

0 引言
随着卫星遥感技术的不断发展,高光谱图像的获取变得更加容易。相对于多光谱遥感,高光谱遥感能够获得大量的波段信息,这些波段信息被广泛应用于目标探测、环境监控和地物分类等方面[1],其中高光谱遥感图像的分类问题一直是国内外学者研究的热点。高光谱遥感图像具有维数大和训练样本数量少的特点[2],在小样本图像分类情况下,维数过大易导致分类任务变得复杂,分类精度会因为波段数量的增加反而下降,从而产生Hughes现象[3]。其中支持向量机(support vector machine,SVM)的分类算法常用于解决此类问题[4]。杨凯歌等[5]将随机子空间集成法结合SVM提出优化子空间SVM集成的分类算法,利用SVM对随机子空间进行聚类,根据J-M距离准则对最优分类器进行集成,通过对比实验证明该算法可以有效地解决小样本情况下的分类问题; Persello等[6]通过对比主动学习策略和半监督学习方法的优缺点,结合2种方法应用在SVM上,解决了小样本情况下未知样本标注问题。
此外,迁移学习通过对同领域或者跨领域进行知识迁移也可以解决小样本情况下的高光谱图像分类问题,当源训练样本集包含的带标签样本数量非常少时,迁移学习将与源训练样本集相似的样本作为辅助样本集,与源样本集组成总训练样本集完成目标样本集的分类、识别等任务[7]。吴田军等[8]将迁移学习应用在高光谱图像分类的样本选择中,将历史的地物信息迁移到新的图像中,建立一种新的特征映射关系,从而实现对目标高光谱图像样本的自动分类; Zhou等[9]将迁移学习应用在极限学习机中,并与最小二乘法结合,利用TrAdaboost算法的权重调整策略对样本进行分类,最后经过对比实验证明了该算法的有效性。其中TrAdaboost算法是Dai等[10]提出的一种基于实例的迁移学习算法,对Adaboost算法进行了改进,使之具有迁移能力,通过判别训练样本的可利用价值调整样本的权重,完成小样本情况下的文本分类任务。
综上所述,SVM和迁移学习分类算法都能够很好地解决小样本问题。但对于高光谱图像分类问题,随着训练样本数目减少(小样本情况),样本维数大且存在冗余波段,相似类别样本间的分类边界变得模糊,导致分类精度大幅度降低。为了解决这个问题,本文提出了基于Fisher准则和TrAdaboost权重调整策略的H_TrAdaboost (Hyperspectral TrAdaboost)算法,利用Fisher准则放大样本间的差异,完成相似样本的划分; 结合TrAdaboost权重调整策略,动态调整样本的权重,实现高光谱相似样本的分类; 最后,在AVIRIS高光谱数据集上进行对比实验,验证H_TrAdaboost算法的有效性。
1 Fisher准则和TrAdaboost算法改进
1.1 辅助样本集确定
1.1.1 迁移学习
传统的机器学习方法对目标样本分类具有一定的前提条件,要求训练样本和测试样本必须符合相同的数据分布,并且需要足够数量的训练样本才能进行学习。这导致了在小样本情况下很多分类方法都不能取得很好的分类效果。迁移学习作为一种新的机器学习方法被提出,打破了传统学习方法的束缚,可以通过确定辅助样本集来解决样本数量少的问题。为了更加清晰地解释迁移学习,对样本集进行如下描述。
定义1: 训练样本数据集Da和Db
式中:
定义2: 目标样本数据集Dt
根据以上定义,迁移学习解决的问题可以描述为: 源训练样本集
由于本文研究的高光谱数据集,具有样本维数大、标记样本少的特点,而迁移学习可以有效解决小样本问题。因此,利用迁移学习,通过确定辅助样本集,将有利于目标分类的样本迁移到训练样本集中,从而扩大总样本数量,解决高光谱分类问题中由于训练样本过少导致的分类问题。
1.1.2 SID_SA结合法
假设
式中:
式中:
式中
1.2 波段选择
1.2.1 问题分析
为了更好地在小样本条件下进行相似地物类间分类,需要使用一种特征提取的方法,帮助放大样本间的差距,提高分类精度。高光谱图像特征提取方法常用的主成分分析法(principal components analysis,PCA)[13],是通过数学变换来压缩波段达到提取特征的目的,容易改变高光谱图像的光谱物理意义。而波段选择的方法是从大量波段中选择出利于分类的波段数据,构成一个波段子集,这样不会破坏物理结构而且可以达到数据降维的目的。因此本文在解决相似样本划分问题时采用的是波段选择的方法。
