

0 引言
近年来,特征优选在农作物遥感分类中得到了不同程度的应用,为更好地识别出农作物提供了可能。RF_RFE由于能够量化每个变量的相对重要性,通常被用于高维的特征优选。梁继等[7]采用RF_RFE算法分析了不同特征对农作物识别的重要程度,筛选出有利于农作物识别的特征,提高了农作物分类的精度和效率。周小成等[8]使用RF_RFE算法优选出有利于林地信息提取的特征,实现了基于无人机数据对竹林、针叶林和阔叶林的分类识别。Relief F是经典的过滤式特征选择算法,在特征优选中具有运算速度快、泛化能力强等特点。刘家福等[9]基于Landsat8数据研究提取滨海湿地信息时,发现基于Relief F算法结合随机森林(random forest,RF)分类器具有高精度、高效率的优势。刘莹等[10]通过Relief F算法对Landsat8数据的71个特征进行特征优选,然后结合SVM分类器有效的识别出城市的不透水面覆盖面积。张东彦等[11]在对安徽北部平原的大豆区进行提取时,使用Relief F算法提取特征,并对比了RF、反向传播神经网络(back-propagation,BP)、支持向量机(support vector machine,SVM)等3种分类器的分类效果,结果表明RF分类器结合Relief F算法的识别结果更加接近真实情况。基于相似性的特征优选(correlation-based feature selection,CFS)算法是用来综合评价特征与分类结果之间的相关性和特征之间冗余度的方法。张文博等[12]对比了CFS算法和Relief F算法提取旱区植被的分类效果,结果表明CFS算法能够在保证较少特征的同时具备较高的分类精度。
综上所述,在基于遥感数据多特征优选的分类识别研究中,分类特征的选择固然重要,但还存在盲目性和不稳定性,对不同的地物识别效果差异也较大,不同的特征优选方法适用于何种遥感数据和分类场景尚未形成统一的定论。本研究以滁州市全椒县为研究区,借助GEE平台,基于Sentinel-2卫星数据构建多时相多维遥感特征,选用RF_RFE,Relief F,CFS这3种特征优选算法,探究不同的特征优选算法在农作物分类中的效果优劣,并确定可用于农作物种植类型识别的最佳特征优选方法; 在此基础上,通过与其他的分类方法比较,进一步探究最佳特征优选算法在不同分类器中的识别农作物种植结构的性能差异。
1 研究区概况与数据源
1.1 研究区概况
全椒县地处安徽省滁州市的最南端,E117°48'~118°24'、N31°50'~32°14'之间。位于江淮分水岭和滁河之间,为亚热带季风气候,年平均气温范围为11.4~16.6 ℃。北部为山区,海拔最高396 m,南部为平原带,东部为主城区,上半年以种植小麦、油菜为主,下半年以种植水稻为主,地理位置及样本点分布如图1所示。
图1
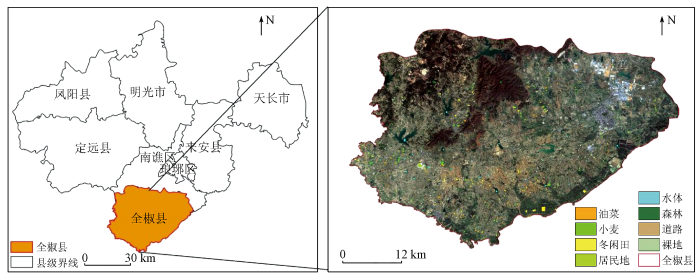
图1
研究区地理位置及其样本分布
Fig.1
Geographical location of the study area and its sample distribution
1.2 数据源与预处理
1.2.1 Sentinel-2影像数据
