

0 引言
在地理学研究领域,数据的精确度常被定义为观测值或计算值与真实值之间的近似程度,因此,在对空间数据产品进行精度评价时,应以一个误差为零的数据作为真实值; 但由于地表对象演进的连续性和复杂性,其绝对状态难以获取,因而数据不确定性的概念被引入到空间数据质量评估中[3]。不确定性是一个比误差和精度更普遍的概念,对遥感分类任务而言,确定性可以看作是分类器对已分配标签的确信程度,过去研究中常使用的误差和精度则可以理解为不确定性的2种表达形式[4]。了解不确定性指标在农作物遥感分类结果中的局部强度有助于量化和评估制图质量在空间上的变化,并允许反向追踪农作物类型识别有误的特征区域,进一步提高后续建模的可靠性,因此具有重要意义。
在定性分析的基础上,已有多种方法用于遥感分类不确定性的定量评价。综合而言可划分为影像整体尺度、地物类型尺度和像元尺度3类[10]。其中,影像整体尺度和地物类型尺度方法均为基于误差矩阵的统计分析,存在以下局限性: 其一,误差矩阵无差别综合了所有像元的分类结果,而忽略不同像元对于总体不确定性的贡献度差异; 其二,误差矩阵及其衍生指标不具备提供不确定性空间分布信息的能力,与空间属性明显的遥感地学分析情境不符[11-12]。对此,Goodchild 等[13]在贝叶斯分类过程中,曾提出一种基于后验概率向量的计算方法,用于模拟整个分类区域像元尺度的不确定性。在此基础上, Brown等[14]结合信息熵理论提出了概率熵; Comber[15]开发了一种地理加权方法来估计局部精度; Khatami 等[16]利用机器学习分类算法中的分类置信度表达类型不确定性; Immitzer等[17]使用随机森林算法进行分类,通过输出类型的投票数与分类树总数的比例来表达类型不确定性,并指出随机森林算法可以提供有意义的类型不确定性信息。较之混淆矩阵中得出的准确度,上述方法基于像素或区域尺度提供了类型不确定性的空间信息,有助于理解误差的空间分配。
然而,在空间表达过程中,传统基于像元或多尺度分割对象的农业遥感制图结果与真实地理实体相脱节,导致计算过程不可控、结果难以验证,是不确定性的主要来源之一。与之相比,耕地地块作为人类利用土地资源开展农耕活动的基本单元,可真实表征耕作区域空间形态、作物类型及生长状况。因此,基于不规则地块的表达方式有望弥补上述缺陷,促使计算过程收敛、结果可信。然而,目前鲜有将地块作为整体研究对象的不确定性分析研究。为探索该问题,本文参考像元尺度的不确定性分析思路,面向农作物遥感分类问题尝试开展地块尺度的不确定性分析。
1 研究方法
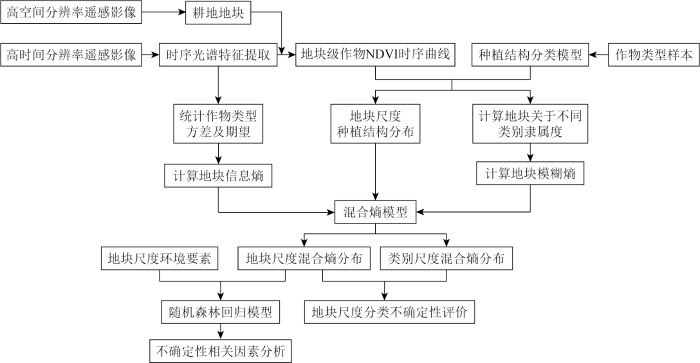
基于上述研究目标,本文提出如下总体研究思路: 首先通过机器学习方法获取地块边界和农作物类型信息,然后以混合熵原理为基础,综合随机性和模糊性开展地块尺度的农作物分类不确定性评价,并在此基础上分析不同地理环境变量对该不确定性空间分布模式的影响。具体研究路线如图1所示。先从高空间分辨率影像上提取耕地地块,再结合多期高时间分辨率影像构建地块尺度的归一化植被指数(normalized difference vegetation index, NDVI)时序曲线,进而结合实地调查样本进行农作物类型识别,最后据此开展不确定性的分析评价。
图1
1.1 基于机器学习的耕地地块提取与农作物分类
图2
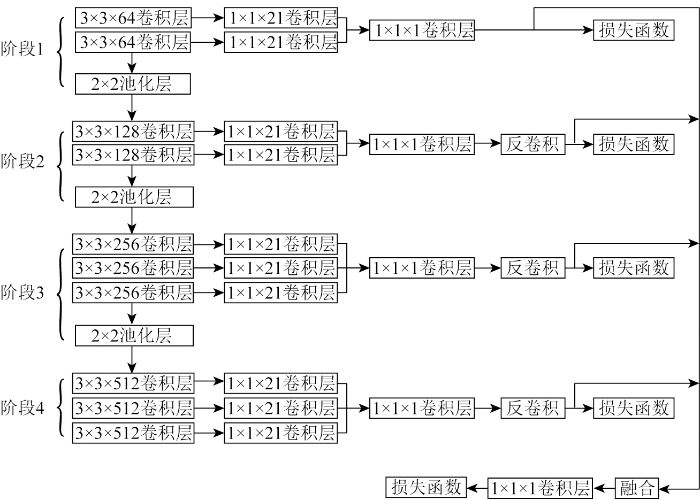
图2
改进的RCF网络结构
Fig.2