以美国印第安纳州高光谱数据集为例进行分析,从中选取名称为corn-notill和corn-mintill的2类相似地物,分别从2类地物中随机选取200个样本点,计算2类光谱均值和标准差。对比结果分别如图1所示。
图1
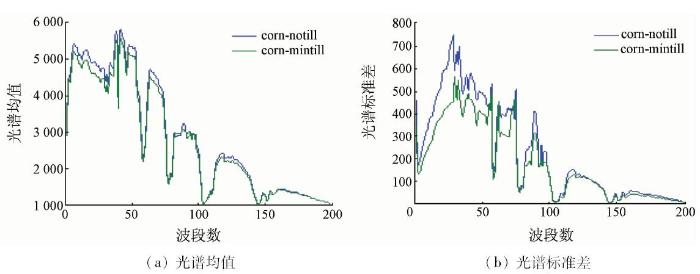
图1
相似地物光谱均值及标准差对比
Fig.1
Contrast of spectral mean and standard deviation of similar features
从图1中可以得知,2类样本在B2—B57和B64—B76等波段上的可分性比较大,在B54—B63和B77—B103等波段上的可分性比较小。这说明虽然相似样本间的波段信息比较相近,但是样本在各个波段上仍然具有可分性,如果在实验中对样本的所有波段进行相同的处理,则弱化了一些重要波段的信息。因此,在解决相似样本划分问题中进行波段选择是必要的,需要秉承的原则是最大化样本类间间距,最小化样本类内间距,最终选择可分性强的波段组成最优子集。Fisher准则作为一种直观有效的类别可分性判据,是波段选择的一个重要依据,因此利用改进的Fisher准则可解决相似样本可分性问题。
1.2.2 改进的Fisher准则
改进的Fisher准则是对原始Fisher准则中的距离度量方法由简单的欧氏距离变为马氏距离。其中马氏距离是表示数据的协方差距离[14],在相似度对比过程中,欧氏距离计算2个样本在空间上的直接距离,而马氏距离考虑的是样本数据各种特性之间的关系与差异,放大个体的影响。在不同的总体样本下,马氏距离的计算结果是不同的,更加适合用于相似样本的划分。因此本文采用基于马氏距离的改进Fisher准则对样本进行可分性研究,具体计算公式为
式中:
根据最小化类内间距、最大化类间间距的原则,可以得出改进的Fisher准则Jp为
式中: SB代表类间间距;
类间可分性越大,
1.3 权重调整策略
对于最后分类阶段,由于每个训练样本在分类过程中的可利用价值有所不同,因此在迭代训练过程中需要对每个样本进行不同的权重控制。原始的TrAdaboost算法是用于文本分类的,对样本进行权重分配时,分别调整辅助训练样本与源训练样本的权值,达到较好的分类效果。而本文在解决高光谱相似样本分类问题时,同样考虑到不同样本的权重问题,因此采用TrAdaboost算法的权重调整策略对目标样本进行分类。对于辅助训练样本,基本思想是如果样本被错误分类,证明此样本不利于分类,在下一次迭代过程中减少权重,主要通过参数
式中:
对于源训练样本,基本思想是如果样本被错误分类,在下一次迭代过程中通过增加权重来强调此样本,更正分类模型,主要通过参数
式中
综上所述,如果在N次迭代过程中,分别对2个训练样本集的权重进行动态调整,可以更好地完成小样本情况下相似样本分类任务。
2 H_TrAdaboost算法
H_TrAdaboost算法流程如图2所示。
图2

本文提出的H_TrAdaboost算法的要点是: 首先,利用SID_SA结合法确定辅助样本集; 然后,根据改进Fisher准则对波段进行可分性研究; 最后,利用权重调整策略完成高光谱相似样本分类。
1)根据小样本的源训练样本数据
2)通过对高光谱相似地物的光谱特性进行分析,得知每个波段的可分性不同,采用基于马氏距离的改进Fisher准则,利用式(12)—(13)对总训练样本
3)已知辅助样本数量
4)输入总训练集,设置样本权重为
式中
式中
5)设置迭代过程中训练样本的权重更新策略,即
式中
6)最终分类器设置为
式中: 「⌉为向下求和;
3 实验与结果分析
3.1 实验数据
图3

Tab.1 Information of Indian Pines dataset for experiment
| 类别 | 类别图例 | 名称 | 总样本数/个 |
|---|---|---|---|
| C1 | 免耕玉米地 | 1 428 | |
| C2 | 玉米幼苗 | 830 | |
| C3 | 玉米 | 237 | |
| C4 | 草地-树木 | 730 | |
| C5 | 免耕大豆地 | 972 | |
| C6 | 大豆幼苗 | 2 455 | |
| C7 | 修剪大豆地 | 593 | |
| C8 | 木材 | 1 265 |
3.2 实验结果
表2 各类别之间的SID_SA值