相较于GF-2卫星数据和Landsat卫星数据,Sentinel-2卫星数据具有重访周期短、分辨率高的综合优势,且具备对农作物分类有重要影响的红边特征。依据全椒县农作物的物候特征(表1)以及相关的前期研究,选择农作物的返青期2022年2月25日、拔节期2022年3月12日、孕穗期2022年4月21日共3景Sentinel-2多光谱数据作为数据源。在GEE中选择的Sentinel-2数据是经过辐射定标和几何校正的Level-1C产品,其中包含13个光谱波段,本文剔除掉气溶胶、水蒸气以及卷云波段这3个无关波段,并利用QA60波段进行去云掩模操作,除去卷云和厚云的影响,最终得到3个时相的全椒县Sentinel-2无云影像。
表1 全椒县午季农作物生长周期
Tab.1
| 时间 | 10月 | 11月 | 12月 | 来年1月 | 2月 | 3月 | 4月 | 5月 | 6月 | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 上 | 中 | 下 | 上 | 中 | 下 | 上 | 中 | 下 | 上 | 中 | 下 | 上 | 中 | 下 | 上 | 中 | 下 | 上 | 中 | 下 | 上 | 中 | 下 | 上 | 中 | 下 | |
| 小麦 | 播种 | 出苗 | 分藥 | 越冬 | 返青 | 拔节 | 孕穗 | 成熟 | |||||||||||||||||||
| 油菜 | 播种 | 移栽 | 越冬 | 现蕾 | 初花 | 中花 | 成熟 | ||||||||||||||||||||
| 冬闲田 | 水稻成熟 | 空闲 | 水稻播种 | 移栽 | |||||||||||||||||||||||
1.2.2 样本数据
本文根据全椒县实地调查情况,将研究区土地覆盖类型分为居民地、道路、裸地、冬闲田、小麦、油菜、水体和森林8类,并于2022年2月24日—2022年2月26日对研究区开展地面调查,获取各种地物样本以及农作物的类型、种植结构、地理位置并拍照记录。共获得512个样本数据,其中居民地68个、道路23个、裸地27个、冬闲田76个、小麦105个、油菜148个、水体26个、林地39个,具体的样本分布情况如图1所示。本文将样本数据按照7∶3的比例随机分为训练样本和验证样本。
2 研究方法
基于GEE平台提取全椒县农作物种植类型的具体流程如图2所示。首先通过GEE平台获取并处理覆盖全椒县的Sentinel-2数据,从中提取出光谱特征、纹理特征、植被指数特征。然后采用RF_RFE,Relief F,CFS对多时相、多维遥感特征进行优选,分析不同特征在农作物识别中的重要性程度,并采用混淆矩阵方法评估分类精度确定最佳的特征优选算法。在此基础上,对比RF,SVM、最小距离分类(minimum distance classification,MDC)3种分类方法,探究最佳特征优选算法在不同分类器中的性能差异,采用全国第二次土地调查数据中的耕地范围对分类结果做掩模处理,并将非农作物类型合并在一起,只分析农作物的识别结果。
图2
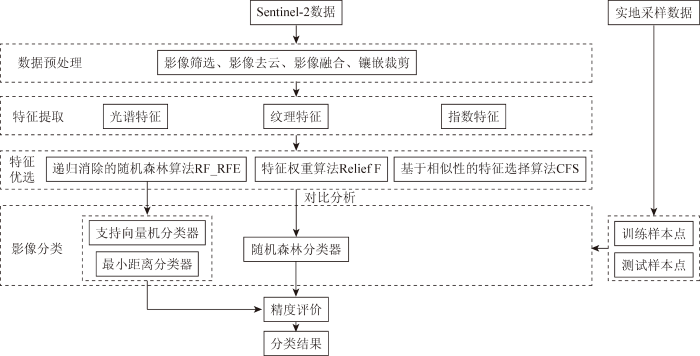
图2
研究区农作物信息提取的技术流程图
Fig.2
Technical flow chart of crop information extraction in the study area
2.1 特征集构建
为了分析不同的特征对农作物遥感识别的影响,提高农作物的识别精度,本文选择光谱特征、植被指数特征、纹理特征等共计90个特征构成数据集,详见表2。表中,光谱特征直接选择每个时相影像的10个原始波段,3个时相的影像共计30个光谱特征。植被指数中,红边波段是哨兵数据特有的,且红边指数特征对植被更加敏感。本文不仅考虑常规植被指数,而且加入了6个与农作物生长过程有关的红边指数,分3个时相共计18个无红边植被特征和18个红边植被指数特征。