Machine learning networks for farmland boundary extraction and crop type recognition
在地块单元提取的基础上,本研究利用多时相的Sentinel-2影像,通过波段计算得到不同时相上每个像元对应的NDVI,并对地块边界内的所有像元统计均值,经异常值剔除后生成一条相对平滑的地块级NDVI时序曲线,用于描述农作物生长期内的生长状态变化,以表示其类型的时空分异[20]。为了挖掘输入信号序列在时间维度上的长期依赖特征,本实验选用长短期记忆网络(long short-term memory, LSTM)[21]作为推测模型。该模型在隐藏层中设置包含3个门控组件的记忆元,借此选择需要记忆或遗忘的信息,并通过记忆元的连接实现处理时间序列信息上的连贯性。实验中基于LSTM的上述基本结构,构建了包含4个隐藏层、36个隐藏神经元的推测模型,结合实地获取的地面样本和地块级NDVI时序数据进行农作物类型的分类识别。
1.2 基于熵理论的农作物分类不确定性计算
式中: x为地块的光谱特征矩阵; xn为x的第
式中:
综上,鉴于信息熵和模糊熵对不确定性的侧重点不同,本研究将两者进行耦合,形成如下的混合熵计算公式:
对式(6)进行进一步分解后可得:
式中:
1.3 农作物分类不确定性的影响因素解析
1)种植结构。若农业生产模式中存在复种、套种等复杂种植结构,会使地块时序曲线产生偏差,在机器学习分类过程中更易被错分或漏分,进而导致类型不确定性升高,因此选择作物类型(x1)作为影响变量。
2)地块形态。为了探究地块形态对分类不确定性的影响,计算每个地块的地块面积(x2,m2)、地块周长(x3,m)、地块形状指数(x4),其中形状指数描述了地块形态的光滑程度,公式为:
式中: S为地块形状指数; e为地块边界长度; A为地块面积。
4)环境与农业管理条件。鉴于环境与农业管理因素会影响灌溉水等生产要素的供应,影响生物有机质含量,作用于植被导致某些类型之间的特征混淆,本研究还计算了灌溉渠网密度(x8,km/km2)、交通路网密度(x9,km/km2)、居民点密度(x10,km/km2)、地块与水渠的距离(x11,km)作为分析的辅助变量。
在此基础上,本研究使用随机森林回归方法评估各类地理因素对农作物分类不确定性的影响[29],并得到特征重要性指标。由于树在每个节点选择的变量的随机性,变量重要性计算过程存在一定程度随机性。因此,对随机森林模型进行10次回归实验,并取10次特征重要性结果平均值。
2 实验及结果分析
2.1 实验区概况及数据介绍
本研究选取宁夏回族自治区引黄灌区作为实验区,如图3所示。该区域地处黄河中上游,覆盖青铜峡市、银川市等11个市区县,属大陆性气候,干旱少雨、热量充足。区域内耕地地块广阔、空间形态规整; 播种类型丰富,主要粮食作物包括水稻、玉米、小麦等,经济作物包括蔬菜、向日葵、西瓜等。宁夏引黄灌区为我国干旱半干旱地区的粮食主产地之一,播种制度多样,主要方式为1年水稻1年旱作物的两段轮作制。在该区域开展地块级农作物分类及其不确定性的评价分析实验,具有较好的代表性。
图3
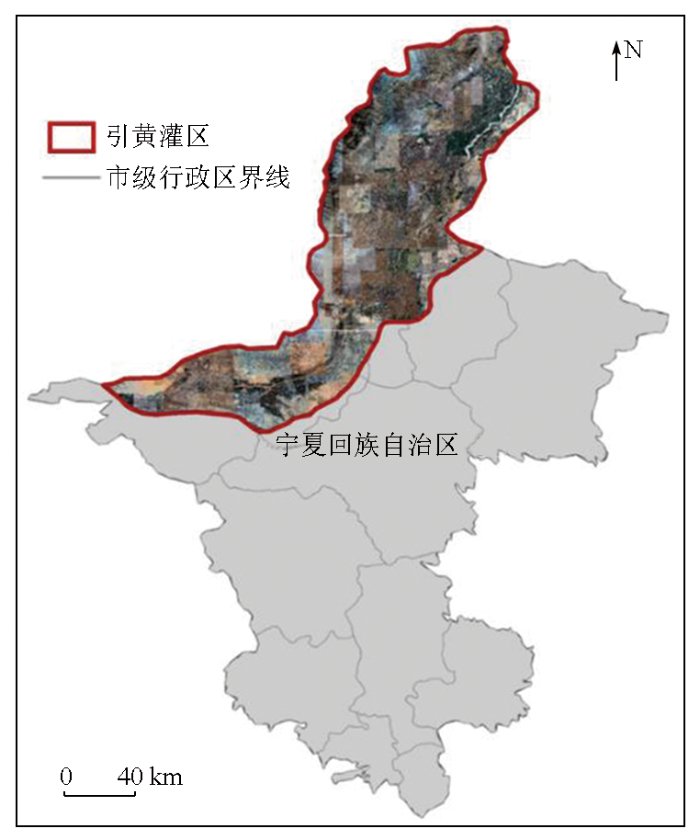
图3
研究区位置及Google Earth影像切片
Fig.3
Location and view of Google Earth image of the study area
