的卷积核捕获到不同范围的上下文信息。CCM不仅提升了网络对于细粒度特征的捕获能力,而且确保了模型在进行特征融合时不会损失空间信息。
图5
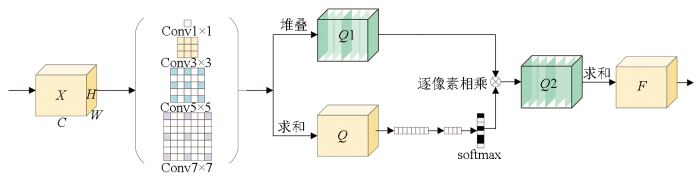
具体操作如下,特征映射X∈RC×H×W,采用了一种多分支卷积提取。首先通过卷积核大小分别为1,3,5和7,进行特征提取,随后依次经过批量归一化和relu函数处理。
通过堆叠(stack)操作,可以融合成一个新的高维特征图像Q1。此张量维度顺序为[k,B,C,H,W],其中k为卷积核数量,B为批大小,C为通道数,H和W分别为特征图高度和宽度。堆叠维度排列有利于模型在后续处理中,依靠注意力权重加强对重要特征的表征。
为了综合不同尺度下的特征信息,引入一个高效的特征融合层。融合层通过对各尺度的特征图进行逐元素的叠加求和(sum)操作,生成了一个综合了广泛的上下文信息与精细的局部特征的特征图Q。
在降维层,对融合特征图Q进行降维操作。具体而言,将Q中的每一个通道进行平均值池化操作,得到降维后的特征,可以看作是对每个通道的特征进行全局平均池化,以减少数据的维度; 接下来,选用全连接层FC对降维后的特征进行处理,将其映射到一个新的特征空间Z,即
通过全连接运算有助于进一步提取特征信息。凭借不同的全连接层FCs学习不同方面的特征,从而在更复杂的特征空间中进行权重优化。每个全连接层产生的权重向量w,它们的维度与输入通道数C相同。进而将权重w转换为与输出尺度大小相匹配的形状,组合成一个张量Aw。不同尺度的特征与相应的注意力权重相乘求和,最终得到融合特征F。公式为:
F=sum(Aw·Q1) 。
2 实验与分析
2.1 WHU数据集
在 WHU 数据集上对 DN-Net 进行了实验,该数据集由季顺平等[21] 创建,覆盖了新西兰基督城约 450 km2的区域。数据集由空间分辨率为 0.3 m的航空图像组成,包含了22 000多个独立的建筑物。为了构建整个数据集,原始数据被裁剪成8 189张512像素×512像素的非重叠切片,取4 736张图像为训练集,1 036张图像为验证集,2,416张图像为测试集。为便于训练,将影像进一步裁剪为256像素×256像素的小块,以适应网络输入的需求。经过裁剪后,数据集生成了18 944张训练影像、4 144 张验证影像和9 664张测试影像,用于评估 DN-Net 的性能。
2.2 评价指标及损失函数
为了评价建筑物提取精度,选取了交并比(intersection over union, IoU)、精确率(Precision,P)和召回率(Recall,R)和F1这4个指标作为评价标准。
式中: TP为正确检测出的建筑物数量; TN为正确检测出的非建筑物像数量; FP为错误检测出的建筑物数量; FN为错误检测出的非建筑物数量。
在评价指标中,R是模型提取的建筑面积占现有建筑总面积的比例,R值越高,模型就越能更好地捕捉实际存在的建筑; P是正确预测建筑的百分比,P越高,表示预测建筑面积与实际建筑面积越匹配; F1综合了R和P之间的权衡,提供了这2个指标的调和平均值,较高的F1表示该模型在提取尽可能多的实际建筑面积的同时能够正确地对建筑物进行分类,在R和P之间取得了很好的平衡。
Lee等[22]提出了深度监督策略,旨在解决深度神经网络中的梯度消失和缓慢收敛问题。本文将深度监督引入到DN-Net结构中,对于模型的5个分支输出,计算它们的平均损失,以获得更全面的训练。具体实施如下: 第一层特征映射
式中: σ(
2.3 结果分析
首先将WHU数据集导入到基于图形处理器(graphics processing unit,GPU)的Pytorch平台,参照已有环境配置,并结合实际条件搭建深度学习实验环境,实验平台采用英特尔i9-1390HK,搭载Nvidia GeForce RTX 4070显卡。在软件环境方面,本文采用Ubuntu20.04操作系统,使用的编程语言为Python3.8,选择以Pytorch2.01框架作为深度学习框架,使用CUDA11.7版本的GPU为运算平台。
通过多次试验,综合考虑网络的计算效率、结果精度以及硬件3个方面,设置batchsize为6,所有在验证集上的实验epoch均为35,在测试集实验epoch均为300。DN-Net采用Sigmoid-IoU loss作为损失函数,通过损失函数将损失降到最小,得到最优的模型。