表2 农作物遥感识别特征集
Tab.2
| 特征变量 | 指数 | 特征公式及说明 | 参考文献 | 特征数目 |
|---|---|---|---|---|
| 光谱特征 | B* | B2,B3,B4,B5,B6,B7,B8,B8A,B11,B12 | 30 | |
| 传统植被指数 | 归一化植被指数(NDVI) | NDVI=(B8-B4)/(B8+B4) | Ni等[13] | 18 |
| 陆地表面水分指数(LSWI) | LSWI=(B8-B11)/(B8+B11) | Ni等[13] | ||
| 增强型植被指数(EVI) | EVI=2.5(B8-B4)/(B8+6B4-7.5B2+1) | Ni等[13] | ||
| 土壤调整植被指数(SAVI) | SAVI=(B7-B3)/(B7+B3-0.5)*(1+0.5) | 王李娟等[14] | ||
| 比值植被指数(RVI) | RVI=B7/B3 | 王李娟等[14] | ||
| 归一化差异耕作指数(NDTI) | NDTI=(B11-B12)/(B11-B12) | 熊皓丽等[15] | ||
| 红边指数特征 | 归一化植被指数红边1(NDVIre1) | NDVIre1=(B8A-B5)/(B8A+B5) | 张磊等[16] | 18 |
| 归一化植被指数红边2(NDVIre2) | NDVIre2=(B8A-B6)/(B8A+B6) | 张磊等[16] | ||
| 归一化植被指数红边3(NDVIre3) | NDVIre3=(B8A-B7)/(B8A+B7) | 张磊等[16] | ||
| 新型倒红边叶绿素指数(IRECI) | IRECI=(B7-B4)/(B5/B6) | 熊皓丽等[15] | ||
| 红边叶绿素指数(Cire) | Cire=B7/B5-1 | 王李娟等[14] | ||
| 地面叶绿素指数(MTCI) | MTCI=(B6-B5)/(B5-B4) | 熊皓丽等[15] | ||
| 纹理特征 | Contrast | 对比度 | 张磊等[16]、熊皓丽等[15] | 24 |
| Asm | 角二阶矩 | |||
| Corr | 相关性 | |||
| Idm | 逆差距 | |||
| Ent | 熵 | |||
| Var | 方差 | |||
| Dvar | 差方差 | |||
| Diss | 不相似性 | |||
| 总计 | 90 |
2.2 特征优选方法
2.2.1 基于RF_RFE算法的特征优选
基于RF_RFE算法的特征优选方法如下: 首先,对于随机森林中的每一个决策树而言,使用相应的袋外数据来计算袋外误差,记作errOOB1; 然后,随机地对袋外数据OOB所有样本的特征X加入噪声干扰,再计算其袋外数据误差,记作errOOB2; 最后,计算特征重要性X,计算公式如下:
式中N为树的个数,式中X的值越高,则说明特征X越重要[8]。把需要的特征子集初始化为整个特征子集,每次剔除掉重要性分数最低的数据,直到获得最后的特征集。
2.2.2 基于Relief F算法的特征优选
Relief F算法是根据样本邻近原则,赋予不同特征的权重。具体步骤如下: ①选择特征样本,从样本集中随机选择一个样本X,从不同类中找到一个最近邻的样本Y,从同类的样本中找到一个最近邻的样本Z。②计算特征权重,在某个特征的条件下,比较X与Y之间的距离和X与Z之间的距离大小; 如果不同类之间的距离较大,说明该特征容易区分,增加特征的权重; 反之,则减少特征的权重。③重复上面的步骤,求取各个特征权重的平均值,特征权重越大代表该类的区分能力较强[19]。