本研究所采用的影像数据主要包括Google Earth及Sentinel-2B影像,其中Google Earth影像空间分辨率达1 m,主要用于开展地块边缘特征提取实验,Sentinel-2B影像共收集并处理33期225景,空间分辨率为10 m,时间范围为2020年3月7日—10月21日,覆盖研究区农作物的播种、生长及成熟期,主要用于构建时序NDVI特征和开展农作物类型识别。为分析不确定性空间分布的影响因素,本研究还获取区域内水系、交通、居民点及设施数据,用于计算灌溉渠网密度、交通路网密度、居民点密度等与地块作物分类相关的环境特征。此外,利用手持全球移动定位系统(global positioning system, GPS)进行农作物定位调查,通过地面采样收集了465个耕地地块采样点的空间坐标和种植作物类型信息,并对照Google Earth高分影像上随机生成的点位,通过参照地面点的人工目视解译方法,补充了模型训练及验证所需的农作物类型样本,最终得到了8大类作物的2 469个地块样本,包括水稻584个、单种小麦377个、复种小麦(即在小麦收割至下一轮播种的间隙,种植蔬菜等其他作物,以提高耕地的利用效率)326个、玉米579个、菜地249个、果园76个、苜蓿186个、其他作物92个。
2.2 耕地地块提取与农作物分类结果
本研究基于Google Earth高分影像数据,结合耕地地块边界样本,借助RCF网络提取了地块边缘强度信息,并经矢量化处理构建地块对象。本次实验共提取研究区内的地块约149万个,典型地块的细节如图4所示,总体效果较为理想,可为后续农作物类型识别及不确定性分析提供稳定的耕地边界空间约束。
图4
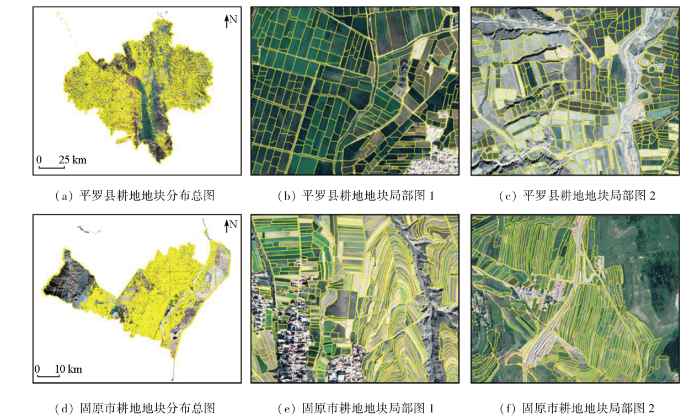
图4
研究区内耕地地块提取效果
Fig.4
Extraction effects of cropland-parcels in the study area
在地块单元构建基础上,本研究基于Sentinel-2B卫星时序影像计算了地块内各像元的NDVI值,取其均值生成地块尺度的NDVI序列,再使用地面采集的样本数据训练LSTM网络,预测各地块作物类型。分类结果如图5所示,据此统计后结果显示: 玉米种植面积最大,占全区耕地面积的40%以上; 菜地次之,面积比重超过16%; 水稻和小麦种植面积相近,占比均在12%左右,其中单种小麦面积比重较高,为复种小麦的4倍左右; 灌区果园、苜蓿等面积较小,仅占总耕种面积的3%; 其他作物面积占比约16%。
图5
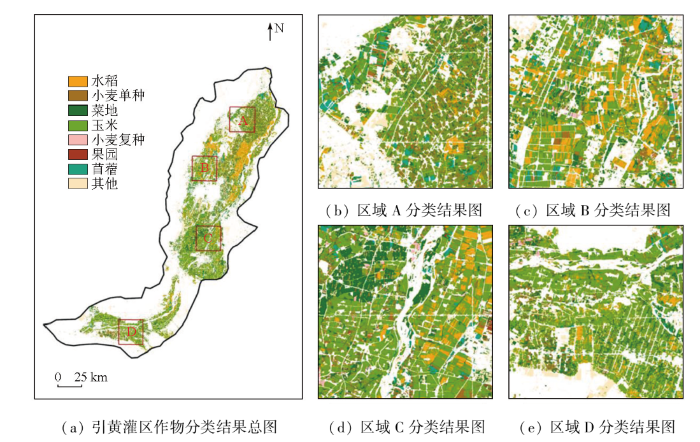
图5
2020年宁夏引黄灌区农作物分类结果
Fig.5
Crop classification results of Yellow River Irrigation Area of Ningxia in 2020
2.3 地块农作物分类的不确定性计算结果
进一步,基于1.2节的混合熵模型计算得到地块尺度农作物分类的不确定性评价结果。如图6所示,在全域上,混合熵取值范围介于0.000 52~3.449 25之间,平均值约为1.130 18; 在局部上,邻近地块的混合熵指标各异、交相分布,显示了不确定性的空间结构较为复杂。
图6
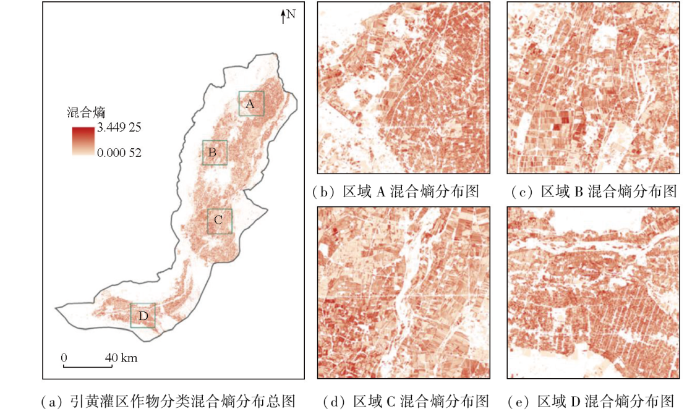
图6
研究区地块尺度农作物分类的混合熵计算结果
Fig.6
Calculation results of hybrid entropy of crop classification on farmland-parcel scale in the study area
