

0 引言
遥感技术的发展使遥感影像空间分辨率提高,地物细节信息更丰富、几何结构和纹理特征等更明显[1],这导致了噪声相应增加。如何从高空间分辨率遥感影像上准确提取建筑物成为研究的热点。
近年来不断涌现出大量深度学习模型,主要集中在以下几方面: ①数据处理速度提升与训练参数量减少的模型,如LeNet[8],AlexNet[9],VGGNet[10]和ResNet[11]等; ②能减少模型训练参数量的轻量级网络SqueezeNet[12],MnasNet[13]和MobileNet[14]等; ③能提高准确率与能进行多尺度特征提取的DeepLab系列模型等。在语义分割中,DeepLab系列是常用模型之一,主要用于逐像素分类。Chen等[15]提出DeepLabv1,结合深度卷积神经网络(deep convolution neural network, DCNN)和概率图模型,提出空洞卷积(atrous convolution),算法速度和准确率较高; Chen等[16]提出DeepLabv2,使用空洞空间金字塔池化(atrous spatial pyramid pooling, ASPP)扩大感受野、降低计算量; Chen等[17]提出DeepLabv3+,引入编码-解码(Encoder-Decoder)形式进行多尺度信息融合,使物体边界分割效果更好; 王俊强等[18]提出DeepLabv3+语义分割与全连接条件随机场相结合的提取方法,能从高分辨率遥感影像中获得典型要素边界信息; 刘文祥等[19]在网络中引入双注意力机制模块(dual attention mechanism module, DAMM),提出将DAMM结构与ASPP层串联和并联2种不同连接方式的网络模型,能有效改善DeepLabv3+的不足。但是利用DeepLabv3+提取遥感影像建筑物仍存在边界信息较粗糙、拟合速度慢、小尺度目标分割模糊和大尺度目标分割有孔洞等问题。
本文针对DeepLabv3+提取建筑物存在边界信息粗糙和训练量大等问题,提出一种轻量级DeepLabv3+模型的遥感影像建筑物提取方法,使用MobileNetv2[20]替换DeepLabv3+的主干网络,并将ASPP模块中空洞卷积的空洞率组合改为4,8,12,16,以期提高DeepLabv3+的训练速度和目标分割精确度,使模型能达到更好的建筑物提取效果。
1 方法与原理
本文提出一种轻量级DeepLabv3+模型的遥感建筑物提取方法: 使用轻量级网络MobileNetv2替换原模型的主干网络Xception; 在此基础上,将ASPP中空洞卷积的空洞率进行优化组合,提出一种新的ASPP模块结构,通过调整模型中的学习率和卷积核等参数,使模型达到更优的建筑物提取效果。
1.1 DeepLabv3+模型
DeepLabv3+引入Encoder-Decoder结构,主要分为编码(Encoder)部分和解码(Decoder)部分。在此结构中,引入可任意控制Encoder提取特征的分辨率,主干网络将原始Xception[21]进行改进,并将深度可分离卷积应用到ASPP和Decoder模块中。