2.2.3 基于CFS算法的特征优选
基于相似性的特征选择是过滤式选择的一种的方法,该方法的核心是采用启发的方式评估特征子集的价值,该方法假设思想是: 好的特征子集包含与类高度相关的特征,但特征之间彼此不相关。启发方程式为:
式中: Merittk为包含k个特征子集t的启发值; Zcf为特征与类之间的相关性的平均值; Zff为特征与特征之间的相关性; Z为相关系数。启发值越大代表这个特征的分类效果越好[12]。
2.3 随机森林分类
随机森林分类是集成分类的一个子类,它依靠决策树投票选择来决定最后的分类结果,将若干个弱分类器的分类结果进行投票选择,从而组成强分类器。其具体操作步骤包括以下几个方面: 首先,在原始的样本中,随机且有放回地抽取N(约为总体样本集的2/3)个训练样本组成训练样本集,剩余的1/3样本作为袋外数据进行内部交叉验证; 然后,根据抽取的样本集分别建立N棵决策树组成的随机森林,每个决策树随机抽取M个特征,采用基尼系数最小的原则进行节点分裂; 最后,将生成的多颗决策树组成随机森林分类器,采用投票的方式决定新样本的类别[20]。
2.4 精度评价方法
根据地面实测样本数据,采用混淆矩阵来评估不同模型的分类效果。使用制图精度来反映分类中的漏分误差、使用用户精度来反映分类中的错分误差。通过Kappa系数来评估不同分类模型的优劣,其计算公式如下:
式中: N为像元的总数; m为类别数;
3 结果与分析
3.1 特征重要性分析
本文共选择了90个特征参与全椒县的农作物遥感提取,通过GEE平台以及分类样本的特征值,结合RF_RFE,Relief F,CFS这3种特征优选算法分别计算出相应的特征重要性。为了避免传统阈值方法的人为主观性影响,本文参考前人已有的研究[18],根据特征重要性大小对不同特征进行降序排列,并从中选出前50个特征组成特征集进行实验。每次从特征集中删除一个特征重要性排在最后的特征,并将保留下来的特征子集用于农作物分类和计算分类精度。重复以上过程,通过逐次迭代计算,从而最终确定特征优选结果变量数目与分类精度之间的关联关系。为了方便统一比较,这里都选择RF作为特征优选后特征子集的分类器,保留下来的特征子集需要确保分类精度较高但特征个数较少,不同特征子集的特征个数对应的Kappa系数见图3。
图3
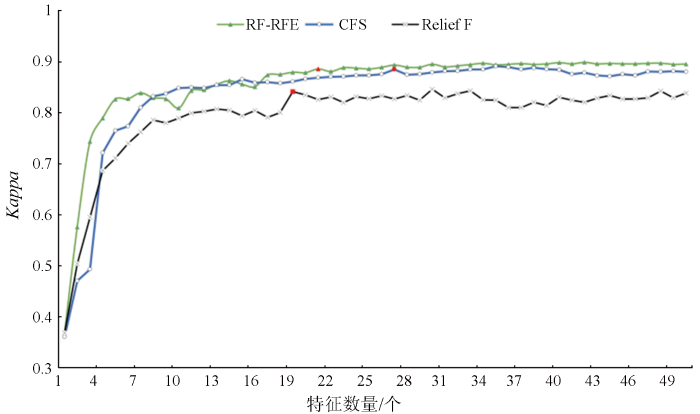
图3
不同特征数目下的Kappa系数
Fig.3
The Kappa coefficient for different numbers of features
表3 3种优选结果的特征分布
Tab.3
| 特征 | 2022/02/25 | 2022/03/12 | 2022/04/21 | 特征个数 |
|---|---|---|---|---|
| Relief F | LSWI0225,NDTI0225, pc1_dvar0225,pc1_diss0225, pc1_contrast0225 | NDTI0312,NDVIre30312, LSWI031,pc1_dvar0312, pc1_diss0312,pc1_contrast0312 | B110421,NDVIre20421, NDVI0421,NDTI0421,LSWI0421, pc1_diss0421,pc1_dvar0421, pc1_cotrast0421 | 19 |