为详细分析不确定性的类型结构,本文统计了各作物类型不同混合熵值区间的地块数量情况,并将综合反映地块光谱特征及类型判定不确定性的混合熵指标(指标1)、直接反映分类模型判别归类情况的最大隶属度指标(指标2),以及反映验证集分类召回率与精确率的F1指标(指标3)进行协同分析。其中,由式(7)的定义可知,混合熵由信息熵及模糊熵2部分综合而得,整体反映“同物异谱”等地物特征固有随机不确定性,以及由于特征不完备、地块非均质、模型学习能力不足等引发的类型归属模糊性; 该指标与直接反映分类模糊性的最大隶属度有所关联,理论上应遵循最大隶属度越高,信息熵越低的规律。此外,低不确定性意味着地块光谱特征具有较为明确的农作物类型归属倾向,易于准确判定其作物类型,因而混合熵越低,F1得分应越高。
各类作物混合熵分布拟合概率密度曲线及不确定性指标对比分析结果分别如图7、表1所示。由图7可知,该区域实验的农作物类间不确定性差异显著: 水稻、菜地、苜蓿3类作物的混合熵整体较小,均值皆在1.0上下,熵值介于0~0.13之间的地块显著占优,熵值大于2.0的地块数目稀少; 果园地块的分布模式与前三者相近,但熵值大于0.13的地块比重有所增加,混合熵均值上升至1.29; 玉米地块与果园的混合熵均值相近,但熵值优势分布扩展至0.4~2.0区间; 单种及复种小麦的整体不确定性最高,混合熵分布向高值区域偏移,均值达到1.9以上。此外,对比表1中各类型3种评价指标可知,与前述相关分析基本一致,但最大归属度越高、不确定性(混合熵)越低的直觉规律并非严格成立,例如,玉米地块的平均归属度高于果园地块,但混合熵均值亦较高,说明分类器的判定倾向性显著,但对于次要类型的判别模糊性较高,或光谱特征的信息熵较高、先验随机性明显。同时,高F1得分并不必然代表低分类不确定性,如水稻地块的F1得分高于菜地,但混合熵亦较高; 苜蓿的混合熵低于玉米,但或许由于样本数量差异,F1指标亦较低。这说明不确定性指标与传统精度指标的衡量标准各有侧重,且验证集上的二值化分类精度指标并不能完全反映全局分类效果。
图7
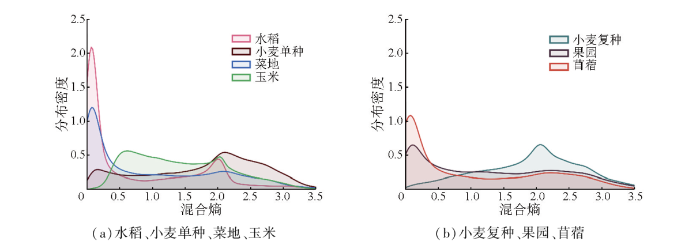
图7
地块尺度各农作物类型的不确定性分布概率密度曲线图
Fig.7
Probability density curve of uncertainty distribution of each crop type at the farmland-parcel scale
表1 地块尺度各农作物类型的不确定性对比分析
Tab.1
| 农作物 类型 | 混合熵均值 | 隶属度均值 | F1 | 总体分 类精度 | |||
|---|---|---|---|---|---|---|---|
| 值 | 由低到 高排序 | 值 | 由高到 低排序 | 值 | 由高到 低排序 | ||
| 水稻 | 1.03 | 2 | 0.83 | 3 | 0.89 | 1 | 0.80 |
| 小麦单种 | 1.93 | 7 | 0.67 | 7 | 0.68 | 6 | |
| 菜地 | 0.92 | 1 | 0.85 | 1 | 0.84 | 3 | |
| 玉米 | 1.37 | 5 | 0.81 | 4 | 0.82 | 4 | |
| 小麦复种 | 1.92 | 6 | 0.69 | 6 | 0.65 | 7 | |
| 果园 | 1.29 | 4 | 0.79 | 5 | 0.86 | 2 | |
| 苜蓿 | 1.04 | 3 | 0.85 | 2 | 0.79 | 5 | |
