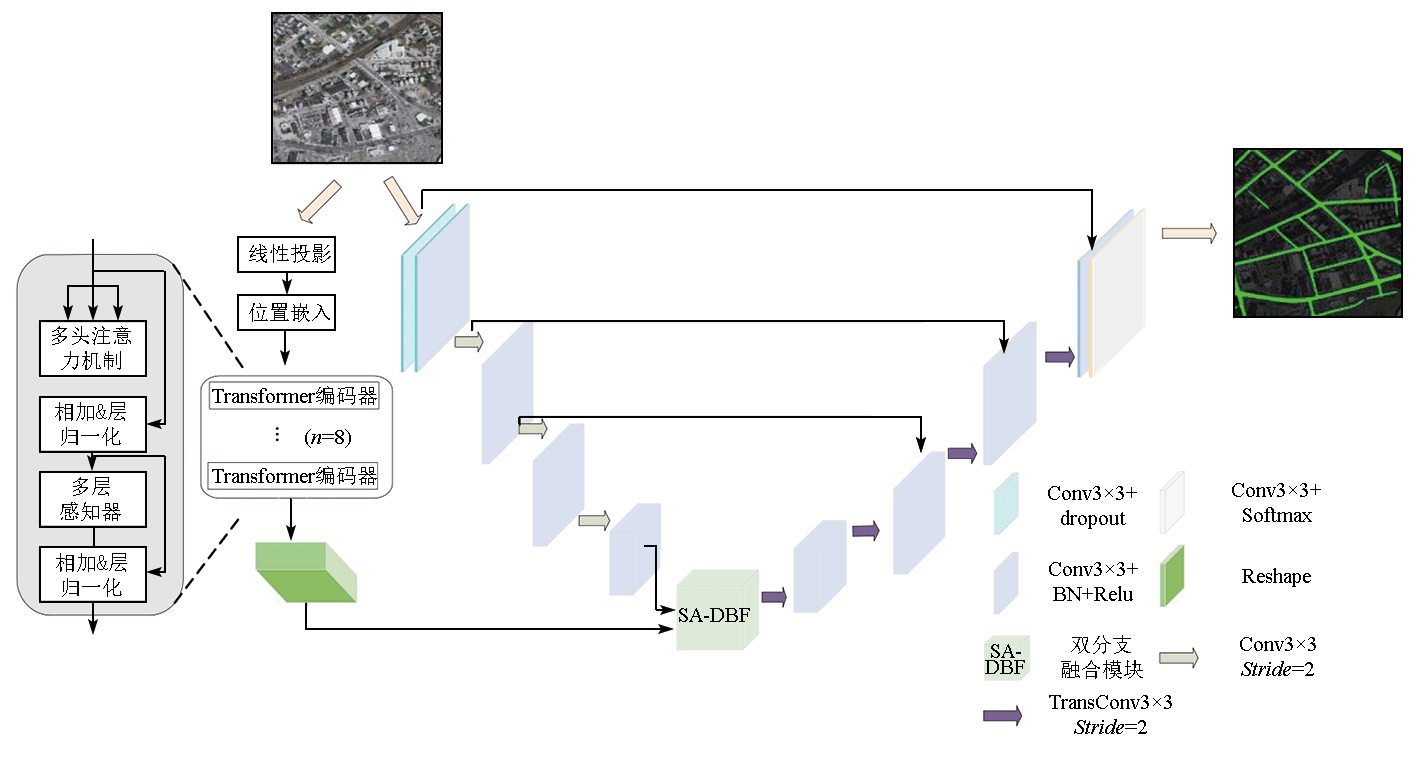
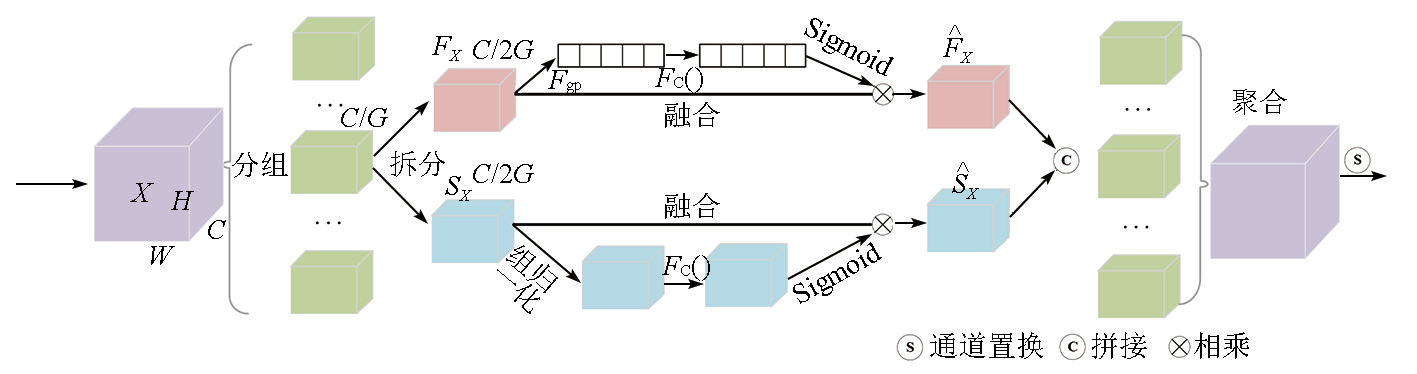
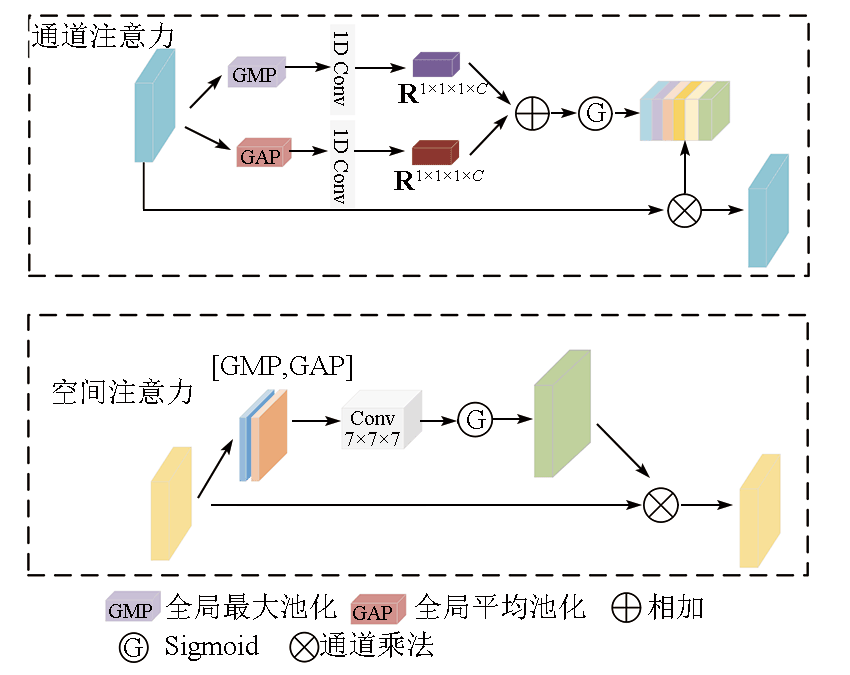
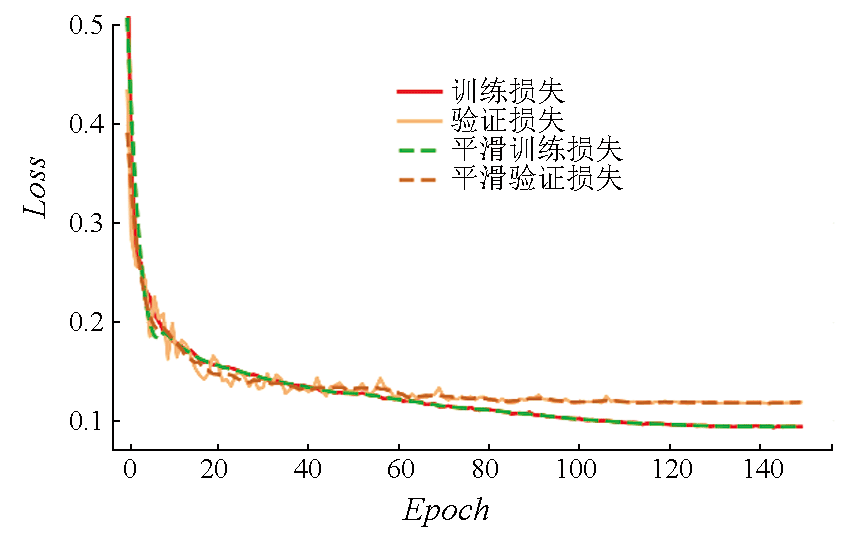
Deep learning-based methods for information extraction of roads from high-resolution remote sensing images face challenges in extracting information about both global context and edge details. This study proposed a cascaded neural network for road segmentation in remote sensing images, allowing both types of information to be simultaneously learned. First, the input feature images were sent to encoders CNN and Transformer. Then, the characteristics learned by both branch encoders were effectively combined using the shuffle attention dual branch fusion (SA-DBF) module, thus achieving the fusion of global and local information. Using the SA-DBF module, the model of the features learned from both branches was established through fine-grained interaction, during which channel and spatial information in the feature images were efficiently extracted and invalid noise was suppressed using multiple attention mechanisms. The proposed network was evaluated using the Massachusetts Road dataset, yielding an overall accuracy rate (OA) of 98.04%, an intersection over union (IoU) of 88.03%, and an F1 score of 65.13%. Compared to that of mainstream methodsU-Net and TransRoadNet, the IoU of the proposed network increased by 2.01 and 1.42 percentage points, respectively. Experimental results indicate that the proposed method outperforms all the methods compared and can effectively improve the accuracy of road segmentation.
曲海成, 王莹, 刘腊梅, 郝明. 融合CNN与Transformer的遥感影像道路信息提取[J]. 自然资源遥感, 2025, 37(1): 38-45.