| CFS | B30225,EVI0225,LSWI0225, pc1_var0225,pc1_corr0225, MTCI0225 | B30312, B40312,B50312, NDVIre30312,MTCI0312, EVI0312,NDVIre20312, pc1_corr0312, pc1_contrast0312,pc1_var0312 | B50421,B8A0421,B110421, LSWI0421,MTCI0421, B40421, NDTI0421,EVI0421, NDVIre20421,pc1_corr0421, NDVIre30421 | 27 |
| RF_RFE | B20225,B110225,LSWI0225, NDTI0225 | B20312, B30312,B50312,B60312,B110312, pc1_idm0312,NDTI0312, EVI0312 | B20421,B30421,B50421,B60421, B8A0421,B70421,B110421, B120421,NDVIre20421 | 21 |
从表3中可以看出(表中特征名以特征加时间命名,如B20225代表2022年2月25日影像的B2波段,同一个特征在不同的特征优选算法里面出现至少2次的用斜体显示),3种特征优选算法在4月份的特征数量最多,是农作物提取的最佳时相,其原因是4月份是小麦和油菜的孕穗期和中花期,两者之间的形态和光谱反射都会产生较大的差异,易于辨识区分。其次是3月份,此时的小麦和油菜正处于拔节期和初花期,此阶段小麦和荒地之间有一定的差异。2月份的小麦和油菜正处于拔节期和现蕾期,小麦和油菜刚有成长,处于苗期,而树林处于长势茂盛期,易于区分,此时间段容易产生“同谱异物”的现象,对分类结果存在一定的干扰。表3中有13个特征至少被2种优选算法同时优选出来,表明这13个特征在分类中起到重要作用,有利于农作物的识别。这些重要的特征在RF_RFE算法、Relief F算法、CFS算法优选的特征集中分别占比47.61%,42.10%和40.74%。因此,相比于Relief F和CFS,RF_RFE在Kappa系数和优选出的特征稳定性上均有利于农作物的地物分类。
对于RF_RFE算法,优选出来的特征集的特征重要性得分如图4所示。在优选的特征中,原始光谱特征占比最多,21个特征中包含15个原始光谱特征,其中的短波红外B11和B12共出现4次,表明短波红外的加入能够在一定程度上提高农作物的分类精度。其次,B5,B6,B7相关的红边特征在农作物分类中也起到了重要的作用。此外,纹理特征中的逆差距有利于农作物的分类,展现出较好的分类效果。
图4
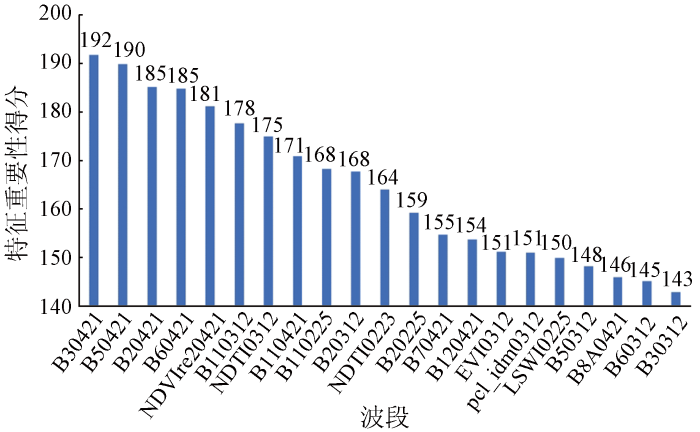
图4
特征名称及其对应的重要性得分
Fig.4
The importance score for feature names and their correspondings
3.2 不同特征优选方法下RF分类精度对比
为了比较3种不同的特征优选方法在农作物分类中的效果,本文以RF分类器为例进行实验研究,表4展示了3种不同特征优选方法在RF下的分类结果,表中3种分类结果的Kappa系数均高于0.83。RF_RFE的分类精度最高,在特征数目为21时,总体精度为92%,Kappa系数为0.89。其余的特征优选算法Kappa系数略低于RF_RFE,从相同的RF分类器下,对比不同的特征优选方法来看,Relief F在特征变量19个时,总体精度和Kappa系数分别为0.83和0.88,相比于RF_RFE算法,特征维度减少了2个,但是总体精度和Kappa系数分别降低了4%和5%。CFS相比于RF_RFE,在Kappa系数略微降低0.01,同时在特征上多使用了6个特征参加计算。从用户精度和生产者精度来看,小麦均高于油菜,说明小麦的可分离性要优于油菜。在RF_RFE算法中,小麦和油菜的精度均达到了最大值,其中,小麦的生产者精度和用户精度分别为96.2%和93.2%,油菜的生产者精度跟用户精度分别为83.5%和88.8%。为了能够更加清楚地知道分类结果,本文将其与2022年3月2日的高分一号卫星多光谱与全色的融合影像进行对比(表5)。