为进一步分析农作物分类不确定性(混合熵)与隶属度的关系,并借此分析不确定性的机理性来源,本文绘制了不确定性与最大隶属度二者之间的散点图(图8),同时计算验证集样本地块的多维隶属度均值,得到混淆矩阵(图9)。由上述2图可知,地块尺度农作物分类的混合熵与最大隶属度之间呈现近似负相关二次曲线关系,混合熵高处最大隶属度低,且点位密集、高隶属度区域(即农作物类内一致性高、不确定性低)曲线形态特征更加明显。例如,苜蓿地块判识的隶属度较高、混合熵均值较低,且不存在与其他农作物明显的混淆情况,因此散点图呈现出较为紧凑的抛物线形状; 玉米地块混合熵均值较高,且与水稻存在误分现象; 小麦单种地块同理,混合熵均值较高、隶属度低,且与小麦复种、玉米混淆明显,散点图分散。另外,对比各类农作物的NDVI时序曲线可知,类型混淆及高不确定性与作物NDVI曲线特征相关: 水稻及玉米的NDVI曲线形态相近,小麦单种、复种作物的部分物候特征完全一致,导致地块间可区分性下降、类型随机性增加,因而不确定性较高; 菜地、苜蓿的曲线形态独特,波峰波谷特征与其他粮食作物差异显著,故而分类不确定性较低。
图8
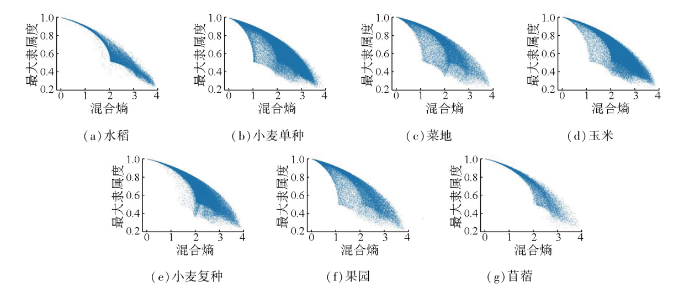
图8
研究区主要农作物分类不确定性(混合熵)与最大隶属度的散点图
Fig.8
Scatterplot of uncertainty and maximum membership of major crop classifications in the study area
图9
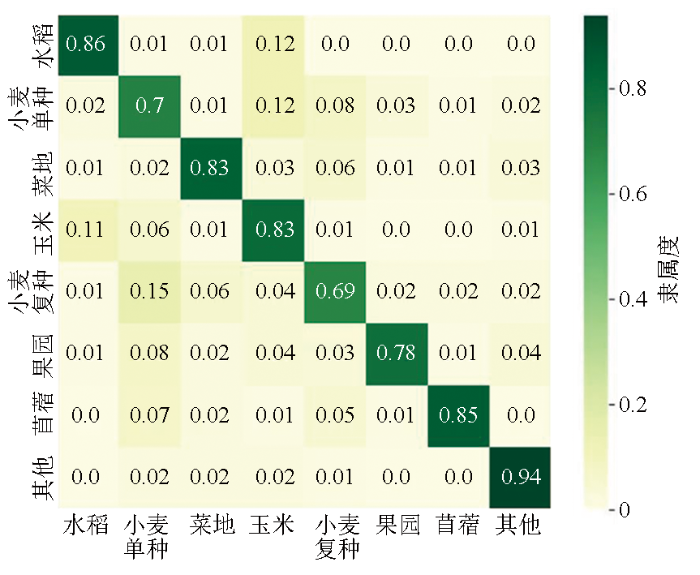
图9
研究区内验证样本地块对各农作物类型的隶属度值分布
Fig.9
Distribution of membership values of the validation sample land-parcels to each crop type in the study area
2.4 地块农作物分类的不确定性影响因素解析结果
基于1.3节所列的种植结构、地块形态、样本特征、环境与农业管理条件等特征因子以及上文以混合熵度量得到的农作物分类不确定性,本研究借助随机森林回归模型进一步分析了在地块尺度农作物分类不确定性的相关影响因素。为减少空间相关性的影响,本文随机抽取268 972个地块,并以9:1分为训练集与测试集,采样均方误差(mean square error,MSE)作为衡量标准,并输出特征重要性及其排名。计算结果如表2所示,MSE值为0.28,R2值为0.68,总体表明随机森林回归模型对地块农作物分类不确定性具有较为好的建模能力。从表2可知,回归模型中最重要的5个变量依次为: 作物类型、水渠距离、地块形状指数、灌溉渠网密度、交通路网密度。这表明地块农作物分类不确定性主要受制于种植结构、环境与农业管理条件以及地块形态特征,具体解析如下:
表2 随机森林回归模型对农作物分类不确定性进行建模生成的特征重要性
Tab.2
| 类型 | 变量 | 特征重要性 | 排名 |
|---|---|---|---|
| 种植结构 | 作物类型 | 0.27 | 1 |
| 地块形态 | 地块面积 | 0.10 | 7 |
| 地块周长 | 0.08 | 8 | |
| 地块形状指数 | 0.14 | 3 | |
| 样本特征 | 样本密度1 km | 0.04 | 11 |
| 样本密度2.5 km | 0.06 | 9 | |
| 样本密度5 km | 0.13 | 6 | |
| 环境与农业 管理条件 | 灌溉渠网密度 | 0.14 | 4 |
| 交通路网密度 | 0.14 | 5 | |
| 居民点密度 | 0.04 | 10 | |