1)Encoder部分。在主干DCNN里使用串行空洞卷积,在图像经过主干DCNN后,得到的结果分别传入Decoder和并行的空洞卷积用不同空洞率(rate)的空洞卷积进行特征提取,提取后合并,用1×1卷积压缩特征,进入Decoder部分,并使用双线性插值方法进行4倍上采样。
2)Decoder部分。一部分是DCNN经过4倍上采样输出的特征,另一部分是DCNN输出以后,经过并行空洞卷积后的结果。为防止Encoder得到的高级特征被弱化,用1×1卷积对低级特征降维,2个特征融合后,用3×3卷积进一步融合特征,使用双线性插值方法进行4倍上采样,得到与原始图像相同大小的分割预测结果。
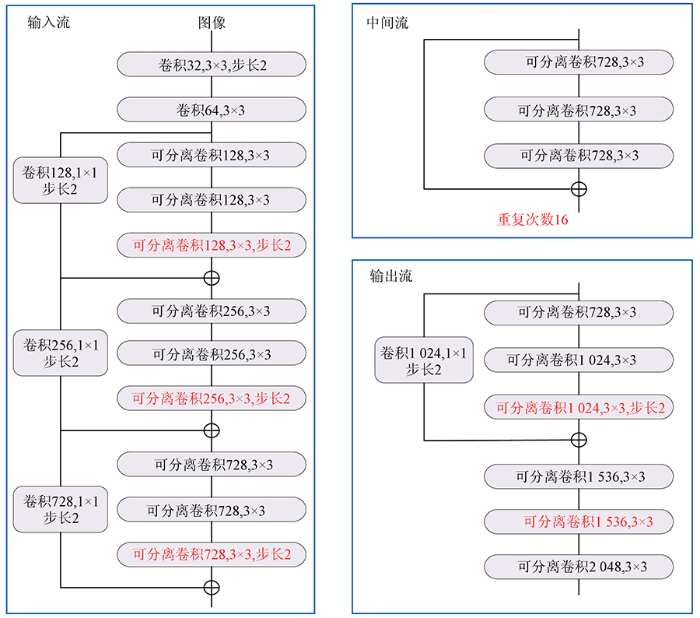
DeepLabv3+在语义分割任务中将Xception模型进行改进,与改进之前的Xception相比,DeepLabv3+的输入流保持不变,但中间流更多; 所有的最大池化被深度可分离卷积(depthwise separable convolution)替代; 在每个3×3深度卷积之后,增加批标准化(batch norm, BN)和整流线性单元(rectified linear units, ReLU)。Xception结构如图1所示。
图1
1.2 改进的DeepLabv3+网络
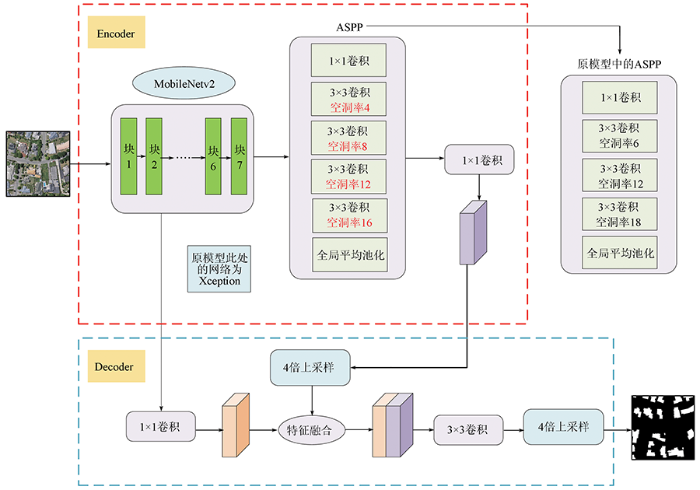
为有效提取遥感影像建筑物在不同尺度下的语义信息,本文使用Encoder-Decoder结构,并将深度可分离卷积应用在ASPP和Decoder模块中减少运算量,提高Encoder-Decoder网络对遥感影像建筑物提取的运行速率和健壮性。为增大感受野而不损失信息,使用空洞卷积增加每个卷积的输出信息量,并通过空洞卷积平衡精度和耗时。为减少训练参数量和训练时间,将DeepLabv3+的主干网络Xception替换为轻量级网络MobileNetv2; 为增强网络对不同大小目标的分割能力,将ASPP模块的空洞卷积中的6,12,18组合的空洞率改为4,8,12,16的组合。经过主干网络后的处理结果传到Decoder层,Decoder层的主要结构不发生改变。在上述工作完成后,对整个Encoder层进行优化,从而使替换后的网络能准确从遥感影像中提取出更高精度的建筑物。改进DeepLabv3+模型结构如图2所示(其中包含与原模型对比)。
图2
1.2.1 深度可分离卷积
本文主干网络核心内容为深度可分离卷积。在含有大量噪声和信息的遥感影像处理中,深度可分离卷积与常规卷积操作相比,有参数量少、训练时间短等优点,在精度保持不变的情况下,能更好地在遥感影像中快速提取建筑物的特征信息。