2.3.1 定参分析
表1 不同训练优化方法结果
Tab.1
| 训练优化法 | IoU | F1 | P | R |
|---|---|---|---|---|
| Adam | 86.92 | 93.00 | 92.19 | 93.82 |
| Adagrad | 88.02 | 93.63 | 93.58 | 93.53 |
| SGD | 89.20 | 94.29 | 94.31 | 94.27 |
2)深度监督学习方法选取。对深度监督学习方法训练进行了探讨,如图6所示。具体操作将损失函数添加到分支,然后进行1×1或3×3卷积运算,产生损失Li,i=1,2,3,4,5。增加多分支深度监督学习能够促进DN-Net学习更为丰富的特征表示。表2中所示的实验结果印证了设定,在采用深度监督方式一(deep supervision method 1,DS1)后,模型在准确率、F1分数、精确率以及召回率等关键指标上均优于仅使用深度监督
图6
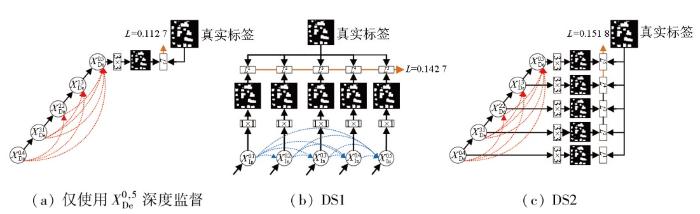
表2 深度监督对DN-Net分割性能的影响
Tab.2
| 深度监督 | IoU | F1 | P | R |
|---|---|---|---|---|
| 88.79 | 94.04 | 92.91 | 95.23 | |
| DS2 | 88.10 | 93.67 | 92.45 | 94.92 |
| DS1 | 89.20 | 94.29 | 94.31 | 94.27 |
2.3.2 消融实验
1)模块的有效性。本文进行了消融实验以量化DN-Net中CAM和CCM对于增强模型分割性能的具体贡献。表3中展示了在不同模块组合配置下,DN-Net在WHU数据集上的分割任务表现,涵盖了IoU、精确率、F1分数和召回率等关键性能指标。实验结果表明,单独添加CAM或CCM都能提升DN-Net的性能; 而将CAM和CCM模块结合使用时,分割效果进一步得到显著提升,从而验证了CAM和CCM模块在结构上的互补性。
表3 CAM和CCM对DN-Net分割性能的影响
Tab.3
| 参数 | DN-Net | Block3 | CAM | CCM | IoU | F1 | P |
|---|---|---|---|---|---|---|---|
| 表现 | √ | √ | — | — | 88.82 | 94.08 | 93.46 |
| √ | √ | √ | — | 89.02 | 94.19 | 93.99 | |
| √ | √ | — | √ | 89.09 | 94.23 | 94.11 | |
| √ | √ | √ | √ | 89.20 | 94.29 | 94.31 |
图7则提供了特征响应的可视化分析,呈现了CAM模块和CCM模块在抑制背景噪声及其对目标区域的强化方面的作用。特征响应图展示了在经过CAM和CCM处理后的特征映射、模块如何聚焦图像中重要的空间信息。综合定量和定性的结果,得出结论,DN-Net通过融入CAM和CCM,显著提升了对遥感图像中建筑物边缘和形状的精确提取。
图7
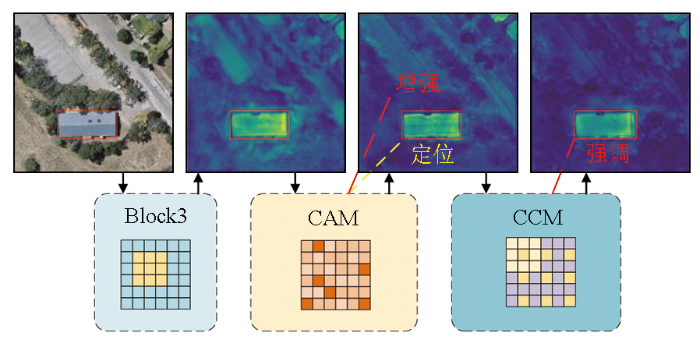
表4展现了DN-Net网络在结合不同模块后的可视化结果。CAM通过横向和纵向的特征信息融合,显著优化了目标的上下文建模,未使用CAM的DN-Net基线在预测时容易产生大量误差,而引入CAM可进行准确的定位; CCM则通过对特征的增强和细化,大大避免空洞现象。加入CAM和CCM后的分割结果显示,在处理小型、密集和大型建筑物上生成的分割图像更加贴合标签,凸显了这2种模块在提高模型性能中的重要作用。
表4 可视化对比
Tab.4
| 类型 | 小型建筑物 | 密集建筑物 | 大型建筑物 | |||
|---|---|---|---|---|---|---|
| 示例1 | 示例2 | 示例1 | 示例2 | 示例1 | 示例2 | |
| 原图 |  | |||||
| 标签 |  | |||||
| DN-Net +Block3 |  | |||||
| DN-Net +Block3+CAM |  | |||||
| DN-Net +Block3+CCM |  | |||||