Tab.2
| 类别 | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 |
|---|---|---|---|---|---|---|---|---|
| C1 | 0.000 0 | 0.000 2 | 0.000 5 | 0.002 9 | 0.000 2 | 0.000 3 | 0.000 4 | 0.010 8 |
| C2 | 0.000 2 | 0.000 0 | 0.000 4 | 0.002 5 | 0.000 3 | 0.000 2 | 0.000 3 | 0.009 9 |
| C3 | 0.000 5 | 0.000 4 | 0.000 0 | 0.001 6 | 0.000 5 | 0.000 5 | 0.000 7 | 0.006 9 |
| C4 | 0.002 9 | 0.002 5 | 0.001 6 | 0.000 0 | 0.003 2 | 0.002 7 | 0.002 8 | 0.001 4 |
| C5 | 0.000 2 | 0.000 3 | 0.000 5 | 0.003 2 | 0.000 0 | 0.000 4 | 0.000 3 | 0.011 7 |
| C6 | 0.000 3 | 0.000 2 | 0.000 5 | 0.002 7 | 0.000 4 | 0.000 0 | 0.000 4 | 0.011 1 |
| C7 | 0.000 4 | 0.000 3 | 0.000 7 | 0.002 8 | 0.000 3 | 0.000 4 | 0.000 0 | 0.010 9 |
| C8 | 0.010 8 | 0.009 9 | 0.006 9 | 0.001 4 | 0.011 7 | 0.011 1 | 0.010 9 | 0.000 0 |
表3 算法间的分类精度对比
Tab.3
| 目标样 本类别 | 辅助样 本类别 | SVM | TrAdaboost | H_TrAdaboost |
|---|---|---|---|---|
| C1 vs C2 | C6 vs C5 | 54.50 | 55.50 | 59.00 |
| C1 vs C2 | C5 vs C6 | 63.50 | 67.00 | 69.50 |
| C1 vs C5 | C2 vs C6 | 73.50 | 74.50 | 77.50 |
| C1 vs C5 | C2 vs C7 | 71.00 | 68.50 | 76.00 |
| C1 vs C6 | C2 vs C7 | 65.50 | 67.00 | 71.00 |
| C1 vs C6 | C7 vs C2 | 70.50 | 72.50 | 73.00 |
| C2 vs C5 | C1 vs C6 | 71.00 | 74.50 | 75.50 |
| C2 vs C8 | C1 vs C4 | 98.50 | 99.50 | 99.50 |
| C2 vs C8 | C1 vs C5 | 94.00 | 97.00 | 97.50 |
从表3中可以看出,当分类C1和C2类样本时,辅助样本类别分别选取为C5与C6类时,分类精度最高且提高较多; 当分类C1和C6类样本时,辅助样本类别分别选取为C7与C2类时,分类精度最高且提高较多; 从而验证了SID_SA值越小,越适合做辅助样本,帮助源训练样本进行分类。同时,当类别本身相似性很小的时候,例如C2和C8类的分类,3种分类算法的效果都很明显,并且SVM算法、TrAdaboost算法与H_TrAdaboost算法分类精度呈上升趋势。验证了TrAdaboost算法经过数据处理后可以较好地应用在高光谱数据上,分类精度比SVM有所提高,将H_TrAdaboost算法与原始的TrAdaboost算法相比,分类精度也有显著提升,证明此算法在非相似样本分类问题上也具有较好的分类效果。
Tab.4 Accuracy compare of each algorithm in every sample
| 样本类别 | SVM算法 分类结果 | TrAdaboost算 法分类结果 | H_TrAdaboost算 法分类结果 |
|---|---|---|---|
| C1 vs C2 | |||
| C1 vs C5 | |||