表4 基于不同特征优选方法和随机森林的地物分类精度
Tab.4
| 不同的特征 优选方法 | RF_RFE | CFS | Relief F | |||
|---|---|---|---|---|---|---|
| 评价指标 | PA/% | UA/% | PA/% | UA/% | PA/% | UA/% |
| 油菜 | 83.5 | 88.8 | 83.0 | 88.7 | 80.0 | 82.9 |
| 小麦 | 96.2 | 93.2 | 95.0 | 92.5 | 94.1 | 91.9 |
| OA/% | 91.7 | 91.5 | 87.71 | |||
| Kappa | 0.89 | 0.88 | 0.83 | |||
表5 不同特征优选方法的局部结果图
Tab.5
| 数据 | 样地一 | 样地二 | 样地三 | |
|---|---|---|---|---|
| 高分一号 |  | |||
| Relief F |  | |||
| CFS |  | |||
| RF_RFE | 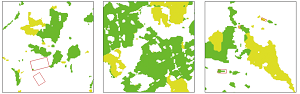 | |||
 | ||||
由表5可知,从高分一号融合影像上看,油菜和小麦在影像上呈现不一样的色调。从RF的3种分类方法的局部结果图中看,样地一表示破碎地块的农作物分类结果,从中可以看出Relief F出现错分,误分的情况较为严重,部分居民地旁边的冬闲田被错误识别为小麦,CFS和RF出现这种现象的程度较轻。样地二表示地块较完整的农作物分类结果,3种分类结果中有部分将田埂、道路错分为农作物的现象,导致这种现象的原因是10 m分辨率的Sentinel-2数据存在混合像元现象。但从整体上来看3个分类结果都较为准确的识别出农作物,局部的差异较小。样地三表示林地附近的农作物分类结果,其中Relief F和CFS都出现漏分现象,对图中红色标记内的农作物,未能准确的识别处理,而RF能够较完整的识别农作物。综上所述,将RF_RFE作为最佳的优选特征,主要有以下2个原因: ①从分类的精度来看,RF_RFE算法在不同的特征优选结果中各项分类指标都最高,且特征个数也偏少; ②从分类效果来看,分类结果中出现较少的错分或漏分的程度最轻。
3.3 不同机器学习分类对农作物识别精度的影响
图5
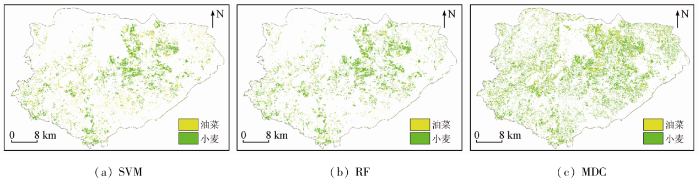
图5
RF_RFE下基于不同机器学习方法的研究区农作物空间分布
Fig.5
Spatial distribution of crops in the study area based on different machine learning methods under RF_RFE