卷积核大小代表感受野大小,卷积核越大感受野越大,若卷积核过大,会使计算量增加,对含有大量信息的遥感影像进行处理时,随着网络深度的增加,计算能力和训练速度会逐渐降低,所以在本文网络中,使用1×1卷积和3×3卷积进行卷积操作。标准卷积是将过滤和输入合并为一组新的输出,而深度可分离卷积是由深度卷积和逐点卷积2部分相结合,一个用于过滤,另一个用于合并,以此用来提取特征。深度卷积是一个卷积核对应一个输入通道,独立对每个输入通道做空间卷积; 逐点卷积用于结合深度卷积的输出,即每个通道单独做卷积,通道数不变,然后将第一步的卷积结果用1×1卷积跨通道进行组合。卷积操作如图3所示。
图3
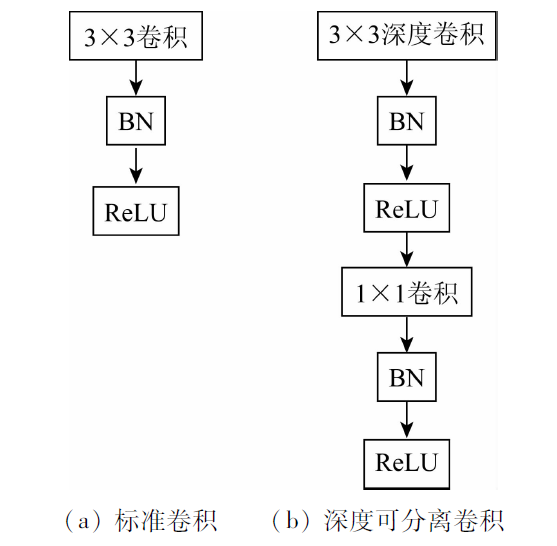
在本文深度可分离卷积中,首先采用深度卷积对不同输入通道分别进行卷积,然后采用逐点卷积将上面的输出进行结合,整体效果和一个标准卷积相同,但是会大大减少计算量和模型参数量,更适合提取建筑物特征。
1.2.2 主干网络
DeepLabv3+的主干网络Xception对种类多的提取任务有较好效果,但其网络复杂度高、参数量大,而遥感影像复杂、信息量大,随着训练的进行,参数量会逐渐加大,故Xception不适合提取遥感影像建筑物信息,因此使用轻量级网络MobileNetv2将DeepLabv3+的主干网络Xception替换,其网络体积小、参数量少,可以更快速、精准地从大量遥感影像信息中提取建筑物。
MobileNetv2网络(图4和表1)有更小的体积、更少的计算量、更高的准确率、更快的速度和多种应用场景等优点,在遥感影像建筑物提取中具有极大优势。MobileNetv2引入线性瓶颈结构(linear bottlenecks)和反向残差结构(inverted residuals),构成线性瓶颈倒残差结构,使遥感影像建筑物提取的参数量和计算量减少、训练速度和提取精度更高。在此结构中,反向残差结构将输入的低维通过1×1卷积进行升维,使用轻量级深度卷积进行过滤并提取特征图,并利用1×1卷积进行降维。为避免降维后ReLU损失建筑物提取精度和破坏建筑物特征,在深度卷积处理后使用线性瓶颈结构替换ReLU进行降维,并使用限制最大输出值为6的ReLU6替换普通ReLU。MobileNetv2中添加扩张倍数控制网络大小,虽然使网络结构更深,但计算量更少,能节省训练时间和资源,对遥感影像中建筑物提取有很大优势。
图4
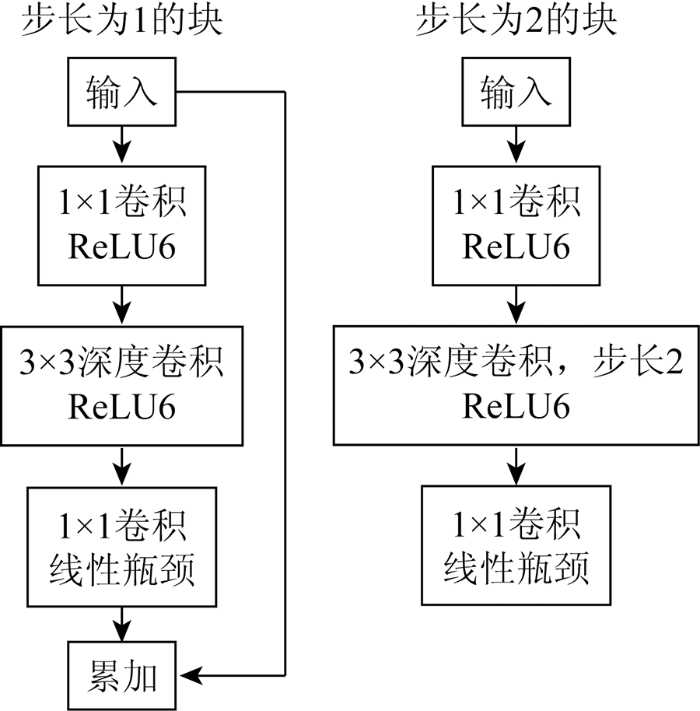
表1 MobileNetv2网络结构及参数
Tab.1
| 输入 | 操作 | 扩张 倍数 | 输出通 道数 | 重复 次数 | 步长 |
|---|---|---|---|---|---|
| 2242×3 | 卷积层 | — | 32 | 1 | 2 |
| 1122×32 | 瓶颈层 | 1 | 16 | 1 | 1 |
| 1122×16 | 瓶颈层 | 6 | 24 | 2 | 2 |
| 562×24 | 瓶颈层 | 6 | 32 | 3 | 2 |
| 282×32 | 瓶颈层 | 6 | 64 | 4 | 2 |
| 282×64 | 瓶颈层 | 6 | 96 | 3 | 1 |
| 142×96 | 瓶颈层 | 6 | 160 | 3 | 2 |
