

0 引言
深度学习模型通过构建层次化的网络框架,能够逐层提取出具有高判别性和信息性的深层次特征,从而获得更为优异的分类和识别效果。栈式自编码[3]、深度置信网络[4]、循环神经网络[5]等深度模型被率先应用于高光谱影像分类的研究中,在样本充足的条件下取得了较传统方法更为优异的分类效果。卷积神经网络[6-7]利用卷积运算能够直接处理呈网格结构的图像数据,因此更适用于高光谱影像的处理和分析。为了同时利用高光谱影像中空间和光谱信息,二维和三维卷积神经网络被广泛应用于高光谱影像分类。例如,高奎亮等[8]将二维卷积和NIN网络结构相结合,设计了一种新颖深度网络模型,有效提高了分类精度; Li等[9]利用三维卷积构建了适用于高光谱影像分类的深度模型,以充分利用影像中的深度空谱联合信息。除此之外,主动学习[10]、迁移学习[11]和残差学习[12]等先进学习方法也与卷积神经网络相结合,进一步提高了高光谱影像分类的精度和鲁棒性。
1 主要算法
1.1 Transformer模型
基本的Transformer模型结构如图1所示,包含一个自注意力层和一个前馈神经网络。Transformer模型的输入和输出均为一个特征向量序列,为了更好地考虑输入的特征向量位置信息,在输入第1层Transformer前,先对特征向量序列进行空间位置编码,然后和特征向量相加作为输入。Transformer模型的输出同样为特征向量序列,并作为下一层Transformer的输入。
图1
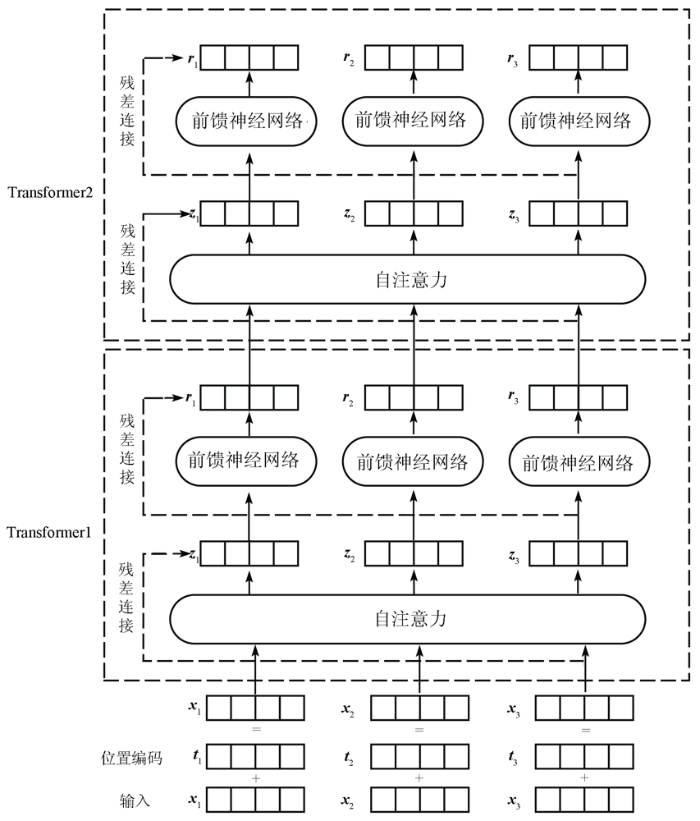
1.1.1 空间位置编码
空间位置编码为每个特征向量输出一个维度与特征向量相同的空间位置向量,从而用空间位置向量来描述特征向量的位置关系。本文采用如下的形式对特征向量进行位置编码,即
式中: PE为位置编码; pos为特征向量在整个序列中的位置;
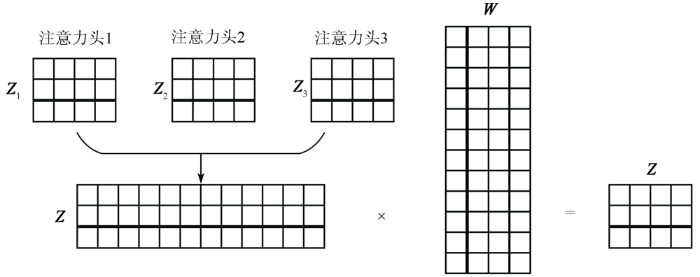
1.1.2 自注意力层
与卷积神经网络的训练参数卷积核不同,每层Transformer的训练参数包含3个矩阵
式中:
图2
为了提高模型的非线性,将自注意力层输出的特征向量序列再分别通过一个前馈神经网络,本文采用2层全连接层作为前馈神经网络。另外,在Transformer模型中的自注意力层和前馈神经网络层引入残差连接,以提高深度模型的训练效果。
1.2 本文网络模型
本文网络模型的整体结构如图3所示,Conv2D,TRM和MLP分别代表二维卷积层、Transformer层和多层感知机。首先,利用主成分分析方法对高光谱数据立方体进行降维处理,并保留前3个主成分分量。为了充分利用高光谱影像中的空谱联合信息,选择中心像素周围32像素×32像素大小的邻域作为输入样本。具体地,将输入样本沿空间方向划分为16个大小相等的图像块; 然后,利用卷积层将图像块映射为一维特征向量,至此一个输入样本被转换为16个一维特征向量; 接着,将序列特征向量输入到包含8个Transformer层的深度网络进行深度特征提取; 最后,利用多层感知机输出分类结果。本文网络模型具有端到端的网络结构,以像素领域数据作为输入,以类别标记作为输出。
图3

2 数据集及参数设置
2.1 数据集
为了验证本文方法的有效性,采用Salinas和Indian Pines这2组高光谱数据集进行试验。Salinas数据集由AVIRIS传感器于1992年获取,观测区域为美国加利福尼亚州某山谷,影像大小为512像素×217像素,光谱覆盖范围为0.40~2.50 μm,空间分辨率为3.7 m。该数据集共包括野草、休耕地和莴苣等16个标注类别和204个波段,标注类别集中分布在影像的左侧和上侧,且均为条状和面状地物。Indian Pines数据集由AVIRIS传感器于2001年获取,观测区域为美国印第安纳州西北部某处农田,影像大小为145像素×145像素,光谱覆盖范围为0.40~2.50 μm,空间分辨率为20 m,共包括200个波段可用于分类。该数据集共包括玉米、大豆和树木等16个地物类别且在影像中均匀分布,但部分类别包含的标记样本过少。参照相关文献,本文仅选取了9个样本数量较多的类别进行实验。另外,2个数据集均随机选取200个标记样本作为训练数据,剩余样本作为测试样本(2个数据集分别包含50 929个和7 434个测试样本)。
2.2 参数设置