对比不同分类方法的分类精度(表6)可知,RF的分类精度表现较为优越,总体精度比SVM和MDC分别高0.7百分点和30.5百分点; Kappa系数比SVM和MDC分别高 0.01和0.41,表明SVM和RF更适用于研究区的地物分类。在RF分类器下,小麦和油菜的用户精度和生产者精度均高于83.5%。小麦的生产者精度和用户精度和油菜的用户精度均达到最大值96.2%,93.2%和88.8%; 在油菜的生产者精度略比SVM低1.2百分点,从数值上来看,除了RF在油菜的生产者精度小于SVM以外,其余的分类精度均大于SVM。综上所述可知,3种机器学习分类方法中,RF在农作物信息提取的分类结果上与SVM分类结果相近,在总体精度上略高于SVM,而MDC 分类算法不适合高维度、大数据量的分类,对比可知,RF分类算法可以有效的识别出农作物。
表6 RF_RFE特征优选下基于不同机器学习分类的农作物分类精度
Tab.6
| 机器学习方法 | RF | SVM | MDC | |||
|---|---|---|---|---|---|---|
| 评价指标 | PA/% | UA/% | PA/% | UA/% | PA/% | UA/% |
| 油菜 | 83.5 | 88.8 | 84.7 | 83.0 | 80.3 | 63.5 |
| 小麦 | 96.2 | 93.2 | 91.1 | 91.3 | 70.8 | 65.4 |
| OA/% | 91.7 | 91.0 | 61.2 | |||
| Kappa | 0.89 | 0.88 | 0.48 | |||
4 结论与讨论
4.1 结论
1)根据RF_RFE的特征重要性得分可知,不同的特征影响着农作物的识别精度,各类特征的得分值从高到低排列依次是光谱特征、红边特征、传统植被指数特征、纹理特征。其中短波红外波段B11和B12,红边波段B5和B6对农作物的识别具有重要的作用。
2)对比RF分类器下的不同的特征优选方法的分类精度。基于RF_RFE的特征优选算法的分类精度最高,总体精度为92%,Kappa系数为0.88,且将特征维度从90维降低到21维。
3)基于相同的RF_RFE特征优选的条件下,RF的Kappa系数比SVM,MDC分别高0.01和0.41,在分类结果中,RF相比于其他的分类,存在较少的错分和漏分现象。因此,RF结合RF_RFE算法是适用于农作物种植结构信息提取的方法。
4.2 讨论
本文基于从Sentinel-2卫星数据中提取的多时相、多维度遥感特征,采取不同的特征优选算法结合RF分类器实现对全椒县的农作物种植结构信息提取。选择有关农作物生理状况和形态结构的特征构造出多维特征,使用RF_RFE,Relief F和CFS计算出不同特征的重要性,依次消除特征重要性最小的特征,避免了采用传统的阈值方法在判定最佳维度时存在的主观性。B3,B5,B8A,B11,NDVI,NDTI,LSWI,EVI和pc1_contrast在至少2种特征优选方法中出现过,表明红边、短波红外以及纹理特征在农作物种植结构识别中具有显著优势,这与文献[7,10,14]的研究结论一致。在特征子集相同的条件下,通过对比不同的机器学习分类方法,证明了RF结合RF_RFE算法在农作物种植结构的信息提取中的有效性。对于接下来的研究中,能否基于多时相多特征的特征优选算法,结合高分辨率遥感影像并推广应用到其他地区需要进一步探究。
参考文献
基于遥感信息与作物模型集合卡尔曼滤波同化的区域冬小麦产量预测
[J].
Regional winter wheat yield forecasting based on assimilation of remote sensing data and crop growth model with Ensemble Kalman method
[J].
中国农业遥感技术应用现状及发展趋势
[J].