| 72×160 | 瓶颈层 | 6 | 320 | 1 | 1 |
| 72×320 | 1×1卷积层 | — | 1 280 | 1 | 1 |
| 72×1 280 | 7×7平均池化层 | — | — | 1 | — |
| 1×1×k | 1×1卷积层 | — | k | — | — |
1.2.3 空洞空间金字塔池化
ASPP是由空洞卷积与空间金字塔池化(spatial pyramid pooling, SPP)[22]融合形成,能有效提取遥感影像中多尺度语义特征,从而在遥感影像建筑物提取中被广泛使用。
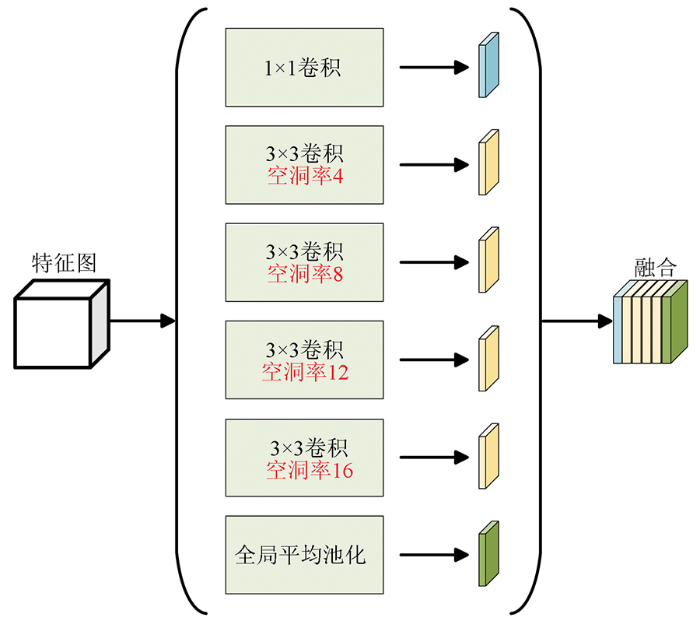
DeepLabv3+中ASPP模块空洞卷积的空洞率组合为6,12,18,随着主干网络对特征提取的进行,特征图分辨率会逐渐减小,6,12,18的组合不能更有效地提取多分辨率特征图特征,没有设置较小的空洞率,导致分割小目标的能力欠缺,从而使网络对不同大小分割目标的分割能力较弱。为更有效地提取多分辨率特征图特征,提高不同大小分割目标的分割能力,本文将空洞卷积的空洞率组合改为4,8,12,16,使较大的分割目标能被较大空洞率的卷积核分割,相反,较小的目标可以被较小空洞率的卷积核分割,较小的空洞率可使特征提取更有效。经过主干网络MobileNetv2得到的特征图输入到本文ASPP模块中,经过1×1卷积操作、不同空洞率3×3卷积操作和最后的池化操作后,不同大小的分割目标依次被卷积提取出特征图,将输出的6张特征图进行融合,得到由本文ASPP产生的特征图。本文改进的ASPP结构如图5所示。
图5
2 实验与分析
2.1 实验数据
WHU数据集主要包含航空图像、覆盖1 000 m2卫星图像、栅格标签和矢量地图,航空数据集由22万多个独立建筑物组成,这些建筑物由空间分辨率为0.075 m、覆盖范围为450 m2的新西兰克赖斯特彻奇航空图像中提取,此地区包含多种地物种类,各种不同颜色、大小和用途的建筑类型。数据集将大部分航空图像(包含187 000栋建筑物)降至0.3 m空间分辨率,并将其无缝裁剪为512像素×512像素的8 188个无重叠图块,同时将数据集分为训练集、验证集和测试集,其中用于训练的图像有4 736张、用于验证的图像有1 036张、用于测试的图像有2 416张。
Massachusetts建筑物数据集由波士顿地区的151张航拍图像组成,每幅图像为1 500像素×1 500像素、空间分辨率为1 m、单张覆盖面积为2.25 km2,整个数据集覆盖约340 km2。数据集预先划分为含有137张图像的训练集、10张图像的验证集和4张图像的测试集。为使Massachusetts数据集与WHU数据集中的图像大小保持相同,将Massachusetts数据集的每张图像分别裁剪为9张512像素×512像素大小的图像,裁剪后的图像数量为1 359张,并将其进行旋转,旋转后的图像数量为2 718张。
