

0 引言
建筑物是城市中的重要主体,在一定程度上反映了城市的发展规模。准确获取建筑物变化信息对于城市发展规划、非法建筑物识别、灾害评估和地理数据库更新等实际领域中具有重要的作用与意义。利用遥感手段对城市建筑物进行变化检测可以快速准确地获取建筑物的变化信息,借助机载激光雷达(light detection and ranging,LiDAR)点云数据可以实现建筑物的三维变化检测,本文三维变化检测意在获取建筑物在三维空间中面积与高程的变化,包括水平面上的新增、拆除以及高度方向上的增高、降低的变化位置与面积。
多年来,研究者们持续挖掘点云在变化检测中的潜力,并发展出了多种检测建筑物三维变化的方法,如基于2期数字表面模型(digital surface model,DSM)差分结果进行人工解译[1]、直方图统计[2]、连通性分析[3]等确定发生变化的建筑物; 或分别对2期点云的DSM通过边界拟合[4]、高度与平整度分析后聚类[5]等方法提取建筑物后,再差分进行变化检测; 通过先提取点云中的非地面点,再利用影像与分类树提取建筑物后,与现有地理数据库对比的方法[6]; 通过影像数字制图产品与激光雷达(light detection and ranging,LiDAR)点云经过支持向量机(support vector machine,SVM)提取建筑物后对比的方法[7]; 使用航空影像密集图像匹配点云与LiDAR点云建立差分DSM提取变化信息后,再使用点云法线方向方差的方法确定变化的建筑物[8]。可见在这些方法中,获取变化建筑物主要有2种手段: 提取建筑物后再检测变化; 先确定变化候选区域,再确定属于建筑物的变化。而上述方法存在的问题在于: 将点云转换为其他规则格式数据易造成信息丢失,局部点甚至更大尺度点云间的关系被忽略; 没有充分利用点的强度和光谱信息特征; 自动化程度低,需要较多的后处理分析来改善精度。
本文采用深度学习与分类后检测的方法研究基于机载LiDAR点云的建筑物三维变化检测,与当前主流点云变化检测研究不同的是: ①引入基于深度学习的点云语义分割网络RandLA-Net,快速准确地提取建筑物; ②结合本文的建筑物提取方法,设计了针对本文异源点云数据的处理方法,以减少点云间的差异,保证变化检测的精度; ③充分考虑局部点间的结构与距离特征,加入LiDAR点云的反射强度特征与影像赋予的光谱信息作为语义特征,以提高建筑物提取的准确率。
1 研究区数据采集与标注
1.1 研究区概况与数据源
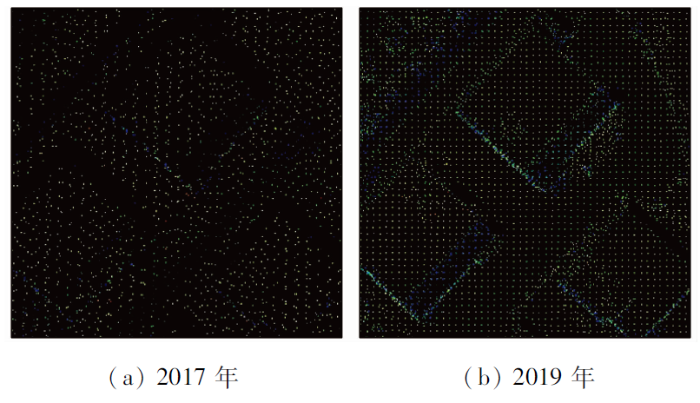
研究使用的机载LiDAR点云,与车载LiDAR不同之处在于: 飞机在一定高度飞行,点云密度较为一致,而车载LiDAR主要为获得较近处的点云,点云密度相较于机载雷达高,但远近点云的密度不同,且点云规模较机载点云规模小。选择南京市部分区域为研究区,地理坐标在N32°2'26″~32°4'8″,E118°34'17″~118°36'21″之间。通过航空机载LiDAR分别采集研究区2017年3月2日及2019年4月6日的点云数据,获得包含地物位置信息以及反射强度的点云,2017年与2019年点云密度分别为1点/m2与16点/m2,点数量分别为10 428 812与181 208 261个点。点云数据示例见图1。
图1

1.2 数据集制作
2期点云数据由不同的LiDAR传感器获取,其点云的不同主要在于点云密度与反射强度的值域。由于RandLA-Net在获取局部点信息时,使用了K最邻近(K-nearest neighbor,KNN)算法,并固定了最邻近点的数量,导致在点云密度不同的情况下获取的局部信息存在差异,进而在较小样本上进行训练时,网络损失与精度曲线难以收敛。因此使用稀疏的2017年点云进行训练,并对2019年点云下采样(图2),使得2期点云密度相同,以保证异源数据的语义分割精度,但是,本文使用网格采样的方法,采样后的点云结构同样存在差异,2017年获取的点云是完全无序的,而2019年点云在采样后则存在着一定的有序性,其表现为点云呈网格状排列。其次,2期点云的反射强度值域不同,2017年点云值为1~6的整数,2019年点云为1~65 535的整数,本文将2019年点云强度值线性映射至2017年的反射强度值域。