| DN-Net+Block3+CAM+CCM |  | |||||
表5 改进残差卷积结果
Tab.5
| 卷积块 | IoU | F1 | P | R |
|---|---|---|---|---|
| Block1 | 88.69 | 94.00 | 93.79 | 94.22 |
| Block2 | 88.78 | 94.10 | 93.72 | 94.60 |
| Block3 | 88.82 | 94.08 | 93.46 | 94.70 |
3)级联卷积注意力的有效性。为深入探讨CCM模块中,不同大小卷积核组合对DN-Net的具体影响,进行实验见表6,其中,[1],[1,3,5]以及[1,3,5,7]分别代表了采取1×1,3×3,5×5和7×7卷积核的不同模型配置。值得关注的是,在包含最大卷积核尺寸7×7的配置[1,3,5,7]中,模块展现出了更为优越的性能表现。这表明了较大卷积核的引入,在捕捉更加丰富的特征方面发挥了显著作用。
表6 CCM模块消融实验
Tab.6
| 卷积核 | IoU | F1 | P | R |
|---|---|---|---|---|
| [1,3] | 88.68 | 94.00 | 93.34 | 94.68 |
| [1,3,5] | 88.82 | 94.08 | 93.46 | 94.70 |
| [1,3,5,7] | 89.09 | 94.23 | 94.11 | 94.35 |
2.3.3 对比实验
为了验证本文网络的有效性,将DN-Net与典型模型和先进方法在WHU数据集上进行比较,包括SegNet[4],UNet[6],ENet[10],ERFNet[11],UNet++[13],UNet3+[14],T-LinKNet[16],Res_ASPP_UNNet++[18]。表7为在验证集和验证集上的评估结果。本文网络在WHU数据集在IoU,F1,精确率和召回率上都有很大的提高。在WHU验证集中,相比于2023年提出的Res_ASPP_UNNet++ 在IoU,F1,精确率和召回率上分别提高了0.85,0.48,0.31和0.09百分点; 测试集上比2023年提出的 Res_ASPP_UNNet++ 在IoU,F1,精确率和召回率上分别提高了0.94,0.52,0.47和0.59百分点。同时,相对于其他网络模型,DN-Net在IoU,F1,精确率和召回率上也有显著提升。
表7 不同网络在WHU数据集上的分割精度对比
Tab.7
| 网络 | 验证集 | 测试集 | ||||||
|---|---|---|---|---|---|---|---|---|
| IoU | F1 | P | R | IoU | F1 | P | R | |
| SegNet | 87.39 | 92.27 | 93.15 | 93.39 | 88.07 | 93.66 | 93.69 | 93.62 |
| UNet | 87.22 | 93.17 | 92.48 | 93.88 | 88.24 | 93.75 | 94.43 | 93.09 |
| ENet | 85.79 | 92.35 | 91.62 | 93.09 | 86.62 | 92.83 | 93.51 | 92.17 |
| UNet++ | 88.18 | 93.72 | 93.51 | 93.92 | 88.65 | 93.99 | 93.43 | 94.55 |
| ERFNet | 86.42 | 92.71 | 91.10 | 94.38 | 87.17 | 93.14 | 92.31 | 93.99 |
| UNet3+ | 88.58 | 93.95 | 93.02 | 93.70 | 89.19 | 94.29 | 93.25 | 95.15 |
| T-LinKNet | 88.70 | 94.01 | 92.87 | 95.21 | 89.33 | 94.37 | 94.39 | 94.36 |
| Res_ASPP_UNNet++ | 88.35 | 93.81 | 94.00 | 94.18 | 88.91 | 94.13 | 93.65 | 94.61 |
| DN-Net | 89.20 | 94.29 | 94.31 | 94.27 | 89.85 | 94.65 | 94.12 | 95.20 |
表8 不同模型在WHU验证集上的可视化