试验中,迭代训练次数设置为600,学习率设置为0.000 1,数据批量大小为64,并利用Adam算法进行网络优化,以保证模型进行充分训练。卷积核数量设置为128,因此每个图像块将被转换为长度为128的特征向量。多头注意力机制中头数设置为8,使模型能够提取到更为丰富的特征。多层感知机中,全连接层的神经元个数分别设置为128和K(K为目标数据集中包含的类别数量)。另外,本文试验的硬件环境为Intel(R) Xeon(R) Gold 6152处理器和Nvidia A100 PCIE显卡。
3 结果与分析
图4
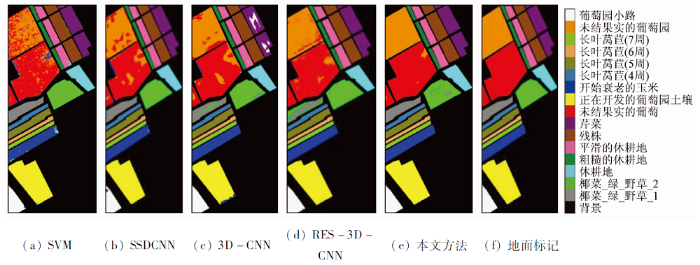
图5
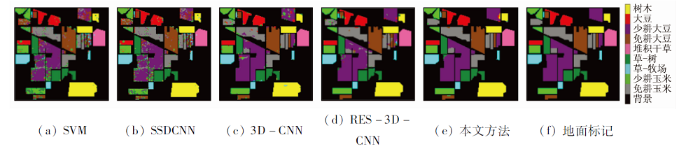
为了进一步对不同方法的分类性能进行定量评价,选择总体分类精度(overall accuray,OA)、平均分类精度(average accuracy,AA)和Kappa系数作为评价指标。2个数据集不同方法的分类结果如表1—2所示。从表中可以看到,传统的机器学习分类器SVM由于无法利用高光谱影像中的深层次特征,因此无法获得令人满意的分类结果。深度学习模型SSDCNN和3D-CNN分别利用二维卷积和三维卷积进行深度特征提取,分类精度有一定提高。RES-3D-CNN利用残差连接和三维卷积核构建了深度残差网络模型,具有更深层次的网络,能够利用深层次的空谱联合特征,因此具有更高的分类精度。在所有对比方法中,本文方法获得了更为优异的分类效果。在Salinas数据集上,其OA,AA和Kappa系数分别较第二名提高了3.01百分点,0.83百分点和0.033 4; 在Indian Pines数据集上,其OA,AA和Kappa系数分别较第二名提高了2.84百分点,1.23百分点和0.033 1。本文方法通过堆叠Transformer模型构建骨干网络,并利用注意力机制和残差连接保证模型能够有效利用到有益于分类任务的深层抽象特征,从而进一步提高分类精度。需要说明的是,本文方法虽然在个别地物上的分类精度略低于RES-3D-CNN模型(例如Salinas数据集中第1类,Indian Pines数据集中第2,4和8类),但其能够明显提高其他方法难以区分的地物的分类精度(例如Salinas数据集中第8类和第15类、Indian Pines数据集中第1类和第7类)。这表明,本文方法能够有效提高可分性差的地物的分类精度,从而提升影像的整体分类效果。
表1 Salinas数据集分类结果
Tab.1
| 序号 | 类名称 | SVM | SSDCNN | 3D- CNN | RES-3D -CNN | 本文 方法 | |
|---|---|---|---|---|---|---|---|
| 各类别分类精度/ % | 1 | 椰菜_绿_野草_1 | 99.20 | 98.90 | 98.75 | 100 | 91.74 |
| 2 | 椰菜_绿_野草_2 | 99.62 | 89.43 | 99.25 | 98.12 | 100.00 | |
| 3 | 休耕地 | 99.70 | 100 | 99.14 | 99.70 | 100.00 | |
| 4 | 粗糙的休耕地 | 99.50 | 99.93 | 99.50 | 99.86 | 100.00 | |
| 5 | 平滑的休耕地 | 96.75 | 96.56 | 99.74 | 99.81 | 99.81 | |
| 6 | 残株 | 99.42 | 99.97 | 99.62 | 100 | 99.87 | |
| 7 | 芹菜 | 99.36 | 97.18 | 98.21 | 99.55 | 100.00 | |
| 8 | 未结果实的葡萄 | 84.75 | 77.61 | 89.57 | 88.24 | 100.00 | |
| 9 | 正在开发的葡萄园土壤 | 99.10 | 99.11 | 99.98 | 99.50 | 99.98 | |
| 10 | 开始衰老的玉米 | 93.29 | 99.69 | 95.01 | 98.66 | 99.82 | |
| 11 | 长叶莴苣(4周) | 97.85 | 99.91 | 95.78 | 100 | 100.00 | |
| 12 | 长叶莴苣(5周) | 99.84 | 100 | 99.79 | 99.95 | 99.95 | |
| 13 | 长叶莴苣(6周) | 98.58 | 99.89 | 100.00 | 99.45 | 99.89 | |