| 与水渠的距离 | 0.16 | 2 | |
| MSE | 0.28 | R2 | 0.68 |
首先,重要性最高的影响变量为农作物类型,这与2.3中的相关讨论一致,不同作物的光谱分布特征不同,类内一致性、类间差异度有所区别,直接影响地块农作物类型的归属判断及不确定性指标。如苜蓿、菜地地块物候特征独特,不易与其他类型相互混淆,整体不确定性较低; 小麦、玉米等与其他类型特征相近,受类内光谱特征差异的影响显著,不确定性较高。
图10
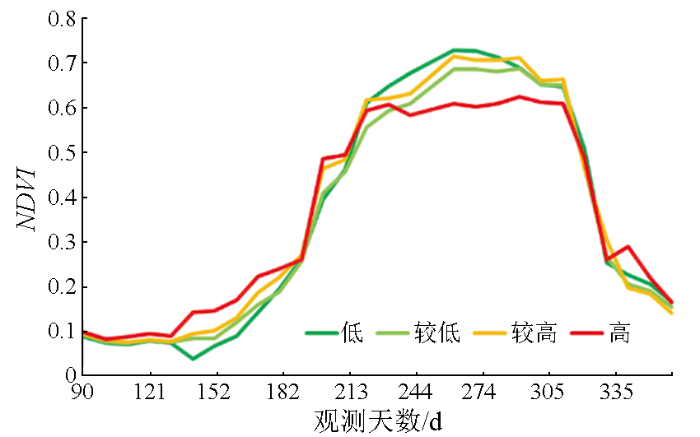
图10
不同不确定性等级的水稻地块NDVI均值曲线
Fig.10
Mean NDVI curves of rice land-parcels with different uncertainty levels
第三,道路密度是潜在的影响因素,在基础设施建设完备、人口密度较大的地区,农作物分类不确定性较低。该相关性是由于较为便利的交通条件保证了田块管理人员及相关设备的灵活出入,进而为农作物提供了更为理想的生长条件,而地块内植被茂密、NDVI特征明显、杂草等干扰信号微弱,分类不确定性因之降低。
第四,5 km半径内的样本密度特征重要性排名靠前,意味着分类器对地块种植农作物进行判识时,受其一定半径内“近邻样本”的影响,拥有更多、更丰富类型的区域,其光谱响应特征将在整体分布中的体现更为显著,进而获得更高质量的分类依据。此外,我们发现半径为2.5 km和1 km的样本密度特征在建模过程中重要性较低,表明过小半径内的样本密度与不确定性关联有限,可能是由于样本数量以及样本类型丰富度不足,无法显著影响作物类型光谱响应特征的整体分布。
3 结论及展望
3.1 研究结论
针对农作物种植结构精准制图与可靠性评价问题,本文选择宁夏引黄灌区作为研究区,开展地块尺度的农作物分类及不确定性分析,得到如下结论:
1)研究区内农作物分类的总体不确定性较低,制图结果较可靠,但由于不同农作物物候特征、光谱响应及播种规模等差异,模型区分能力存在一定的类间波动,其中水稻、菜地、苜蓿地块的分类不确定性较小,单种及复种小麦地块易于相互混淆,不确定性较大,玉米的低不确定性及高不确定性地块数量比例均较低。
2)基于混合熵的不确定性评价指标综合考虑了在基于时序观测、借助深度学习网络进行作物分类过程的不同环节中,由于光谱特征自身混杂缺损、类别稳定性不足造成的先验随机性,以及分类模型最终结果的判别模糊性。实验结果与F1得分等传统的精度评价指标倾向性基本一致,但侧重点有所不同,可以视作对分类不确定性来源分解、综合度量的一种尝试,具有一定的科研及实用价值。
3)较传统的混淆矩阵及像素级精度评价方案,本文构建的不确定性建模过程以地块作为空间“容器”,将不确定性分析结果与地理实体相匹配,直观展示了制图可靠性的空间分布模式,能为后续环境变量相关性分析、地面样本扩充及模型迭代优化提供指示信息。
4)由随机森林回归模型的特征重要性解析得出,农作物分类的不确定性与种植作物类型、环境与农业管理条件等因素存在相关性: 灌溉条件优越、地块形状规则的区域,农作物生物量较高,光谱特征显著,不确定性相应较低; 而对物候变化特征显著的农作物,模型的可分性较强,不确定性同样较低。
3.2 讨论及展望
本文借助混合熵模型,在地块尺度开展了农作物分类不确定性的评价,验证了基于混合熵指标评价农作物分类质量的有效性,展示不确定性的空间分布结构,并对造成不确定性的地理环境要素进行了定量解析。在此基础上,本研究在以下几个方面可进一步深入:
1)对基于混合熵构建不确定性度量的机理性解释还有待进一步探索。