Tab.8
| 类型 | 原图 | SegNet | UNet | ENet | UNet++ | ERFNet | UNet3+ | T-LinK Net | Res_ UNet++ | DN-Net | 标签 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 小型建筑物 |  | ||||||||||
| 密集建筑物 |  | ||||||||||
| 大型建筑物 |  | ||||||||||
表9 不同模型在WHU测试集上的可视化
Tab.9
| 类型 | 原图 | SegNet | UNet | ENet | UNet++ | ERFNet | UNet3+ | T-LinK Net | Res_ UNet++ | DN-Net | 标签 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 小型建筑物 |  | ||||||||||
| 密集建筑物 |  | ||||||||||
| 大型建筑物 |  | ||||||||||
2.3.4 网络复杂度分析
在本节中,在WHU建筑物数据集上将参数量、每秒浮点运算次数(floating point operations per second,FLOPs)、IOU和F1与其他最先进的方法进行比较。定量结果如表10所示。根据结果,所提出的DN-Net具有较大的参数量和FLOPs,这表明本文方法具有较高的复杂性。与其他8个模型相比,DN-Net增加的参数量和FLOPs有助于提高分割精度。
表10 在WHU数据集不同网络复杂性分析
Tab.10
| Model | FLOPs/109 | 参数量/106 | IoU/% | F1% |
|---|---|---|---|---|
| SegNet | 0.5 | 0.4 | 88.07 | 93.66 |
| UNet | 31.1 | 13.4 | 88.24 | 93.75 |
| ENet | 0.5 | 0.4 | 86.62 | 92.83 |
| UNet++ | 17.5 | 24.7 | 88.65 | 93.99 |
| ERFNet | 3.4 | 2.1 | 87.17 | 93.14 |
| UNet3+ | 90.5 | 7.6 | 89.19 | 94.29 |
| T-LinKNet | 153.2 | 200.0 | 89.33 | 94.37 |
| Res_ASPP_UNNet++ | 8.8 | 4.5 | 88.91 | 94.13 |
| DN-Net | 43.2 | 12.9 | 89.85 | 94.65 |
3 结论
为了提高遥感建筑物提取精度,提出了一种新的网络结构DN-Net。该模型分别通过密集跳跃和全尺度连接,在5个分支中引入深度监督,将同一层级的特征进行融合,以最大限度地融合高层次语义和低层次的细节信息,实现准确的遥感建筑物位置的感知和分割。首先,利用DN-Net中子网络和改进的残差卷积模块实现了建筑物的粗略轮廓提取; 其次,引入坐标注意力模块(CAM)精确定位建筑物位置,有效减少了误检现象; 最后,采用级联卷积模块(CCM),通过不同尺寸的卷积核提取细节,解决了空洞问题,进一步提升了建筑物提取的精度。
实验结果表明所提模型在每个评价指标均优于所对比的模型,本文方法在WHU验证集上取得了89.20%的IoU和94.29%的F1分数,而在测试集上分别达到了89.85%和94.65%,表现出良好的建筑物提取性能。DN-Net在分割中背景噪声和错误率较低,能更准确地提取建筑物边缘,减少漏检、误检和粘连现象,同时有效避免空洞问题。证实本方法可以使建筑物提取更加完整和精细,有效提升对不同大小建筑物的分割精度。
尽管所提出的DN-Net在所进行的分析中被认为是有效的,但也存在局限性。目前,DN-Net在城市和山区场景的建筑物分割中表现出良好的提取性能,但尚未在其他任务(如道路分割)中进行测试。未来可进一步研究DN-Net在不同遥感图像任务中的应用及性能优化。
参考文献
Double branch parallel network for segmentation of buildings and waters in remote sensing images
[J].