| 14 | 长叶莴苣(7周) | 95.79 | 99.53 | 97.99 | 100 | 100.00 | |
| 15 | 未结果实的葡萄园 | 65.74 | 96.68 | 82.12 | 91.98 | 96.40 | |
| 16 | 葡萄园小路 | 98.89 | 99.34 | 99.43 | 99.45 | 100.00 | |
| OA/% | 91.20 | 93.61 | 94.67 | 96.12 | 99.13 | ||
| AA/% | 95.46 | 97.11 | 97.12 | 98.39 | 99.22 | ||
| Kappa | 0.902 0 | 0.929 1 | 0.940 7 | 0.956 9 | 0.990 3 | ||
表2 Indian Pines数据集分类结果
Tab.2
| 序号 | 类名称 | SVM | SSDCNN | 3D- CNN | RES-3D -CNN | 本文 方法 | |
|---|---|---|---|---|---|---|---|
| 各类别分类精度/ % | 1 | 免耕玉米 | 75.78 | 88.38 | 93.07 | 94.05 | 99.64 |
| 2 | 少耕玉米 | 71.12 | 94.34 | 96.27 | 99.04 | 97.42 | |
| 3 | 草-牧场 | 89.10 | 97.52 | 98.55 | 98.96 | 100.00 | |
| 4 | 草-树 | 96.15 | 99.86 | 97.12 | 99.59 | 97.73 | |
| 5 | 堆积干草 | 99.79 | 100.00 | 100.00 | 100.00 | 100.00 | |
| 6 | 免耕大豆 | 69.98 | 92.49 | 96.81 | 97.02 | 98.37 | |
| 7 | 少耕大豆 | 89.22 | 87.17 | 91.85 | 91.28 | 99.59 | |
| 8 | 大豆 | 79.79 | 99.33 | 97.47 | 99.33 | 97.85 | |
| 9 | 树木 | 99.68 | 96.36 | 98.42 | 99.21 | 98.98 | |
| OA/% | 84.57 | 92.81 | 95.41 | 96.12 | 98.96 | ||
| AA/% | 85.62 | 95.05 | 96.62 | 97.61 | 98.84 | ||
| Kappa | 0.820 9 | 0.915 9 | 0.946 3 | 0.954 7 | 0.987 8 | ||
另外,深度学习模型需要足够的标记样本进行网络优化和参数更新,然而,实际中获取高质量的标记样本是十分费时费力的。因此,深度分类模型应对训练样本数量的变化具有良好的适应性。为了探究不同分类方法在训练样本逐渐减少时的分类性能,随机选取每类100,120,140,160,180,200个样本作为训练样本进行分类试验,结果如图6所示。从图6中可以看出,随着训练样本的减少,所有分类方法的分类准确率都逐渐下降。SVM在2个数据集上的分类曲线始终低于其他对比方法。SSDCNN,3D-CNN和RES-3D-CNN这3种基于CNN的深度学习分类模型的总体分类精度曲线变化相对平稳,说明它们对训练样本数量的变化具有较好的适应性。本文方法的总体分类精度曲线始终高于其他方法,这表明当训练样本逐渐减少时,该方法具有最好的分类性能。
图6
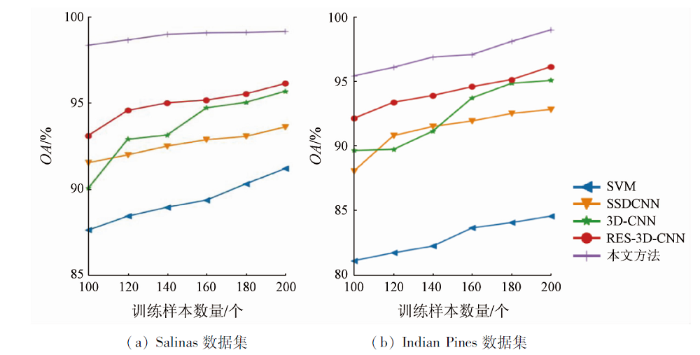
图6
训练样本数量对分类精度的影响
Fig.6
Influence of the number of training samples on classification accuracy
4 结论
为了进一步提高高光谱影像分类精度,基于Transformer模型设计了一种新颖的深度分类模型,并展开了相关高光谱影像分类试验,具体结论如下:
1)与基于卷积神经网络的深度学习模型相比,本文方法能够更好地对全局语义信息进行建模,从而获得更高的分类性能。在Salinas和Indian Pines这2个数据集上的试验结果表明,本文方法能够获得比现有卷积神经网络模型更为优异的分类性能。
2)从类一致性的角度看,本文方法的分类结果具有更好的视觉效果,更接近地面真实标记。
3)在逐渐减少训练样本的条件下,本文方法始终能够获得较为优异的分类效果,表明本文方法对训练样本数量具有较好的适应性。