2)地块尺度的种植结构制图精度包括形态精度和类型精度,本文仅聚焦于类型判识中的不确定性建模,缺乏针对形态不确定性的解析,后续可尝试引入交并比等形态精度指标。
3)本研究的不确定性分析仅用于量化评价分类算法的输出结果,尚未将其融入实际制图流程中,对其支撑下的分类算法迭代优化研究还未开展,后续可在不确定性空间分布指示下进行目的性补样及模型强化学习,验证其提升制图精度的可行性和有效性。
参考文献
Remote sensing for agricultural applications:A meta-review
[J].
大数据时代的农情监测与预警
[J].
Agricultural monitoring and early warning in the era of big data
[J].
How good is my map? A tool for semi-automated thematic mapping and spatially explicit confidence assessment
[J].
Good practices for estimating area and assessing accuracy of land change
[J].
遥感影像数据分类的不确定性分析及其处理方法综述
[J].
Review of uncertainty analysis and processing methods of remote sensing image data classification
[J].
Estimation and mapping of misclassification probabilities for thematic land cover maps
[J].
A new method for cross-calibration of two satellite sensors
[J].
Spatial analysis of remote sensing image classification accuracy
[J].
Factors affecting spatial variation of classification uncertainty in an image object-based vegetation mapping
[J].
遥感数据专题分类不确定性评价研究:进展、问题与展望
[J].
DOI:10.11867/j.issn.1001-8166.2005.11.1218
[本文引用: 1]

从遥感数据中提取专题类别信息是当前遥感数据最主要的应用领域之一。由于遥感分类专题信息广泛应用于各种领域,其数据质量受到越来越多的关注。不确定性是评价分类专题类别数据质量最主要的方面。回顾了遥感数据专题分类不确定性评价方法的历史,总结了当前各种评价方法及其指标体系,将这些方法归结为基于误差矩阵的方法、模糊评价方法、像元尺度上的不确定性评价方法和其它方法四大类。对每一类不确定性评价方法及其指标体系的优点和缺点进行了分析和总结,指出从理论方法研究方面,需要优先发展独立于分类方法的像元尺度上的遥感分类不确定性评价模型与指标体系,以及统一的遥感数据分类不确定性评价模型体系研究;在应用研究方面,需要加强优化空间采样设计和不确定性评价过程标准化研究。
Assessment on uncertainty in remotely sensed data classification:Progresses,problems and prospects
[J].