图2
点云数据集基于MicroStation的Terrascan软件,结合航拍影像判读,对研究区内建筑物点云进行目视解译并人工标注。由于实验用的点云重复区域较多,因此仅将2017年点云数据进行数据划分,其中2期点云5%的区域用于测试,并将2017年点云其他部分按4:1的比例划分为训练集与验证集,2019年点云数据不参与训练,仅用于测试。
图3

2 研究方法
传统的使用点云数据进行变化检测,往往基于DSM差分的方法,依赖于高程与手动调整阈值提取建筑物与其变化信息,忽略了较多的局部信息与点云特征,且自动化程度低,结果易与树木混淆,导致低矮建筑物检测结果不佳。针对这些问题,本文引入基于深度学习方法的RandLA-Net点云语义分割网络提取建筑物,利用点云坐标、局部点的位置关系、强度、光谱信息,快速、高精度、自动化地提取建筑物。结合分类后检测的变化检测方案,比较前后时期点云语义分割结果,定性与定量地获得目标区域地物范围与高程的变化。同时,本文还通过实验研究了不同特征的组合对最终结果的影响,提出了不同情况下的应用建议。
点云具有无序性的特点,以及前后时期点云数据密度大多不同,无法实现2期点云的分割结果的直接差分进行变化检测。因此本文结合影像差分的思路,将RandLA-Net网络提取出的点云建筑物通过正射投影的方式,按照相同的空间分辨率投影为包含建筑物高度信息的灰度影像。投影时根据点云的尺寸以及设定的空间分辨率自动计算点云每点坐标与影像像素坐标的转换公式,获得每点对应的像素坐标,像素值为该像素内所有建筑物点的最大Z值,非建筑物目标像素值为0; 然后通过2期结果差分前后的状态与差分后的值定性定量地判断建筑物目标在三维空间上的变化。其中,假设前一时期的投影结果对应像素值为A,后一时期为B,则差分时的评判规则为: 若B>A,且A=0,则该位置为新增建筑物; 若B>A,且A≠0,则为增高; 若B<A,且B=0,则为拆除; 若B<A,且B≠0,则为降低; 其他情况为无变化。
2.1 RandLA-Net算法结构
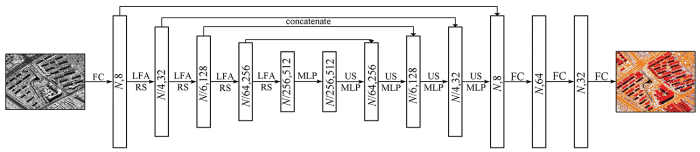
RandLA-Net结构遵循具有跳跃连接的编码解码思想。其结构如图4所示,点云不同于影像在于无法通过卷积核的遍历影像提取特征,因此在点云的语义分割算法中,其基本单元为多层感知机(multilayer perceptron,MLP)。在编码端,点云通过每一层的局部特征聚合(local feature aggregation,LFA)算法丰富与学习点的特征,并使用随机采样(random sampling,RS)减小点云的规模,每次保留25%的点云数量,每一层的特征维数为(8,32,128,256,512)。解码端使用每个点与KNN获得最邻近点的线性插值方法进行上采样(up-sampling,US),通过跳跃连接与编码端的特征图叠加,然后输入共享的MLP进行特征降维。最后,3个全连接层(fully connected layers,FC)与Dropout层用于预测每个点的类别。
图4
2.2 LFA算法
LFA算法是RandLA-Net结构的核心,主要由3个模块组成,包括局部空间编码(local spatial encoding,LocSE)、注意力池化(attentive pooling)与扩张残差块(dilated residual block),LFA的模块结构如图5所示。
图5
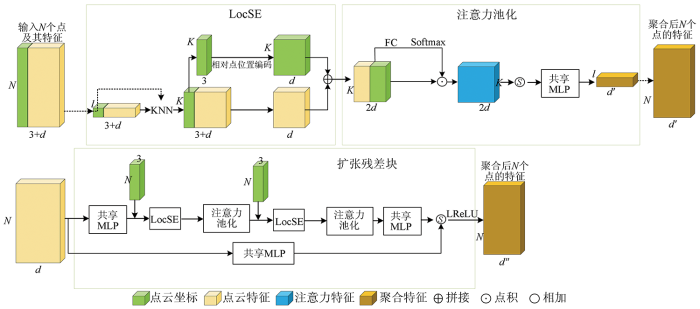
2.2.1 LocSE