DOI:10.3390/rs15061536
URL
[本文引用: 1]

The segmentation algorithm for buildings and waters is extremely important for the efficient planning and utilization of land resources. The temporal and space range of remote sensing pictures is growing. Due to the generic convolutional neural network’s (CNN) insensitivity to the spatial position information in remote sensing images, certain location and edge details can be lost, leading to a low level of segmentation accuracy. This research suggests a double-branch parallel interactive network to address these issues, fully using the interactivity of global information in a Swin Transformer network, and integrating CNN to capture deeper information. Then, by building a cross-scale multi-level fusion module, the model can combine features gathered using convolutional neural networks with features derived using Swin Transformer, successfully extracting the semantic information of spatial information and context. Then, an up-sampling module for multi-scale fusion is suggested. It employs the output high-level feature information to direct the low-level feature information and recover the high-resolution pixel-level features. According to experimental results, the proposed networks maximizes the benefits of the two models and increases the precision of semantic segmentation of buildings and waters.
DBENet:Dual-branch ensemble network for sea-land segmentation of remote-sensing images
[J].
Fully convolutional networks for semantic segmentation
[J].
DOI:10.1109/TPAMI.2016.2572683
PMID:27244717
[本文引用: 1]
Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixels-to-pixels, improve on the previous best result in semantic segmentation. Our key insight is to build "fully convolutional" networks that take input of arbitrary size and produce correspondingly-sized output with efficient inference and learning. We define and detail the space of fully convolutional networks, explain their application to spatially dense prediction tasks, and draw connections to prior models. We adapt contemporary classification networks (AlexNet, the VGG net, and GoogLeNet) into fully convolutional networks and transfer their learned representations by fine-tuning to the segmentation task. We then define a skip architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations. Our fully convolutional networks achieve improved segmentation of PASCAL VOC (30% relative improvement to 67.2% mean IU on 2012), NYUDv2, SIFT Flow, and PASCAL-Context, while inference takes one tenth of a second for a typical image.
SegNet:A deep convolutional encoder-decoder architecture for image segmentation
[J].
DOI:10.1109/TPAMI.2016.2644615
PMID:28060704
[本文引用: 1]
We present a novel and practical deep fully convolutional neural network architecture for semantic pixel-wise segmentation termed SegNet. This core trainable segmentation engine consists of an encoder network, a corresponding decoder network followed by a pixel-wise classification layer. The architecture of the encoder network is topologically identical to the 13 convolutional layers in the VGG16 network [1]. The role of the decoder network is to map the low resolution encoder feature maps to full input resolution feature maps for pixel-wise classification. The novelty of SegNet lies is in the manner in which the decoder upsamples its lower resolution input feature map(s). Specifically, the decoder uses pooling indices computed in the max-pooling step of the corresponding encoder to perform non-linear upsampling. This eliminates the need for learning to upsample. The upsampled maps are sparse and are then convolved with trainable filters to produce dense feature maps. We compare our proposed architecture with the widely adopted FCN [2] and also with the well known DeepLab-LargeFOV [3], DeconvNet [4] architectures. This comparison reveals the memory versus accuracy trade-off involved in achieving good segmentation performance. SegNet was primarily motivated by scene understanding applications. Hence, it is designed to be efficient both in terms of memory and computational time during inference. It is also significantly smaller in the number of trainable parameters than other competing architectures and can be trained end-to-end using stochastic gradient descent. We also performed a controlled benchmark of SegNet and other architectures on both road scenes and SUN RGB-D indoor scene segmentation tasks. These quantitative assessments show that SegNet provides good performance with competitive inference time and most efficient inference memory-wise as compared to other architectures. We also provide a Caffe implementation of SegNet and a web demo at http://mi.eng.cam.ac.uk/projects/segnet.