| C1 vs C6 | |||
| C2 vs C5 | |||
| C2 vs C8 | |||
表5 样本1上算法间的分类精度对比
Tab.5
| 算法 | 统计值 | 15% | 10% | 5% | 3% | 2% | 1% |
|---|---|---|---|---|---|---|---|
| SVM | OA/% | 71.00 | 71.00 | 69.00 | 65.50 | 63.50 | 63.50 |
| Kappa | 0.70 | 0.71 | 0.67 | 0.64 | 0.63 | 0.62 | |
| TrAdaboost | OA/% | 77.50 | 76.00 | 71.00 | 69.50 | 68.50 | 67.00 |
| Kappa | 0.77 | 0.73 | 0.71 | 0.68 | 0.68 | 0.65 | |
| H_TrAdaboost | OA/% | 79.50 | 77.50 | 73.50 | 72.00 | 70.50 | 69.50 |
| Kappa | 0.79 | 0.77 | 0.73 | 0.72 | 0.70 | 0.69 |
表6 样本2上算法间的分类精度对比
Tab.6
| 算法 | 统计值 | 15% | 10% | 5% | 3% | 2% | 1% |
|---|---|---|---|---|---|---|---|
| SVM | OA/% | 77.00 | 76.00 | 73.00 | 71.50 | 70.00 | 70.50 |
| Kappa | 0.76 | 0.76 | 0.73 | 0.71 | 0.70 | 0.70 | |
| TrAdaboost | OA/% | 79.50 | 77.50 | 75.00 | 72.50 | 73.50 | 72.50 |
| Kappa | 0.77 | 0.77 | 0.75 | 0.73 | 0.73 | 0.72 | |
| H_TrAdaboost | OA/% | 80.50 | 79.00 | 76.50 | 74.50 | 73.50 | 73.00 |
| Kappa | 0.81 | 0.79 | 0.76 | 0.74 | 0.73 | 0.73 |
4 结论
1)利用实例迁移思想,采用SID_SA结合法对高光谱波段进行相似度度量,达到了确定辅助样本集的目的,解决小样本问题。
2)改进的Fisher准则侧重于高光谱数据整体特点,利用该准则从训练样本中选择可分性强的波段,达到放大相似样本波段间差异的目的。
3)利用TrAdaboost算法的权重调整策略为样本分配合理权重,最终通过实验表明,H_TrAdaboost算法可以很好地实现相似样本的分类。
4)虽然本文算法对与相似地物分类精度上有了一定提高,但仍有可以改进的地方。下一步的研究方向是考虑结合空间信息,从光谱的空间特征方面进一步提升高光谱相似地物的分类精度问题。
参考文献
高光谱遥感影像分类研究进展
[J].
DOI:10.11834/jrs.20165022
URL
[本文引用: 1]

随着模式识别、机器学习、遥感技术等相关学科领域的发展,高光谱遥感影像分类研究取得快速进展。本文系统总结和评述了当前高光谱遥感影像分类的相关研究进展,在总结分类策略的基础上,重点从以核方法为代表的新型分类器设计、特征挖掘、空间-光谱分类、基于主动学习和半监督学习的分类、基于稀疏表达的分类、多分类器集成六个方面对高光谱影像像素级分类最新研究进行了综述。针对今后的研究方向,指出高光谱遥感影像分类一方面要适应大数据、智能化高光谱对地观测的发展前沿,继续引入机器学习领域的新理论、新方法,综合利用多源遥感数据、多维特征空间互补的优势,提高分类精度、分类器泛化能力和自动化程度;另一方面要关注高光谱遥感应用的需求,突出高光谱遥感记录精细光谱特征的优势,针对应用需求发展有效的分类方法。
Review of hyperspectral remote sensing image classification
[J].
Advances in hyperspectral image classification:Earth monitoring with statistical learning methods
[J].