WHU与Massachusetts数据集实例图像如图6所示。WHU数据集影像的空间分辨率高于Massachusetts数据集影像的空间分辨率,并且Massachusetts数据集中的建筑物密度高,建筑物大小相对更小,更能体现出深度学习网络提取小型建筑物的能力。
图6

图6
WHU与Massachusetts数据集实例图像
Fig.6
Example images of WHU and Massachusetts datasets
2.2 实验设置
实验所用机器主要软硬件配置见表2。
表2 计算机配置
Tab.2
| 项目 | 配置 |
|---|---|
| CPU | Intel(R) Core(TM) i5-10200H CPU @ 2.40 GHz |
| GPU | NVIDIA GeForce GTX 1650 Ti |
| RAM | 16 G |
| 操作系统 | 64位Windows10 |
| 开发语言 | Python 3.7 |
| 深度学习框架 | Tensorflow-GPU 1.13.1 |
实验主要设置: 定义输入图片的高和宽及需要分割的种类数量,读取输入的图像和标签,进行归一化和大小调整,使用迁移学习思想获取主干特征提取网络的权重,并将数据集图像随机打乱,送入网络进行训练。初始学习率设置为0.000 3; 每次送入网络训练的图像批次为4,迭代次数为100次,每迭代2次保存一次训练细节; 使用交叉熵作为损失函数; 主干网络使用MobileNetv2网络; 优化器选择Adam优化器,该优化器能动态调整每个参数的学习率; 激活函数使用ReLU激活函数; 膨胀系数α设为1。评价指标为交并比(intersection over union, IoU)和F1分数,交叉熵损失函数、IoU和F1分数的公式分别为:
式中:
2.3 结果与分析
DeepLabv3+中ASPP模块空洞卷积的空洞率为6,12,18,本文ASPP模块的空洞率组合为4,8,12,16。在本文模型基础上,依次使用6,12,18和4,8,12,16的空洞率组合进行实验,验证ASPP模块的改进在网络模型中的效果。在使用原空洞率组合的情况下,测试结果的IoU值为80.54%,使用改进的ASPP空洞率组合的情况下,测试结果的IoU值为82.37%,比原组合提高1.83百分点,所以使用4,8,12,16的空洞率组合对遥感影像建筑物有更优的提取效果。
表3为不同模型分别在2个数据集中的评价指标值,其评价指标主要为IoU与F1分数。较其他经典模型相比,本文方法在2个数据集中实验结果的交并比均较高,遥感影像建筑物提取精度得到进一步提高。相比于DeepLabv3+模型,本文方法在WHU数据集中的IoU提升2.71百分点、F1分数提高2.14百分点,在Massachusetts数据集中的IoU提升2.04百分点、F1分数提高2.32百分点,U-Net与SegNet的评价指标值较低。总体上,本文提出的方法与其他模型相比均有所提升,对建筑物提取具有较高的有效性。由于本文模型使用的是轻量级网络,与DeepLabv3+模型的主干网络Xception相比,本文方法的主干网络参数量少,所以训练时间更短,能有效提升模型训练速度。