与常规卷积神经网络相比,本文方法利用Transformer模型有效提高了高光谱影像分类精度。下一步的工作将结合半监督学习、元学习等方法进一步提高高光谱影像在训练样本受限条件下的分类精度。
参考文献
Recent advances on spectral-spatial hyperspectral image classification:An overview and new guidelines
[J].DOI:10.1109/TGRS.2017.2765364 URL [本文引用: 1]
Advanced spectral classifiers for hyperspectral images:A review
[J].
Unsupervised spectral-spatial feature learning with stacked sparse autoencoder for hyperspectral imagery classification
[J].DOI:10.1109/LGRS.2015.2482520 URL [本文引用: 1]
Classification of hyperspectral image based on deep belief networks
[C]//
Spatial sequential recurrent neural network for hyperspectral image classification
[J].DOI:10.1109/JSTARS.2018.2844873 URL [本文引用: 1]
CSA-MSO3DCNN:Multiscale octave 3D CNN with channel and spatial attention for hyperspectral image classification
[J].DOI:10.3390/rs12010188 URL [本文引用: 1]
Deep induction network for small samples classification of hyperspectral images
[J].DOI:10.1109/JSTARS.2020.3002787 URL [本文引用: 1]
基于Network In Network网络结构的高光谱影像分类方法
[J].
Classification method of hyperspectral image based on Network In Network structure
[J].
Spectral-spatial classification of hyperspectral imagery with 3D convolutional neural network
[J].DOI:10.3390/rs9010067 URL [本文引用: 2]
Multiview intensity-based active learning for hyperspectral image classification
[J].DOI:10.1109/TGRS.2017.2752738 URL [本文引用: 1]
Transferring CNN ensemble for hyperspectral image classification
[J].DOI:10.1109/LGRS.2020.2988494 URL [本文引用: 1]
Unsupervised spectral-spatial feature learning via deep residual Conv-Deconv network for hyperspectral image classification
[J].DOI:10.1109/TGRS.2017.2748160 URL [本文引用: 1]
Attention is all you need
[C]//
An image is worth 16×16
[Z].
Spectral-spatial classification of hyperspectral images using deep convolutional neural networks
[J].DOI:10.1080/2150704X.2015.1047045 URL [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}