DOI:10.1109/MSP.2013.2279179
URL
[本文引用: 1]
Abstract: Hyperspectral images show similar statistical properties to natural grayscale or color photographic images. However, the classification of hyperspectral images is more challenging because of the very high dimensionality of the pixels and the small number of labeled examples typically available for learning. These peculiarities lead to particular signal processing problems, mainly characterized by indetermination and complex manifolds. The framework of statistical learning has gained popularity in the last decade. New methods have been presented to account for the spatial homogeneity of images, to include user's interaction via active learning, to take advantage of the manifold structure with semisupervised learning, to extract and encode invariances, or to adapt classifiers and image representations to unseen yet similar scenes. This tutuorial reviews the main advances for hyperspectral remote sensing image classification through illustrative examples.
高光谱遥感图像分类技术研究
[D].
Research on Classification Techinique for Hyperspectral Remote Sensing Imagery
[D].
基于支持向量机的高光谱遥感影像分类研究
[D].
Research on Hyperspectral Romote Sensing Image Classification Based on Support Vector Machine
[D].
优化子空间SVM集成的高光谱图像分类
[J].
Optimal subspace ensemble with SVM for hyperspectral image classification
[J].
Active and semisupervised learning for the classification of remote sensing images
[J].
DOI:10.1109/TGRS.2014.2305805
URL
[本文引用: 1]
This paper aims at analyzing and comparing active learning (AL) and semisupervised learning (SSL) methods for the classification of remote sensing (RS) images. We present a literature review of the two learning paradigms and compare them theoretically and experimentally when addressing classification problems characterized by few training samples (w.r.t. the number of features) and affected by sample selection bias. Commonalities and differences are highlighted in the context of a conceptual framework used to describe the workflow of the two approaches. We point out advantages and disadvantages of the two approaches, delineating the boundary conditions on the applicability of the two paradigms with respect to both the amount and the quality of available training samples. Moreover, we investigate the integration of concepts that are in common between the two learning paradigms for improving state-of-the-art techniques and combining AL and SSL in order to jointly leverage the advantages of both approaches. In this framework, we propose a novel SSL algorithm that improves the progressive semisupervised support vector machine by integrating concepts that are usually considered in AL methods. We performed several experiments considering both synthetic and real multispectral and hyperspectral RS data, defining different classification problems starting from different initial training sets. The experiments are carried out considering classification methods based on support vector machines.
A survey on transfer learning
[J].
DOI:10.1109/TKDE.2009.191
URL
[本文引用: 1]
A major assumption in many machine learning and data mining algorithms is that the training and future data must be in the same feature space and have the same distribution. However, in many real-world applications, this assumption may not hold. For example, we sometimes have a classification task in one domain of interest, but we only have sufficient training data in another domain of interest, where the latter data may be in a different feature space or follow a different data distribution. In such cases, knowledge transfer, if done successfully, would greatly improve the performance of learning by avoiding much expensive data-labeling efforts. In recent years, transfer learning has emerged as a new learning framework to address this problem. This survey focuses on categorizing and reviewing the current progress on transfer learning for classification, regression, and clustering problems. In this survey, we discuss the relationship between transfer learning and other related machine learning techniques such as domain adaptation, multitask learning and sample selection bias, as well as covariate shift. We also explore some potential future issues in transfer learning research.
迁移学习支持下的遥感影像对象级分类样本自动选择方法
[J].
DOI:10.13485/j.cnki.11-2089.2014.0163
Magsci
[本文引用: 1]
<p>面向遥感大范围应用的目标,自动化程度仍是遥感影像分类面临的重要问题,样本的人工选择难以适应当前土地覆盖信息自动化提取的实际应用需求。为了构建一套基于先验知识的遥感影像全自动分类流程,本文将空间信息挖掘技术引入到遥感信息提取过程中,提出了一种面向遥感影像对象级分类的样本自动选择方法。该方法通过变化检测将不变地物标示在新的目标影像上,并将过去解译的地物类别知识迁移至新的影像上,建立新的特征与地物关系,从而完成历史专题数据辅助下目标影像的自动化的对象级分类。实验结果表明,在已有历史专题层的图斑知识指导下,该方法能有效地自动选择适用于新影像分类的可靠样本,获得较好的信息提取效果,提高了对象级分类的效率。</p>
An automatic sample collection method for object-oriented classification of remotely sensed imageries based on transfer learning
[J].
Remote sensing image transfer classification based on weighted extreme learning machine
[J].