表3 建筑物提取评价结果
Tab.3
| 数据集 | 模型 | IoU/% | F1分 数/% | 训练时 间/h |
|---|---|---|---|---|
| WHU | U-Net | 77.28 | 88.23 | 10.53 |
| SegNet | 77.15 | 89.14 | 15.64 | |
| PSPNet | 78.23 | 89.53 | 11.32 | |
| DeepLabv3+ | 79.66 | 90.75 | 10.65 | |
| 本文方法 | 82.37 | 92.89 | 6.15 | |
| Massachusetts | U-Net | 71.25 | 82.11 | 12.88 |
| SegNet | 71.87 | 83.84 | 17.32 | |
| PSPNet | 72.15 | 82.26 | 13.55 | |
| DeepLabv3+ | 74.58 | 84.43 | 12.72 | |
| 本文方法 | 76.62 | 86.75 | 7.35 |
建筑物提取结果如表4所示,在预测结果中随机选取图像作为本次实验结果的对比分析。在WHU数据集中U-Net和SegNet的提取结果相似,整体效果不佳,对小型建筑物的提取有时会失效或提取面积极小,在Massachusetts数据集中也可看出其对小型建筑物有提取效果不佳、提取面积极小的情况,并出现多处建筑漏提现象。较其他经典模型相比,DeepLabv3+模型的提取效果较好,对大型建筑物边界的提取精度更高,与本文方法相比,对小型建筑物的提取效果不佳、提取面积小、数量少。由于本文对ASPP中的空洞卷积设置较小的空洞率,因此本文方法对小型建筑物的提取面积有所增大,比DeepLabv3+模型提取的建筑物数量更多,改善了DeepLabv3+漏提和少提现象,边界信息进一步提高,优于DeepLabv3+模型提取效果; 对建筑物错误提取率较低,提取出的建筑物完整度较高,总体上提取效果较好。但是对小型建筑物的提取精度仍然有待提高,小型建筑物的边界信息提取不够完善,对具有复杂边界的建筑物提取时,其边界细节信息提取不够精细,对大型建筑物提取时偶尔会出现一些孔洞或提取模糊现象。
表4 WHU和Massachusetts数据集建筑物提取结果
Tab.4
| 数据集 | 序号 | 原始图像 | 标签 | U-Net | SegNet | DeepLabv3+ | 本文方法 |
|---|---|---|---|---|---|---|---|
| WHU | 1 |  | |||||
| 2 |  | ||||||
| 3 |  | ||||||
| Massa- chusetts | 1 |  | |||||
| 2 |  | ||||||
| 3 |  | ||||||
3 结论和展望