DOI:10.11924/j.issn.1000-6850.casb20190700361
[本文引用: 1]

在中国农业遥感技术应用现状梳理基础上,分析遥感技术应用发展的趋势和不足,提出农业遥感技术应用的发展趋势,为遥感技术在农业领域的深入应用提供参考依据。对文献、政策进行整理及归纳分析,并结合国内外进展的对比,从中国农业遥感技术的重要性、应用水平、发展趋势、应用前景等方面进行总结,并提出相应的建议。结果表明,在遥感(RS)、地理信息系统(GIS)、全球定位系统(GPS)的技术支撑下,国内对农业遥感技术需求是迫切的,农业遥感技术应用也比较广泛;农业遥感技术应用研究发展迅速,取得长足的进步,发展趋势呈现基础性、整体性、系统性等特点。但与世界先进水平相比,中国农业遥感技术应用仍然处于相对滞后的状态,需要突出基础理论研究、强化关键技术的应用普适性,加强国家宏观统筹,进一步提高农业遥感技术应用水平,促进农业数字化水平的提高。
Application status and development trend of agriculture remote sensing technology application in China
[J].
农作物遥感分类特征变量选择研究现状与展望
[J].
Review of features selection in crop classification using remote sensing data
[J].
基于支持向量机的乾安县土地利用遥感分类研究
[J].
Land use information extraction based on support vector machine using multitemporal remote sensing in Qian’an County
[J].
基于Sentinel-2A/B时序数据与随机森林算法的农耕区土地利用分类
[J].
Land use classification of farming areas based on time series Sentinel-2A/B data and random forest algorithm
[J].
基于MODIS EVI的江汉平原油菜和冬小麦种植信息提取研究
[J].
A study of information extraction of rape and winter wheat planting in Jianghan Plain based on MODIS EVI
[J].
高分六号红边特征的农作物识别与评估
[J].
Crop recognition and evaluationusing red edge features of GF-6 satellite
[J].
基于多特征优选的无人机可见光遥感林分类型分类
[J].
Classification of forest stand based on multi-feature optimization of UAV visible light remote sensing
[J].
基于特征优选的随机森林模型的黄河口滨海湿地信息提取研究
[J].
Information extraction of coastal wetlands in Yellow River Estuary by optimal feature-based random forest model
[J].
基于特征优选与支持向量机的不透水面覆盖度估算方法
[J].
A method for estimating impervious surface percentage based on feature optimization and SVM
[J].
结合Sentinel-2影像和特征优选模型提取大豆种植区
[J].
Extraction of soybean planting areas combining Sentinel-2 images and optimized feature model
[J].
面向对象的旱区植被遥感精细分类研究
[J].
Fine vegetation classification of remote sensing in arid areas based on object-oriented method
[J].
An enhanced pixel-based phenological feature for accurate paddy rice mapping with Sentinel-2 imagery in Google Earth Engine
[J].
基于特征优选随机森林算法的农耕区土地利用分类
[J].
Classification of land use in farming areas based on feature optimization random forest algorithm
[J].
基于GEE云平台的福建省10 m茶园专题空间分布制图
[J].
Mapping the spatial distribution of tea plantations with 10 m resolution in Fujian Province using google earth engine
[J].
Sentinel-2影像多特征优选的黄河三角洲湿地信息提取
[J].
Wetland mapping of Yellow River Delta wetlands based on multi-feature optimization of Sentinel-2 images
[J].
Textural features for image classification
[J].
基于改进分离阈值特征优选的秋季作物遥感分类
[J].
Remote sensing classification of autumn crops based on hybrid feature selection model combining with relief F and improved separability and thresholds
[J].
基于特征优选的面向对象毛竹林分布信息提取
[J].
Mapping of moso bamboo forest using object-based approach based on the optimal features
[J].
On the importance of training data sample selection in random forest image classification:A case study in peatland ecosystem mapping
[J].DOI:10.3390/rs70708489 URL [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}