DOI:10.1109/LGRS.2016.2568263
URL
[本文引用: 1]
It is expensive in time or resources to obtain adequate labeled data for a new remote sensing image to be categorized. The cost of manual interpretation can be reduced if labeled samples collected from previous temporal images can be reused to classify a new image over the same investigated area. However, it is reasonable to consider that the distributions of the target data and the historical data are usually not identical. Therefore, the efficient strategy of transferring the beneficial information from historical images to the target image hits a bottleneck. In order to reuse sufficient historical samples to classify a given image with scarce labeled samples, this letter presents a novel transfer learning algorithm for remote sensing image classification based on extreme learning machine with weighted least square. This algorithm adds a transferring item to an objective function and adjusts historical and target training data with different weight strategies. Experiments on two sets of remote sensing images show that the presented algorithm reduces the requirement for target training samples and improves classification accuracy, timeliness, and integrity.
Boosting for transfer learning
基于光谱信息散度的非监督波段选择
[J].
DOI:10.3969/j.issn.1000-386x.2015.07.051
URL
[本文引用: 1]
在实际高光谱图像处理中,目标的先验信息往往较难获得,而非监督波段选择既能很好地完成海量光谱数据降维的任务,又不依赖于目标的先验信息,因而得到了广泛的应用。提出一种非监督波段选择算法:使用光谱信息散度作为相似性准则度量波段间的相似性,采用前向搜索算法作为波段搜索策略,逐步选出信息量丰富的波段集合。实验结果显示,采用该算法选出的波段集合与正交子空间投影算法和多元线性回归等非监督波段选择算法相比,拥有更高的分类检测精度。
An unsupervised band selection algorithm based on spectral information divergence
[J].
基于光谱信息散度与光谱角匹配的高光谱解混算法
[J].
DOI:10.11772/j.issn.1001-9081.2015.03.844
Magsci
[本文引用: 1]
<p>针对采用线性逆卷积(LD)算法进行端元初选过程中,端元子集中存在相似端元光谱,影响解混精度的问题,提出了一种基于光谱信息散度(SID)与光谱角匹配(SAM)算法的端元子集优选光谱解混算法。通过在端元进行二次选择时,采用以光谱信息散度和光谱角(SID-SA)混合法准则作为最相似端元选择的判据,去除相似端元,降低相似端元对解混精度的影响。实验结果表明,基于SID与SAM的高光谱解混算法将重构影像的均方根误差(RMSE)降低到0.0104,该方法比传统方法提高了端元的选择精度,减少了丰度估计误差,误差分布更加均匀。</p>
Hyperspectral unmixing algorithm based on spectral information divergence and spectral angle mapping
[J].
结合PCA及字典学习的高光谱图像自适应去噪方法
[J].
DOI:10.11772/j.issn.1001-9081.2016.12.3411
URL
Magsci
[本文引用: 1]
高光谱图像各波段图像噪声分布复杂,传统去噪方法难以达到理想效果。针对这一问题,在主成分分析(PCA)的基础上,结合噪声估计和字典学习,提出一种新的高光谱去噪方法。首先,对原始高光谱数据进行主成分变换得到一组主成分图像并根据能量比重将其划分为清晰图像组和含噪图像组;然后,根据任一波段图像的信息,利用奇异值分解(SVD)对图像进行噪声估计,再将得到的噪声估计方法与K-SVD字典学习去噪算法结合,提出一种具备自适应噪声估计特性的字典学习去噪算法,并将其应用于信息量较小的含噪图像组进行去噪处理;最后,按各主成分图像对应的信息量比例进行加权融合得到最终的去噪图像。通过对模拟与实际高光谱遥感图像的实验表明,与PCA、PCA-Bish、PCA-Contourlet三种去噪方法相比,所提方法去噪后图像的峰值信噪比(PSNR)可以提升1~3 dB,且具有更多的细节信息和更好的视觉效果。
Adaptive denoising method of hyperspectral remote sensing based on PCA and dictionary learning
[J].
基于类别可分性的高光谱图像波段选择
[J].
Supervised band selection based on class separability for hyperspectral image
[J].
多流形LE算法在高光谱图像降维和分类上的应用
[J].
Multi-manifold LE algorithm for dimension reduction and classification of multitemporal hyperspectral image
[J].
一种切空间协同表示的高光谱遥感影像分类方法
[J].
A hyperspectral image classification method based on collaborative representation in tangent space
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}