针对DeepLabv3+网络参数量大的问题,本文对DeepLabv3+中的主干网络进行替换,利用MobileNetv2网络轻便的特点,减少网络参数量、优化网络结构,实验结果也证明了本文方法的有效性,训练速度和精度得到有效提升; 对网络中ASPP模块进行调整,将原ASPP模块中6,12,18的空洞率调整为4,8,12,16的组合,经过对ASPP模块的实验结果可得出,本文改进空洞率的ASPP模块对建筑物的提取效果优于原空洞率组合的提取效果。本文方法总体上对遥感影像建筑物的提取精度较高、参数量少、训练成本更低,能更有效提取遥感影像建筑物。由实验结果可看出,本文网络对建筑物提取仍然存在不足,在后续研究中,继续对ASPP中的空洞率组合和主干网络参数进行调整实验,使其对小型建筑物能够达到更好的提取效果; 根据边界损失等思想进一步思考,提出能够提高边界提取精度的新方法; 考虑在本文模型基础上加入其他结构和机制,以此加强网络的健壮性和提取效果、能更有效地改善提取模糊和孔洞现象。
参考文献
基于深度学习的高分辨率遥感影像建筑物提取方法
[J].
A high-resolution remote sensing image building extraction method based on deep learning
[J].
利用U-net网络的高分遥感影像建筑提取方法
[J].
High-resolution image building extraction using U-net neural network
[J].
结合模糊度和形态学指数约束的深度学习建筑物提取
[J].
DOI:10.12082/dqxxkx.2021.200397
[本文引用: 1]

基于高分辨率遥感影像的建筑物提取一直是研究的热点问题,深度学习的深层次特征提取方法,非常适合高分辨率影像中建筑物的提取,但使用深度学习提取建筑物时,大多以改变网络结构为主进行算法优化,很少与其他方法结合。本文研究在改进深度学习网络结构的基础上,结合影像模糊度约束增强、形态学建筑指数约束增强等方法,对建筑物提取方法进行更全面更有针对性的改进。本文主要改进内容为:① 提出PwDeepLab网络,该网络基于DeepLab v3+网络结构,在特征融合方式和损失函数等方面进行了改进。② 提出模糊度约束方法,在固定影像块大小的情况下,通过影像模糊度约束对影像进行上采样增强。③ 提出形态学指数约束方法,通过形态学建筑物指数(MBI)约束范围拉伸增强的方法,在较少改变原始影像特征的情况下,突出建筑信息。本文在Massachusetts数据集和武汉大学的Satellite Dataset Ⅱ(East Asia) 数据集上进行验证, 2个数据集的主要建筑类型存在较大区别。本文提出的方法在2个数据集上的精度相对于DeepLab v3+分别提高了10.9%和3.8%,相对于U-Net分别提高了10.0%和9.6%。实验结果表明本文提出的方法对建筑物提取效果有明显提升,且具有很好的鲁棒性和通用性。
Building extraction by deep learning method combined with ambiguity and morphological index constraints
[J].