LocSE对输入点云的每一个点与最近邻
式中⊕表示两者串联拼接。经过MLP编码后的特征数为
2.2.2 注意力池化
注意力池化模块用于聚合点的局部特征。LocSE获得的局部点特征,经过可学习的FC与Softmax激活函数获得每个邻近点特征的得分作为输入邻近点特征的权重,对所有邻近点特征加权求和后获得该点
2.2.3 扩张残差块
为了处理大规模的点云,RandLA-Net采用了随机采样的方法对编码端的点云进行下采样,因为其具有时间与空间复杂度低的特点,高效且占用内存小。但是随机采样有几率造成关键点信息的丢失,因此使用扩张残差块模块对LocSE、注意力池化与MLP进行堆叠,增加每个点的感受野,降低随机采样丢失关键点信息的影响。
在扩张残差块中,将LocSE与注意力池化模块进行多次堆叠,并在每次进行LocSE前将点的位置信息加入。同时在输入前与输出后馈入MLP,以获得必要的特征数,并将堆叠后的输出特征与输入点云经过MLP处理后的特征相加,获得最终的聚合特征。
3 实验与结果分析
3.1 实验环境与各项参数
本文的实验环境为I5-8400处理器,内存大小16 G, NVIDIA GeForce GTX 1080Ti 11 G显卡,使用CUDA 11.0 加速GPU计算,深度学习框架为基于Python 3.5.6的TensorFlow-GPU 1.11.0。实验准备数据采样为1点/m2的点云,模型使用的最邻近点K值为16,单次输入点数为40 960,初始学习率为0.01,动量为0.95,模型迭代次数为100。点云的预处理与数据集的制作主要基于MicroStation上的TerraScan软件,点云投影影像空间分辨率为1 m。
3.2 LiDAR点云建筑物提取
从LiDAR点云中准确提取建筑物有着诸多干扰,首先是低矮建筑物高度往往低于周边的高大树木,因此在提取过程中,单纯考虑建筑物的高度常会混淆树木与建筑物的提取结果,同理,在地形地势起伏较大的区域,也存在着这种问题,因此建筑物中点与点之间的关系信息不能忽略。同时,在考虑点与点之间关系时,往往受困于建筑物不同的几何结构,而人工寻找并定义这些结构费时费力。另一方面,可以借助LiDAR点云的反射强度信息作为辅助信息,在同一栋建筑物上的反射强度常常具有一致性,但是不同建筑物仍然会表现不同的强度信息,甚至与周围地物强度一致,所以无法单独作为判断的依据。再者,点云也可以结合影像的光谱信息作为辅助特征,本文则基于以上信息,分析了不同方法以及不同特征对建筑物提取以及变化检测结果的影响。
使用RandLA-Net结合不同的点云特征提取2时期异源点云中的建筑物,并同时使用传统基于DSM高程阈值的方法与基于软件ENVI LiDAR和TerraScan的建筑物提取方法进行了对比。在基于DSM的方法中,为了尽可能获得最好的结果,对每一块区域单独设置基于人工判断的高度阈值,包括最低、最高与分段的高度阈值。测试区域选取了2017—2019年变化较大的区域,并存在着不同形态的建筑物,如矮于树木的低矮临时建筑物、形状不规则的楼宇以及常见的小区住宅楼等。为了直观表达建筑物提取结果以及便于精度评价,将点云垂直投影为二维图像,并通过分级色彩表达建筑物的高程信息,如表1—2所示。其中,RandLA-Net代表本文使用的方法; I代表训练与测试时,除坐标外使用了反射强度信息作为特征; RGB表示结合了后期赋予点的光谱信息作为特征; IRGB则表示同时加入了强度信息与光谱信息; C代表该数据中每一点云块的坐标转换为最小坐标为0的相对坐标。


图6

一方面,使用传统方法时,本文未对原始点云进行下采样,由TerraScan提取的建筑物在稀疏与密集的点云上表现较为一致,但是目标的边界准确度低,存在着较多的错检情况; 而ENVI LiDAR的结果受点云密度影响较大,难以有效提取2017年点云的建筑物; 使用人工DSM设置高程阈值的方法简单,且不受点云质量差异的影响,但是高耸的树木与地形的起伏使得在处理时要面对树木与低矮建筑物的取舍,同时,为了避免较多的误差,分区域地设置阈值人工成本高,自动化程度低。