QU Haicheng, WANG Ying, LIU Lamei, HAO Ming. Information extraction of roads from remote sensing images using CNN combined with Transformer. Remote Sensing for Natural Resources, 2025, 37(1): 38-45.
He D, Zhong Y, Wang X, et al. Deep convolutional neural network framework for subpixel mapping[J]. IEEE Transactions on Geoscience and Remote Sensing, 2021, 59(11):9518-9539.
[2]
Huang B, Zhao B, Song Y. Urban land-use mapping using a deep convolutional neural network with high spatial resolution multispectral remote sensing imagery[J]. Remote Sensing of Environment, 2018,214:73-86.
[3]
Xu Y, Chen H, Du C, et al. MSACon Mining spatial attention-based contextual information for road extraction[J]. IEEE Transactions on Geoscience and Remote Sensing, 1809,60:5604317.
[4]
Yuan Q, Shen H, Li T, et al. Deep learning in environmental remote sensing achievements and challenges[J]. Remote Sensing of Environment an Interdisciplinary Journal, 2020,241:111716.
[5]
Zhu Q, Zhang Y, Wang L, et al. A global context-aware and batch-independent network for road extraction from VHR satellite imagery[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2021,175:353-365.
[6]
Yang K, Yi J, Chen A, et al. ConDinet++:Full-scale fusion network based on conditional dilated convolution to extract roads from remote sensing images[J]. IEEE Geoscience and Remote Sensing Letters, 2021,19:8015105.
[7]
He D, Shi Q, Liu X, et al. Generating 2m fine-scale urban tree cover product over 34 metropolises in China based on deep context-aware sub-pixel mapping network[J]. International Journal of Applied Earth Observation and Geoinformation, 2022,106:102667.
[8]
Shelhamer E, Long J, Darrell T. Fully convolutional networks for semantic segmentation[C]// IEEE Transactions on Pattern Analysis and Machine Intelligence. IEEE,2017:640-651.
[9]
Ronneberger O, Fischer P, Brox T. U-net convolutional networks for biomedical image segmentation[C]// IEEE Springer International 2015:234-241.
[10]
Badrinarayanan V, Kendall A, Cipolla R. SegNet:A deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12):2481-2495.
doi: 10.1109/TPAMI.2016.2644615
pmid: 28060704
[11]
Chen L C, Zhu Y, Papandreou G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[M]// Computer Vision-ECCV 2018.Cham Springer International Publishing,2018:833-851.
[12]
Gao L, Song W, Dai J, et al. Road extraction from high-resolution remote sensing imagery using refined deep residual convolutional neural network[J]. Remote Sensing, 2019, 11(5):552.
Wang Y, Zeng X Q. Road extraction model derived from integrated attention mechanism and dilated convolution[J]. Journal of Image and Graphics, 2022, 27(10):3102-3115.
Wu Q Q, Wang S, Wang B, et al. Road extraction method of high-resolution remote sensing image on the basis of the spatial information perception semantic segmentation model[J]. National RemoteSensing Bulletin, 2022, 26(9):1872-1885.
[15]
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. 2017, Long Beach.ACM,2017:6000-6010.
[16]
Sanchis-Agudo M, Wang Y, Duraisamy K, et al. Easy attention:A simple self-attention mechanism for Transformers[J/OL]. 2023:arXiv:2308.12874.http //arxiv.org/abs/2308.12874.
[17]
Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16×16 words:Transformers for image recognition at scale[J/OL].2020:arXiv:2010.11929.http //arxiv.org/abs/2010.11929.
[18]
Yang Z, Zhou D, Yang Y, et al. TransRoadNet:A novel road extraction method for remote sensing images via combining high-level semantic feature and context[J]. IEEE Geoscience and Remote Sensing Letters, 1973,19:6509505.
[19]
Dai Z, Liu H, Le Q V, et al. CoAtNet:Marrying convolution and attention for all data sizes[J/OL]. 2021:arXiv:2106.04803.http //arxiv.org/abs/2106.04803.
[20]
Cao Y, Xu J, Lin S, et al.GCNet:Non-local networks meet squeeze-excitation networks and beyond[C]//2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW).Seoul,Korea (South). IEEE,2019:1971-1980.
[21]
Woo S, Park J, Lee J Y, et al. CBAM:Convolutional block attention module[M]// Computer Vision-ECCV 2018.Cham: Springer International Publishing,2018:3-19.
[22]
Su R, Huang W, Ma H, et al. SGE NET:Video object detection with squeezed GRU and information entropy map[C]//2021 IEEE International Conference on Image Processing (ICIP).Anchorage,AK,USA.IEEE,2021:689-693.
[23]
Wang Q, Wu B, Zhu P, et al.ECA-net:Efficient channel attention for deep convolutional neural networks[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle.IEEE,2020:11531-11539.
[24]
Zhou L, Zhang C, Wu M.D-LinkNet:LinkNet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Salt Lake City.IEEE,2018:192-1924.
 2025, Vol. 37
2025, Vol. 37  ), 王莹(
), 王莹(