Learning deconvolution network for semantic segmentation
[C]//2015 IEEE International Conference on Computer Vision (ICCV).December 7-13,2015,
DeepLab:Semantic image segmentation with deep convolutional nets,atrous convolution,and fully connected CRFs
[J].DOI:10.1109/TPAMI.2017.2699184 URL [本文引用: 1]
Rethinking atrous convolution for semantic image segmentation
[J].
ENet:A deep neural network architecture for real-time semantic segmentation
[J/OL].(
ERFNet:Efficient residual factorized ConvNet for real-time semantic segmentation
[J].DOI:10.1109/TITS.2017.2750080 URL [本文引用: 2]
ESFNet:Efficient network for building extraction from high-resolution aerial images
[J].
Unet++:A nested u-net architecture for medical image segmentation
[C]//Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support:4th International Workshop,
UNet 3:A full-scale connected UNet for medical image segmentation
[C]//
Swin transformer: Hierarchical vision transformer using shifted windows
[C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV).Montreal,QC,Canada.
IEU-Net高分辨率遥感影像房屋建筑物提取
[J].
House building extraction from high-resolution remote sensing images based on IEU-Net
[J].DOI:10.11834/jrs.20210042 URL [本文引用: 2]
改进LinkNet的高分辨率遥感影像建筑物提取方法
[J].
Improved LinkNet building extraction method for high resolution remote sensing image
[J].
新型语义分割D-UNet的建筑物提取
[J].
New building extraction method based on semantic segmentation
[J].DOI:10.11834/jrs.20211029 URL [本文引用: 2]
Res_ASPP_UNet++:结合分离卷积与空洞金字塔的遥感影像建筑物提取网络
[J].
Res_ASPP_UNet++:Building an extraction network from remote sensing imagery combining depthwise separable convolution with atrous spatial pyramid pooling
[J].DOI:10.11834/jrs.20210477 URL [本文引用: 1]
基于混合注意力机制和Deeplabv3+的遥感影像建筑物提取方法
[J].
A method for information extraction of buildings from remote sensing image based on hybrid attention mechanism and Deeplabv3+
[J]
遥感影像建筑物提取的卷积神经元网络与开源数据集方法
[J].
DOI:10.11947/j.AGCS.2019.20180206
[本文引用: 1]
从遥感图像中自动化地检测和提取建筑物在城市规划、人口估计、地形图制作和更新等应用中具有极为重要的意义。本文提出和展示了建筑物提取的数个研究进展。由于遥感成像机理、建筑物自身、背景环境的复杂性,传统的经验设计特征的方法一直未能实现自动化,建筑物提取成为30余年尚未解决的挑战。先进的深度学习方法带来新的机遇,但目前存在两个困境:①尚缺少高精度的建筑物数据库,而数据是深度学习必不可少的“燃料”;②目前国际上的方法都采用像素级的语义分割,目标级、矢量级的提取工作亟待开展。针对于此,本文进行以下工作:①与目前同类数据集相比,建立了一套目前国际上范围最大、精度最高、涵盖多种样本形式(栅格、矢量)、多类数据源(航空、卫星)的建筑物数据库(WHU building dataset),并实现开源;②提出一种基于全卷积网络的建筑物语义分割方法,与当前国际上的最新算法相比达到了领先水平;③将建筑物提取的范围从像素级的语义分割推广至目标实例分割,实现以目标(建筑物)为对象的识别和提取。通过试验,验证了WHU数据库在国际上的领先性和本文方法的先进性。
Building extraction via convolutional neural networks from an open remote sensing building dataset
[J].
Deeply-supervised nets
[C]//

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}