另一方面,在使用RandLA-Net算法时,对比了4种情况,考虑到LiDAR点云数据普遍带有反射强度信息,且在早期测试中的结果也反映出带有特征的点云比单纯使用坐标信息的结果要好,因此本文并没有单独使用坐标信息。在设置的组合中,最值得注意的是,在同样只使用强度信息作为特征时,将坐标转换为相对坐标带来的提升效果明显,尤其在对低矮建筑物的提取上,使用相对坐标则有着更完整的建筑物个体与更为准确的建筑物边界。基于RandLA-Net的结果明显好于其他方法,其误差主要在于建筑物本身上,很少存在将树木或其他地物错分为建筑物的情况。精度对比如表3所示。
表3 建筑物提取方法精度对比
Tab.3
| 年份 | 方法 | 准确率/% | 精准率/% | 召回率/% | F1分数 | Kappa系数 |
|---|---|---|---|---|---|---|
| 2017年 | RandLA-Net IRGB C | 98.52 | 88.21 | 97.45 | 92.60 | 0.917 8 |
| RandLA-Net RGB C | 98.49 | 88.83 | 96.45 | 92.48 | 0.916 4 | |
| RandLA-Net I C | 98.32 | 88.15 | 95.45 | 91.65 | 0.907 2 | |
| RandLA-Net I | 97.27 | 92.59 | 83.23 | 87.66 | 0.861 3 | |
| ENVI LiDAR | 91.91 | 24.24 | 94.24 | 38.39 | 0.358 1 | |
| TerraScan | 95.76 | 73.58 | 83.96 | 78.43 | 0.760 9 | |
| DSM高程阈值法 | 93.55 | 88.61 | 63.85 | 74.22 | 0.706 4 | |
| 2019年 | RandLA-Net IRGB C | 98.54 | 86.10 | 97.69 | 91.53 | 0.907 3 |
| RandLA-Net RGB C | 98.94 | 90.30 | 97.93 | 93.96 | 0.933 7 | |
| RandLA-Net I C | 98.59 | 86.67 | 97.72 | 91.86 | 0.910 9 | |
| RandLA-Net I | 94.26 | 38.24 | 97.94 | 55.00 | 0.525 7 | |
| ENVI LiDAR | 97.93 | 86.17 | 90.76 | 88.41 | 0.872 7 | |
| TerraScan | 94.83 | 72.68 | 71.46 | 72.06 | 0.692 2 | |
| DSM高程阈值法 | 97.29 | 77.23 | 91.93 | 83.94 | 0.824 7 |
由表3计算出的各项指标可以看出,基于RandLA-Net算法获得建筑物区域的各项指标均优于ENVI LiDAR,TerraSacn以及DSM高程阈值的方法。对比不同特征的影响,在2017年点云上进行的训练,并同时对2017年与2019年点云进行测试,结果是: 2017年点云同时使用反射强度与光谱信息的结果最好,2019年点云仅使用光谱信息结果最好,2期点云差异如图2所示。因此建议: ①在提取建筑物时,使用格网采样后的2019年点云,仅需加入光谱信息。考虑到LiDAR传感器大多无法同时获取光谱信息,或者相机参数未知及相机参数误差较大,无法利用光谱信息的时候,仅使用强度信息同样可以获得很好的结果,不建议同时加入强度和光谱信息; ②在处理质量较差的2017年点云时,其点云整体无序,则需要更多的特征,此时越丰富的特征带来的效果越好,正如结合了反射强度与光谱信息的2017年点云结果最好。