基于特征增强和ELU的神经网络建筑物提取研究
[J].
DOI:10.12082/dqxxkx.2021.200130
[本文引用: 1]
近年来,城市发展快速,大量人口奔向城市工作生活,城市建筑物的数量有如雨后春笋般扩张,需要合理地规划城市土地资源,遏制违规乱建现象,因此基于高分辨率遥感影像,对建筑物进行准确提取,对城市规划和管理有着重要辅助作用。本文基于U-Net网络模型,使用美国马萨诸塞州建筑物数据集,对网络模型结构进行探究,提出了一种激活函数为ELU、“编码器-特征增强-解码器”结构的网络模型FE-Net。实验首先通过比较不同网络层数的U-Net5、U-Net6、U-Net7的建筑物提取效果,找到最佳的基础网络模型U-Net6;其次,基于该模型,加入特征增强结构得到“U-Net6+ReLU+特征增强”的网络模型;最后,考虑到ReLU容易产生神经元死亡,为优化激活函数,将激活函数替换为ELU,从而得到网络模型FE-Net(U-Net6+ELU+特征增强)。比较3个网络模型(U-Net6+ReLU、U-Net6+ReLU+特征增强、FE-Net(U-Net6+ELU+特征增强))的建筑物提取结果,表明FE-Net网络模型的建筑物提取效果最好,精度放松F1值达到97.23%,比“U-Net6+ReLU”和“U-Net6+ReLU+特征增强”2个网络模型分别高出0.36%和0.12%,且与其他具有相同数据集的研究成果比较,具有最高的提取精度,它能较好地提取出多尺度的建筑物,不仅对小尺度建筑物有较好的提取效果,而且能大致、较完整地提取出形状不规则的建筑物,有相对更少的漏检和错检,较准确地实现了端到端的建筑物提取。
Research on building extraction based on neural network with feature enhancement and ELU activation function
[J].
利用深度残差网络的遥感影像建筑物提取
[J].
Building extraction in remote sensing imagery based on deep residual network
[J].
基于编解码网络的航空影像像素级建筑物提取
[J].
Building extraction in pixel level from aerial imagery with a deep encoder-decoder network
[J].
基于增强DeepLabV3网络的高分辨率遥感影像分类
[J].
High-resolution remote sensing image classification based on improved DeepLabV3 network
[J].
Gradient-based learning applied to document recognition
[J].DOI:10.1109/5.726791 URL [本文引用: 1]
ImageNet classification with deep convolutional neural networks
[J].
Very deep convolutional networks for large-scale image recognition
[J].
Deep residual learning for image recognition
[EB/OL].(
SqueezeNet:AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size
[EB/OL].(
MnasNet:Platform-aware neural architecture search for mobile
[C]//
MobileNets:Efficient convolutional neural networks for mobile vision applications
[EB/OL].(
Semantic image segmentation with deep convolutional nets and fully connected CRFs
[J].
DeepLab:Semantic image segmentation with deep convolutional nets,atrous convolution,and fully connected CRFs
[J].DOI:10.1109/TPAMI.2017.2699184 URL [本文引用: 1]
Encoder-decoder with atrous separable convolution for semantic image segmentation
[C]//
基于DeepLabv3+与CRF的遥感影像典型要素提取方法
[J].
Typical element extraction method of remote sensing image based on DeepLabv3+ and CRF
[J].
采用双注意力机制DeepLabv3+算法的遥感影像语义分割
[J].
Remote sensing image segmentation using dual attention mechanism DeepLabv3+ algorithm
[J].
Mobilenetv2:Inverted residuals and linear bottlenecks
[C]//
Xception:Deep learning with depthwise separable convolutions
[C]//
Spatial pyramid pooling in deep convolutional networks for visual recognition
[J].
Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set
[J].DOI:10.1109/TGRS.2018.2858817 URL [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}