基于不确定性迭代优化的山地植被遥感制图
[J].
DOI:10.12082/dqxxkx.2022.210594
[本文引用: 1]
山地因其较高的异质性和特殊的环境特征给遥感科学及其应用带来了诸多问题和挑战。为实现山地植被信息的精准提取,本研究选择部分滇西北山地区域作为研究区开展方法实验,利用高分辨率遥感影像数据和数字高程模型,结合分区分层感知思想,提出一种基于不确定性理论的山地植被型组分类制图方法。首先结合地形对研究区影像进行多尺度分割制作图斑;然后根据图斑特征使用随机森林方法进行分类,将分类结果与对应类别样本间的相似性作为优化目标, 并构建混合熵模型定量计算图斑推测类型的不确定性,据此进行针对性的样本补充和分类模型的迭代优化。实验总体分类精度达90.8%,较迭代前提升了29.4%,Kappa系数达到0.875。在高不确定性区域,该方法相比使用一次性补样和随机补样方法的分类结果,精度分别提高了17%和13%。研究结果表明,通过人机交互的方式,基于不确定性理论为样本库融入增量信息的迭代优化方法能够有效提高植被型组分类的精度,相较于传统的样本选择方法具有更高的效率和更低的不确定性。
Remote sensing mapping of mountain vegetation via uncertainty-based iterative optimization
[J].
A comparison of resampling methods for remote sensing classification and accuracy assessment
[J].
Development and test of an error model for categorical data
[J].
Estimating per-pixel thematic uncertainty in remote sensing classifications
[J].
Geographically weighted methods for estimating local surfaces of overall,user and producer accuracies
[J].
Mapping per-pixel predicted accuracy of classified remote sensing images
[J].
First experience with sentinel-2 data for crop and tree species classifications in central Europe
[J].
Richer convolutional features for edge detection
[J].
DOI:10.1109/TPAMI.2018.2878849
PMID:30387723
[本文引用: 1]
Edge detection is a fundamental problem in computer vision. Recently, convolutional neural networks (CNNs) have pushed forward this field significantly. Existing methods which adopt specific layers of deep CNNs may fail to capture complex data structures caused by variations of scales and aspect ratios. In this paper, we propose an accurate edge detector using richer convolutional features (RCF). RCF encapsulates all convolutional features into more discriminative representation, which makes good usage of rich feature hierarchies, and is amenable to training via backpropagation. RCF fully exploits multiscale and multilevel information of objects to perform the image-to-image prediction holistically. Using VGG16 network, we achieve state-of-the-art performance on several available datasets. When evaluating on the well-known BSDS500 benchmark, we achieve ODS F-measure of 0.811 while retaining a fast speed (8 FPS). Besides, our fast version of RCF achieves ODS F-measure of 0.806 with 30 FPS. We also demonstrate the versatility of the proposed method by applying RCF edges for classical image segmentation.
Long short-term memory
[J].
DOI:10.1162/neco.1997.9.8.1735
PMID:9377276
[本文引用: 1]
Learning to store information over extended time intervals by recurrent backpropagation takes a very long time, mostly because of insufficient, decaying error backflow. We briefly review Hochreiter's (1991) analysis of this problem, then address it by introducing a novel, efficient, gradient-based method called long short-term memory (LSTM). Truncating the gradient where this does not do harm, LSTM can learn to bridge minimal time lags in excess of 1000 discrete-time steps by enforcing constant error flow through constant error carousels within special units. Multiplicative gate units learn to open and close access to the constant error flow. LSTM is local in space and time; its computational complexity per time step and weight is O(1). Our experiments with artificial data involve local, distributed, real-valued, and noisy pattern representations. In comparisons with real-time recurrent learning, back propagation through time, recurrent cascade correlation, Elman nets, and neural sequence chunking, LSTM leads to many more successful runs, and learns much faster. LSTM also solves complex, artificial long-time-lag tasks that have never been solved by previous recurrent network algorithms.
A mathematical theory of communication
[J].
遥感云分类不确定性的多维混合熵模型评价
[J].
Evaluation on uncertainty of RS cloud classification based on multidimensional hybrid entropy mo-del
[J].
基于混合熵模型的遥感分类不确定性的多尺度评价方法研究
[J].
Multi-scale evaluation method for uncertainty of remote sensing classification based on hybrid entropy model
[J].
Effects of landscape characteristics on land-cover class accuracy
[J].
On the use of the overlapping area matrix for ima-ge segmentation evaluation:A survey and new performance measures
[J].
Status of land cover classification accuracy assessment
[J].
Variable importance assessment in regression:Linear regression versus random forest
[J].
Impact of feature selection on the accuracy and spatial uncertainty of per-field crop classification using support vector machines
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}