此外,点云差异如第1.2节所述,使用点的位置、邻近点的位置、2点的相对位置关系以及其欧式距离来表达坐标位置的特征。如图2(b),越是规则的点云其相对位置关系的特征越是一致,这点在RandLA-Net原文中也有阐述。这也解释了在2017年点云上训练的网络在不同特征组合下,2019年的结果会比2017年结果更好的现象。
3.3 LiDAR点云建筑物变化检测

表5 建筑物变化检测结果精度对比
Tab.5
| 方法 | 变化 类型 | 准确 率/% | 精准 率/% | 召回 率/% | F1 分数 | Kappa 系数 |
|---|---|---|---|---|---|---|
| RandLA- Net IRBG C | 增高 | 97.22 | 70.40 | 97.65 | 81.57 | 0.856 6 |
| 降低 | 87.23 | 99.71 | 93.05 | |||
| 新建 | 87.42 | 92.07 | 89.68 | |||
| 拆除 | 77.74 | 79.05 | 78.39 | |||
| RandLA- Net RBG C | 增高 | 97.61 | 82.23 | 97.71 | 89.30 | 0.876 9 |
| 降低 | 88.22 | 98.52 | 93.09 | |||
| 新建 | 87.73 | 93.24 | 90.40 | |||
| 拆除 | 78.91 | 84.54 | 81.63 | |||
| RandLA- Net I C | 增高 | 97.10 | 85.62 | 98.94 | 91.80 | 0.849 2 |
| 降低 | 91.63 | 99.54 | 95.42 | |||
| 新建 | 77.33 | 90.63 | 83.45 | |||
| 拆除 | 78.20 | 82.85 | 80.46 | |||
| RandLA- Net I | 增高 | 91.77 | 31.10 | 96.60 | 47.05 | 0.606 0 |
| 降低 | 36.72 | 100.00 | 53.72 | |||
| 新建 | 38.85 | 94.24 | 55.02 | |||
| 拆除 | 86.21 | 42.94 | 57.33 | |||
| ENVI LiDAR | 增高 | 90.46 | 11.05 | 64.22 | 18.86 | 0.502 4 |
| 降低 | 9.61 | 69.44 | 16.88 | |||
| 新建 | 79.55 | 35.58 | 49.17 | |||
| 拆除 | 30.27 | 88.06 | 45.05 | |||
| TerraScan | 增高 | 91.67 | 33.31 | 80.18 | 47.07 | 0.628 9 |
| 降低 | 21.82 | 73.95 | 33.70 | |||
| 新建 | 67.19 | 36.26 | 47.10 | |||
| 拆除 | 85.90 | 65.65 | 74.42 | |||
| DSM高程阈值法 | 增高 | 91.65 | 84.08 | 88.39 | 86.18 | 0.642 4 |
| 降低 | 71.99 | 100.00 | 83.71 | |||
| 新建 | 63.90 | 81.50 | 71.63 | |||
| 拆除 | 83.83 | 41.62 | 55.62 |
由变化检测结果与指标的计算结果可知,使用RandLA-Net方法获得的结果明显优于传统方法,其中使用光谱信息与相对坐标的点云获得最优的变化检测结果,而不是加入所有的特征。同时,使用相对坐标比使用绝对坐标的变化检测结果精度提升明显,而且在仅使用强度信息与相对坐标时的结果与最好的结果差异较小,这些与上一阶段提取建筑物结果的结论基本一致。
但是明显的问题是存在2期建筑物边界不完全重合的情况,即使在原始数据上也存在着边界的粗差,虽然对指标的计算影响较小,但是在实际应用时仍然有着一定问题。其主要原因在于: 原始点云的差异,如图2所示的点云结构,使得2期点云表达的建筑物存在偏差。面对此种问题的处理可使用形态学的后处理方法,但本文为了表现实验过程中的真实性,并未进行过多的后处理。
4 结论与展望
为了同时实现建筑物的面积与高程定性定量的变化检测,使用机载LiDAR点云数据制作建筑物点云语义分割数据集,并基于深度学习方法RandLA-Net的点云语义分割网络提取建筑物,利用点云的语义分割结果投影为二维影像并进行分类后检测。本研究得出以下结论:
1)使用的RandLA-Net算法在建筑物提取与变化检测上的总体精度优于常用的软件与DSM分析的方法。
2)在对点云的数据预处理上,使用相对坐标要比使用绝对坐标结果好。
3)在对点云特征的取舍上,过多的特征会造成冗余,仅使用光谱或强度信息时获得的变化检测结果有时要好于两者结合的结果,结合成本分析,仅使用LiDAR点云特有的强度信息是最佳方案。
虽然使用的RandLA-Net算法获得了很好的建筑物提取与变化检测效果,但是仍然存在由点云差异而影响建筑物边界精度的问题。本文仅使用了较少的建筑物样本进行训练,且只使用了2017年的点云进行训练与验证,在之后的研究中会增加点云中目标的样本,通过上下采样增加点云结构化程度; 同时优化算法与数据组成,提高模型在异源点云数据上的泛化能力,改善异源点云数据的变化检测精度; 未来会加入点云法向量作为特征,进一步提高点云语义分割的性能。
参考文献
Change detection of buildings using an airborne laser scanner
[J].DOI:10.1016/S0924-2716(99)00006-4 URL [本文引用: 1]
LiDAR-based change detection of buildings in dense urban areas
[C]//
Object-based analysis of airborne LiDAR data for building change detection
[J].DOI:10.3390/rs61110733 URL [本文引用: 1]
Developing an algorithm for buildings extraction and determining changes from airborne LiDAR,and comparing with R-CNN method from drone images
[J].DOI:10.3390/rs11111272 URL [本文引用: 1]
基于LiDAR点云的城区地表变化检测
[J].
Urban land surface change detection based on LiDAR point cloud
[J].
Automatic detection of buildings and changes in buildings for updating of maps
[J].DOI:10.3390/rs2051217 URL [本文引用: 1]
Urban changes with satellite imagery and LiDAR data
[J].
Building change detection using old aerial images and new LiDAR data
[J].DOI:10.3390/rs8121030 URL [本文引用: 1]
Fully convolutional networks for semantic segmentation
[J].
DOI:10.1109/TPAMI.2016.2572683
PMID:27244717
[本文引用: 1]

Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixels-to-pixels, improve on the previous best result in semantic segmentation. Our key insight is to build "fully convolutional" networks that take input of arbitrary size and produce correspondingly-sized output with efficient inference and learning. We define and detail the space of fully convolutional networks, explain their application to spatially dense prediction tasks, and draw connections to prior models. We adapt contemporary classification networks (AlexNet, the VGG net, and GoogLeNet) into fully convolutional networks and transfer their learned representations by fine-tuning to the segmentation task. We then define a skip architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations. Our fully convolutional networks achieve improved segmentation of PASCAL VOC (30% relative improvement to 67.2% mean IU on 2012), NYUDv2, SIFT Flow, and PASCAL-Context, while inference takes one tenth of a second for a typical image.
Very deep convolutional networks for large-scale image recognition
[J/OL].
Segnet:A deep convolutional encoder-decoder architecture for image segmentation
[J].
DOI:10.1109/TPAMI.2016.2644615
PMID:28060704
[本文引用: 1]
We present a novel and practical deep fully convolutional neural network architecture for semantic pixel-wise segmentation termed SegNet. This core trainable segmentation engine consists of an encoder network, a corresponding decoder network followed by a pixel-wise classification layer. The architecture of the encoder network is topologically identical to the 13 convolutional layers in the VGG16 network [1]. The role of the decoder network is to map the low resolution encoder feature maps to full input resolution feature maps for pixel-wise classification. The novelty of SegNet lies is in the manner in which the decoder upsamples its lower resolution input feature map(s). Specifically, the decoder uses pooling indices computed in the max-pooling step of the corresponding encoder to perform non-linear upsampling. This eliminates the need for learning to upsample. The upsampled maps are sparse and are then convolved with trainable filters to produce dense feature maps. We compare our proposed architecture with the widely adopted FCN [2] and also with the well known DeepLab-LargeFOV [3], DeconvNet [4] architectures. This comparison reveals the memory versus accuracy trade-off involved in achieving good segmentation performance. SegNet was primarily motivated by scene understanding applications. Hence, it is designed to be efficient both in terms of memory and computational time during inference. It is also significantly smaller in the number of trainable parameters than other competing architectures and can be trained end-to-end using stochastic gradient descent. We also performed a controlled benchmark of SegNet and other architectures on both road scenes and SUN RGB-D indoor scene segmentation tasks. These quantitative assessments show that SegNet provides good performance with competitive inference time and most efficient inference memory-wise as compared to other architectures. We also provide a Caffe implementation of SegNet and a web demo at http://mi.eng.cam.ac.uk/projects/segnet.
Deep residual learning for image reco-gnition
[C]//
U-Net:Convolutional networks for biomedical image segmentation
[C]//
Faster R-CNN:Towards real-time object detection with region proposal networks
[J].DOI:10.1109/TPAMI.2016.2577031 URL [本文引用: 1]
Feature pyramid networks for object detection
[C]//
基于Faster R-CNN的高分辨率图像目标检测技术
[J].
Research on high resolution image object detection technology based on Faster R-CNN
[J].
基于改进U-Net的建筑物集群识别研究
[J].
Research on building cluster identification based on improved U-Net
[J].
基于多层次感知网络的GF-2遥感影像建筑物提取
[J].
Buildings extraction of GF-2 remote sensing image based on multi-layer perception network
[J].
基于DeepLabv3+语义分割模型的GF-2影像城市绿地提取
[J].
Urban green space extraction from GF-2 remote sensing image based on DeepLabv3+ semantic segmentation model
[J].
基于Faster R-CNN的火电厂冷却塔检测及工作状态判定
[J].
The detection and determination of the working state of cooling tower in the thermal power plant based on Faster R-CNN
[J].
Deep learning for 3D point clouds:A survey
[J].DOI:10.1109/TPAMI.2020.3005434 URL [本文引用: 1]
Pointnet:Deep learning on point sets for 3D classification and segmentation
[C]//
Squeezeseg:Convolutional neural nets with recurrent CRF for real-time road-object segmentation from 3D LiDAR point cloud
[C]//
Kpconv:Flexible and deformable convolution for point clouds
[C]//
RandLA-Net:Efficient semantic segmentation of large-scale point clouds
[C]//

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}